1. Introduction to Collectors
collect() receives a parameter of type Collector, which determines how elements in the stream are aggregated into other data structures. The Collectors class contains a large number of factory methods for common collectors, of which toList() and toSet() are the two most common. In addition to them, there are many collectors for complex data conversion.
Instructional code and functional comparison:
With multilevel grouping, the difference between instructional and functional forms becomes more obvious: instructional code quickly becomes more difficult to read, maintain and modify because of the need for many layers of nested loops and conditions. By contrast, functional versions can be easily enhanced with just one more collector
Predefined collectors are those that can be created from factory methods provided by Collectors classes, such as groupingBy. They provide three main functions:
- Reducing and summarizing flow elements into a single value
- Element grouping
- Elemental partitioning
2. Use collectors
When it is necessary to reorganize flow items into collections, the collector (parameters of the Stream method collect) is generally used. Broadly speaking, it can be used whenever all the items in the stream are merged into one result. This result can be of any type, complex as a multilevel mapping representing a tree, or simple as an integer.
3. Collector examples
Maximum and Minimum in 3.1 Stream
Collectors.maxBy and Collectors.minBy, calculate the maximum or minimum value in the stream. The two collectors receive a Comparator parameter to compare elements in the stream. You can create a Comparator to compare dishes based on calories:
System.out.println("Find out the foods with the highest calories:");
Optional<Dish> collect = DataUtil.genMenu().stream().collect(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)));
collect.ifPresent(System.out::println);
System.out.println("Find out the food with the lowest calories:");
Optional<Dish> collect1 = DataUtil.genMenu().stream().collect(Collectors.minBy(Comparator.comparingInt(Dish::getCalories)));
collect1.ifPresent(System.out::println);3.2 Summary
The Collectors class specifically provides a factory method for aggregation: Collectors.summingInt. It accepts a function that maps an object to the sum of the required int s and returns a collector that performs the summary operation we need after passing it to the normal collector method. For example, you can calculate the total calorie of the menu list in this way:
Integer collect = DataUtil.genMenu().stream().collect(Collectors.summingInt(Dish::getCalories));
System.out.println("Total heat:" + collect);
Double collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.summingDouble(Double::doubleValue));
System.out.println("double and:" + collect1);
Long collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.summingLong(Long::longValue));
System.out.println("long and:" + collect2);3.3 Summary average
Collectors. averaging Int, averaging Long and averaging Double can calculate the average number of values:
Double collect = DataUtil.genMenu().stream().collect(Collectors.averagingInt(Dish::getCalories));
System.out.println("Average calorific value:" + collect);
Double collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.averagingDouble(Double::doubleValue));
System.out.println("double average value:" + collect1);
Double collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.averagingLong(Long::longValue));
System.out.println("long average value:" + collect2);3.4 Summary
You may want to get two or more of these results, and you want to do it in one operation. In this case, you can use the summarizingInt factory method to return the collector. For example, through a summarizing operation, you can count the number of elements in the menu and get the total, average, maximum and minimum of calories:
IntSummaryStatistics collect = DataUtil.genMenu().stream().collect(Collectors.summarizingInt(Dish::getCalories));
System.out.println("int:" + collect);
DoubleSummaryStatistics collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.summarizingDouble(Double::doubleValue));
System.out.println("double:" + collect1);
LongSummaryStatistics collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.summarizingLong(Long::longValue));
System.out.println("long:" + collect2);3.5 Connection String
The collector returned by the joining factory method will concatenate all strings obtained by applying the toString method to each object in the convection into one string.
String collect = DataUtil.genMenu().stream().map(Dish::getName).collect(Collectors.joining());
Note that joining uses StringBuilder internally to append the generated strings one by one. Fortunately, the joining factory method has an overloaded version that accepts delimiters between elements, so you can get a well-separated list of names:
String collect1 = DataUtil.genMenu().stream().map(Dish::getName).collect(Collectors.joining(","));4. Generalized Reduction Summary
All collectors are special cases of a reduction process that can be defined using the reducing factory method. The Collectors.reducing factory method is a generalization of all these special cases.
It requires three parameters:
- The first parameter is the starting value of the reduction operation and the return value when there are no elements in the stream, so it is clear that 0 is an appropriate value for both values and values.
- The second parameter is the function you use in Section 6.2.2, which converts a dish into an int representing its calorie content.
