Preface
I wrote a previous article using TF. iOS Implementing Prisma-like Software After the article, I received many online friends to exchange ideas and ask for Demo replies, which shows that you have a strong interest in the realization of this function.
The previous article did not elaborate on the principle of Google's implementation. It simply ran parameters and computational diagrams on iOS devices. Because of the complexity of TF's compilation and construction project, unmanaged source code is available for download.
This is mainly through the analysis of the logic in Google's paper, using the new Metal framework of iOS and the GPU part of the device to accelerate the operation, the image is rendered like Prisma (of course, the network parameters are still trained by Google). During this period, we have crossed many pits. Here we share them. I hope it will be helpful for your research.

structure
Having read the paper A LEARNED REPRESENTATION FOR ARTISTIC STYLE, I should still be familiar with the overall network structure proposed by Google, as follows:
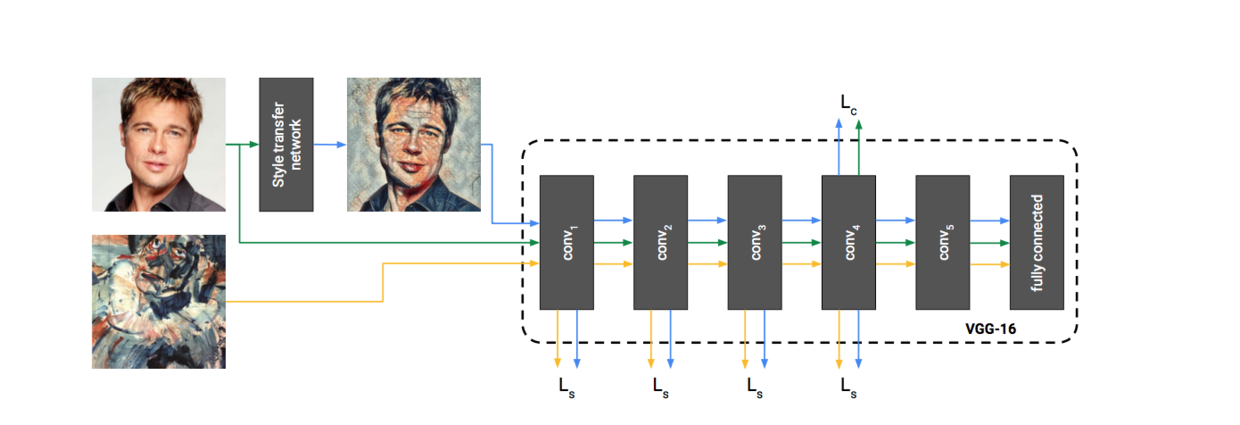
The latter dotted line part is the VGG-19 network. This part of the training method is the same as in the paper A Neural Algorithms of Artistic Style in 2015. It is not the focus of this optimization by google.
Focus on the Style transfer network section, our training parameters are also parameters of this layer. This is a forward-generating network. With such a forward-generating network layer, we only need to train the parameters well and generate the pictures only by one forward operation. This saves a lot of time compared with using VGG-19 network to learn to generate pictures back and forth directly. And because of the short time to synthesize images, it can also run locally on mobile devices.
