background
In recent years, with the progress of society and the development of information and communication technology, the application of information system and Internet in various industries and fields has expanded rapidly. More and more data are collected, processed and accumulated by these systems, and the increase of data is faster and faster. The Vol Ume of data increases at an explosive rate every year. Before the emergence of the Internet, data was mainly generated by man-machine conversation, mainly structured data. So we all need traditional RDBMS to manage these data and application systems. At that time, the data growth was slow and the system was isolated, so the traditional RDBMS is relatively isolated. However, with the arrival of the era of big data, data has gradually changed to non-structured and semi-structured. People's use of data is not limited to business applications. Commonly used means of valuable information. Traditional databases are almost at a loss for such needs and applications, both technically and functionally. The unification of traditional database (OldSQL) has become a situation in which OldSQL+NewSQL+NoSQL+other technologies (streaming, real-time, memory, etc.) support multiple applications.
Product introduction
SequoiaDB Jushan database, focusing on the development of a new generation of large data infrastructure, is the leading domestic distributed database manufacturer of the new generation. SequoiaDB Jushan database is a new SQL database which supports SQL, high concurrency, real-time, distributed, scalable and flexible storage. In addition, SequoiaDB supports the docking of spark, hive, hadoop, kafka, postgreSQL and other large data tools. In application development, SequoiaDB not only provides native API, but also provides C driver, c++ driver, CSharp driver, java driver, PHP driver, REST interface and so on. Developers can easily and quickly use SequoiaDB for application development. This article will introduce how to use java API for application development.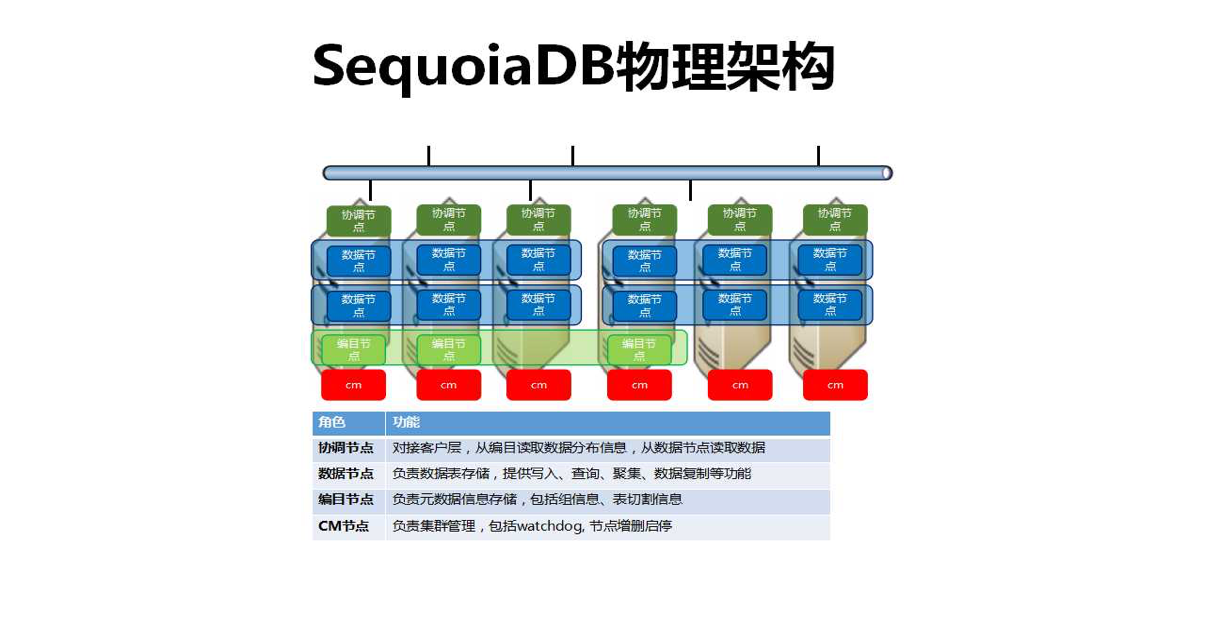
Application Development Advantages Using SequoiaDB
Flexible storage mode
SequoiaDB database is a document database, using JSON format to store data can effectively improve the development efficiency. As we all know, in the development of large-scale applications, many tables will be involved, and the relationship between tables will be particularly numerous. Especially in banking, Internet Finance and other industries, because of the complexity of business, the relationship between tables and tables will be extremely complex. When using traditional databases for development, tables need to be associated first, and the design of complex tables needs to invest a lot of money. Manpower, which not only wastes money, but also slows down the progress of development. In addition, in the later maintenance and upgrade, after many iterations, the fields in the table usually change. If the values of some fields need to be modified or deleted, it is difficult to determine whether the results of the changes will have an impact on other business systems. This requires developers to understand the business very well and raise the threshold of development. If the document database is used, the data is stored in JSON structure. Users can store the field of business system design in a table by using object method. When table association is involved, they can store data in a nested way in BSON. This makes developers do not need to spend a lot of energy in the design of tables, reducing the cost of development.