- The third parameter is a BinaryOperator, which accumulates two items into a value of the same type. Here it is the sum of two ints.
The following two operations are the same:
Optional<Dish> collect = DataUtil.genMenu().stream().collect(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))); Optional<Dish> mostCalorieDish = menu.stream().collect(reducing((d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2));
5. Grouping
The collector returned with the Collectors.groupingBy factory method can easily accomplish the task:
Map<Dish.Type, List<Dish>> collect = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType));
A Function (in the form of a method reference) is passed to the groupingBy method, which extracts the Dish.Type for each Dish in the stream. We call this function a classification function because it is used to divide elements in a stream into different groups. The result of the grouping operation is a Map, which takes the value returned by the grouping function as the key of the mapping, and the list of all items in the stream with this value as the corresponding mapping value.
5.1 Multilevel Grouping
To achieve multi-level grouping, we can use a collector created by the two-parameter version of Collectors.groupingBy factory method, which accepts the second parameter of collector type in addition to the normal classification function. To do the secondary grouping, we can pass an inner grouping by to the outer grouping by and define a secondary criterion for the classification of items in the stream:
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> collect1 = DataUtil.genMenu().stream().collect(
Collectors.groupingBy(Dish::getType,
Collectors.groupingBy(dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
} else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
} else return CaloricLevel.FAT;
}))
);5.2 Data collection by subgroup
The second collector passed to the first groupingBy can be of any type, not necessarily another groupingBy. For example, to count the number of dishes in the menu, you can pass the counting collector as the second parameter of the grouping BY collector:
Map<Dish.Type, Long> collect2 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType, Collectors.counting()));
Also note that the common single parameter groupingBy (f) (where f is a classification function) is actually a simple way to write groupingBy(f, toList()).
To convert the results returned by the collector to another type, you can use the Collectors. collecting AndThen factory method to return the collector, which takes two parameters: the collector to be converted and the conversion function, and returns another collector.
Map<Dish.Type, Dish> collect3 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)),
Optional::get
)));This operation is safe here because the reducing collector will never return Optional.empty().
Another collector that is often used in conjunction with groupingBy is generated by the mapping method. This method takes two parameters: one is to transform the elements in the function convection, the other is to collect the result objects of the transformation. The purpose is to apply a mapping function to each input element before accumulation, so that the receiver accepting a particular type of element can adapt to different types of objects. Let's look at a practical example of using this collector. For example, you want to know what Caloric Level is on the menu for each type of Dish.
Map<Dish.Type, Set<CaloricLevel>> collect4 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(
Dish::getType, Collectors.mapping(
dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
} else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
} else return CaloricLevel.FAT;
}, Collectors.toSet()
)
));6. Zoning
Partitioning is a special case of grouping: a predicate (a function that returns a Boolean value) acts as a classification function, which is called a classification function. The partition function returns a Boolean value, which means that the key type of the resulting grouped Map is Boolean, so it can be divided into at most two groups - true is a group, false is a group. For example, if you want to separate vegetarian dishes from non-vegetarian dishes:
Map<Boolean, List<Dish>> collect = DataUtil.genMenu().stream().collect(Collectors.partitioningBy(Dish::isVegetarian));
System.out.println(collect.get(true));
partitioningBy The factory method has an overloaded version that can pass the second collector as follows:
Map<Boolean, Map<Dish.Type, List<Dish>>> collect1 = DataUtil.genMenu().stream().collect(Collectors.partitioningBy(
Dish::isVegetarian, Collectors.groupingBy(Dish::getType)
));Partitioning is considered as a special case of grouping.