The following is the network structure of Style transfer network:
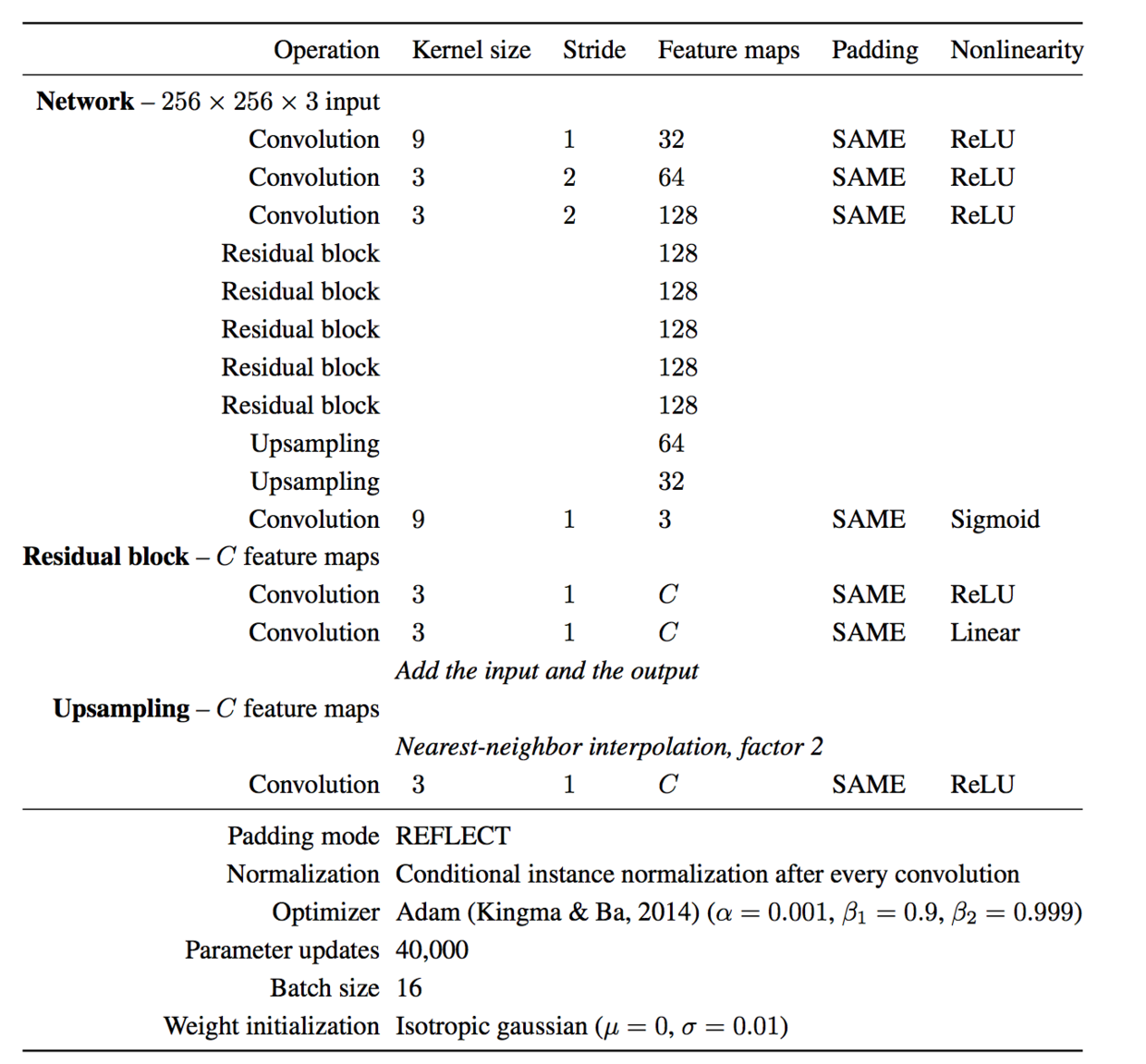
There are 3 convolutions + 5 Residual Blocks + 2 upsampling+1 convolution in the network. In fact, Residual Block is two convolutions, and then the input and output are added. Upampling first enlarges the image with Nearest-Neighbor, and then convolutes. So there are 16 layers of convolution operations, and each convolution operation is followed by Batch-normalization, followed by activation function (here started because Apple MPSCNN library can convolute directly with activation function, so when I put BN into activation, the image generated is an error).
Padding Mode Paper here is Reflect, Apple Metal does not support this padding method, I wrote a_, but finally found that the application of Zero Padding is the right. I wonder if Apple's convolution implementations are different, or is the Padding model here just for training? I'll have time to study it later.
The above is the core network structure of the whole implementation. In theory, we have parameters and know the network implementation. Without TF calculating graph, it is also possible to realize it by ourselves. This can avoid tedious TF integration, compilation, and its own network debugging, memory control and so on are much more convenient.
However, it is not so simple. Many of the deep neural network kernel s in the Apple Metal framework are not yet available. They are only partially encapsulated for convolution operations. Here we share the implementation of several important algorithms in the implementation process.
Batch-Normalization
BN(Batch-Normalization) is actually the core part of this network. Every different style picture is distinguished here. When you choose different style, each layer of convolution operation is the same, but BN is different, that is to change the style of the final generated picture.