In addition, SequoiaDB is a dual-engine database, which supports data storage in JSON format and distributed object storage. It can support unstructured data management very well.
Low-cost deployment
SequoiaDB can be installed on X86 machines, which is a cost savings compared to the database installed in high-end storage. SequoiaDB uses a three-copy storage mode, which effectively ensures the security of data. In addition, due to the use of distributed, data is stored in multiple servers. When querying data, query tasks will be distributed to multiple machines at the same time, and finally aggregated on the same machine. This makes it possible to make full use of the resources of multiple servers, thus achieving low cost. Deployment and quick effect.
Supporting composite indexing
In traditional databases, many products only support a single index, while SequoiaDB also supports a composite index. In complex business systems, the amount of data is usually very large. When querying data, we usually need to take multiple query conditions, and also require fast response. This makes it difficult for a single index query to meet business needs. SequoiaDB can effectively solve this problem. According to the business query habits, developers can count out some query conditions that often need to be brought with them, so that they can create a composite index based on the conditions that must be brought with each query. When the business system queries, SequoiaDB will quickly query by index scanning.
High safety
SequoiaDB uses multi-copy storage mode. Developers plan to scatter data in different data groups. The nodes of the same data group are scattered on different machines. Because the data of the same data group are the same, when the server goes down, the database can quickly switch the main node to other nodes to provide service for the business system. At the same time, it can effectively prevent data loss.
Environment building
software configuration
Operating system: windows 8
JDK: 1.7.0_8064 bits, download address is: http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html#jdk-7u80-oth-JPR
Myeclipse: 12.0.0
SequoiaDB: 2.8.1. Installation Deployment Reference:
Java driver: 2.6.3, download address:
http://download.sequoiadb.com/cn/ index-cat_id-2
Configuring the Eclipse environment
Copy the sequoiadb.jar file in the SequoiaDB driver development kit to the project file directory (it is recommended to place it in all other dependent library directories, such as lib directory);
In the "Package Explore" window on the left side of the Eclipse main window, select the development project and click the right mouse button.
Select the "properties" menu item in the menu.
The pop-up "property for project..." In the window, select "Java Build Path" - > "Libraries", as shown in the following figure:
Click "Add External JARs..." Button, select to add sequoiadb.jar to the project;
Click "OK" to complete the environment configuration.
SequoiaDB Java Development Example
Example 1: List collection
Connect to the database and list all collection s in the database.
package com.sequoiadb.demo;
import com.sequoiadb.base.DBCursor;
import com.sequoiadb.base.Sequoiadb;
import com.sequoiadb.exception.BaseException;
public class Demo01 {
public static void main(String[] args) {
try{
String connStr = "192.168.43.237";
String userName = "";
String password = "";
//The 11810 port of this routine connected to the local database is the service port of the coordinating node, using empty usernames and
//Password. Users need to configure parameters according to their actual situation.
