1. Introduction
Quratz is the most mature and widely used java task scheduling framework with powerful functions and flexible configuration. It plays an important role in enterprise applications. The way quratz is used in cluster environment is a problem that every enterprise system should consider. As early as 2006, there was a discussion on quratz cluster scheme on ITeye. http://www.iteye.com/topic/40970 ITeye founder @Robbin gave his opinion on quartz cluster application on the 8th floor.
Later, three quratz cluster schemes were summarized: http://www.iteye.com/topic/114965
-
Start a Job Server to run jobs, not deployed in a web container. Other web nodes can notify Job Server in various ways (DB, JMS, Web Service, etc.) when they need to start asynchronous tasks. Job Server receives this notification and loads asynchronous tasks into its own task queue.
-
Separate a job server, which runs a spring+quartz application, which is dedicated to starting tasks. Add hessain to the job server to get the business interface, so that the job server can call the business operation in the web container, that is to say, the Tomcat in the cluster or the real task. After jobserver starts the timing task, it invokes business operations on different addresses in turn (similar to apache distributing tomcat), which allows different timing tasks to run on different nodes and reduces the pressure on a node.
- Quartz itself actually supports clustering. In this scenario, each node on the cluster runs quartz, and then judges whether the operation is being performed by the state of the data records, which requires that all nodes on the cluster should have the same time. And the fact that every node runs applications means that every node needs its own thread pool to run quartz.
Generally speaking, the first method, which performs tasks on a single server, has a great limitation on the scope of application of tasks, and it is very troublesome to access various resources in the web environment. But centralized management can easily avoid the synchronization problems in the distributed environment from the architecture. The second method is reduced on the basis of the first method. The third scheme is the cluster scheme supported by quartz itself, which is totally distributed in architecture and has no centralized management. Ratz guarantees that multiple nodes do not acquire tasks repeatedly through database locks and identification fields, and has load balancing mechanism and fault tolerance mechanism. Ratz trades a small amount of redundancy for high avilable HA and high reliability. (Personally, the mechanism of Ratz and git has similarities and differences, distributed redundancy design, in exchange for reliability and speed.) .
The purpose of this paper is to study the mechanism of quratz to solve the problems of avoiding duplicate execution and load balancing in distributed task scheduling.
Refer to another article of the CRM project team for the configuration and application of quratz: CRM uses Quartz cluster to summarize and share.
2. Quatz Cluster Architecture
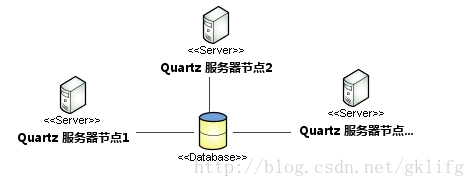
Quatz's distributed architecture, as shown above, shows that the database is the hub of the scheduler on each node. Each node does not perceive the existence of other nodes, but communicates indirectly through the database.
In fact, quartz's distributed strategy is a concurrent strategy with database as the boundary resource. Each node obeys the same operation criteria, so that the operation of database can be executed serially. Schedulers with different names can run concurrently without affecting each other.