7. Static factory method of Collectors class
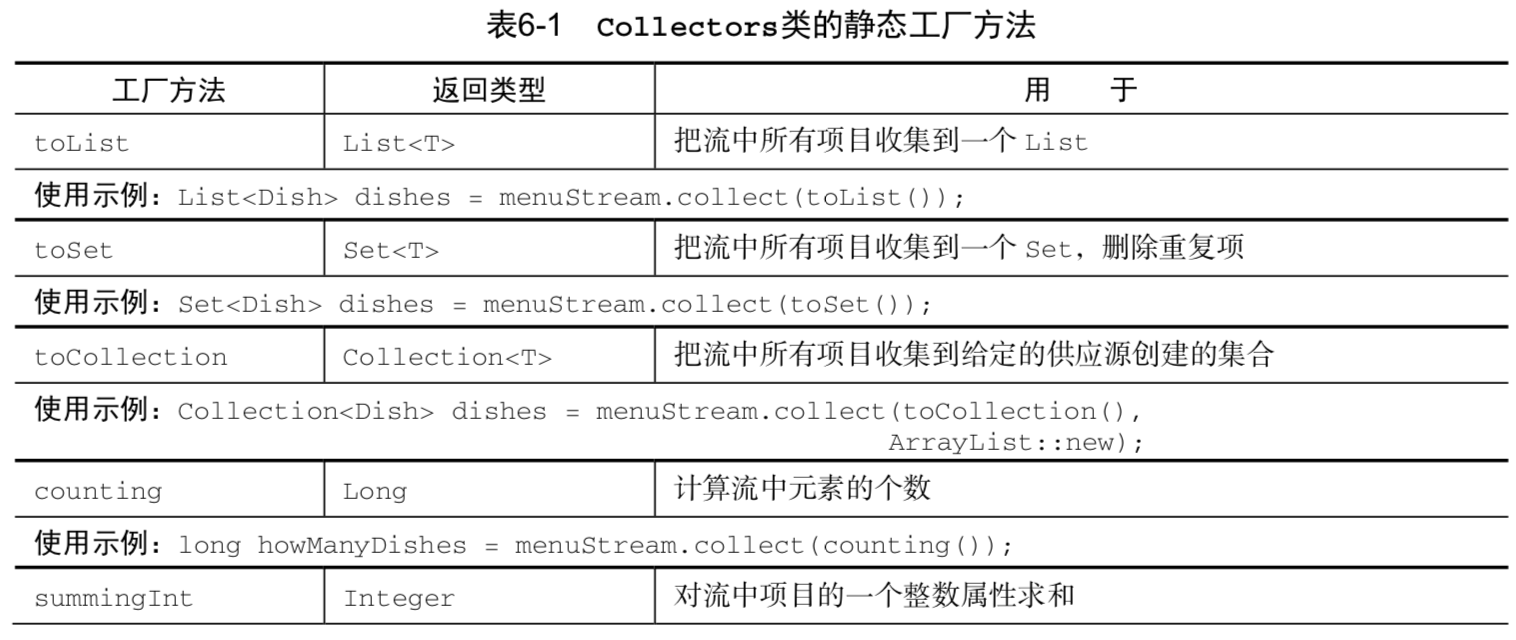
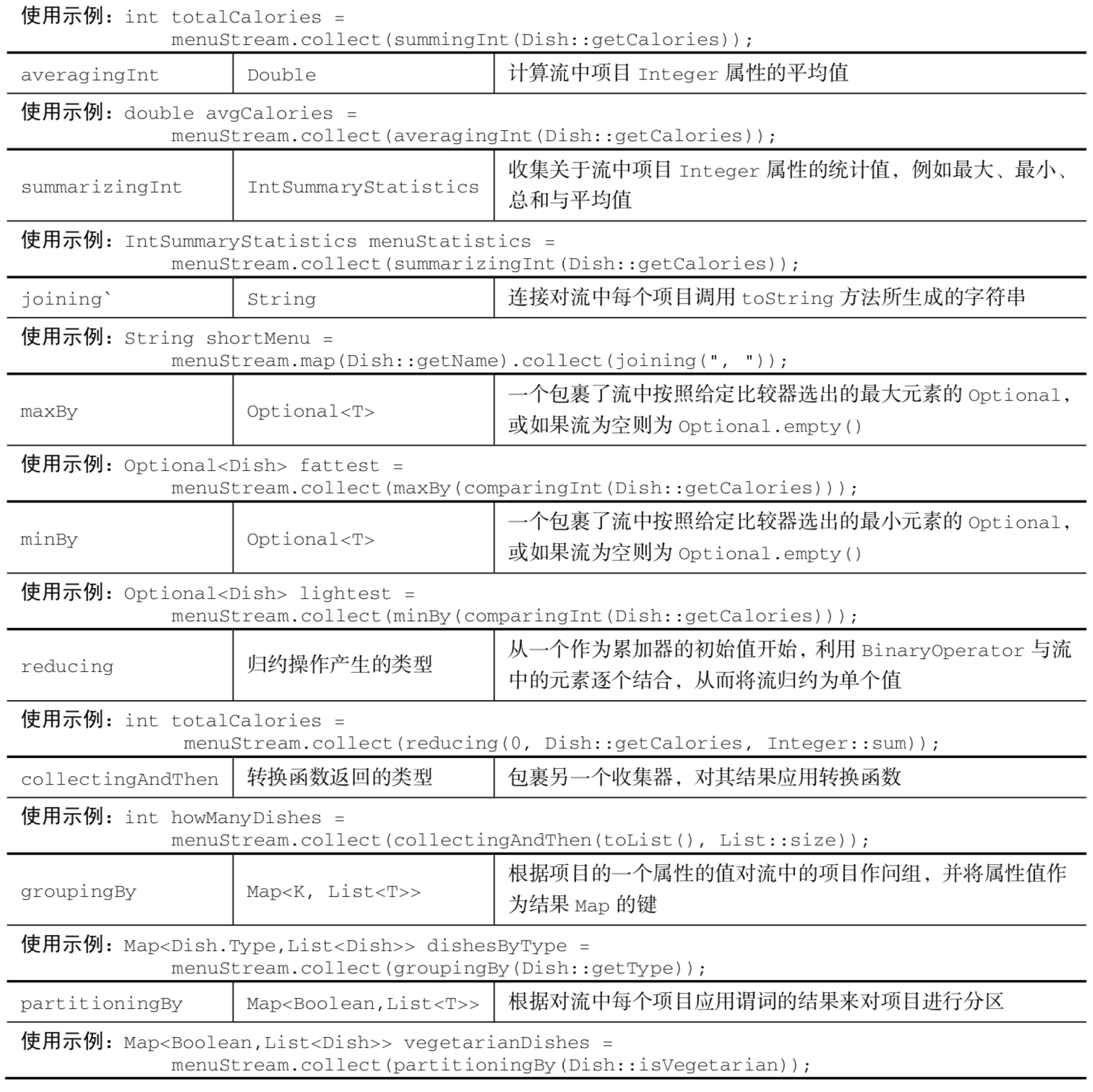
8. Collector interface
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
Function<A, R> finisher();
BinaryOperator<A> combiner();
Set<Characteristics> characteristics();
}The following definitions apply to this list:
- T is a generic type of the items to be collected in the stream.
- A is the type of accumulator, which is the object used to accumulate part of the results during the collection process.
- R is the type of object (usually but not necessarily a collection) obtained by mobile phone operation.
8.1 Establishing a New Result Container: supplier Method
The supplier method must return a Supplier whose result is empty, that is, a parametric function, which creates an empty accumulator instance when invoked for use in the data collection process.
8.2 Adding elements to the result container: accumulator method
The accumulator method returns the function that performs the reduction operation. When traversing to the nth element in the stream, the function executes with two parameters: the accumulator that holds the reduction result (the first n-1 item in the stream has been