Sequoiadb sdb = new Sequoiadb(connStr,userName,password);
DBCursor cursor = sdb.listCollections();
try{
while(cursor.hasNext()){
System.out.println(cursor.getNext().toString());
}
}finally{
cursor.close();
}
}catch (BaseException e) {
System.out.println("Sequoiadb driver error, error description:" + e.getErrorType());
}
}
}
Example 2: Adding a lookup operation
Connect to the database, and do additional lookup operations on the records of test tables in the database.
package com.sequoiadb.demo;
import org.bson.BSONObject;
import org.bson.BasicBSONObject;
import com.sequoiadb.base.CollectionSpace;
import com.sequoiadb.base.DBCollection;
import com.sequoiadb.base.DBCursor;
import com.sequoiadb.base.Sequoiadb;
import com.sequoiadb.exception.BaseException;
public class Demo02 {
public static void main(String[] args) {
String connStr = "192.168.43.237:11810";
String userName = "";
String password = "";
DBCursor cursor = null;
try {
Sequoiadb sdb = new Sequoiadb(connStr,userName,password);
CollectionSpace db = sdb.createCollectionSpace("space");
DBCollection cl = db.createCollection("collection");
//DBCollection cl = sdb.getCollectionSpace("space")
.getCollection("collection");
// Create an inserted bson object
BSONObject obj = new BasicBSONObject();
obj.put("name", "xiaoming");
obj.put("age", 24);
//Add a record
cl.insert(obj);
//Query record
cursor = cl.query();
try{
while (cursor.hasNext()) {
BSONObject record = cursor.getNext();
String name = (String) record.get("name");
System.out.println("name=" + name);
}
}finally{
cursor.close();
}
} catch (BaseException e) {
System.out.println("Sequoiadb driver error, error description:" + e.getErrorType());
}
}
}
Example 3: Use of data connection pool
The basic principle of database connection pool is to maintain a certain number of database connections in the internal object pool, and to expose the methods of obtaining and returning database connections. For example, the external user can get the connection through the getConnection method, and then return the connection through the release Connection method after using it. Note that the connection is not closed at this time, but recycled by the connection pool manager, and ready for the next use.
Advantages of database connection pool technology:
Resource reuse: Because database connections are reused, a large amount of performance overhead caused by frequent creation and release of connections is avoided. On the basis of reducing system consumption, it also improves the stability of system running environment (reducing memory fragmentation and the number of database temporary processes/threads).
Faster system response speed: During the initialization of database connection pools, several database connections have been created for backup in the pool. At this point, the initialization of the connection has been completed. For business request processing, the time of database connection initialization and release process is avoided by directly utilizing available connections, thus reducing the overall response time of the system.
Unified connection management to avoid leakage of database connection: In a more complete database connection pool implementation, the occupied connection can be forcibly retrieved according to the pre-set connection occupancy timeout. This avoids the resource leakage that may occur in the routine database connection operation.
package com.sequoiadb.demo;
import java.util.ArrayList;
import org.bson.BSONObject;
import org.bson.BasicBSONObject;
import com.sequoiadb.base.CollectionSpace;
import com.sequoiadb.base.DBCollection;
import com.sequoiadb.base.DBCursor;
import com.sequoiadb.base.Sequoiadb;
import com.sequoiadb.base.SequoiadbDatasource;
import com.sequoiadb.datasource.ConnectStrategy;
import com.sequoiadb.datasource.DatasourceOptions;
import com.sequoiadb.exception.BaseException;
import com.sequoiadb.net.ConfigOptions;
public class Datasource {
public static void main(String[] args) throws InterruptedException {
ArrayList<String> addrs = new ArrayList<String>();
String user = "";
String password = "";
ConfigOptions nwOpt = new ConfigOptions();
DatasourceOptions dsOpt = new DatasourceOptions();
SequoiadbDatasource ds = null;
// Provide coord node address
addrs.add("192.168.43.237:11810");
addrs.add("zxq3:11810");
// Setting Network Parameters
nwOpt.setConnectTimeout(500); // The overtime time of Jianlian is 500 ms.
nwOpt.setMaxAutoConnectRetryTime(0); // The retrial time is 0 ms after the company failed.
// Setting connection pool parameters
dsOpt.setMaxCount(500); // Connection pools can provide up to 500 connections.
dsOpt.setDeltaIncCount(20); // Add 20 connections at a time.
dsOpt.setMaxIdleCount(20); // When the connection pool is free, 20 connections are reserved.
dsOpt.setKeepAliveTimeout(0); // The lifetime of idle connections in the pool. Unit: milliseconds.