Communication diagrams between components are as follows: (* Note: The main sql statements are attached at the end of the article)
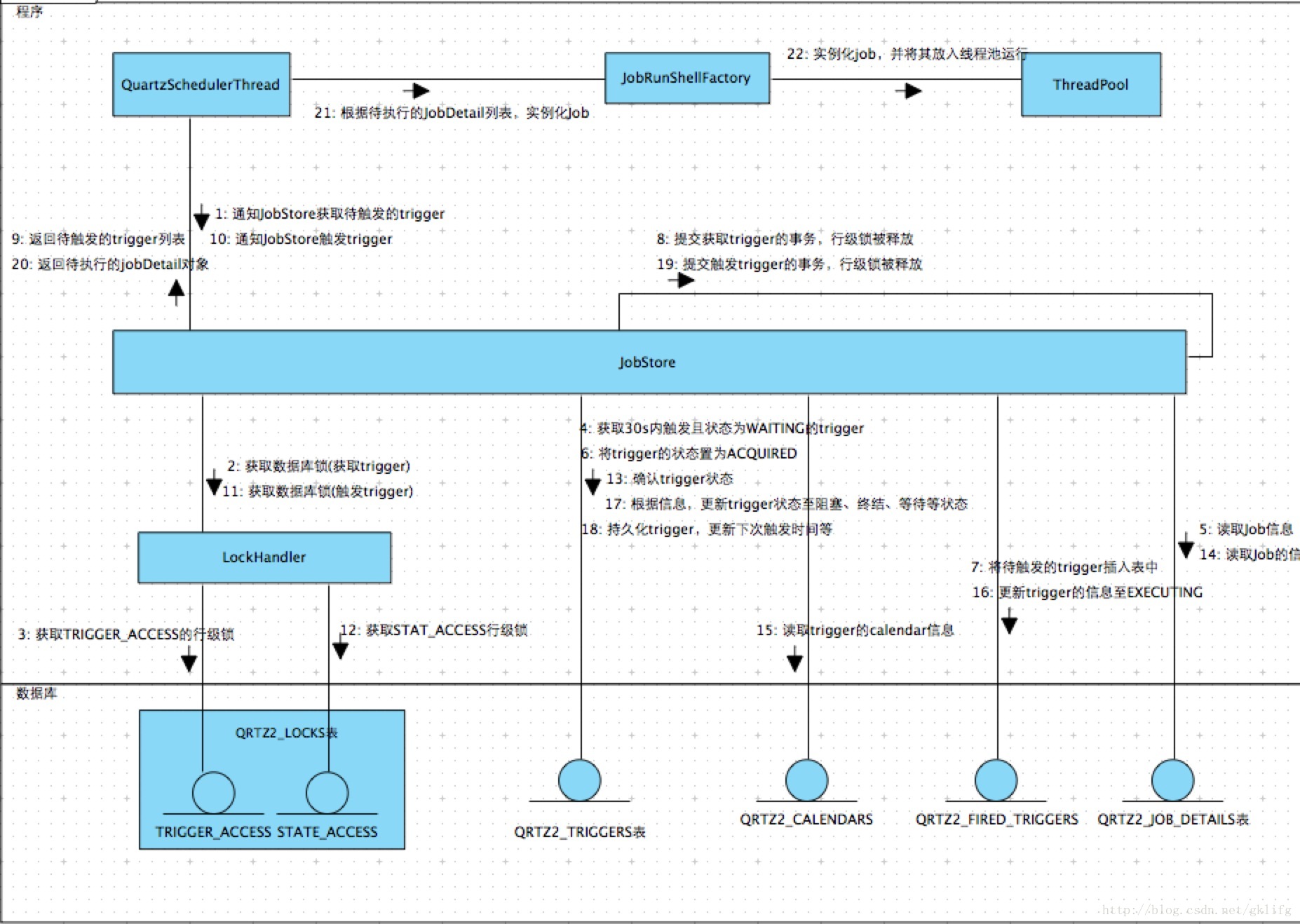
Quartz runtime uses the QuartzSchedulerThread class as the main body, and executes the scheduling process iteratively. JobStore, as the middle layer, performs database operations according to quartz's concurrency strategy and completes the main scheduling logic. JobRun ShellFactory is responsible for instantiating JobDetail objects and putting them into the thread pool to run. LockHandler is responsible for obtaining database locks in LOCKS tables.