collected), and the nth element itself. The function returns void because the accumulator is updated in situ, that is, the execution of the function changes its internal state to reflect the effect of traversing elements.
8.3 Application of Final Conversion to Result Containers: finisher Method
After traversing the stream, the finisher method must return a function to be called at the end of the cumulative process in order to convert the accumulator object into the final result of the entire set operation.
The logical steps of the sequential reduction process are as follows: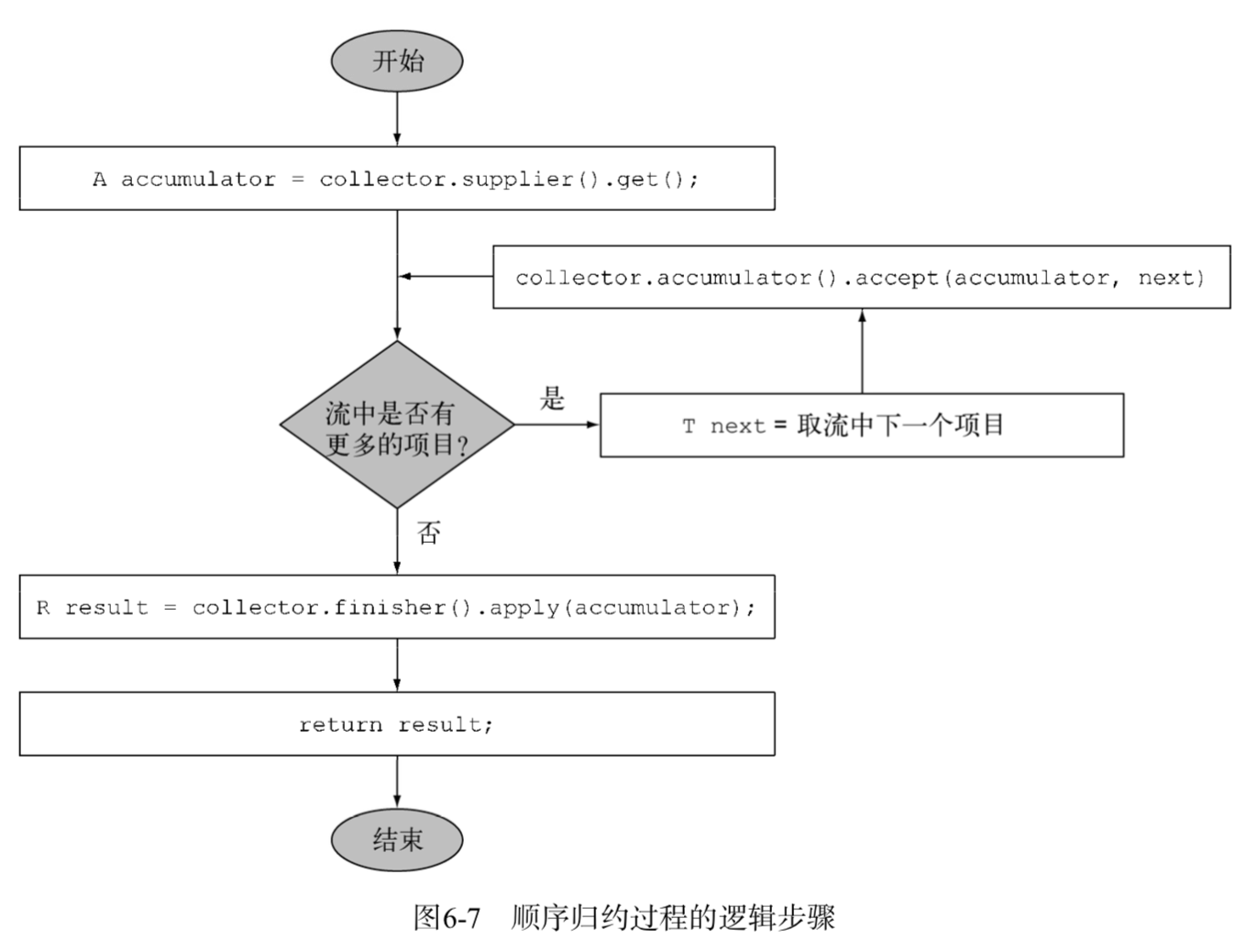
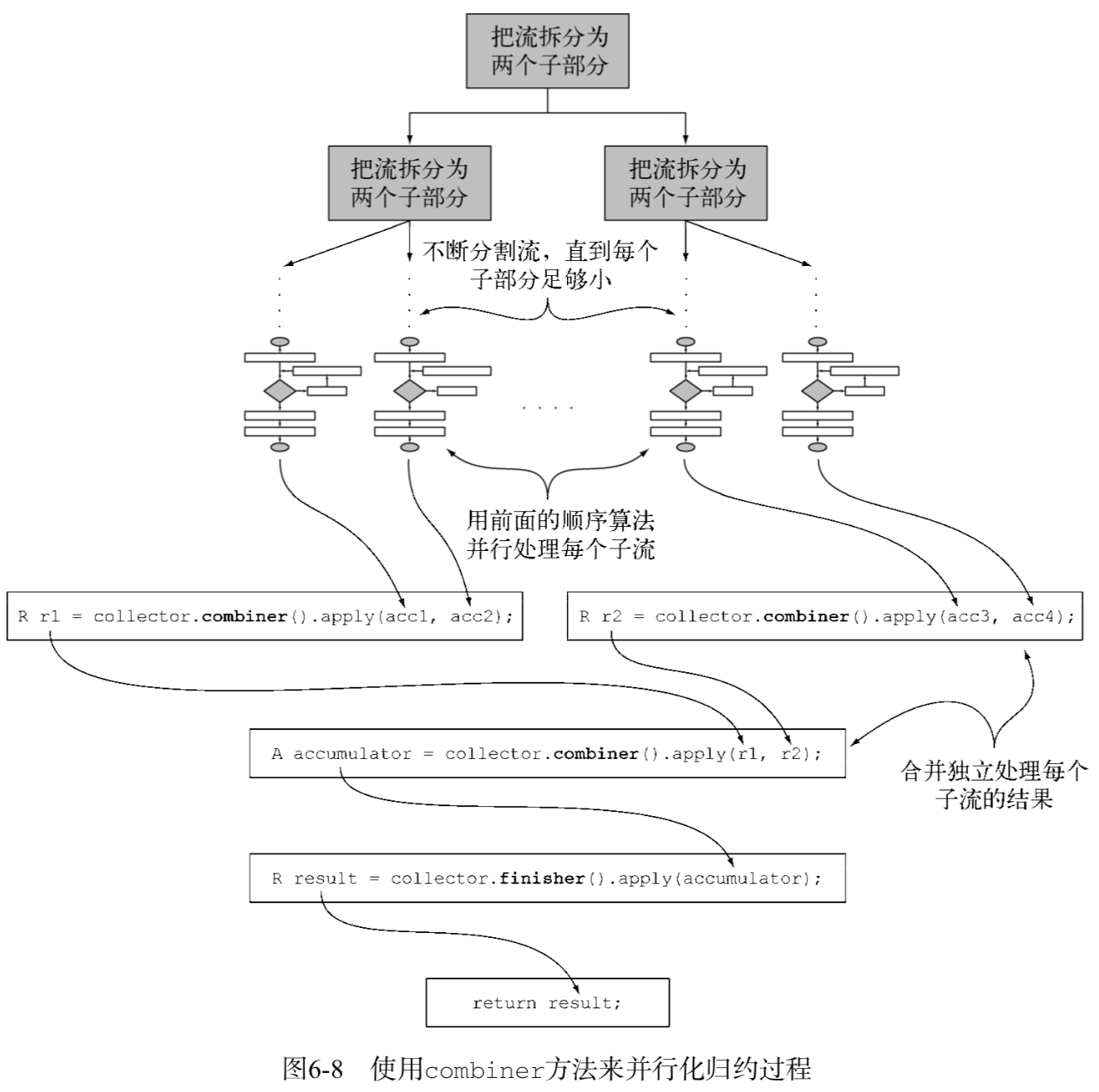
8.4 Merge two result containers: combiner method
The combiner method, the last of the four methods, returns a function for reduction operations, which defines how the accumulators generated by the reduction of each sub-part of the convection can be merged when the sub-parts of the convection are processed in parallel:
- The original stream is split into sub-streams in a recursive manner until one condition that defines whether the stream needs further splitting is nonsense (if the distributed unit of work is too small, parallel computing tends to be slower than sequential computing, and if the number of parallel tasks generated is much larger than the number of processor cores, it makes no sense).
