1. File class
file class represents platform independent files and directories under java.io package, that is, if you want to operate files and directories in the program, you can use file class. It is worth noting that both files and directories are operated by file. File can create, delete and rename files and directories, and file cannot access the file content itself. If you need to access the file content itself, you need to use input / output streams.
1.1. Accessing files and directories
the File class can create a File instance using a File path string, which can be either an absolute path or a relative path. By default, the system always interprets the relative path according to the user's working path. This path is specified by the system attribute "user.dir", which is usually the path where the Java virtual machine is running.
once the File object is created, you can call the method of the File object to access it. The File class provides many methods to operate files and directories. Some common methods are listed below.
1. Methods related to accessing file names
String getName(): returns the File name or path name represented by the File object (if it is a path, it returns the last level sub path name).
String getPath(): returns the path name corresponding to this File object.
File getAbsoluteFile(): returns the absolute path of this File object.
String getAbsolutePath(): returns the absolute pathname corresponding to this File object.
String getParent(): returns the parent directory name of the directory (the last level subdirectory) corresponding to this File object.
boolean renameTo(File newName): renames the File or directory corresponding to the File object. If the renaming is successful, it returns true; Otherwise, false is returned.
2. Relevant methods of document detection
boolean exists(): judge whether the File or directory corresponding to the File object exists.
boolean canWrite(): judge whether the File and directory corresponding to the File object are writable.
boolean canRead(): judge whether the File and directory corresponding to the File object are readable.
boolean isFile(): judge whether the File object corresponds to a File rather than a directory.
boolean isDirectory(): judge whether the File object corresponds to a directory rather than a File.
boolean isAbsolute(): judge whether the File or directory corresponding to the File object is an absolute path. This method eliminates the differences between different platforms and can directly judge whether the File object is an absolute path. On UNIX/Linux/BSD and other systems, if the path name starts with a slash (/), it indicates that the File object corresponds to an absolute path; On Windows and other systems, if the path starts with a drive letter, it indicates that it is an absolute path.
3. Get general file information
long lastModified(): returns the last modified time of the file.
long length(): returns the length of the file content.
4. Methods related to file operation
boolean createNewFile(): when the File corresponding to the File object does not exist, this method will create a new File specified by the File object. If the creation is successful, it will return true; Otherwise, false is returned.
boolean delete(): deletes the File or path corresponding to the File object.
static File createTempFile(String prefix, String suffix): create a temporary empty File in the default temporary File directory, and use the given prefix, system generated random number and given suffix as the File name. This is a static method that can be called directly through the File class. The prefix parameter must be at least 3 bytes long. It is recommended to use a short, meaningful string for the prefix, such as "hjb" or "mail". The suffix parameter can be null, in which case the default suffix ". tmp" will be used.
static File createTempFile(String prefix, String suffix, File directory): create a temporary empty File in the directory specified by the directory, and use the given prefix, random number generated by the system and the given suffix as the File name. This is a static method that can be called directly through the File class.
void deleteOnExit(): register a deletion hook to delete the File and directory corresponding to the File object when the Java virtual machine exits.
5. Methods related to directory operation
boolean mkdir(): attempts to create a directory corresponding to a File object. If the creation is successful, it returns true; Otherwise, false is returned. When this method is called, the File object must correspond to a path, not a File.
String[] list(): lists all child File names and pathnames of the File object, and returns a String array.
File[] listFiles(): lists all child files and paths of the File object and returns the File array.
static File[] listRoots(): lists all root paths of the system. This is a static method that can be called directly through the File class.
the common methods of the File class are listed in detail above. The following program tests the function of the File class with several simple methods.
public class FileTest {
public static void main(String[] args)
throws IOException {
// Create a File object with the current path
File file = new File(".");
// Get the file name directly and output a little
System.out.println(file.getName());
// There may be an error getting the parent path of the relative path. The following code outputs null
System.out.println(file.getParent());
// Get absolute path
System.out.println(file.getAbsoluteFile());
// Get upper level path
System.out.println(file.getAbsoluteFile().getParent());
// Create a temporary file under the current path
File tmpFile = File.createTempFile("aaa", ".txt", file);
// Specifies that the file is deleted when the JVM exits
tmpFile.deleteOnExit();
// Create a new file with the current system time as the new file name
File newFile = new File(System.currentTimeMillis() + "");
System.out.println("newFile Object exists:" + newFile.exists());
// Creates a file by specifying the newFile object
newFile.createNewFile();
// Create a directory with the newFile object because the newFile already exists,
// Therefore, the following method returns false, that is, the directory cannot be created
newFile.mkdir();
// Use the list() method to list all files and paths under the current path
String[] fileList = file.list();
System.out.println("====All files and paths under the current path are as follows====");
assert fileList != null;
for (String fileName : fileList) {
System.out.println(fileName);
}
// The listRoots() static method lists all disk root paths.
File[] roots = File.listRoots();
System.out.println("====All root paths of the system are as follows====");
for (File root : roots) {
System.out.println(root);
}
}
}
when running the above program, you can see that when the program lists all files and paths of the current path, it lists the temporary files created by the program, but after the program runs, the aaa.txt temporary file does not exist, because the program specifies that the file will be deleted automatically when the virtual machine exits.
there is another point to note in the above program. When using System.out.println(file.getParent()); An error may be caused when obtaining the parent path relative to the File object of the path, because this method returns the result of deleting the directory name corresponding to the File object, the last subdirectory name in the File name, and the child File name.
1.2 document filter
you can receive a FilenameFilter parameter in the list() method of File class, which can list only qualified files. The function of the FilenameFilter interface here is very similar to that of the FileFilter abstract class under the javax.swing.filechooser package. FileFilter can be regarded as the implementation class of FilenameFilter.
the FilenameFilter interface contains an accept(File dir, String name) method, which will iterate over all subdirectories or files of the specified File in turn. If this method returns true, the list() method will list the subdirectories or files.
public class FilenameFilterTest {
public static void main(String[] args) {
File file = new File(".");
// There is only one abstract method in the FilenameFilter interface, so the interface is also a functional interface. You can use Lambda expressions to create objects that implement the interface.
// The file filter is implemented using a Lambda expression (the target type is FilenameFilter).
// If the file name ends in. java or the file corresponds to a path, return true
String[] nameList = file.list((dir, name) -> name.endsWith(".java") || new File(name).isDirectory());
assert nameList != null;
for (String name : nameList) {
System.out.println(name);
}
}
}
run the above program and you will see that all *. java files and folders under the current path are listed.
2. Understand the IO flow of Java
Java IO flow is the basis for realizing input / output. It can easily realize the input / output operation of data. In Java, different input / output sources (keyboard, file, network connection, etc.) are abstractly expressed as "stream", which allows Java programs to access different input / output sources in the same way. Stream is ordered data from source to sink.
Java puts all traditional stream types (classes or abstract classes) into the java.io package to realize input / output functions.
2.1 classification of flow
according to different classification methods, streams can be divided into different types. Below, streams are classified from different angles. They may overlap conceptually.
1. Input stream and output stream
according to the flow direction, it can be divided into input flow and output flow.
input stream: data can only be read from it, not written to it.
output stream: only data can be written to it, but data cannot be read from it.
the input stream of Java mainly uses InputStream and Reader as the base classes, while the output stream mainly uses OutputStream and Writer as the base classes. They are all abstract base classes and cannot create instances directly.
2. Byte stream and character stream
the usage of byte stream and character stream is almost the same. The difference is that the data unit operated by byte stream and character stream is different - the data unit operated by byte stream is 8-bit bytes, while the data unit operated by character stream is 16 bit characters.
byte stream is mainly based on InputStream and OutputStream, while character stream is mainly based on Reader and Writer.
3. Node flow and processing flow
according to the role of flow, it can be divided into node flow and processing flow.
the stream that can read / write data from / to a specific IO device (such as disk and network) is called node stream, and node stream is also called Low Level Stream. The following figure shows a schematic diagram of node flow.

as can be seen from the above figure, when using node flow for input / output, the program is directly connected to the actual data source and the actual input / output node.
processing stream is used to connect or encapsulate an existing stream, and realize data read / write function through the encapsulated stream. Processing flows are also called high-level flows. The following figure shows a schematic of the process flow.
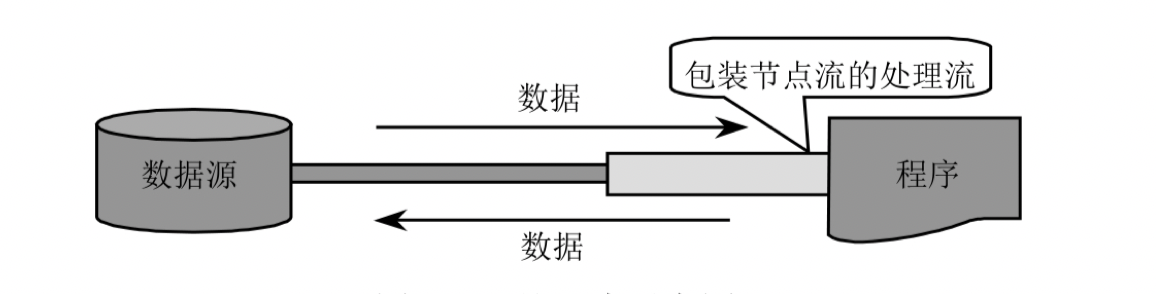
as can be seen from the above figure, when the processing flow is used for input / output, the program is not directly connected to the actual data source, and is not connected to the actual input / output node. An obvious advantage of using the processing flow is that as long as the same processing flow is used, the program can use the same input / output code to access different data sources. With the change of the node flow wrapped by the processing flow, the data sources actually accessed by the program will change accordingly.
in fact, Java uses processing flow to wrap node flow is a typical decorator design pattern. By using processing flow to wrap different node flows, we can not only eliminate the implementation differences of different node flows, but also provide more convenient methods to complete input / output functions. Therefore, the processing flow is also called wrapping flow.