The whole quartz scheduling sequence is roughly as follows:
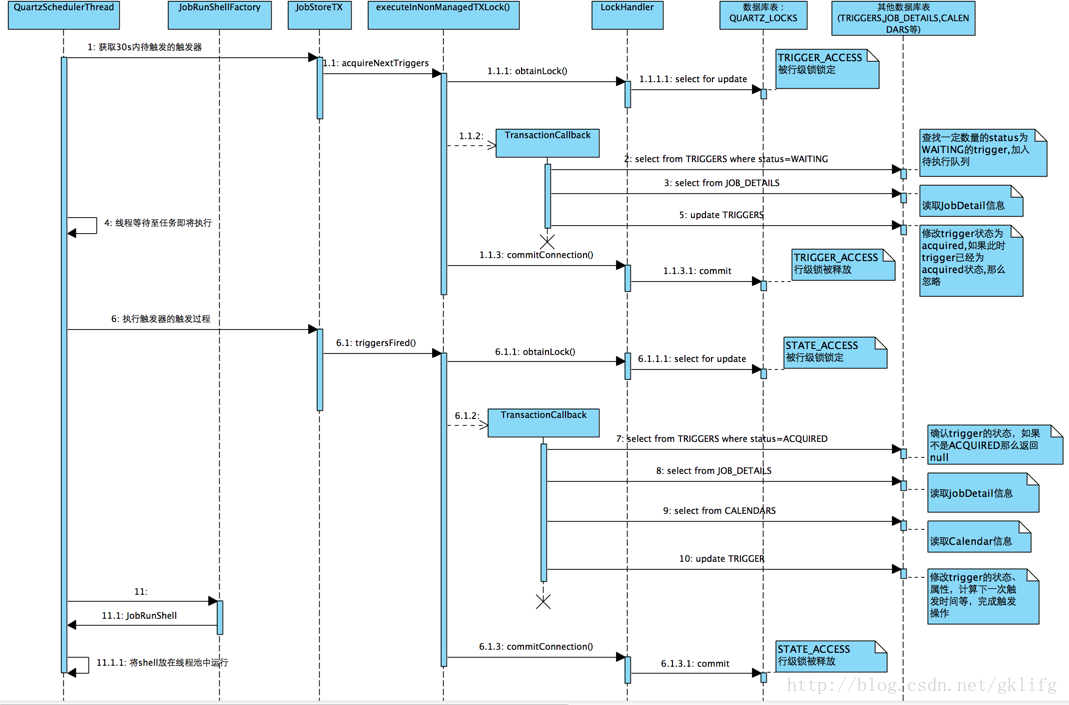
To sort out the process, it can be expressed as:
0. Scheduler thread run()
1. Get the trigger to be triggered
1.1 Database LOCKS Table TRIGGER_ACCESS Row Locking
1.2 Read JobDetail Information
1.3 Read the trigger information in the trigger table and mark it as "acquired"
1.4 commit transaction, release lock
2. Trigger trigger
2.1 Database LOCKS Table STATE_ACCESS Row Locking
2.2 Confirmation of trigger status
2.3 Read JobDetail Information of trigger
2.4 Read alendar information of trigger
2.3 Update trigger information
2.3 commit transaction, release lock
3 Instantiate and execute Job
3.1 Get the run method of thread execution JobRun Shell from thread poolAs you can see, there are two similar processes in this process: the update operation of the data table and the release of the lock after the lock operation is completed before the operation is executed. This rule can be regarded as the core idea of quartz to solve the cluster problem.
Rule flow chart:
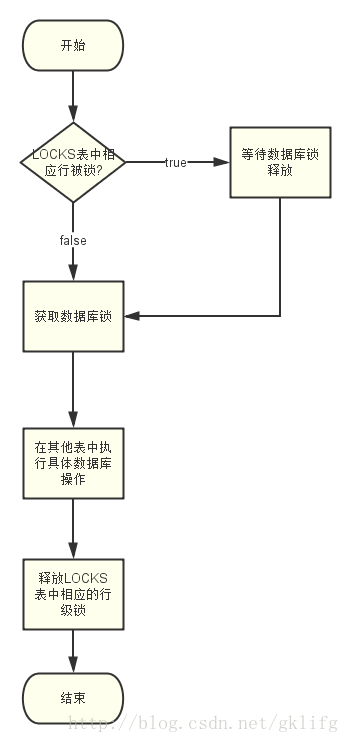
Further explanation of this rule is that before a scheduler instance performs a database operation involving distributed problems, it first acquires row-level locks corresponding to the previous scheduler in the QUARTZ2_LOCKS table, and then executes database operations in other tables. With the submission of operational transactions, row-level locks are released to provide other schedulers. Instance acquisition.
Each instance of the scheduler in the cluster follows such a strict operation procedure, so for the same kind of scheduler, the operation of each instance on the database can only be serial, while the schedulers with different names can be executed in parallel.