At first, I expected Metal to have BN implementation, but I did not find a circle, considering that writing kernels and convolution operations can be operated on GPU, but finally found that the kernels coding is too complex from scratch, so I implemented one on the CPU. After each convolution, the image Copy came out to calculate BN on the CPU, and then connected the activation function (or expect Apple to provide a kernel supporting BN later). (vi).
The implementation code is as follows:
- (void)batch_norm:(MPSImage *)image styles:(float *)styles shift:(float *)shift { NSUInteger w = image.texture.width; NSUInteger h = image.texture.height; NSUInteger featureNum = image.featureChannels; float *gamma = calloc(featureNum, sizeof(float)); float *beta = calloc(featureNum, sizeof(float)); // float gamma[featureNum], beta[featureNum]; vDSP_mmul(styles, 1, shift, 1, beta, 1, 1, featureNum, styleNum); vDSP_mmul(styles, 1, shift+featureNum*styleNum, 1, gamma, 1, 1, featureNum, styleNum); // for (int i = 0; i < featureNum; i++) { // printf("%f,%f ",gamma[i],beta[i]); // } // NSLog(@"%@",image); // NSUInteger numSlices = (featureNum + 3) / 4; NSUInteger numComponents = featureNum < 3 ? featureNum : 4; NSUInteger channels = featureNum < 3 ? featureNum : numSlices * 4; float16_t *htemp = calloc(w*h*channels, sizeof(float16_t)); for (int i = 0; i < numSlices; i++) { [image.texture getBytes:htemp+w*h*numComponents*i bytesPerRow:w*numComponents*2 bytesPerImage:0 fromRegion:MTLRegionMake3D(0, 0, 0, w, h, 1) mipmapLevel:0 slice:i]; } float *temp = calloc(w*h*channels, sizeof(float)); [self halfTofloat:htemp floatp:temp width:w height:h channel:channels]; float mean, var; for (int i = 0; i < featureNum; i++) { int slice = i / 4; int stride = i % 4; vDSP_normalize(temp+slice*w*h*numComponents+stride, numComponents, temp+slice*w*h*numComponents+stride, numComponents, &mean, &var, w*h); if (var == 0) { vDSP_vfill(&var, temp+slice*w*h*numComponents+stride, numComponents, w*h); } vDSP_vsmul(temp+slice*w*h*numComponents+stride, numComponents, &gamma[i], temp+slice*w*h*numComponents+stride, numComponents, w*h); vDSP_vsadd(temp+slice*w*h*numComponents+stride, numComponents, &beta[i], temp+slice*w*h*numComponents+stride, numComponents, w*h); } [self floatToHalf:temp halfp:htemp width:w height:h channel:channels]; for (int i = 0; i < numSlices; i++) { [image.texture replaceRegion:MTLRegionMake3D(0, 0, 0, w, h, 1) mipmapLevel:0 slice:i withBytes:htemp+w*h*numComponents*i bytesPerRow:w*numComponents*2 bytesPerImage:0]; } free(temp); free(htemp); free(gamma); free(beta); }
Nearest-Neighbor
This filling algorithm is not directly provided by Apple. There are some related methods in BlitCommand Encoder, but I feel it is a bit troublesome to use. It is a very simple filling algorithm. In addition, the previous BN has been implemented on the CPU. This is called twice, so I also directly implemented the calculation on the CPU.
The principle is very simple, that is to enlarge the image around the pixels to fill with this color value.
