To access Hive, Java needs to connect Hive by beeline. hiveserver2 provides a new command-line tool, beeline. hiveserver2 upgrades the previous hive, which has more powerful functions. It adds permission control. To use beeline, you need to start hiverserver2 first, and then use beeline connection.
Operation steps:
(1) Modify the core-site.xml configuration file of hadoop
(2) Start hadoop
(3) Start hiverserver2
(4) Open a new window and use beeline connection (note that Java API DB here needs to be established in advance)
_. New java project (maven)
Detailed steps:
1. Modify hadoop's core-site.xml configuration file
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
Otherwise, when using beeline connection, the following error will be reported
hadoop is not allowed to impersonate hadoop (state=08S01,code=0)
Reason: hiveserver2 adds permission control and needs to be configured in the hadoop configuration file
Solution: Add the following in hadoop's core-site.xml, restart hadoop, and then use beeline connection
Reference website:
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/Superusers.html
2. Start hadoop
start-sll.sh

3. Start hiverserver2
hiveserver2
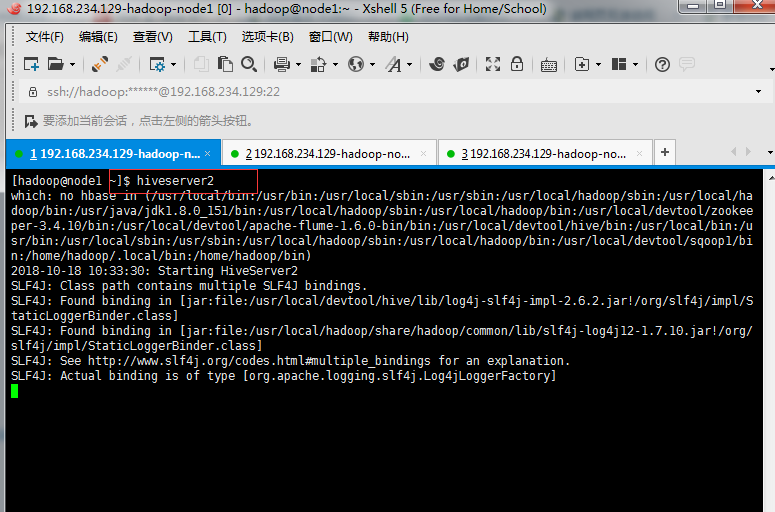
jps sees this process to show that the startup is successful

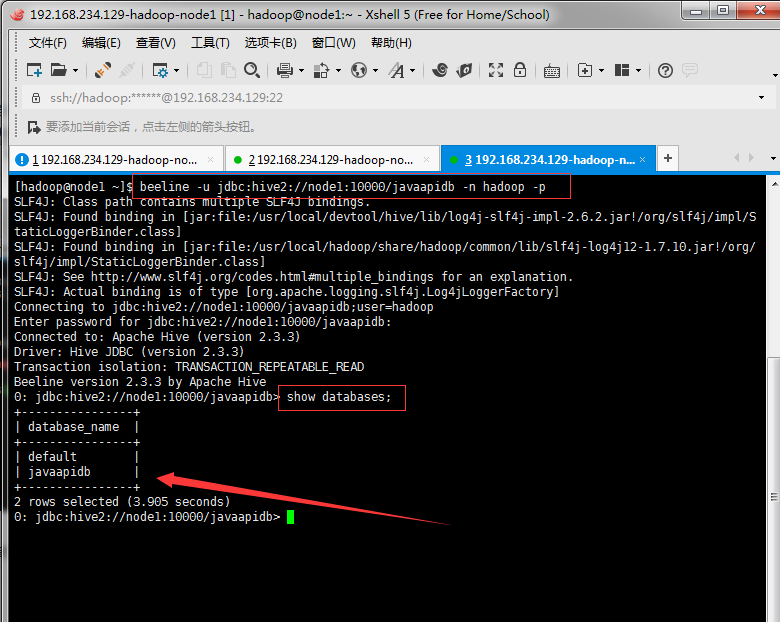
4. Open a new window and use beeline connection (note that Java API DB here needs to be established in advance)
beeline -u jdbc:hive2://node1:10000/javaapidb -n hadoop -p
Parametric interpretation:
- u: Connect url, using IP or host name. Port defaults to 10000
- n: The user name of the connection (Note: Not the user name for hive, but the login user name for the server where hive is located)
- p: Password, you don't need to enter it.
In boot, the password can be returned directly. After boot, we can check the database to see if the boot is successful.