Now let's go into the source code and look at the details of quartz cluster scheduling from a micro perspective
3. Scheduler instantiation
A simplest quartz helloworld application is as follows:
public class HelloWorldMain { Log log = LogFactory.getLog(HelloWorldMain.class); public void run() { try { //Get the Schedule object SchedulerFactory sf = new StdSchedulerFactory(); Scheduler sch = sf.getScheduler(); JobDetail jd = new JobDetail("HelloWorldJobDetail",Scheduler.DEFAULT_GROUP,HelloWorldJob.class); Trigger tg = TriggerUtils.makeMinutelyTrigger(1); tg.setName("HelloWorldTrigger"); sch.scheduleJob(jd, tg); sch.start(); } catch ( Exception e ) { e.printStackTrace(); } } public static void main(String[] args) { HelloWorldMain hw = new HelloWorldMain(); hw.run(); } }
We see that to initialize a scheduler, we need to use the factory class to get an instance:
SchedulerFactory sf = new StdSchedulerFactory(); Scheduler sch = sf.getScheduler();
Then start:
sch.start();
Following up on StdScheduler Factory's getScheduler() method:
public Scheduler getScheduler() throws SchedulerException { if (cfg == null) { initialize(); } SchedulerRepository schedRep = SchedulerRepository.getInstance(); //Get a scheduler instance from the Scheduler Warehouse based on the Scheduler Name configuration of properties Scheduler sched = schedRep.lookup(getSchedulerName()); if (sched != null) { if (sched.isShutdown()) { schedRep.remove(getSchedulerName()); } else { return sched; } } //Initialization scheduler sched = instantiate(); return sched; }
Follow-up initialization sched = instantiate(); found to be more than 700 lines of initialization method, involving
- Read configuration resources.
- Generating the QuartzScheduler object,
- Create the running thread of the object and start the thread.
- Initialize JobStore, Quartz Scheduler, DBConnection Manager and other important components
So far, the initialization work of the scheduler has been completed. In the initialization work, quratz reads the lock information stored in the database corresponding to the previous scheduler, corresponding to the table QRTZ2_LOCKS in CRM, STATE_ACCESS in CRM and TRIGGER_ACCESS in two LOCK_NAME.
public void initialize(ClassLoadHelper loadHelper, SchedulerSignaler signaler) throws SchedulerConfigException { if (dsName == null) { throw new SchedulerConfigException("DataSource name not set."); } classLoadHelper = loadHelper; if(isThreadsInheritInitializersClassLoadContext()) { log.info("JDBCJobStore threads will inherit ContextClassLoader of thread: " + Thread.currentThread().getName()); initializersLoader = Thread.currentThread().getContextClassLoader(); } this.schedSignaler = signaler; // If the user hasn't specified an explicit lock handler, then // choose one based on CMT/Clustered/UseDBLocks. if (getLockHandler() == null) { // If the user hasn't specified an explicit lock handler, // then we *must* use DB locks with clustering if (isClustered()) { setUseDBLocks(true); } if (getUseDBLocks()) { if(getDriverDelegateClass() != null && getDriverDelegateClass().equals(MSSQLDelegate.class.getName())) { if(getSelectWithLockSQL() == null) { //Read the lock information in the database LOCKS table corresponding to the previous scheduler String msSqlDflt = "SELECT * FROM {0}LOCKS WITH (UPDLOCK,ROWLOCK) WHERE " + COL_SCHEDULER_NAME + " = {1} AND LOCK_NAME = ?"; getLog().info("Detected usage of MSSQLDelegate class - defaulting 'selectWithLockSQL' to '" + msSqlDflt + "'."); setSelectWithLockSQL(msSqlDflt); } } getLog().info("Using db table-based data access locking (synchronization)."); setLockHandler(new StdRowLockSemaphore(getTablePrefix(), getInstanceName(), getSelectWithLockSQL())); } else { getLog().info( "Using thread monitor-based data access locking (synchronization)."); setLockHandler(new SimpleSemaphore()); } } }
When calling sch.start(); method, scheduler does the following:
- Notify listener to start
- Start scheduler threads
- Start plugin
- Notify listener to start up
public void start() throws SchedulerException { if (shuttingDown|| closed) { throw new SchedulerException( "The Scheduler cannot be restarted after shutdown() has been called."); } // QTZ-212 : calling new schedulerStarting() method on the listeners // right after entering start() //Notify the listener of the scheduler to start notifySchedulerListenersStarting(); if (initialStart == null) { initialStart = new Date(); //Start the thread of the scheduler this.resources.getJobStore().schedulerStarted(); //Start plugins startPlugins(); } else { resources.getJobStore().schedulerResumed(); } schedThread.togglePause(false); getLog().info( "Scheduler " + resources.getUniqueIdentifier() + " started."); //Notify the listener of the scheduler to start and complete notifySchedulerListenersStarted(); }
4. Scheduling process
After the scheduler is started, the thread of the scheduler is in running state and begins to perform quartz's main task, scheduling tasks. As mentioned earlier, the task scheduling process can be roughly divided into three steps:
- Get the trigger to be triggered
- Trigger trigger
- Instantiate and execute Job
The source code of the three stages is analyzed below.
