
introduction
In the previous chapter, we discussed data vertical splitting. Today, we will continue to discuss data splitting: horizontal splitting!
There are some differences between horizontal splitting and vertical splitting. The smallest unit of vertical splitting is a field, which has a strong correlation with the business. The specific business corresponds to the specific split data; The smallest unit of horizontal splitting is a data row, which has little to do with specific businesses. Business associations can be single table data after splitting or global data before splitting. In short, horizontal splitting is transparent to applications, and the application logic does not need to move much after data splitting.
text
Generally, in relational databases, horizontal splitting corresponds to two aspects:
The first is to dismantle the meter horizontally.
Horizontal table splitting is the data splitting of multiple tables based on a certain field of a table. After splitting, the original operation on a single table needs to be converted to the operation on multiple sub tables. Generally speaking, similar to vertical splitting, a global routing table is required. After defining the routing table, you can simplify the operation of splitting the table. For example, when it comes to data synchronization after data splitting and sending query statements to the split molecular table, you can directly operate the routing table.
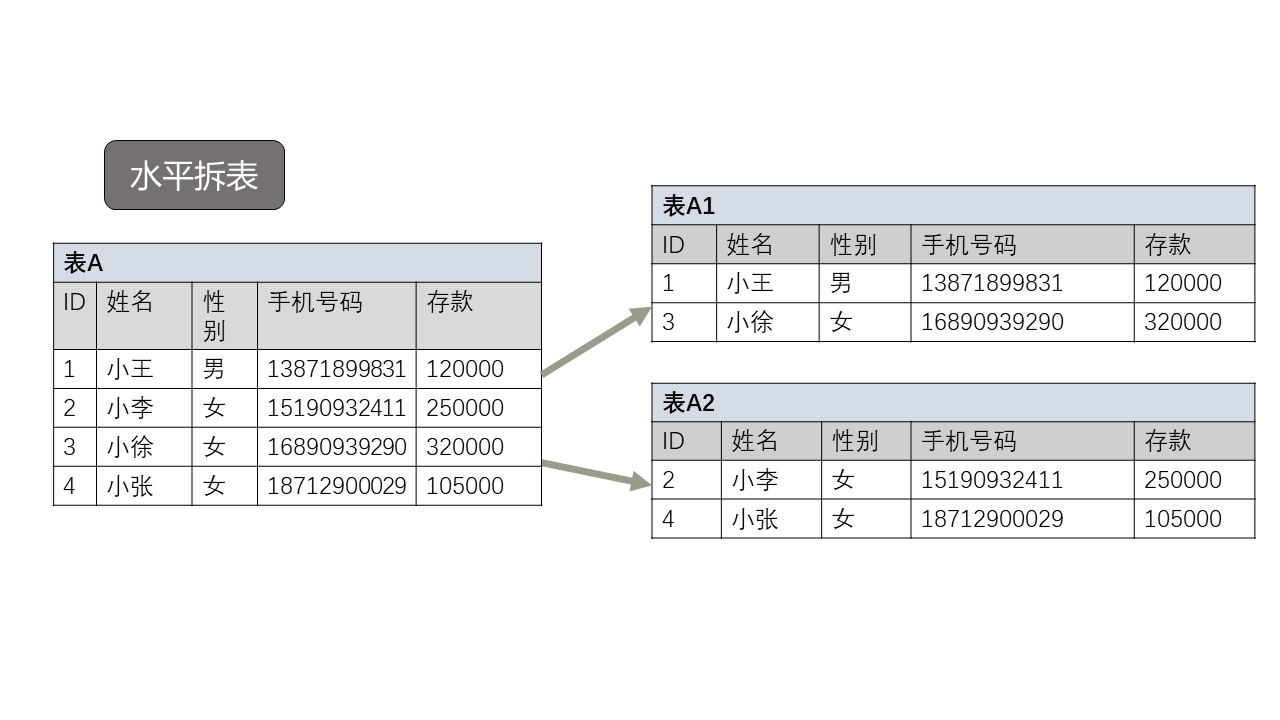
As shown in the figure below, table a is split according to ID. the odd table is table A1 and the even table is table A2:
The second is horizontal zoning.