2.2 conceptual model of flow
Java abstracts the ordered data in all devices into a stream model, simplifies input / output processing, and understands Java IO by understanding the conceptual model of stream.
Java's IO stream involves more than 40 classes. These classes look cluttered and messy, but they are actually very regular and closely related to each other. More than 40 classes of Java IO stream are derived from the following four abstract base classes.
InputStream/Reader: the base class of all input streams. The former is byte input stream and the latter is character input stream.
OutputStream/Writer: the base class of all output streams. The former is byte output stream and the latter is character output stream.
for InputStream and Reader, they abstract the input device into a "water pipe", and each "water drop" in the water pipe is arranged in turn, as shown in the figure below.
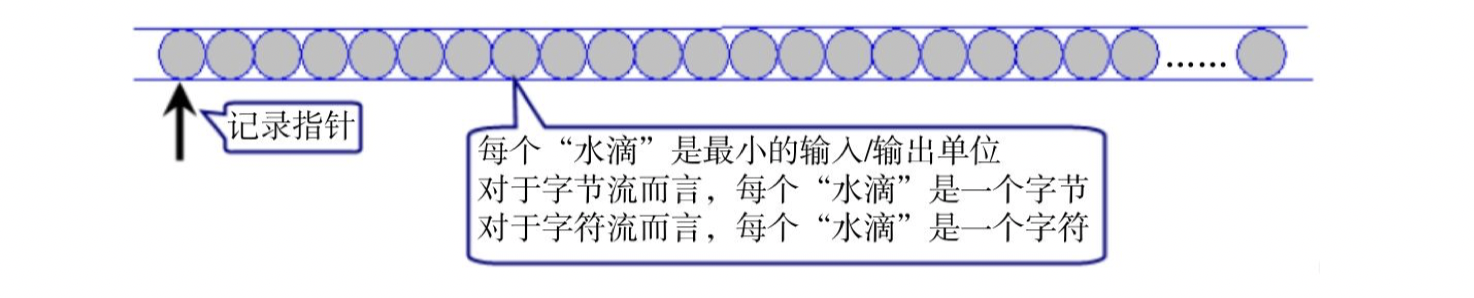
as can be seen from the above figure, the processing methods of byte stream and character stream are very similar, but their input / output units are different. The input stream uses an implicit recording pointer to indicate which "water drop" is currently being read from. Whenever the program takes out one or more "water drops" from InputStream or Reader, the recording pointer automatically moves backward; In addition, both InputStream and Reader provide some methods to control the movement of the record pointer.
for OutputStream and Writer, they also abstract the output device into a "water pipe", but there are no water droplets in the water pipe, as shown in the figure below.

as shown in the above figure, when executing the output, the program is equivalent to putting "water droplets" into the water pipe of the output stream in turn. The output stream also uses an implicit recording pointer to identify the position where the current water droplets will be put. Whenever the program outputs one or more water droplets to the OutputStream or Writer, the recording pointer automatically moves backward.
in addition to the basic conceptual model of Java IO flow, there is also Java processing flow. Java processing flow model reflects the flexibility of Java input / output flow design. The function of processing flow is mainly reflected in the following two aspects.
81.
convenience of operation: processing flow may provide a series of convenient methods to input / output large quantities of content at one time, rather than one or more "water droplets".
processing streams can be "grafted" on the basis of any existing stream, which allows Java applications to access the data streams of different input / output devices in the same code and transparent way. The following illustration shows a model of the process flow.
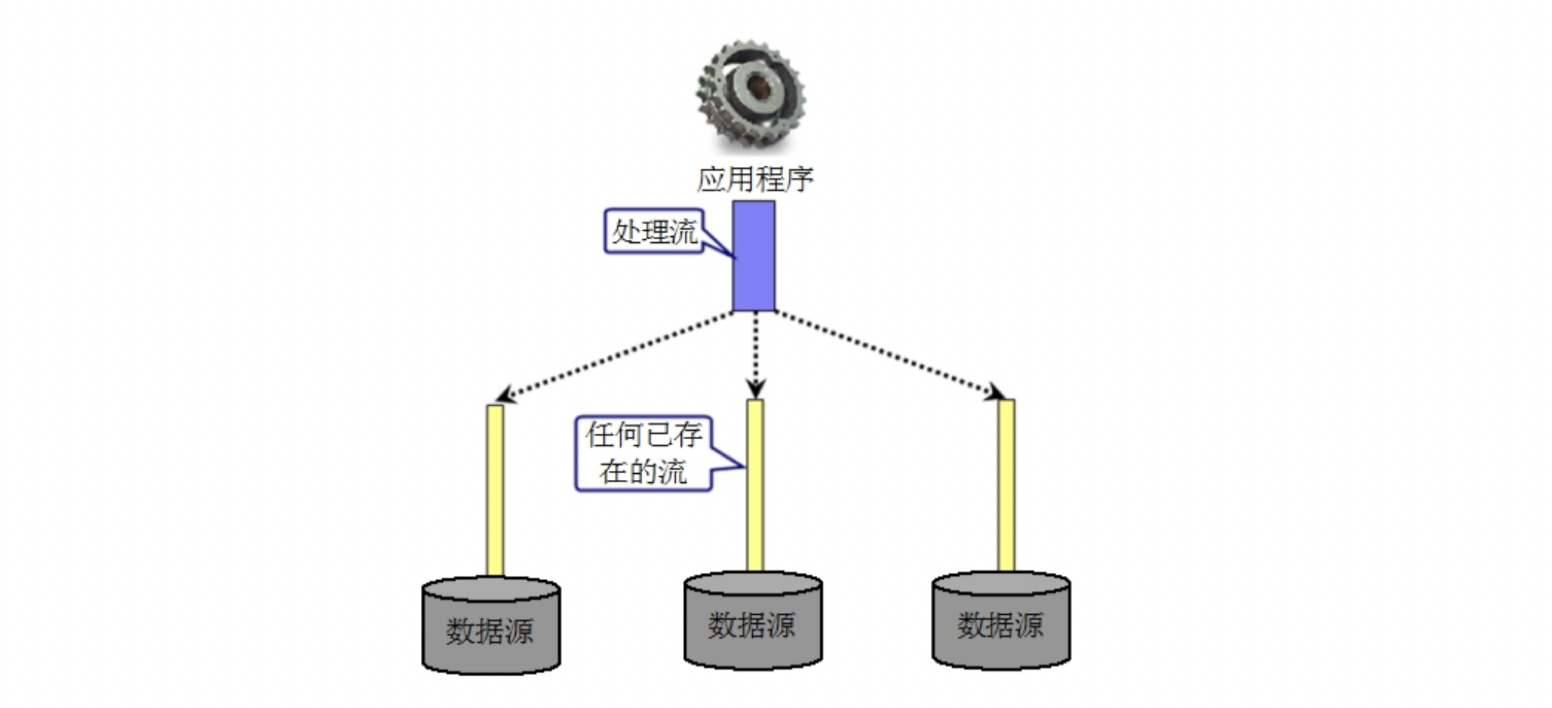
by using processing streams, Java programs do not care whether the input / output nodes are disks, networks or other input / output devices. As long as the program packages these node streams into processing streams, it can use the same input / output code to read and write data of different input / output devices.
3. Byte stream and character stream
3.1 InputStream and Reader
InputStream and Reader are abstract base classes for all input streams. They cannot create instances to execute input, but they will become templates for all input streams, so their methods are methods that can be used by all input streams.
the InputStream contains the following three methods.
int read(): read a single byte from the input stream (equivalent to taking a drop of water from the water pipe) and return the read byte data (byte data can be directly converted to int type).
.
. The Reader contains the following three methods.
the Reader contains the following three methods.
int read(): read a single character from the input stream (equivalent to taking a drop of water from the water pipe) and return the read character data (the character data can be directly converted to int type).
8195.
int read(char[] cbuf, int off, int len): read data with a maximum of len characters from the input stream and store it in the character array cbuf. When it is put into the array cbuf, it does not start from the starting point of the array, but from the off position to return the actual number of characters read.
comparing the methods provided by InputStream and Reader, it is not difficult to find that the functions of the two base classes are basically the same. InputStream and Reader abstract the input data into a water pipe as shown in the above figure, so the program can read one "water drop" at a time through the read() method, or read multiple "water drops" through the read(char[]cbuf) or read(byte[] b) method. When the array is used as the parameter of the read() method, it can be understood as using a "bamboo tube" to take water from the water pipe shown in Figure 15.5, as shown in the figure below. The array in the read(char[]cbuf) method can be understood as a "bamboo tube". Every time the program calls the read(char[]cbuf) or read(byte[] b) method of the input stream, it is equivalent to taking a barrel of "water droplets" from the input stream with the "bamboo tube". After the program obtains the "water droplets" in the "bamboo tube", it can be converted into corresponding data; The program repeats this "water intake" process many times until the end. How does the program judge that the water has been taken to the end? Until the read(char[]cbuf) or read(byte[] b) method returns − 1, it indicates that the end point of the input stream has been reached.