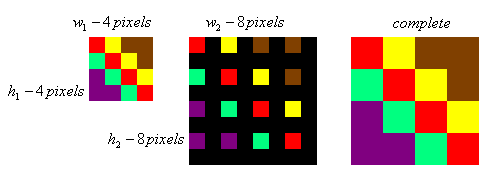
Implementation code:
- (void)ResizeNearestNeighbor:(MPSImage *)source destinationImage:(MPSImage *)destinationImage { NSUInteger w = source.texture.width; NSUInteger h = source.texture.height; NSUInteger w2 = destinationImage.texture.width; NSUInteger h2 = destinationImage.texture.height; NSUInteger featureNum = source.featureChannels; NSUInteger numSlices = (featureNum + 3) / 4; NSUInteger numComponents = featureNum < 3 ? featureNum : 4; NSUInteger channels = featureNum < 3 ? featureNum : numSlices * 4; float16_t *htemp1 = calloc(w*h*channels, sizeof(float16_t)); float16_t *htemp2 = calloc(w2*h2*channels, sizeof(float16_t)); for (int i = 0; i < numSlices; i++) { [source.texture getBytes:htemp1+w*h*numComponents*i bytesPerRow:w*numComponents*2 bytesPerImage:0 fromRegion:MTLRegionMake3D(0, 0, 0, w, h, 1) mipmapLevel:0 slice:i]; } int x_ratio = (int)((w<<16)/w2) +1; int y_ratio = (int)((h<<16)/h2) +1; int x2, y2 ; for (int k = 0; k < featureNum; k++) { int slice = k / 4; int stride = k % 4; for (int i=0;i<h2;i++) { for (int j=0;j<w2;j++) { x2 = ((j*x_ratio)>>16) ; y2 = ((i*y_ratio)>>16) ; htemp2[slice*w2*h2*numComponents+(i*w2+j)*numComponents+stride] = htemp1[slice*w*h*numComponents+((y2*w)+x2)*numComponents+stride]; } } } for (int i = 0; i < numSlices; i++) { [destinationImage.texture replaceRegion:MTLRegionMake3D(0, 0, 0, w2, h2, 1) mipmapLevel:0 slice:i withBytes:htemp2+w2*h2*numComponents*i bytesPerRow:w2*numComponents*2 bytesPerImage:0]; } free(htemp1); free(htemp2); }
Implementation of the whole network
Finally, the implementation of the whole network, referring to the structure and link order in the paper, where all convolutions are inherited MPSC Convolution objects, the code is a bit long as follows:
- (MPSImage *)forward:(CGImageRef)srcImage width:(int)width height:(int)height styles:(float *)styles { id<MTLCommandBuffer> commandbuffer = [commandQueue commandBuffer]; int w = width; int h = height; MTKTextureLoader *loader = [[MTKTextureLoader alloc] initWithDevice:mtDevice]; id<MTLTexture> srcTexture = [loader newTextureWithCGImage:srcImage options:nil error:nil]; MPSImage *cc1Image = [[MPSImage alloc] initWithTexture:srcTexture featureChannels:3]; // MPSImage *tImage = [[MPSImage alloc] initWithTexture:srcTexture featureChannels:3]; // MPSImageDescriptor *cc1Des = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:3]; // MPSImage *cc1Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:cc1Des]; // [cc1Image.texture replaceRegion:MTLRegionMake3D(0, 0, 0, w, h, 1) mipmapLevel:0 withBytes:srcImage bytesPerRow:w*4*2]; // contract MPSImageDescriptor *cc2Des = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:32]; MPSImage *cc2Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:cc2Des]; [contractConv1 encodeToCommandBuffer:commandbuffer sourceImage:cc1Image destinationImage:cc2Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:cc2Image styles:styles shift:cc1Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:cc2Image destinationImage:cc2Image]; w /= 2; h /= 2; MPSImageDescriptor *cc3Des = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:64]; MPSImage *cc3Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:cc3Des]; [contractConv2 encodeToCommandBuffer:commandbuffer sourceImage:cc2Image destinationImage:cc3Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:cc3Image styles:styles shift:cc2Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:cc3Image destinationImage:cc3Image]; w /= 2; h /= 2; MPSImageDescriptor *rcDes = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:128]; MPSImage *rc11Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [contractConv3 encodeToCommandBuffer:commandbuffer sourceImage:cc3Image destinationImage:rc11Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc11Image styles:styles shift:cc3Shift]; // residual commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:rc11Image destinationImage:rc11Image]; MPSImage *rc12Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual1Conv1 encodeToCommandBuffer:commandbuffer sourceImage:rc11Image destinationImage:rc12Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc12Image styles:styles shift:rc11Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:rc12Image destinationImage:rc12Image]; MPSImage *rc21Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual1Conv2 encodeToCommandBuffer:commandbuffer sourceImage:rc12Image destinationImage:rc21Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc21Image styles:styles shift:rc12Shift]; [self addImage:rc11Image B:rc21Image C:rc21Image]; commandbuffer = [commandQueue commandBuffer]; MPSImage *rc22Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual2Conv1 encodeToCommandBuffer:commandbuffer sourceImage:rc21Image destinationImage:rc22Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc22Image