The horizontal partition is similar to the horizontal split table, which splits the table data based on one field. The difference is that the horizontal partition is a built-in function of the database. Compared with the horizontal partition table, the operation will be simpler. However, the biggest disadvantage is that the split data cannot cross instances, which is why most middleware or NEW SQL do not directly use horizontal partitioning. However, if you only consider data splitting on a single machine, you should prefer horizontal partitioning. We will talk about the specific reasons in the following chapters. Today, we mainly review the built-in horizontal table splitting scheme of MySQL.
MySQL native horizontal split table
When it comes to MySQL's native horizontal split table, you can think of MERGE Table! MERGE table is a function table for horizontal summary of traditional MYISAM tables. When it comes to MYISAM, many people may think it's outdated and there's no need to continue! However, what I want to say here is that although MERGE is outdated, the method that MERGE provides us for horizontal splitting in the future is very worth learning, which is why this article wants to give an example of MERGE. Understanding how to use the MERGE table is of great reference significance to the INNODB table splitting we will talk about later.
MERGE table has many advantages, which are listed as follows:
- Data is easy to manage. For example, a large log table stores data for 10 years. It is divided into 120 tables according to month. MERGE table is used for aggregation. There is no need to retrieve 120 sub tables separately, just the MERGE table.
- Reduce the IO utilization of a single disk. For example, the data of the log table in different months can be distributed to different disks to avoid the problem of high IO utilization of a single disk.
- Simple query. For example, the query mode of the log table is relatively fixed, and the requests to query the data of the current year are very frequent. If the historical data is queried occasionally, it can be divided into two tables, one current table and one historical table. Then the MERGE table is used as the unified entry of the two tables, and the query MERGE table will be automatically routed to the current table.
- MERGE Table zero maintenance. The MERGE table only stores the metadata of the sub table, so it does not need maintenance. It is very fast to create and destroy.
- The sub tables managed by MERGE table are very flexible. Each sub table does not need to be limited to a single database, but can be flexibly distributed in different databases.
Next, let's use a few simple examples to understand how to use the MERGE table.
Table m1 - m10, 10 sub tables, which are stored from small to large according to id. each table has 10000 records. The table structure is as follows:
(debian-ytt1:3500)|(ytt)>show create table m1\G
*************************** 1. row ***************************
Table: m1
Create Table: CREATE TABLE `m1` (
`id` int NOT NULL,
`r1` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_r1` (`r1`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
(debian-ytt1:3500)|(ytt)>select count(*) from m1;
+----------+
| count(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.00 sec)
...
The corresponding MERGE table structure is as follows:
(debian-ytt1:3500)|(ytt)>show create table m_global\G
*************************** 1. row ***************************
Table: m_global
Create Table: CREATE TABLE `m_global` (
`id` int NOT NULL,
`r1` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_r1` (`r1`)
) ENGINE=MRG_MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci INSERT_METHOD=LAST UNION=(`m1`,`m2`,`m3`,`m4`,`m5`,`m6`,`m7`,`m8`,`m9`,`m10`)
1 row in set (0.00 sec)
The sub tables contained in the table definition are defined with union and Insert_method means to insert to the last table when inserting.
Use the merge table to query the total number of records in these 10 tables:
(debian-ytt1:3500)|(ytt)>select count(*) from m_global; +----------+ | count(*) | +----------+ | 100000 | +----------+ 1 row in set (0.00 sec)
Simplify query:
For example, if you want to query the records with id 11000120001 in M1, M2 and M3 respectively, you need to query each table and then UNION
(debian-ytt1:3500)|(ytt)>select * from m1 where id = 1
-> union all
-> select * from m2 where id = 10001
-> union all
-> select * from m3 where id = 20001;
+-------+------+
| id | r1 |
+-------+------+
| 1 | 1 |
| 10001 | 1 |
| 20001 | 1 |
+-------+------+
3 rows in set (0.00 sec)
Use the merge table to simplify the query, which can be queried only once.