as mentioned earlier, InputStream and Reader are abstract classes and cannot create instances themselves, but they have an input stream for reading files: FileInputStream and FileReader, which are node streams - and will be directly associated with the specified file. The following program demonstrates the effect of using FileInputStream to read itself.
public class FileInputStreamTest {
public static void main(String[] args) throws IOException {
// Create byte input stream
InputStream fis = new FileInputStream("./java-base/src/main/java/com/yt/base/test/FileInputStreamTest.java");
// Create a "bamboo tube" with a length of 1024
byte[] bbuf = new byte[1024];
// The number of bytes used to hold the actual read
int hasRead = 0;
// Use the cycle to repeat the "water intake" process
while ((hasRead = fis.read(bbuf)) > 0) {
// Take out the water drops (bytes) in the "bamboo tube", and convert the byte array into a string input!
System.out.print(new String(bbuf, 0, hasRead));
}
// It is safer to close the file input stream and put it in the finally block
fis.close();
}
}
the above program creates a 1024 byte array to read the file. In fact, the length of the Java source file is less than 1024 bytes, that is, the program only needs to execute the read () method once to read all the contents. However, if a small byte array is created, garbled code may appear when outputting Chinese comments when the program runs - this is because the UTF-8 encoding method is adopted when saving this file. In this way, one Chinese is equal to three bytes. If the read() method reads only half a Chinese character, garbled code will be caused.
the above program finally uses fis.close() to close the file input stream. Like JDBC programming, the file IO resource opened in the program does not belong to the resource in memory, and the garbage collection mechanism cannot recover the resource, so the file IO resource should be explicitly closed. Java 7 rewrites all IO resource classes. They all implement the autoclosable interface. Therefore, these IO streams can be closed by automatically closing the try statement of resources. The following program uses FileReader to read the file itself.
public class FileReaderTest {
public static void main(String[] args) {
// Create character input stream
try (Reader fr = new FileReader("FileReaderTest.java")) {
// Create a "bamboo tube" with a length of 32
char[] cbuf = new char[32];
// Used to save the number of characters actually read
int hasRead = 0;
// Use the cycle to repeat the "water intake" process
while ((hasRead = fr.read(cbuf)) > 0) {
// Take out the water drops (characters) in the "bamboo tube", and convert the character array into a string input!
System.out.print(new String(cbuf, 0, hasRead));
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
the FileReaderTest.java program above is not much different from the FileInputStreamTest.java program above. The program only changes the length of the character array to 32, which means that the program needs to call the read() method many times to fully read all the data of the input stream. Finally, the program uses the try statement of automatically closing resources to close the file input stream, which can ensure that the input stream will be closed.
in addition, InputStream and Reader also support the following methods to move the record pointer.
void mark(int readAheadLimit): record a mark at the current position of the record pointer.
boolean markSupported(): judge whether this input stream supports mark() operation, that is, whether it supports record marks.
Зvoid reset(): reposition the record pointer of this stream to the position of the last record mark.
long skip(long n): the record pointer moves forward n bytes / characters.
3.2. OutputStream and Writer
OutputStream and Writer are also very similar. Both streams provide the following three methods.
void write(int c): outputs the specified byte / character to the output stream, where C can represent both bytes and characters.
void write(byte[]/char[] buf): outputs the data in byte array / character array to the specified output stream.
Зvoid write(byte[]/char[] buf, int off, int len): outputs bytes / characters of length len from byte array / character array to output stream.
because the character stream directly takes the character as the operation unit, the Writer can replace the character array with a String, that is, take the String object as the parameter. The Writer also contains the following two methods.
void write(String str): outputs the characters contained in the str string to the specified output stream.
void write(String str, int off, int len): outputs the characters in the str string with the length of len starting from the off position to the specified output stream.
the following program uses FileInputStream to execute input and FileOutputStream to execute output to realize the function of copying FileOutputStreamTest.java file.
public class FileOutputStreamTest {
public static void main(String[] args) {
try (
// Create byte input stream
InputStream fis = new FileInputStream("./java-base/src/main/java/com/yt/base/test/FileOutputStreamTest.java");
// Create byte output stream
OutputStream fos = new FileOutputStream("./java-base/src/main/java/com/yt/base/test/newFile.txt")
) {
byte[] bbuf = new byte[32];
int hasRead = 0;
// Loop fetches data from the input stream
while ((hasRead = fis.read(bbuf)) > 0) {
// Each read, that is, write to the file output stream. Write as much as you read.
fos.write(bbuf, 0, hasRead);
}
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
run the above program and you will see that there is an additional file in the current path of the system: newFile.txt. The content of this file is exactly the same as that of FileOutputStreamTest.java file.
when using the Java IO stream to execute output, don't forget to close the output stream. Closing the output stream can not only ensure that the physical resources of the stream are recycled, but also flush the data in the output stream buffer to the physical node (because the flush() method of the output stream is automatically executed before the close() method is executed). Many output streams of Java provide buffering by default. In fact, there is no need to deliberately remember which streams have buffering function and which streams do not. As long as all output streams are closed normally, the program can be normal.
if you want to directly output the string content, using Writer will have better results, as shown in the following program.
public class FileWriterTest {
public static void main(String[] args) {
try (Writer fw = new FileWriter("./java-base/src/main/java/com/yt/base/test/poem.txt")) {
fw.write("The Richly Painted Zither - Li Shangyin\r\n");
fw.write("There are fifty strings in a beautiful harp without any reason. One string and one column miss the year of China.\r\n");
fw.write("Zhuangsheng Xiaomeng is fascinated by butterflies and hopes the emperor's spring heart holds cuckoos.\r\n");
fw.write("The moon pearl in the sea has tears, the sun in the blue field is warm, and the jade gives birth to smoke.\r\n");
fw.write("This situation can be recalled, but it was at a loss at that time.\r\n");
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
run the above program, and a poem.txt file will be output in the current directory. The content of the file is the content output from the program.
when the above program outputs the string content, the last of the string content is \ r\n, which is the line feed character of Windows platform. In this way, the output content can be wrapped; If it is a UNIX/Linux/BSD platform, use \ n as the newline character.
4. Input / output flow system
4.1 usage of processing flow
processing flow can hide the difference of node flow on the underlying device and provide more convenient input / output methods, so that programmers only need to care about the operation of high-level flow.
the typical idea when using the processing flow is to use the processing flow to wrap the node flow, and the program uses the processing flow to execute the input / output function, so that the node flow interacts with the underlying I/O devices and files.
it is very simple to actually identify the processing flow. As long as the constructor parameter of the flow is not a physical node, but an existing flow, this flow must be a processing flow; All node flows directly take physical IO nodes as constructor parameters.
the advantages of using processing flow can be summarized into two points: ① it is easier for developers to use processing flow for input / output operations; ② The execution efficiency is higher by using processing flow.
the following program uses the PrintStream processing stream to wrap the OutputStream. The output stream after using the processing stream will be more convenient when outputting.
public class PrintStreamTest {
public static void main(String[] args) {
try (
OutputStream fos = new FileOutputStream("./java-base/src/main/java/com/yt/base/test/test.txt");
PrintStream ps = new PrintStream(fos)
) {
// Performing output using PrintStream
ps.println("Normal string");
// Output objects directly using PrintStream
ps.println(new PrintStreamTest());
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
the code in the above program first defines a node output stream FileOutputStream, then the program uses Print Stream to wrap the node output stream, and finally uses PrintStream to output string and output object... The output function of PrintStream is very powerful. The type of standard output System.out used in the previous program is PrintStream. PrintStream class has very powerful output function. Generally, if you need to output text content, you should wrap the output stream into PrintStream for output.
as can be seen from the above code, it is very simple for the program to use the processing flow. Usually, you only need to pass in a node flow as the constructor parameter when creating the processing flow. In this way, the created processing flow is the processing flow that wraps the node flow.
after wrapping the bottom node stream with the processing stream, when closing the input / output stream resources, just close the top processing stream. When closing the top-level processing flow, the system will automatically close the node flow wrapped by the processing flow. It should also be noted that the closing sequence is: use first and then close.
4.2 input / output flow system
Java's input / output stream system provides nearly 40 classes. These classes look messy and irregular, but if they are classified by function, it is not difficult to find that they are very regular. The following chart shows the stream classification commonly used in the Java input / output stream system.