styles:styles shift:rc21Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:rc22Image destinationImage:rc22Image]; MPSImage *rc31Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual2Conv2 encodeToCommandBuffer:commandbuffer sourceImage:rc22Image destinationImage:rc31Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc31Image styles:styles shift:rc22Shift]; [self addImage:rc21Image B:rc31Image C:rc31Image]; commandbuffer = [commandQueue commandBuffer]; MPSImage *rc32Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual3Conv1 encodeToCommandBuffer:commandbuffer sourceImage:rc31Image destinationImage:rc32Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc32Image styles:styles shift:rc31Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:rc32Image destinationImage:rc32Image]; MPSImage *rc41Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual3Conv2 encodeToCommandBuffer:commandbuffer sourceImage:rc32Image destinationImage:rc41Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc41Image styles:styles shift:rc32Shift]; [self addImage:rc31Image B:rc41Image C:rc41Image]; commandbuffer = [commandQueue commandBuffer]; MPSImage *rc42Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual4Conv1 encodeToCommandBuffer:commandbuffer sourceImage:rc41Image destinationImage:rc42Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc42Image styles:styles shift:rc41Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:rc42Image destinationImage:rc42Image]; MPSImage *rc51Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual4Conv2 encodeToCommandBuffer:commandbuffer sourceImage:rc42Image destinationImage:rc51Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc51Image styles:styles shift:rc42Shift]; [self addImage:rc41Image B:rc51Image C:rc51Image]; commandbuffer = [commandQueue commandBuffer]; MPSImage *rc52Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual5Conv1 encodeToCommandBuffer:commandbuffer sourceImage:rc51Image destinationImage:rc52Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:rc52Image styles:styles shift:rc51Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:rc52Image destinationImage:rc52Image]; MPSImage *temp = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:rcDes]; [residual5Conv2 encodeToCommandBuffer:commandbuffer sourceImage:rc52Image destinationImage:temp device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:temp styles:styles