(debian-ytt1:3500)|(ytt)>select * from m_global where id in (1,10001,20001); +-------+------+ | id | r1 | +-------+------+ | 1 | 1 | | 10001 | 1 | | 20001 | 1 | +-------+------+ 3 rows in set (0.00 sec)
The biggest problem with MERGE tables is inserting records: MERGE Table attribute insert_method has three options, NO/FIRST/LAST.
Table m_global sets LAST, that is, inserting a new record will be inserted into the LAST table. For example, inserting a record (10000001100) will insert it into the sub table m10.
(debian-ytt1:3500)|(ytt)>insert into m_global values (1000001,100); Query OK, 1 row affected (0.00 sec) (debian-ytt1:3500)|(ytt)>select * from m_global where id = 1000001; +---------+------+ | id | r1 | +---------+------+ | 1000001 | 100 | +---------+------+ 1 row in set (0.00 sec) (debian-ytt1:3500)|(ytt)>select * from m10 where id = 1000001; +---------+------+ | id | r1 | +---------+------+ | 1000001 | 100 | +---------+------+ 1 row in set (0.00 sec)
Similarly, if you set insert_method=first, only the first table will be inserted. This will result in very uneven data distribution. In the later stage, you need to manually split the table with increased data again. Therefore, the MERGE table provides a third option: insert_method=no . After setting, write to MERGE table is not allowed, only read is allowed.
(debian-ytt1:3500)|(ytt)>alter table m_global insert_method=no; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 (debian-ytt1:3500)|(ytt)>insert into m_global values (1000002,100); ERROR 1036 (HY000): Table 'm_global' is read only (debian-ytt1:3500)|(ytt)>
After the MERGE table is set to read-only, the distribution of sub table data must be guaranteed by non MySQL native methods.
I only listed the advantages and disadvantages of MERGE table above:
-
The sub table of the MERGE table is the MYISAM engine and cannot build a full-text index based on the MERGE table.
-
The MERGE table uses more file descriptors.
-
Reading the MERGE table index is slower. The MERGE table scans each table index below to see which is appropriate.
For the third disadvantage, such as the previous query, compare the following two SQL execution plans:
(debian-ytt1:3500)|(ytt)>explain format=tree select * from m1 where id = 2 union all select * from m2 where id = 10002 union all select * from m3 where id = 20002\G
*************************** 1. row ***************************
EXPLAIN: -> Append
-> Stream results
-> Rows fetched before execution
-> Stream results
-> Rows fetched before execution
-> Stream results
-> Rows fetched before execution
1 row in set (0.00 sec)
(debian-ytt1:3500)|(ytt)>explain format=tree select * from m_global where id in (2,10002,20002)\G
*************************** 1. row ***************************
EXPLAIN: -> Filter: (m_global.id in (2,10002,20002)) (cost=2.11 rows=3)
-> Index range scan on m_global using PRIMARY (cost=2.11 rows=3)
1 row in set (0.00 sec)
The results show that the UNION query efficiency of the three sub tables is higher than that of the MERGE table.
- Deleting the MERGE table does not delete the child tables below. MERGE table is a routing table. Deleting a routing table will not affect the bottom sub table.
(debian-ytt1:3500)|(ytt)>drop table m_global; Query OK, 0 rows affected (0.01 sec) (debian-ytt1:3500)|(ytt)>show tables like 'm%'; +--------------------+ | Tables_in_ytt (m%) | +--------------------+ | m1 | | m10 | | m2 | | m3 | | m4 | | m5 | | m6 | | m7 | | m8 | | m9 | +--------------------+ 10 rows in set (0.00 sec)
Therefore, the application scenarios of MERGE table are limited to the following:
- Log table, and the table has been split according to the defined split key. For example, by date, by user ID, etc.
- Tables that are not updated frequently can be compressed.
- Tables with low data reliability requirements. Such as news and information.
summary
In this article, we discussed MySQL's native horizontal splitting table. Although MERGE table is outdated, being familiar with the use of MERGE table can expand our subsequent thinking of horizontal splitting table.
What else do you want to know about the technical content of MySQL? Leave a message and tell Xiaobian!