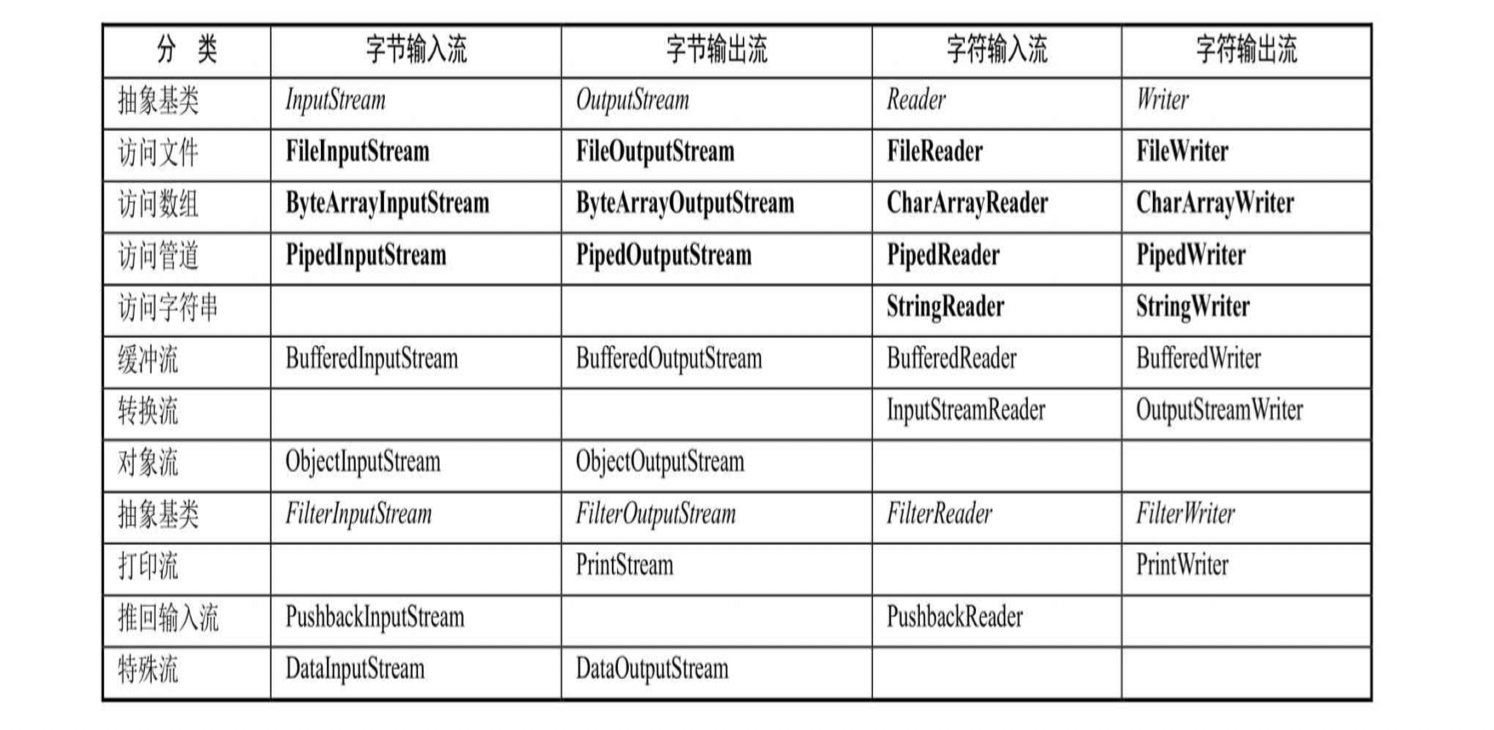
the class marked in bold in the above table represents the node flow and must be directly associated with the specified physical node; The classes marked in italics represent abstract base classes, and instances cannot be created directly.
the above table lists four streams accessing the pipeline: PipedInputStream, PipedOutputStream, PipedReader and PipedWriter, which are used to realize the communication function between processes, namely byte input stream, byte output stream, character input stream and character output stream.
the four buffer streams in the above table add the buffer function. Adding the buffer function can improve the efficiency of input and output. After adding the buffer function, you need to use flush() to write the contents of the buffer to the actual physical node.
the object stream in the above table is mainly used to serialize objects.
generally speaking, the function of byte stream is more powerful than that of character stream, because all data in the computer is binary, and byte stream can process all binary files - but the problem is that if byte stream is used to process text files, these bytes need to be converted into characters in an appropriate way, which increases the complexity of programming. Therefore, there is usually a rule: if the input / output content is text content, character stream should be considered; If the input / output content is binary content, you should consider using byte stream.
the above table only summarizes the streams under the java.io package in the input / output stream system, as well as some byte streams with the functions of accessing audio files, encryption / decryption, compression / decompression, such as AudioInputStream, CipherInputStream, DeflaterInputStream and ZipInputStream. They have special functions and are located under other packages of JDK.
the above table also lists a node stream with array as physical node, byte stream with byte array as node and character stream with character array as node; This kind of node flow with array as physical node is completely similar to file node flow in usage, except that a byte array or character array needs to be passed in when creating node flow object. Similarly, a character stream can also use a string as a physical node to read content from a string or write content to a string (using StringBuffer as a string). The following program demonstrates the use of character input / output streams using strings as physical nodes.
public class StringNodeTest {
public static void main(String[] args) {
String src = "From tomorrow on, be a happy person\n"
+ "Feed horses, chop firewood and travel around the world\n"
+ "From tomorrow on, care about food and vegetables\n"
+ "I have a house that faces the sea and flowers bloom in spring\n"
+ "From tomorrow on, communicate with every relative\n"
+ "Tell them my happiness\n";
char[] buffer = new char[32];
int hasRead = 0;
try (
Reader sr = new StringReader(src)
) {
// Read string with circular read access
while ((hasRead = sr.read(buffer)) > 0) {
System.out.print(new String(buffer, 0, hasRead));
}
} catch (IOException ioe) {
ioe.printStackTrace();
}
try (
// When creating a StringWriter, it actually takes a StringBuffer as the output node
// The 20 specified below is the initial length of StringBuffer
Writer sw = new StringWriter(20)
) {
// Call the method of StringWriter to execute the output
sw.write("There is a beautiful new world,\n");
sw.write("She is waiting for me in the distance,\n");
sw.write("There are innocent children there,\n");
sw.write("And the girl's dimple\n");
System.out.println("----Here is sw The contents of the string node----");
// Use the toString() method to return the contents of the string node of the StringWriter
System.out.println(sw.toString());
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
the above program is basically similar to the previous programs using FileReader and FileWriter, except that when creating StringReader and StringWriter objects, the String node is passed in instead of the file node. Because String is an immutable String object, StringWriter uses StringBuffer as the output node.
4.3 conversion flow
the input / output stream system also provides two conversion streams, which are used to convert byte streams into character streams. InputStreamReader converts byte input streams into character input streams, and OutputStreamWriter converts byte output streams into character output streams.
next, take obtaining keyboard input as an example to introduce the usage of conversion stream. Java uses System.in to represent standard input, that is, keyboard input, but this standard input stream is an instance of InputStream class, which is inconvenient to use, and the keyboard input content is text content, so it can be converted into character input stream by InputStreamReader, which is still inconvenient for ordinary readers to read the input content, Ordinary readers can be wrapped in BufferedReader again, and one line of content can be read at a time by using the readLine() method of BufferedReader. The following procedure is shown.
public class KeyinTest {
public static void main(String[] args) {
try (
// Convert Sytem.in object to Reader object
InputStreamReader reader = new InputStreamReader(System.in);
// Wrap a normal Reader into a BufferedReader
BufferedReader br = new BufferedReader(reader)
) {
String line = null;
// Read line by line in a circular manner
while ((line = br.readLine()) != null) {
// If the read string is "exit", the program exits
if (line.equals("exit")) {
System.exit(1);
}
// Print read content
System.out.println("The input content is:" + line);
}
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
4.4 push back the input stream
in the input / output stream system, there are two special streams that are different, namely PushbackInputStream and PushbackReader. They both provide the following three methods.
void unread(byte[]/char[] buf): pushes the contents of a byte / character array back to the push back buffer, allowing repeated reading of the contents just read.
void unread(byte[]/char[] b, int off, int len): push back the contents of a byte / character array with a length of len bytes / characters from off to the push back buffer, so as to allow repeated reading of the contents just read.
void unread(int b): push a byte / character back into the buffer, allowing repeated reading of the content just read.
careful readers may have found that these three methods correspond to the three read() methods in InputStream and Reader one by one. Yes, these three methods are the mystery of PushbackInputStream and PushbackReader.
both push back input streams have a push back buffer. When the program calls the unread() method of the two push back input streams, the system will push back the contents of the specified array into the buffer. When the push back input stream calls the read() method, it will always read from the push back buffer first. Only after the contents of the push back buffer are completely read, However, it is not read from the original input stream until the array required by read () is full. The following figure shows the processing diagram of this push back input stream.