shift:rc52Shift]; [self addImage:rc51Image B:temp C:temp]; // unsampling commandbuffer = [commandQueue commandBuffer]; w *= 2; h *= 2; MPSImageDescriptor *ec1Des = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:128]; MPSImage *ec1Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:ec1Des]; [self ResizeNearestNeighbor:temp destinationImage:ec1Image]; MPSImageDescriptor *temp2Des = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:64]; MPSImage *temp2 = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:temp2Des]; [expandConv1 encodeToCommandBuffer:commandbuffer sourceImage:ec1Image destinationImage:temp2 device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:temp2 styles:styles shift:ec1Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:temp2 destinationImage:temp2]; w *= 2; h *= 2; MPSImageDescriptor *ec2Des = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:64]; MPSImage *ec2Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:ec2Des]; [self ResizeNearestNeighbor:temp2 destinationImage:ec2Image]; MPSImageDescriptor *ec3Des = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:32]; MPSImage *ec3Image = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:ec3Des]; [expandConv2 encodeToCommandBuffer:commandbuffer sourceImage:ec2Image destinationImage:ec3Image device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:ec3Image styles:styles shift:ec2Shift]; commandbuffer = [commandQueue commandBuffer]; [relu encodeToCommandBuffer:commandbuffer sourceImage:ec3Image destinationImage:ec3Image]; MPSImageDescriptor *destDes = [MPSImageDescriptor imageDescriptorWithChannelFormat:MPSImageFeatureChannelFormatFloat16 width:w height:h featureChannels:3]; MPSImage *destImage = [[MPSImage alloc] initWithDevice:mtDevice imageDescriptor:destDes]; [expandConv3 encodeToCommandBuffer:commandbuffer sourceImage:ec3Image destinationImage:destImage device:mtDevice]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; [self batch_norm:destImage styles:styles shift:ec3Shift]; commandbuffer = [commandQueue commandBuffer]; [sigmoid encodeToCommandBuffer:commandbuffer sourceImage:destImage destinationImage:destImage]; [commandbuffer commit]; [commandbuffer waitUntilCompleted]; return destImage; }
epilogue
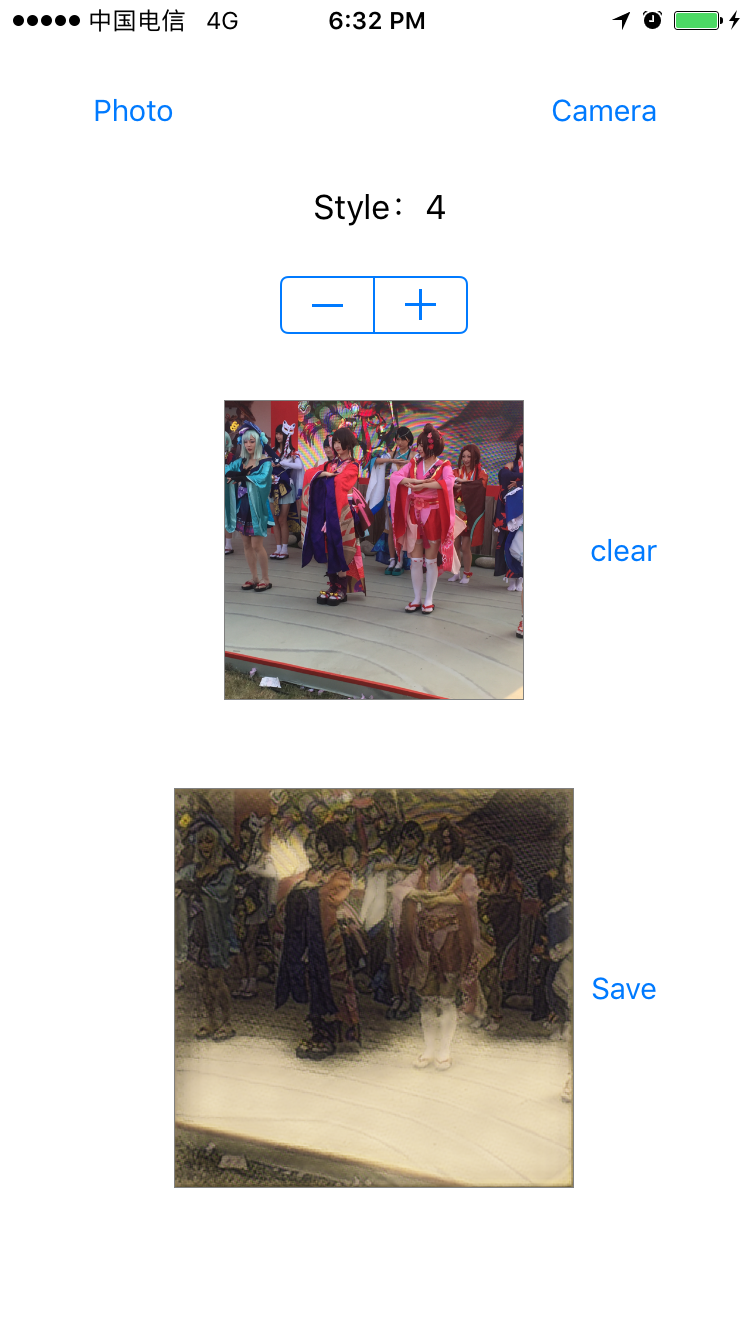
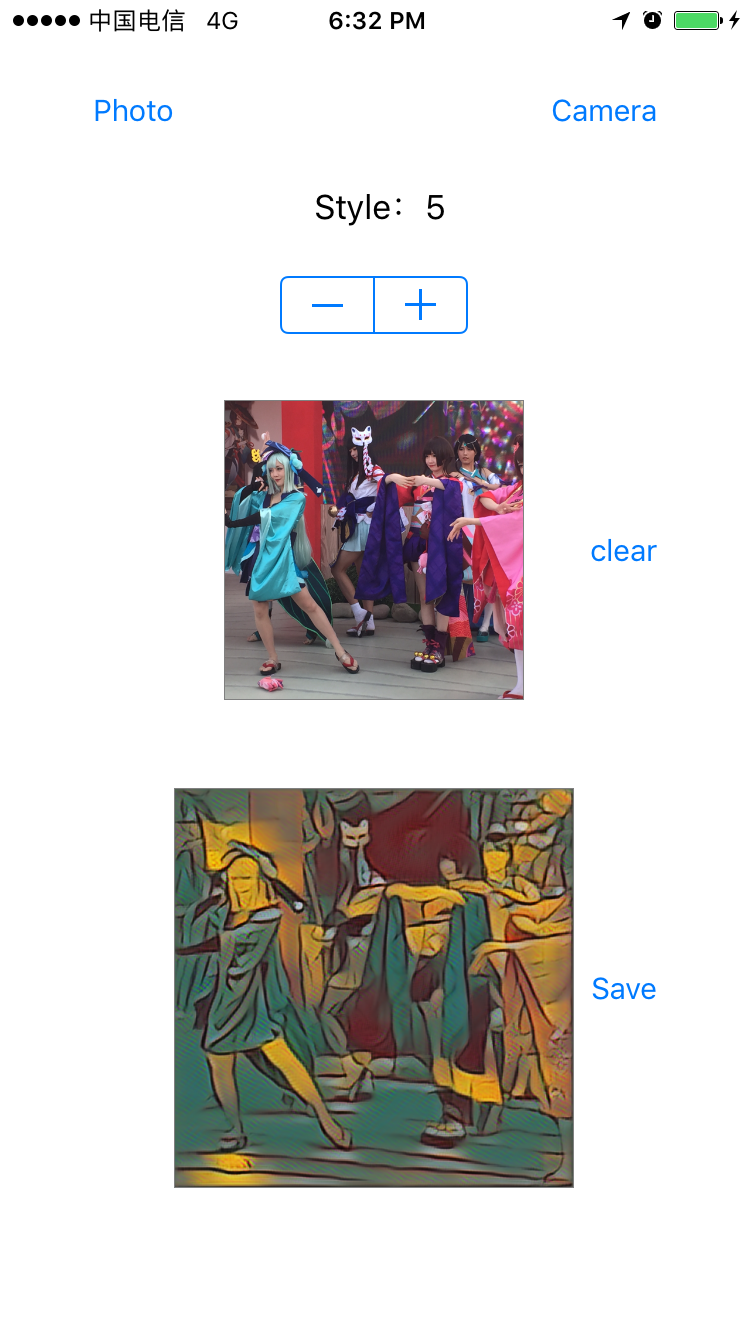
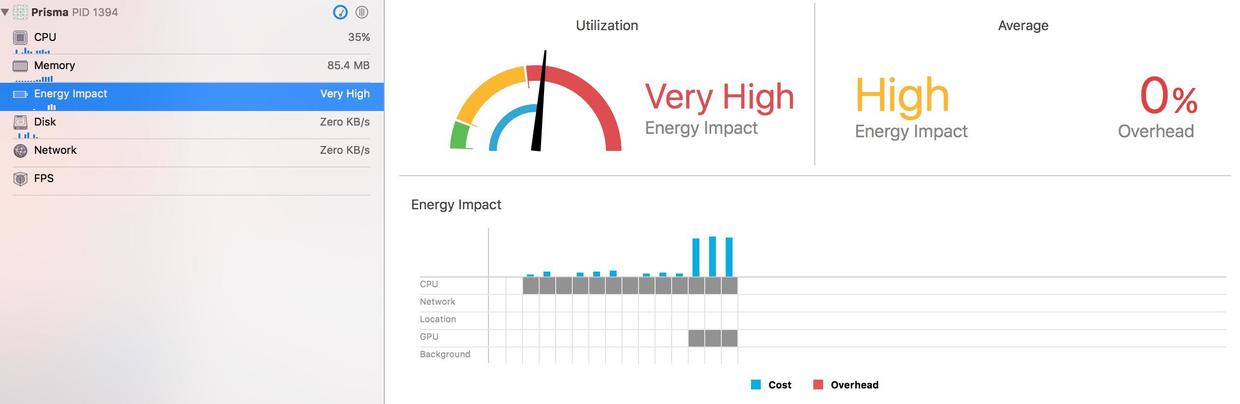
I don't want to leave anything behind. Let's put some program charts.