Quartz Scheduler Thread is a scheduler thread class. The three steps of the scheduling process are carried in the run() method. For analysis, see the code comments:
public void run() { boolean lastAcquireFailed = false; // while (!halted.get()) { try { // check if we're supposed to pause... synchronized (sigLock) { while (paused && !halted.get()) { try { // wait until togglePause(false) is called... sigLock.wait(1000L); } catch (InterruptedException ignore) { } } if (halted.get()) { break; } } /Gets the number of threads in the current thread pool int availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads(); if(availThreadCount > 0) { // will always be true, due to semantics of blockForAvailableThreads... List<OperableTrigger> triggers = null; long now = System.currentTimeMillis(); clearSignaledSchedulingChange(); try { //The scheduler looks for a certain number of triggers within 30 seconds in the trigger queue to prepare for scheduling. //Parameter 1:nolaterthan = now+3000ms, parameter 2 maximizes the number of fetches, size fetches thread pool thread residues and definitions are worth less //The default time window of parameter 3 is 0. The program will select trigger by adding window size after nolaterthan. triggers = qsRsrcs.getJobStore().acquireNextTriggers( now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow()); //The success of the previous step sets the failure flag to false. lastAcquireFailed = false; if (log.isDebugEnabled()) log.debug("batch acquisition of " + (triggers == null ? 0 : triggers.size()) + " triggers"); } catch (JobPersistenceException jpe) { if(!lastAcquireFailed) { qs.notifySchedulerListenersError( "An error occurred while scanning for the next triggers to fire.", jpe); } //If an exception is caught, the value is flagged as true and retrieved lastAcquireFailed = true; continue; } catch (RuntimeException e) { if(!lastAcquireFailed) { getLog().error("quartzSchedulerThreadLoop: RuntimeException " +e.getMessage(), e); } lastAcquireFailed = true; continue; } if (triggers != null && !triggers.isEmpty()) { now = System.currentTimeMillis(); long triggerTime = triggers.get(0).getNextFireTime().getTime(); long timeUntilTrigger = triggerTime - now;//Calculate the trigger time of distance trigger while(timeUntilTrigger > 2) { synchronized (sigLock) { if (halted.get()) { break; } //If the scheduler changes and a new trigger is added, it is possible that the new trigger is more likely to be added than the current trigger to be executed. //More urgently, you need to abandon the current trigger and retrieve it. However, there is a problem that the value is not worth it if you retrieve the new trigger. //It takes longer than the current time to start a new trigger, and even if the current trigger is abandoned, the xntrigger acquisition will still fail. //But we don't know how long it will take to get a new trigger, so we made a subjective judgement, if the job store is RAM, then //Assuming that the acquisition time is 7 ms, if the job store is persistent, assuming that it takes 70 ms, the difference between the current time and the trigger time of the new trigger is less than // We don't think it's worth retrieving this value and returning false. //It is not worth abandoning this trigger to determine whether or not this happens. If it does not abandon, the thread will wait for the trigger to trigger directly. if (!isCandidateNewTimeEarlierWithinReason(triggerTime, false)) { try { // we could have blocked a long while // on 'synchronize', so we must recompute now = System.currentTimeMillis(); timeUntilTrigger = triggerTime - now; if(timeUntilTrigger >= 1) sigLock.wait(timeUntilTrigger); } catch (InterruptedException ignore) { } } } //This method calls the above decision method as the logic of re-determination. //There are two ways to get there. 1. Decide to give up the current trigger, then decide again. If you still give up, empty the triggers list and // Exit the loop 2. Do nothing without giving up the current trigger and the thread has wait ed until the trigger triggers. if(releaseIfScheduleChangedSignificantly(triggers, triggerTime)) { break; } now = System.currentTimeMillis(); timeUntilTrigger = triggerTime - now; //At this point, the trigger is about to trigger, and the value will be less than 2. } // this happens if releaseIfScheduleChangedSignificantly decided to release triggers if(triggers.isEmpty()) continue; // set triggers to 'executing' List<TriggerFiredResult> bndles = new ArrayList<TriggerFiredResult>(); boolean goAhead = true; synchronized(sigLock) { goAhead = !halted.get(); } if(goAhead) { try { //Trigger triggers, and the result is paid to bndles. Note that when you return from here, the trigger has been locked and unlocked in the database. This process //So, quratz must not release the possession of trigger resources until job is executed, but release resources immediately after reading the information needed for this trigger. //Then execute jobs List<TriggerFiredResult> res = qsRsrcs.getJobStore().triggersFired(triggers); if(res != null) bndles = res; } catch (SchedulerException se) { qs.notifySchedulerListenersError( "An error occurred while firing triggers '" + triggers + "'", se); //QTZ-179 : a problem occurred interacting with the triggers from the db //we release them and loop again for (int i = 0; i < triggers.size(); i++) { qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i)); } continue; } } //Iterate