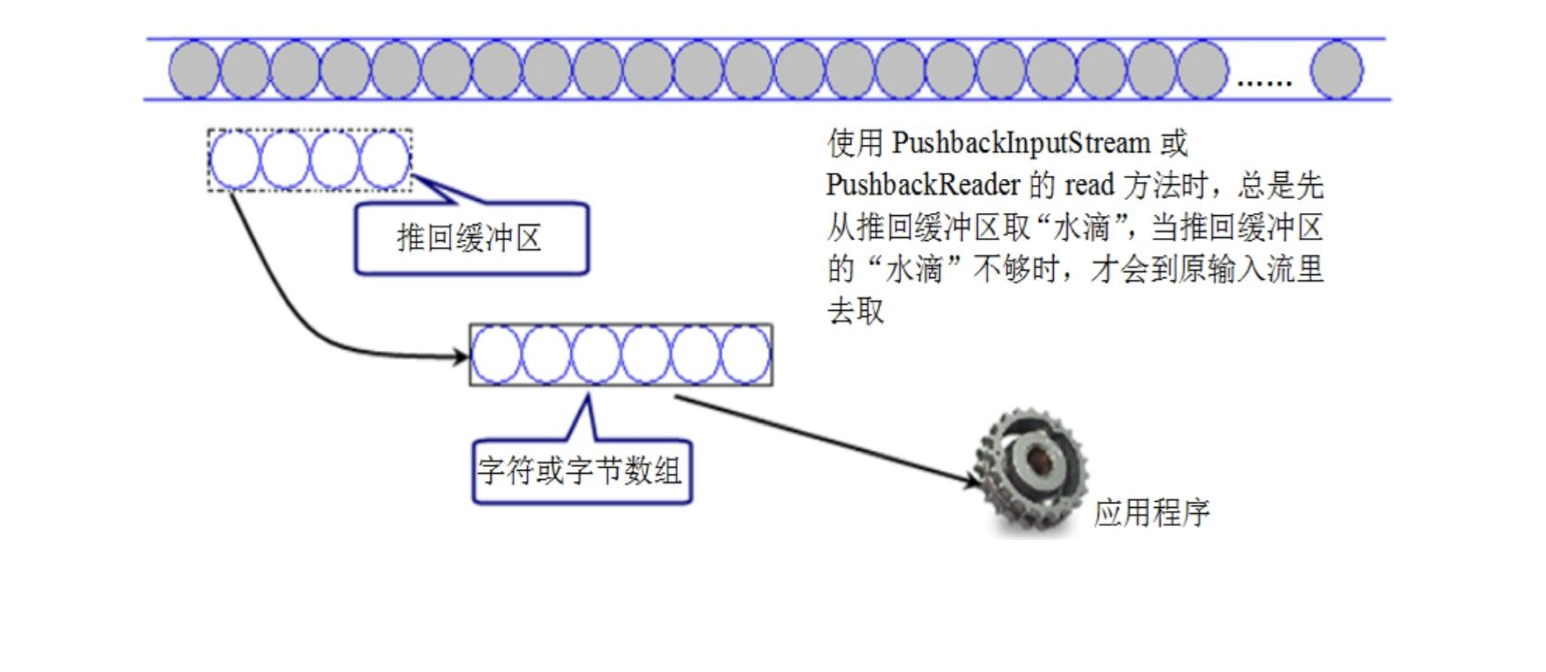
according to the above introduction, when the program creates a PushbackInputStream and PushbackReader, it needs to specify the size of the push back buffer. The default length of the push back buffer is 1. If the contents of the push back buffer in the program exceed the size of the push back buffer, an IOException of Pushback buffer overflow will be thrown.
the following program tries to find the "new PushbackReader" string in the program. When the string is found, the program just prints the content before the target string.
public class PushbackTest {
public static void main(String[] args) {
try (
// Create a PushbackReader object and specify that the length of the push back buffer is 64
PushbackReader pr = new PushbackReader(new FileReader("./java-base/src/main/java/com/yt/base/test/PushbackTest.java"), 64)
) {
char[] buf = new char[32];
// Used to save the last read string content
String lastContent = "";
int hasRead = 0;
// Loop reading file contents
while ((hasRead = pr.read(buf)) > 0) {
// Converts the read content into a string
String content = new String(buf, 0, hasRead);
int targetIndex = 0;
// Spell the string read last time with the string read this time,
// Check whether the target string is included. If yes, the target string is included
if ((targetIndex = (lastContent + content).indexOf("new PushbackReader")) > 0) {
// Push the current content back to the buffer together with the last content
pr.unread((lastContent + content).toCharArray());
// Redefine a char array with length of targetIndex
if (targetIndex > 32) {
buf = new char[targetIndex];
}
// Read the content of the specified length again (that is, the content before the target string)
pr.read(buf, 0, targetIndex);
// Print read content
System.out.print(new String(buf, 0, targetIndex));
System.exit(0);
} else {
// Print last read
System.out.print(lastContent);
// Set the current content as the last read content
lastContent = content;
}
}
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
the code in the above program pushes the specified content back to the push back buffer. Therefore, when the program calls the read() method again, it actually only reads part of the contents of the push back buffer, thus realizing the function of printing only the contents in front of the target string.
5. Redirect standard I / O
the System class provides the following three methods to redirect standard I / O.
static void setErr(PrintStream err): redirect the "standard" error output stream.
≯ static void setIn(InputStream in): redirect the "standard" input stream.
static void setOut(PrintStream out): redirect the "standard" output stream.
the following program redirects the output of System.out to file output instead of output on the screen by redirecting the standard output stream.
public class RedirectOut {
public static void main(String[] args) {
try (
// Create PrintStream output stream at one time
PrintStream ps = new PrintStream(new FileOutputStream("./java-base/src/main/java/com/yt/base/test/out.txt"))
) {
// Redirect standard output to ps output stream
System.setOut(ps);
// Outputs a string to standard output
System.out.println("Normal string");
// Export an object to standard output
System.out.println(new RedirectOut());
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
the above program code creates a PrintStream output stream and redirects the standard output of the system to the Print Stream output stream. When you run the above program, you won't see any output -- this means that the standard output is no longer output to the screen, but to the out.txt file.
the following program redirects standard input so that System.in can be redirected to the specified file instead of keyboard input.
public class RedirectIn {
public static void main(String[] args) {
try (
FileInputStream fis = new FileInputStream("./java-base/src/main/java/com/yt/base/test/RedirectIn.java")
) {
// Redirect standard input to fis input stream
System.setIn(fis);
// Create a Scanner object using System.in to get standard input
Scanner sc = new Scanner(System.in);
// Add the following line with carriage return as the separator only
sc.useDelimiter("\n");
// Determine whether there is another input item
while (sc.hasNext()) {
// Output input
System.out.println("The keyboard input is:" + sc.next());
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
the code in the above program creates a FileInputStream input stream and redirects the System standard input to the file input stream using the setIn() method of System. When running the above program, the program will not wait for user input, but directly output the contents of RedirectIn.java file, which indicates that the program no longer uses the keyboard as standard input, but uses RedirectIn.java file as standard input source.
5,RandomAccessFile
RandomAccessFile is the most versatile file content access class in the Java input / output stream system. It provides many methods to access the file content. It can read the file content or output data to the file. Different from ordinary input / output streams, RandomAccessFile supports "random access", and the program can directly jump to any place of the file to read and write data.
since RandomAccessFile can freely access any location of the file, if you only need to access part of the file instead of reading the file from beginning to end, RandomAccessFile will be a better choice.
different from output streams such as OutputStream and Writer, RandomAccessFile allows free positioning of file record pointers. RandomAccessFile can output without starting from the beginning. Therefore, RandomAccessFile can add content to the existing file. If the program needs to append content to an existing file, RandomAccessFile should be used.
Although RandomAccessFile has many methods, its biggest limitation is that it can only read and write files, not other IO nodes.
the RandomAccessFile object also contains a record pointer to identify the current reading and writing position. When the program creates a new RandomAccessFile object, the file record pointer of the object is located in the file header (i.e. 0). When bytes are read / written, the file record pointer will move backward by bytes. In addition, RandomAccessFile can move the record pointer freely, either forward or backward. RandomAccessFile contains the following two methods to manipulate the file record pointer.
long getFilePointer(): returns the current position of the file record pointer.
void seek(long pos): locate the file record pointer to the pos position.
RandomAccessFile can read or write files, so it contains three read() methods completely similar to InputStream, and its usage is exactly the same as that of InputStream; It also contains three write() methods that are completely similar to OutputStream, and their usage is exactly the same as the three write() methods of OutputStream. In addition, RandomAccessFile also contains a series of readXxx() and writeXxx() methods to complete input and output.
RandomAccessFile class has two constructors. In fact, the two constructors are basically the same, but the form of specifying the File is different - one uses String parameter to specify the File name, and the other uses File parameter to specify the File itself. In addition, when creating RandomAccessFile object, you also need to specify a mode parameter, which specifies the access mode of RandomAccessFile. This parameter has the following four values.
"r": opens the specified file as read-only. If you try to execute a write method on the RandomAccessFile, you will throw an IOException.
"rw": open the specified file in read and write mode. If the file does not already exist, try creating it.
"rws": open the specified file in read and write mode. Compared with "rw" mode, it also requires that each update of file content or metadata be synchronously written to the underlying storage device.
"rwd": open the specified file in read and write mode. Compared with "rw" mode, it is also required that each update of file content is synchronously written to the underlying storage device.
the following program uses RandomAccessFile to access the specified middle part data.
public class RandomAccessFileTest {
public static void main(String[] args) {
try (
RandomAccessFile raf = new RandomAccessFile("./java-base/src/main/java/com/yt/base/test/RandomAccessFileTest.java", "r")
) {
// Gets the position of the RandomAccessFile object file pointer. The initial position is 0
System.out.println("RandomAccessFile Initial position of file pointer:" + raf.getFilePointer());
// 2 - move the position of the file record pointer of raf
raf.seek(300);
byte[] bbuf = new byte[1024];
// The number of bytes used to hold the actual read
int hasRead = 0;
// Use the cycle to repeat the "water intake" process
while ((hasRead = raf.read(bbuf)) > 0) {
// Take out the water drops (bytes) in the "bamboo tube", and convert the byte array into a string input!
System.out.print(new String(bbuf, 0, hasRead));
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
the first line of code in the above program creates a RandomAccessFile object, which opens the RandomAccessFileTest.java file in read-only mode, which means that the RandomAccessFile object can only read the file content and cannot write.
the second word code in the program locates the file record pointer to 300, that is, the program will read and write from 300 bytes. The next part of the program is not much different from reading with InputStream. Run the above program, you will see the effect that the program only reads the later part.
the following program demonstrates how to add content to the specified file. In order to add content, the program should first move the record pointer to the end of the file, and then start outputting content to the file.
public class AppendContent {
public static void main(String[] args) {
try (
// 1 -- open a RandomAccessFile object in read and write mode
RandomAccessFile raf = new RandomAccessFile("./java-base/src/main/java/com/yt/base/test/out.txt", "rw")
) {
// 2 -- move the record pointer to the end of the out.txt file
raf.seek(raf.length());
raf.write("Additional content!\r\n".getBytes());
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
the first code in the above program creates a RandomAccessFile object by reading and writing, and the second code moves the record pointer of the RandomAccessFile object to the end; Next, using RandomAccessFile to perform output is not much different from using OutputStream or Writer to perform output.
every time you run the above program, you can see an additional line of "additional content!" string in the out.txt file. The program uses "\ r\n" after the string to control line feed.