- Now, all sub-streams can be processed in parallel, that is, the sequential reduction algorithm shown in Figure 6-7 is applied to each sub-stream.
- Finally, the function returned by the collector combiner method is used to merge all partial results in pairs. At this point, the results of the sub-streams corresponding to each split of the original stream are combined.
8.5 characteristics Method
The last method, Characteristics, returns an immutable collection of Characteristics, which defines the behavior of the collector -- especially the hints about whether the stream can be reduced in parallel and what optimizations can be used.
Characteristics is an enumeration of three items.
- UNORDERED - Reduction results are not affected by the traversal and cumulative order of items in the stream.
- CONCURRENT - accumulator function can be called from multiple threads at the same time, and the collector can reduce the flow in parallel. If the collector is not marked UNORDERED, it can be reduced in parallel only for disordered data sources.
- IDENTITY_FINISH -- This indicates that the function returned by the finisher method is an identity function that can be skipped. In this case, the accumulator object will be used directly as the final result of the reduction process. This also means that it is safe to convert accumulator A to result R unchecked.
9. Summary
- collect is a terminal operation that accepts various ways (called collectors) of accumulating elements in the stream into summary results.
- Predefined collectors include reducing and aggregating flow elements to a value, such as calculating a minimum, maximum, or average. These collectors are summarized in Table 6-1.
- The predefined collector can group elements in the grouping BY convection or partitioning BY.
- Collectors can be efficiently compounded for multi-level grouping, partitioning and reduction.
- You can implement the methods defined in the Collector interface to develop your own collector.
Access to resources
- Public Number Response: Java 8 is available in English and Chinese version of Java 8 in Action!
Tips
- Welcome to collect and forward, thank you for your support! (_) _
- Welcome to pay attention to my public name: Zhuangli Program Ape, Book Notes Tutorial Resources for the first time!