trigger information and run job s separately for (int i = 0; i < bndles.size(); i++) { TriggerFiredResult result = bndles.get(i); TriggerFiredBundle bndle = result.getTriggerFiredBundle(); Exception exception = result.getException(); if (exception instanceof RuntimeException) { getLog().error("RuntimeException while firing trigger " + triggers.get(i), exception); qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i)); continue; } // it's possible to get 'null' if the triggers was paused, // blocked, or other similar occurrences that prevent it being // fired at this time... or if the scheduler was shutdown (halted) //In special cases, the bndle may be null. Looking at the triggerFired method, you can see that when you get the trigger from the database, if status is not //In the case of STATE_ACQUIRED, the scheduler starts the retry process and retrieves it four times, if there are still problems, // An exception is thrown. if (bndle == null) { qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i)); continue; } //Executing job JobRunShell shell = null; try { //Create a job unshell shell = qsRsrcs.getJobRunShellFactory().createJobRunShell(bndle); shell.initialize(qs); } catch (SchedulerException se) { qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR); continue; } //Put the run shell in the thread pool and run if (qsRsrcs.getThreadPool().runInThread(shell) == false) { // this case should never happen, as it is indicative of the // scheduler being shutdown or a bug in the thread pool or // a thread pool being used concurrently - which the docs // say not to do... getLog().error("ThreadPool.runInThread() return false!"); qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR); } } continue; // while (!halted) } } else { // if(availThreadCount > 0) // should never happen, if threadPool.blockForAvailableThreads() follows contract continue; // while (!halted) } //To ensure load balancing, this scheduler will wait for a random time after each trigger, so that schedulers on other nodes can get resources. long now = System.currentTimeMillis(); long waitTime = now + getRandomizedIdleWaitTime(); long timeUntilContinue = waitTime - now; synchronized(sigLock) { try { if(!halted.get()) { // QTZ-336 A job might have been completed in the mean time and we might have // missed the scheduled changed signal by not waiting for the notify() yet // Check that before waiting for too long in case this very job needs to be // scheduled very soon if (!isScheduleChanged()) { sigLock.wait(timeUntilContinue); } } } catch (InterruptedException ignore) { } } } catch(RuntimeException re) { getLog().error("Runtime error occurred in main trigger firing loop.", re); } } // while (!halted) // drop references to scheduler stuff to aid garbage collection... qs = null; qsRsrcs = null; }
Each trigger acquired by the scheduler needs to be executed within 30 seconds, so it has to wait for a period of time until 2 ms before the trigger is executed.
You can see that as long as the scheduler is running, it will continue to execute the scheduling process. It is worth noting that at the end of the process, the thread will wait for a random time. This is the load balancing mechanism of quartz.
Following are three steps to follow up:
4.1. Acquisition of triggers
Scheduler call:
triggers = qsRsrcs.getJobStore().acquireNextTriggers( now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
Find triggers that will be triggered in a certain time range in the database. The significance of the parameters is as follows: parameter 1:nolaterthan = now+3000ms, that is, triggers will be triggered in the next 30 seconds. The next trigger execution time is calculated after the trigger is triggered, and recorded in the NEXT_FIRE_TIME field of the database QRTZ2_TRIGGERS. Comparing the current milliseconds with the field when searching, we can find the trigger that will trigger in the next period of time. When searching, we call the method in the JobStoreSupport class:
public List<OperableTrigger> acquireNextTriggers(final long noLaterThan, final int maxCount, final long timeWindow) throws JobPersistenceException { String lockName; if(isAcquireTriggersWithinLock() || maxCount > 1) { lockName = LOCK_TRIGGER_ACCESS; } else { lockName = null; } return executeInNonManagedTXLock(lockName, new TransactionCallback<List<OperableTrigger>>() { public List<OperableTrigger> execute(Connection conn) throws JobPersistenceException { return acquireNextTrigger(conn, noLaterThan, maxCount, timeWindow); } }, new TransactionValidator<List<OperableTrigger>>() { public Boolean validate(Connection conn, List<OperableTrigger> result) throws JobPersistenceException { //... exception handling callback method } }); }
The key point of this method is to execute the executeInNonManagedTXLock() method, which specifies a lock name and two callback functions. Locks are acquired at the beginning of execution, and are released with transaction commit after execution of the method. At the bottom of this method, row-level locks are added to the database by using for update statement, which ensures that other schedulers will execute tr during execution of the method. When igger is acquired, it will wait for the scheduler to release the lock. This method is a concrete implementation of the quartz cluster strategy described earlier, and this template method will be used in the trigger trigger process later.