RandomAccessFile still cannot insert content into the specified position of the file. If you directly move the file record pointer to the middle position and start output, the newly output content will overwrite the original content in the file. If you need to insert content into the specified location, the program needs to first read the content behind the insertion point into the buffer, write the data to be inserted into the file, and then append the content of the buffer to the file.
the following program example implements the function of inserting content into the specified file and location.
public class InsertContent {
public static void insert(String fileName, long pos, String insertContent) throws IOException {
// Create temporary file
File tmp = File.createTempFile("tmp", null);
tmp.deleteOnExit();
try (
RandomAccessFile raf = new RandomAccessFile(fileName, "rw");
// Use a temporary file to save the data after the insertion point
FileOutputStream tmpOut = new FileOutputStream(tmp);
FileInputStream tmpIn = new FileInputStream(tmp)
) {
raf.seek(pos);
// ------The following code reads the content after the insertion point into a temporary file and saves it------
byte[] bbuf = new byte[64];
// The number of bytes used to hold the actual read
int hasRead = 0;
// Read the data after the insertion point in a circular manner
while ((hasRead = raf.read(bbuf)) > 0) {
// Writes the read data to a temporary file
tmpOut.write(bbuf, 0, hasRead);
}
// ----------The following code inserts the content----------
// Reposition the file record pointer to the pos position
raf.seek(pos);
// Append content to be inserted
raf.write(insertContent.getBytes());
// Append contents in temporary file
while ((hasRead = tmpIn.read(bbuf)) > 0) {
raf.write(bbuf, 0, hasRead);
}
}
}
public static void main(String[] args) throws IOException {
insert("./java-base/src/main/java/com/yt/base/test/InsertContent.java", 45, "Inserted content\r\n");
}
}
the network download tools of multi-threaded breakpoints (such as FlashGet) can be implemented through the RandomAccessFile class. All download tools will create two files at the beginning of download: one is an empty file with the same size as the downloaded file, and the other is a file recording the location of the file pointer. The download tool starts the input stream with multiple threads to read network data, And use RandomAccessFile to write the data read from the network into the previously established empty file. After writing some data, the file recording the file pointer will record the current file pointer position of each RandomAccessFile respectively - when downloading again after the network is disconnected, Each RandomAccessFile continues to write data down according to the position recorded in the file recording the file pointer.
6. Object serialization
the goal of object serialization is to save the object to disk or allow the object to be transferred directly over the network. The object serialization mechanism allows Java objects in memory to be converted into platform independent binary streams, which allows this binary stream to be permanently stored on disk and transmitted to another network node through the network. Once other programs have obtained this binary stream (whether obtained from disk or through the network), they can restore this binary stream to the original Java object.
6.1 meaning and significance of serialization
the serialization mechanism allows Java objects that implement serialization to be converted into byte sequences, which can be saved on disk or transmitted over the network for later restoration to the original objects. The serialization mechanism allows objects to exist independently of the program.
serializing an object refers to writing a Java object into the IO stream. Correspondingly, deserializing an object refers to recovering the Java object from the IO stream.
Java 9 enhances the object serialization mechanism, which allows filtering of read serialized data. This filtering can verify the data before deserialization, so as to improve security and robustness.
if you need an object to support serialization, you must make its class serializable. In order for a class to be serializable, the class must implement one of the following two interfaces.
➢ Serializable
➢ Externalizable
many classes in Java have implemented Serializable. This interface is a tag interface. There is no need to implement any method to implement this interface. It only indicates that the instance of this class is Serializable.
all classes of objects that may be transmitted on the network should be serializable, otherwise the program will encounter exceptions, such as parameters and return values in RMI (Remote Method Invoke, which is the basis of Java EE); All classes of objects that need to be saved to disk must be serializable, such as Java objects that need to be saved to HttpSession or ServletContext attribute in Web applications.
because serialization is a mechanism that must be implemented for both parameters and return values of RMI process, and RMI is the basis of Java EE technology - all distributed applications often need to cross platforms and networks, so it is required that all passed parameters and return values must be serialized. Therefore, serialization mechanism is the basis of Java EE platform. It is generally recommended that each JavaBean class created by the program implement Serializable.
6.2. Serialization using object stream
the following program defines a Person class. This Person class is an ordinary Java class, which only implements the Serializable interface, which identifies that the object of this class is Serializable.
public class Person implements Serializable {
private String name;
private int age;
// Note that no parameterless constructor is provided here!
public Person(String name, int age) {
System.out.println("Constructor with parameters");
this.name = name;
this.age = age;
}
// name's setter and getter methods
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
// setter and getter methods of age
public void setAge(int age) {
this.age = age;
}
public int getAge() {
return this.age;
}
}
the following program uses ObjectOutputStream to write a Person object to a disk file.
public class WriteObject {
public static void main(String[] args) {
try (
// Create an ObjectOutputStream output stream
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./java-base/src/main/java/com/yt/base/test/serializable/object.txt"))
) {
Person per = new Person("Sun WuKong", 500);
// Write per object to output stream
oos.writeObject(per);
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
in the above program, an ObjectOutputStream output stream is created, which is based on a file output stream; Then use the writeObject() method to write a Person object to the output stream. Run the above program, you will see that an object.txt file is generated, and the content of this file is the Person object.
if you want to recover Java objects from binary streams, you need to use deserialization. The steps of deserialization are as follows. The following program demonstrates the steps of reading the Person object from the just generated object.txt file.
public class ReadObject {
public static void main(String[] args) {
try (
// Create an ObjectInputStream input stream
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("./java-base/src/main/java/com/yt/base/test/serializable/object.txt"))
) {
// Read a Java object from the input stream and cast it to the Person class
Person p = (Person) ois.readObject();
System.out.println("The name is:" + p.getName() + "\n Age:" + p.getAge());
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
the above program wraps a file input stream into an ObjectInputStream input stream, and then uses readObject() to read the Java object in the file, which completes the deserialization process.
it must be pointed out that deserialization only reads the data of Java objects, not Java classes. Therefore, when using deserialization to recover Java objects, you must provide the class file of the class to which the Java object belongs, otherwise ClassNotFoundException will be thrown.
there is another point to point out: the Person class has only one constructor with parameters, no constructor without parameters, and there is an ordinary print statement in the constructor. When deserialization reads a Java object, it does not see the program calling the constructor, which indicates that the deserialization mechanism does not need to initialize the Java object through the constructor.
if multiple Java objects are written to the file using the serialization mechanism, the objects must be read in the order actually written when they are recovered using the deserialization mechanism.
when a serializable class has multiple parent classes (including direct and indirect parent classes), these parent classes either have parameterless constructors or are serializable -- otherwise, InvalidClassException will be thrown during deserialization. If the parent class is non serializable and only has a parameterless constructor, the member variable values defined in the parent class will not be serialized into the binary stream.
6.3. Serialization of object references
the two member variables of the Person class described above are String type and int type respectively. If the type of the member variable of a class is not a basic type or String type, but another reference type, the reference class must be serializable, otherwise the class with the member variable of this type is also not serializable.
the following Teacher class holds a reference to the Person class. Only the Person class is serializable, the Teacher class is serializable. If the Person class is not serializable, the Teacher class is not serializable regardless of whether the Teacher class implements the serializable and Externalizable interfaces.