5. New java project (maven)

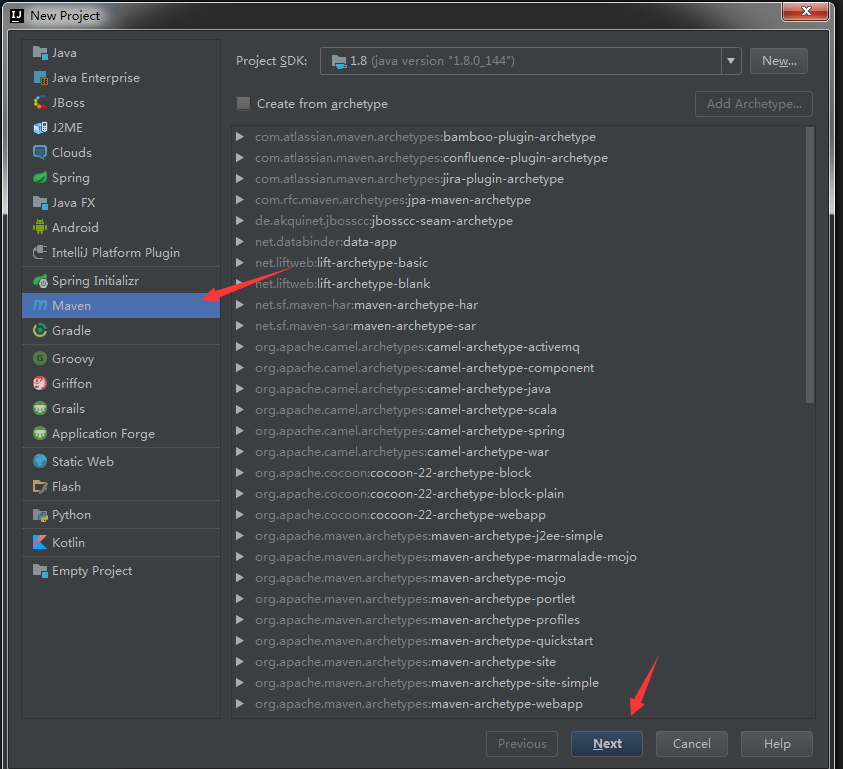


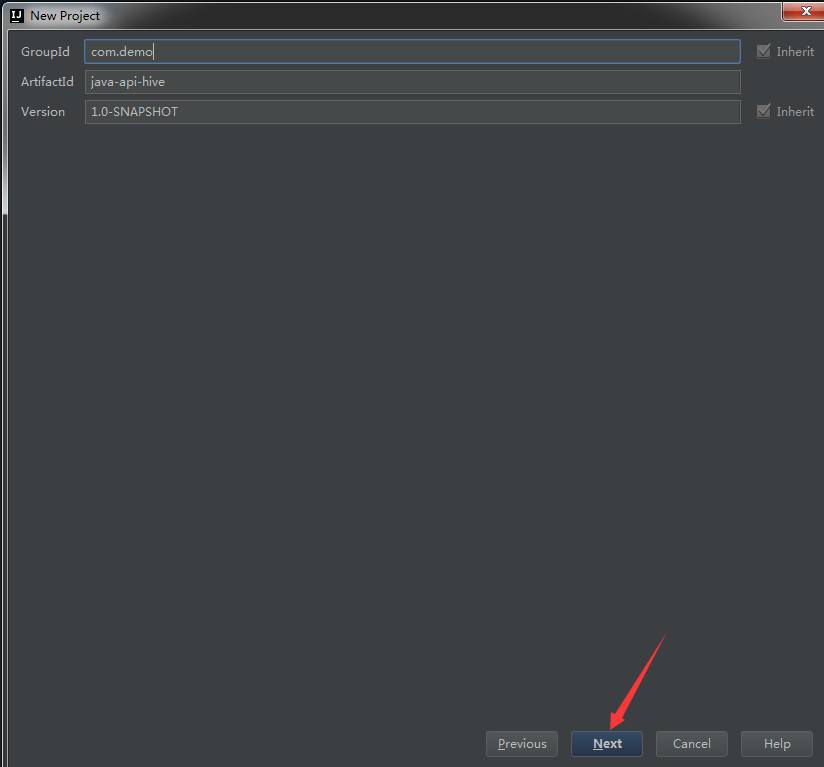
1. Modifying pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.demo</groupId>
<artifactId>java-api-hive</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>2. Create the test class HiveJDBC with the following code
Official website reference: https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
Demonstrate a query
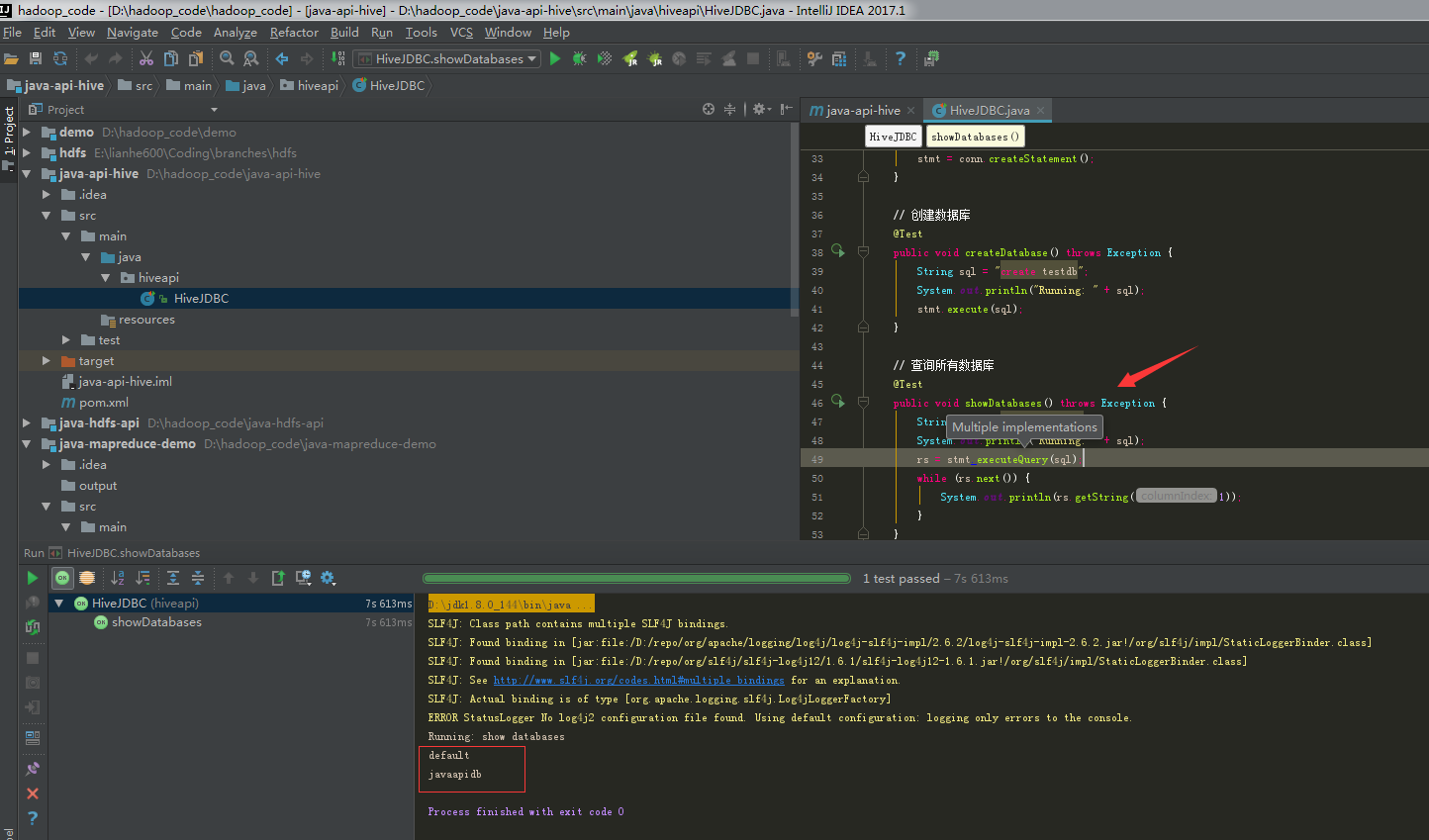
Complete code:
package hiveapi;
/**
* Created by zhoujh on 2018/8/15.
*/
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.sql.*;
/**
* JDBC Operating Hive (Note: JDBC needs to start Hive Server 2 before accessing Hive)
*/
public class HiveJDBC {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://node1:10000/javaapidb";
private static String user = "hadoop";
private static String password = "";
private static Connection conn = null;
private static Statement stmt = null;
private static ResultSet rs = null;
// Load driver, create connection
@Before
public void init() throws Exception {
Class.forName(driverName);
conn = DriverManager.getConnection(url, user, password);
stmt = conn.createStatement();
}
// Create a database
@Test
public void createDatabase() throws Exception {
String sql = "create testdb";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// Query all databases
@Test
public void showDatabases() throws Exception {
String sql = "show databases";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1));
}
}
// Create table
@Test
public void createTable() throws Exception {
String sql = "create table emp(\n" +
"empno int,\n" +
"ename string,\n" +
"job string,\n" +
"mgr int,\n" +
"hiredate string,\n" +
"sal double,\n" +
"comm double,\n" +
"deptno int\n" +