public static final String SELECT_FOR_LOCK = "SELECT * FROM " + TABLE_PREFIX_SUBST + TABLE_LOCKS + " WHERE " + COL_SCHEDULER_NAME + " = " + SCHED_NAME_SUBST + " AND " + COL_LOCK_NAME + " = ? FOR UPDATE";
Further explanation: quratz accesses the corresponding LOCK_NAME data in the LOCKS table for update before acquiring database resources. If the row has been locked before, wait, if not, read the required triggers, and set their status to STATE_ACQUIRED. If tirgger has been set to STATE_ACQUIRED, then the trigger has been locked. If it is claimed by other scheduler instances, the scheduler will ignore this trigger. The indirect communication between scheduler instances is embodied here.
In the JobStoreSupport.acquireNextTrigger() method:
int rowsUpdated = getDelegate().updateTriggerStateFromOtherState(conn, triggerKey, STATE_ACQUIRED, STATE_WAITING);
Finally, unlock the trigger. If the next scheduler queues to get the trigger, it will still perform the same steps. This mechanism ensures that the trigger will not be retrieved repeatedly. According to the normal operation of this algorithm, a considerable part of the trigger read by the scheduler will be marked as being retrieved.
The process of getting trigger is completed.
4.2. Trigger trigger
In Quartz Scheduler Thread: List < Trigger Fired Result > res = qsRsrcs. getJobStore (). triggers Fired (triggers);
Call the triggersFired() method of the JobStoreSupport class:
public List<TriggerFiredResult> triggersFired(final List<OperableTrigger> triggers) throws JobPersistenceException { return executeInNonManagedTXLock(LOCK_TRIGGER_ACCESS, new TransactionCallback<List<TriggerFiredResult>>() { public List<TriggerFiredResult> execute(Connection conn) throws JobPersistenceException { List<TriggerFiredResult> results = new ArrayList<TriggerFiredResult>(); TriggerFiredResult result; for (OperableTrigger trigger : triggers) { try { TriggerFiredBundle bundle = triggerFired(conn, trigger); result = new TriggerFiredResult(bundle); } catch (JobPersistenceException jpe) { result = new TriggerFiredResult(jpe); } catch(RuntimeException re) { result = new TriggerFiredResult(re); } results.add(result); } return results; } }, new TransactionValidator<List<TriggerFiredResult>>() { @Override public Boolean validate(Connection conn, List<TriggerFiredResult> result) throws JobPersistenceException { //... exception handling callback method } }); }
Here we use the quratz behavior specification again: executeInNonManagedTXLock() method to trigger the trigger when the lock is acquired. The trigger details are as follows:
protected TriggerFiredBundle triggerFired(Connection conn, OperableTrigger trigger) throws JobPersistenceException { JobDetail job; Calendar cal = null; // Make sure trigger wasn't deleted, paused, or completed... try { // if trigger was deleted, state will be STATE_DELETED String state = getDelegate().selectTriggerState(conn, trigger.getKey()); if (!state.equals(STATE_ACQUIRED)) { return null; } } catch (SQLException e) { throw new JobPersistenceException("Couldn't select trigger state: " + e.getMessage(), e); } try { job = retrieveJob(conn, trigger.getJobKey()); if (job == null) { return null; } } catch (JobPersistenceException jpe) { try { getLog().error("Error retrieving job, setting trigger state to ERROR.", jpe); getDelegate().updateTriggerState(conn, trigger.getKey(), STATE_ERROR); } catch (SQLException sqle) { getLog().error("Unable to set trigger state to ERROR.", sqle); } throw jpe; } if (trigger.getCalendarName() != null) { cal = retrieveCalendar(conn, trigger.getCalendarName()); if (cal == null) { return null; } } try { getDelegate().updateFiredTrigger(conn, trigger, STATE_EXECUTING, job); } catch (SQLException e) { throw new JobPersistenceException("Couldn't insert fired trigger: " + e.getMessage(), e); } Date prevFireTime = trigger.getPreviousFireTime(); // call triggered - to update the trigger's next-fire-time state... trigger.triggered(cal); String state = STATE_WAITING; boolean force = true; if (job.isConcurrentExectionDisallowed()) { state = STATE_BLOCKED; force = false; try { getDelegate().updateTriggerStatesForJobFromOtherState(conn, job.getKey(), STATE_BLOCKED, STATE_WAITING); getDelegate().updateTriggerStatesForJobFromOtherState(conn, job.getKey(), STATE_BLOCKED, STATE_ACQUIRED); getDelegate().updateTriggerStatesForJobFromOtherState(conn, job.getKey(), STATE_PAUSED_BLOCKED, STATE_PAUSED); } catch (SQLException e) { throw new JobPersistenceException( "Couldn't update states of blocked triggers: " + e.getMessage(), e); } } if (trigger.getNextFireTime() == null) { state = STATE_COMPLETE; force = true; } storeTrigger(conn, trigger, job, true, state, force, false); job.getJobDataMap().clearDirtyFlag(); return new TriggerFiredBundle(job, trigger, cal, trigger.getKey().getGroup() .equals(Scheduler.DEFAULT_RECOVERY_GROUP), new Date(), trigger .getPreviousFireTime(), prevFireTime, trigger.getNextFireTime()); }
The method does the following work:
- Get the current status of trigger
- Read the Job information contained in trigger through JobKey in trigger
- Update trigger to trigger state
- Triggering trigger with calendar information involves multiple status updates
- Update the trigger information in the database, including changing the status to STATE_COMPLETE and calculating the next trigger time.
- Data transmission class TriggerFiredBundle that returns trigger trigger results
After returning from this method, the execution process of trigger has been basically completed. Returning to the executeInNonManagedTXLock method which executes the quratz operation specification, the database lock is released.
Trigger trigger operation completed
4.3. Job execution process
Returning to line 353 of the thread class Quartz Scheduler Thread, the triggers are all started and the job details are in place.
QuartzSchedulerThread line:368
qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i)); shell.initialize(qs);
Generate a runnable Run Shell for each Job and run it in the thread pool.
In the final scheduling thread, a random waiting time is generated and a short waiting time is entered, which makes the scheduler of other nodes have the opportunity to access database resources. Thus, the load balance of quratz is realized.
This completes the entire scheduling process. The scheduler thread enters the next loop.
summary
Simply put, quartz's distributed scheduling strategy is an asynchronous strategy with database as boundary resource. Each scheduler follows an operation rule based on database lock to ensure the uniqueness of the operation. At the same time, the asynchronous operation of multiple nodes ensures the reliability of the service. However, this strategy has its own limitations. Description of quratz cluster characteristics:
Only one node will fire the job for each firing. What I mean by that is, if the job has a repeating trigger that tells it to fire every 10 seconds, then at 12:00:00 exactly one node will run the job, and at 12:00:10 exactly one node will run the job, etc. It won't necessarily be the same node each time - it will more or less be random which node runs it. The load balancing mechanism is near-random for busy schedulers (lots of triggers) but favors the same node for non-busy (e.g. few triggers) schedulers. The clustering feature works best for scaling out long-running and/or cpu-intensive jobs (distributing the work-load over multiple nodes). If you need to scale out to support thousands of short-running (e.g 1 second) jobs, consider partitioning the set of jobs by using multiple distinct schedulers (including multiple clustered schedulers for HA). The scheduler makes use of a cluster-wide lock, a pattern that degrades performance as you add more nodes (when going beyond about three nodes - depending upon your database's capabilities, etc.).
It is pointed out that the clustering feature works well for tasks with high cpu utilization, but for a large number of short tasks, each node will preempt the database lock, which will result in a large number of threads waiting for resources. This situation will become more and more serious with the increase of nodes.