public class Teacher implements Serializable {
private String name;
private Person student;
public Teacher(String name, Person student) {
this.name = name;
this.student = student;
}
// The setter and getter methods of name and student are omitted here
// name's setter and getter methods
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
// student's setter and getter methods
public void setStudent(Person student) {
this.student = student;
}
public Person getStudent() {
return this.student;
}
}
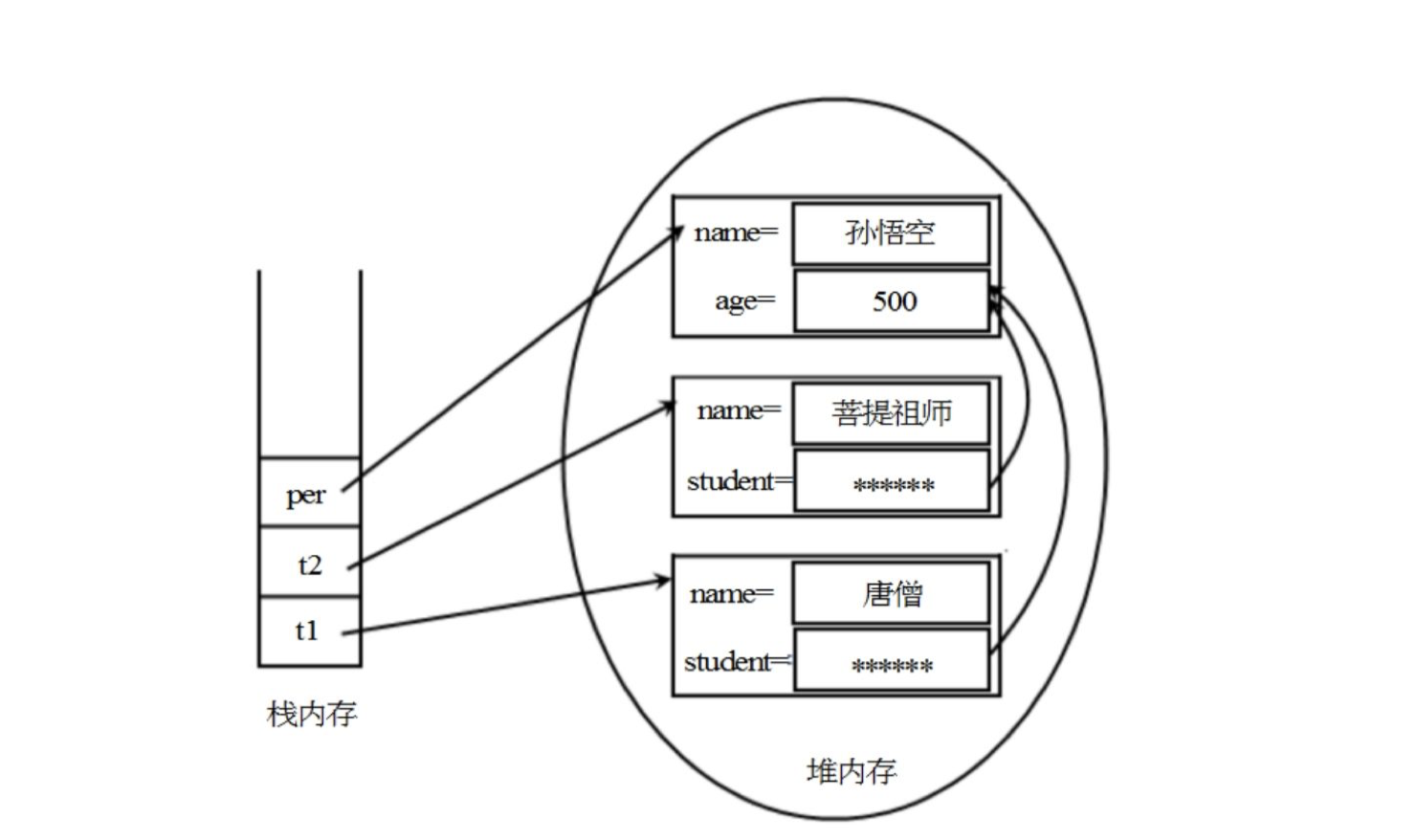
now suppose there is a special case as follows: there are two Teacher objects in the program, their student instance variables refer to the same Person object, and the Person object also has a reference variable to refer to it. The code is as follows:
Person per = new Person("Sun WuKong", 500);
Teacher t1 = new Teacher("Tang Monk", per);
Teacher t2 = new Teacher("master puti ", per);
the above code creates two Teacher objects and one Person object. The storage diagram of these three objects in memory is shown in the figure below.
a problem arises here - if the t1 object is serialized first, the system serializes the Person object referenced by the t1 object together; If the program serializes the t2 object again, the system will also serialize the t2 object, and the Person object referenced by the t2 object will be serialized again; If the program explicitly serializes the per object again, the system serializes the Person object again. This process seems to output three Person objects to the output stream.
if the system writes three Person objects to the output stream, the consequence is that when the program deserializes these objects from the input stream, it will get three Person objects, resulting in that the Person objects referenced by t1 and t2 are not the same object, which is obviously inconsistent with the effect shown in the above figure - which is contrary to the original intention of Java serialization mechanism.
therefore, the Java serialization mechanism adopts a special serialization algorithm, which is as follows.
all objects saved to disk have a serialization number.
when the program attempts to serialize an object, the program will first check whether the object has been serialized. Only if the object has never been serialized (in this virtual machine), the system will convert the object into a byte sequence and output it.
if an object has been serialized, the program will just output a serialization number directly instead of re serializing the object again.
according to the above serialization algorithm, we can draw a conclusion - when serializing the Person object for the second and third time, the program will not convert the Person object into a byte sequence and output it again, but only output a serialization number. Suppose there are serialization codes in the following order:
oos.writeObject(t1); oos.writeObject(t2); oos.writeObject(per);
the above code serializes t1, t2 and per objects in turn. The storage diagram of disk files after serialization is shown in the figure below.
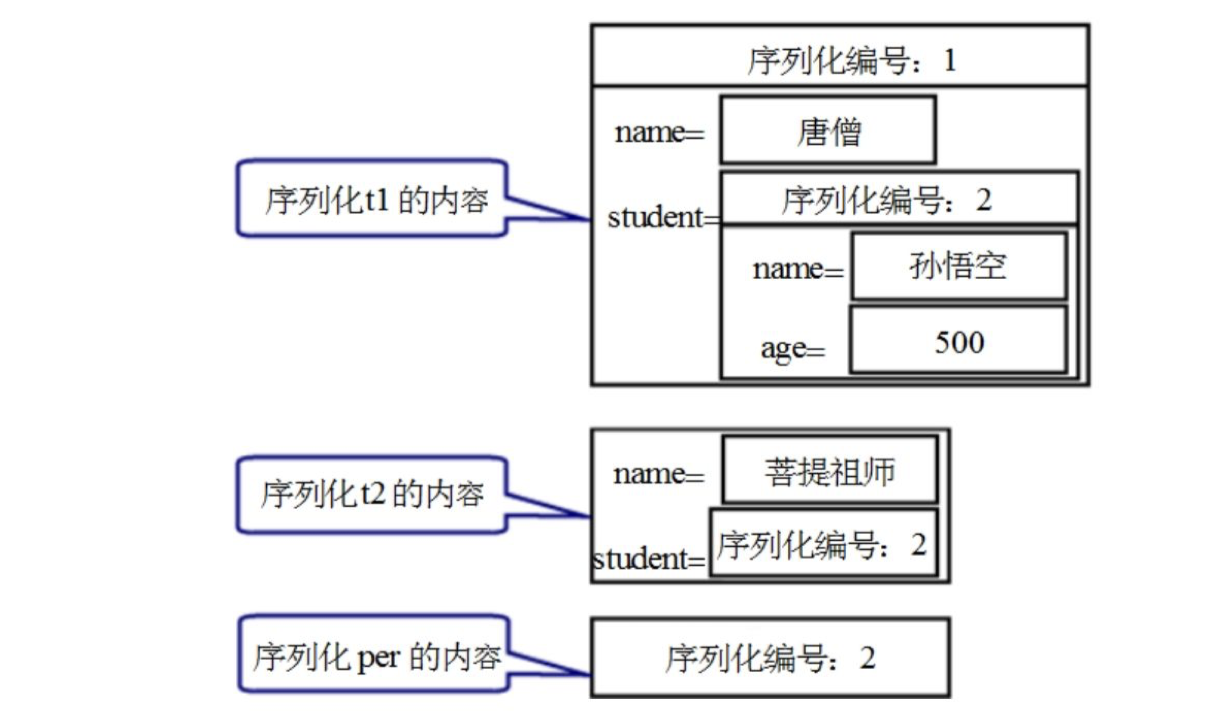
the bottom mechanism of Java serialization can be well understood through the above figure. It is not difficult to see from this mechanism that when the writeObject() method is called multiple times to output the same object, the object will be converted into a byte sequence and output only when the writeObject() method is called for the first time.
the following program serializes two Teacher objects. Both Teacher objects hold a reference to the same Person object, and the program calls the writeObject() method twice to output the same Teacher object.
public class WriteTeacher {
public static void main(String[] args) {
try (
// Create an ObjectOutputStream output stream
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./java-base/src/main/java/com/yt/base/test/serializable/teacher.txt"))
) {
Person per = new Person("Sun WuKong", 500);
Teacher t1 = new Teacher("Tang Monk", per);
Teacher t2 = new Teacher("master puti ", per);
// Write the four objects to the output stream in turn
oos.writeObject(t1);
oos.writeObject(t2);
oos.writeObject(per);
oos.writeObject(t2);
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
the code in the above program called the writeObject() method four times to output objects. In fact, only three objects were serialized, and the student references of the two Teacher objects in the sequence are actually the same Person object. The following program can prove this by reading the objects in the serialization file.
public class ReadTeacher {
public static void main(String[] args) {
try (
// Create an ObjectInputStream output stream
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("./java-base/src/main/java/com/yt/base/test/serializable/teacher.txt"))
) {
// Read the four objects in the ObjectInputStream input stream in turn
Teacher t1 = (Teacher) ois.readObject();
Teacher t2 = (Teacher) ois.readObject();
Person p = (Person) ois.readObject();
Teacher t3 = (Teacher) ois.readObject();
// Output true
System.out.println("t1 of student References and p Same:" + (t1.getStudent() == p));
// Output true
System.out.println("t2 of student References and p Same:" + (t2.getStudent() == p));
// Output true
System.out.println("t2 and t3 Is it the same object:" + (t2 == t3));
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
the code in the above program reads four Java objects in the serialization file in turn, but it is not difficult to find that t2 and t3 are the same Java object, and the student referenced by t1, t2 and p reference variables are also the same Java object.
due to the Java serialization mechanism, if the same Java object is serialized multiple times, the Java object will be converted into a byte sequence and output only for the first serialization, which may cause a potential problem - when the program serializes a variable object, writeObject() is used only for the first time The object will be converted into a byte sequence and output when the method is output. When the program calls the writeobject () method again, the program will only output the previous serialization number. Even if the instance variable value of the object has been changed later, the changed instance variable value will not be output. The procedure is as follows.