")\n" +
"row format delimited fields terminated by '\\t'";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// Query all tables
@Test
public void showTables() throws Exception {
String sql = "show tables";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1));
}
}
// View table structure
@Test
public void descTable() throws Exception {
String sql = "desc emp";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1) + "\t" + rs.getString(2));
}
}
// Loading data
@Test
public void loadData() throws Exception {
String filePath = "/home/hadoop/data/emp.txt";
String sql = "load data local inpath '" + filePath + "' overwrite into table emp";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// Query data
@Test
public void selectData() throws Exception {
String sql = "select * from emp";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
System.out.println("Employee number" + "\t" + "Employee name" + "\t" + "Post");
while (rs.next()) {
System.out.println(rs.getString("empno") + "\t\t" + rs.getString("ename") + "\t\t" + rs.getString("job"));
}
}
// Statistical queries (running mapreduce jobs)
@Test
public void countData() throws Exception {
String sql = "select count(1) from emp";
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getInt(1));
}
}
// Delete the database
@Test
public void dropDatabase() throws Exception {
String sql = "drop database if exists hive_jdbc_test";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// Delete database tables
@Test
public void deopTable() throws Exception {
String sql = "drop table if exists emp";
System.out.println("Running: " + sql);
stmt.execute(sql);
}
// Release resources
@After
public void destory() throws Exception {
if (rs != null) {
rs.close();
}
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}