public class SerializeMutable {
public static void main(String[] args) {
try (
// Create an ObjectOutputStream input stream
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./java-base/src/main/java/com/yt/base/test/serializable/mutable.txt"));
// Create an ObjectInputStream input stream
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("./java-base/src/main/java/com/yt/base/test/serializable/mutable.txt"))
) {
Person per = new Person("Sun WuKong", 500);
// The system converts the byte sequence to the per object and outputs it
oos.writeObject(per);
// Change the name instance variable of the per object
per.setName("Zhu Bajie");
// The system only outputs the serialization number, so the changed name will not be serialized
oos.writeObject(per);
Person p1 = (Person) ois.readObject(); // ①
Person p2 = (Person) ois.readObject(); // ②
// Output true below, that is, p1 equals p2 after deserialization
System.out.println(p1 == p2);
// You can still see the output "Monkey King", that is, the changed instance variable has not been serialized
System.out.println(p2.getName());
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
the first code in the program first writes a Person object using the writeObject() method, then the program changes the name instance variable value of the Person object, and then the program outputs the Person object again, but this time the output will not convert the Person object into a byte sequence and output, but only a serialization number. code ① and ② in the program called the readObject() method twice to read the Java objects in the serialized file. The Java objects read twice will be exactly the same. The program outputs that the value of the name instance variable of the Person object read the second time is still "Monkey King", indicating that the changed Person object has not been written - which is consistent with the Java serialization mechanism.
when serializing a variable object using the Java serialization mechanism, it must be noted that the object will be converted into a byte sequence and written to ObjectOutputStream only when the wirteObject() method is called for the first time to output the object; In the later program, even if the instance variable of the object is changed, when the writeObject() method is called again to output the object, the changed instance variable will not be output.
6.4 filtering function added in Java 9
Java 9 adds setObjectInputFilter() and getObjectInputFilter() methods to ObjectInputStream. The first method is used to set the filter for the object input stream. When the program deserializes an object through ObjectInputStream, the filter's checkInput() method is automatically fired to check whether the serialized data is valid.
there are three return values when using the checkInput() method to check serialized data.
.
Status.ALLOWED: allow recovery.
Status.UNDECIDED: the status is not determined, and the program continues to check.
ObjectInputStream will decide whether to perform deserialization according to the inspection results of ObjectInputFilter. If the checkInput() method returns Status.REJECTED, the deserialization will be blocked; If the checkinput () method returns Status.ALLOWED, the program can perform deserialization.
the following program improves the previous ReadObject.java program, which will check the data before deserialization.
public class FilterTest {
public static void main(String[] args) {
try (
// Create an ObjectInputStream input stream
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("./java-base/src/main/java/com/yt/base/test/serializable/object.txt"))
) {
ois.setObjectInputFilter((info) -> {
System.out.println("===Perform data filtering===");
ObjectInputFilter serialFilter = ObjectInputFilter.Config.getSerialFilter();
if (serialFilter != null) {
// First, use the ObjectInputFilter to perform the default check
ObjectInputFilter.Status status = serialFilter.checkInput(info);
// If the result of the default check is not Status.UNDECIDED
if (status != ObjectInputFilter.Status.UNDECIDED) {
// Directly return inspection results
return status;
}
}
// If the object to be recovered is not 1
if (info.references() != 1) {
// Restoring objects is not allowed
return ObjectInputFilter.Status.REJECTED;
}
if (info.serialClass() != null &&
// If the Person class is not restored
info.serialClass() != Person.class) {
// Restoring objects is not allowed
return ObjectInputFilter.Status.REJECTED;
}
return ObjectInputFilter.Status.UNDECIDED;
});
// Read a Java object from the input stream and cast it to the Person class
Person p = (Person) ois.readObject();
System.out.println("The name is:" + p.getName()
+ "\n Age:" + p.getAge());
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
the bold code in the above program sets the ObjectInputFilter filter for ObjectInputStream (the program uses Lambda expression to create the filter), and the program overrides the checkInput() method.
when overriding the checkInput() method, first use the default ObjectInputFilter to perform the check. If the check result is not Status.UNDECIDED, the program will directly return the check result. Next, the program checks the serialized data through FilterInfo. If the object in the serialized data is not unique (the data has been polluted), the program refuses to perform deserialization; If the object in the serialized data is not a Person object (the data is contaminated), the program refuses to perform deserialization. Through this check, the program can ensure that the deserialized Person object is the only Person object, which makes the deserialization more secure and robust.
6.5. User defined serialization
in some special scenarios, if some instance variables contained in a class are sensitive information, such as bank account information, the system does not want to serialize the instance variable value; Or the type of an instance variable is not serializable, so you do not want to recursively serialize the instance variable to avoid throwing a java.io.NotSerializableException exception.
when serializing an object, the system will automatically serialize all instance variables of the object in turn. If an instance variable references another object, the referenced object will also be serialized; If the instance variable of the referenced object also references other objects, the referenced object will also be serialized, which is called recursive serialization.
by using the transient keyword in front of the instance variable, you can specify that the instance variable is ignored during Java serialization. The following Person class is almost identical to the previous Person class, except that its age is decorated with the transient keyword.
public class Person implements Serializable {
private String name;
private transient int age; // 1
// Note that no parameterless constructor is provided here!
public Person(String name, int age) {
System.out.println("Constructor with parameters");
this.name = name;
this.age = age;
}
// name's setter and getter methods
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
// setter and getter methods of age
public void setAge(int age) {
this.age = age;
}
public int getAge() {
return this.age;
}
}
the following program first serializes a Person object, and then deserializes the Person object. After obtaining the deserialized Person object, the program outputs the age instance variable value of the object.
public class TransientTest {
public static void main(String[] args) {
try (
// Create an ObjectOutputStream output stream
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./java-base/src/main/java/com/yt/base/test/serializable/transient.txt"));
// Create an ObjectInputStream input stream
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("./java-base/src/main/java/com/yt/base/test/serializable/transient.txt"))
) {
Person per = new Person("Sun WuKong", 500);
// The system converts the byte sequence to the per object and outputs it
oos.writeObject(per);
Person p = (Person) ois.readObject();
System.out.println(p.getAge());
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
although it is simple and convenient to modify an instance variable with the transient keyword, the instance variable modified by transient will be completely isolated from the serialization mechanism, resulting in the inability to obtain the instance variable value when deserializing and restoring Java objects. Java also provides a custom serialization mechanism, through which the program can control how to serialize each instance variable, or even not serialize some instance variables at all (the same effect as using the transient keyword).
classes requiring special processing during serialization and deserialization should provide the following special signature methods to implement custom serialization.
➢ private void writeObject(java.io.ObjectOutputStream out) throws IOException
➢ private void readObject(java.io.ObjectInputStream in) throws IOException,ClassNotFoundException;
➢ private void readObjectNoData() throws ObjectStreamException;
the writeObject() method is responsible for writing the instance state of a specific class so that the corresponding readObject() method can recover it. By rewriting this method, the programmer can fully control the serialization mechanism and decide which instance variables need to be serialized and how to serialize them. By default, this method will call out.defaultWriteObject to save the instance variables of the Java object, so as to achieve the purpose of serializing the state of the Java object.
readObject() method is responsible for reading and recovering object instance variables from the stream. By rewriting this method, programmers can fully control the deserialization mechanism and decide which instance variables need to be deserialized and how to deserialize them. By default, this method calls in.defaultReadObject to recover the non transient instance variables of the Java object. Under normal circumstances, the readObject () method corresponds to the writeObject() method. If the writeObject() method performs some processing on the instance variables of a Java object, the readObject () method should perform corresponding inverse processing on its instance variables to correctly recover the object.
when the serialization stream is incomplete, the readObjectNoData() method can be used to correctly initialize the deserialized object. For example, when the version of the deserialized class used by the receiver is different from that of the sender, or the class extended by the receiver's version is not the class extended by the sender's version, or the serialized stream is tampered with, the system will call the readObjectNoData() method to initialize the deserialized object.
the following Person class provides two methods: writeObject() and readObject(). When saving the Person object, the writeObject() method wraps its name instance variable into StringBuffer and writes it after reversing its character sequence; The strategy for handling name in the readObject () method corresponds to this: first convert the read data into a StringBuffer, then invert it and assign it to the name instance variable.
public class Person implements Serializable {
private String name;
private int age;
// Note that no parameterless constructor is provided here!
public Person(String name, int age) {
System.out.println("Constructor with parameters");
this.name = name;
this.age = age;
}
// name's setter and getter methods
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
// setter and getter methods of age
public void setAge(int age) {
this.age = age;
}
public int getAge() {
return this.age;
}
private void writeObject(java.io.ObjectOutputStream out)
throws IOException {
// Reverse the value of the name instance variable and write it to the binary stream
out.writeObject(new StringBuffer(name).reverse());
out.writeInt(age);
}
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException {
// Reverse the read string and assign it to the name instance variable
this.name = ((StringBuffer) in.readObject()).reverse()
.toString();
this.age = in.readInt();
}
}
the writeObject and readObject methods in the above program are used to implement custom serialization. For this Person class, there is no difference between serializing and deserializing Person instances - the difference is that even if a Cracker intercepts the Person object stream, the name he sees is also the encrypted name value, which improves the security of serialization.
it should be noted that the order of storing instance variables in writeObject() method should be consistent with the order of restoring instance variables in readObject() method, otherwise the Java object cannot be restored normally.
this is a brief introduction to serialization. There are many other serialization methods and details that you can learn by yourself.