// 0 means that you don't care how long the connection lasts without sending or receiving messages.
dsOpt.setCheckInterval(60 * 1000); // More than 60 seconds per connection pool
// MaxIdleCount-qualified idle connections are closed.
// And will survive too long (connection has stopped sending and receiving)
// Connections that exceed the keep Alive Timeout time are closed.
// Synchronize the cycle of coord addresses to catalog. Unit: milliseconds.
// 0 means asynchrony.
dsOpt.setSyncCoordInterval(0);
// When connecting out of the pool, whether to detect the availability of the connection is not detected by default.
dsOpt.setValidateConnection(false);
// Connections are acquired by default using the coord address load balancing policy.
dsOpt.setConnectStrategy(ConnectStrategy.BALANCE);
// Establish connection pool
ds = new SequoiadbDatasource(addrs, user, password, nwOpt, dsOpt);
// Running tasks using connection pools
runTask(ds);
// When the task is over, close the connection pool
ds.close();
}
static void runTask(SequoiadbDatasource ds) throws InterruptedException {
String clFullName = "mycs.mycl";
// Preparation task
Thread createCLTask = new Thread(new CreateCLTask(ds, clFullName));
Thread insertTask = new Thread(new InsertTask(ds, clFullName));
Thread queryTask = new Thread(new QueryTask(ds, clFullName));
// Create set
createCLTask.start();
createCLTask.join();
// Interpolate Records into Sets
insertTask.start();
Thread.sleep(3000);
// Look up records from collections
queryTask.start();
// Waiting for the end of the task
insertTask.join();
queryTask.join();
}
}
class CreateCLTask implements Runnable {
private SequoiadbDatasource ds;
private String csName;
private String clName;
public CreateCLTask(SequoiadbDatasource ds, String clFullName) {
this.ds = ds;
this.csName = clFullName.split("\\.")[0];
this.clName = clFullName.split("\\.")[1];
}
@Override
public void run() {
Sequoiadb db = null;
CollectionSpace cs = null;
DBCollection cl = null;
// Getting connection pools from connection pools
try {
db = ds.getConnection();
} catch (BaseException e) {
e.printStackTrace();
System.exit(1);
} catch (InterruptedException e) {
e.printStackTrace();
System.exit(1);
}
// Create collections using connections
if (db.isCollectionSpaceExist(csName))
db.dropCollectionSpace(csName);
cs = db.createCollectionSpace(csName);
cl = cs.createCollection(clName);
// Return the connection back to the connection pool
ds.releaseConnection(db);
System.out.println("Suceess to create collection " + csName + "." + clName);
}
}
class InsertTask implements Runnable {
private SequoiadbDatasource ds;
private String csName;
private String clName;
public InsertTask(SequoiadbDatasource ds, String clFullName) {
this.ds = ds;
this.csName = clFullName.split("\\.")[0];
this.clName = clFullName.split("\\.")[1];
}
@Override
public void run() {
Sequoiadb db = null;
CollectionSpace cs = null;
DBCollection cl = null;
BSONObject record = null;
// Getting connections from connection pools
try {
db = ds.getConnection();
} catch (BaseException e) {
e.printStackTrace();
System.exit(1);
} catch (InterruptedException e) {
e.printStackTrace();
System.exit(1);
}
// Using Connections to Get Collection Objects
cs = db.getCollectionSpace(csName);
cl = cs.getCollection(clName);
// Inserting Records Using Collection Objects
record = genRecord();
cl.insert(record);
// Return the connection back to the connection pool
ds.releaseConnection(db);
System.out.println("Suceess to insert record: " + record.toString());
}
private BSONObject genRecord() {
BSONObject obj = new BasicBSONObject();
obj.put("name", "James");
obj.put("age", 30);
return obj;
}
}
class QueryTask implements Runnable {
private SequoiadbDatasource ds;
private String csName;
private String clName;
public QueryTask(SequoiadbDatasource ds, String clFullName) {
this.ds = ds;
this.csName = clFullName.split("\\.")[0];
this.clName = clFullName.split("\\.")[1];
}
@Override
public void run() {
Sequoiadb db = null;
CollectionSpace cs = null;
DBCollection cl = null;
DBCursor cursor = null;
// Getting connections from connection pools
try {
db = ds.getConnection();
} catch (BaseException e) {
e.printStackTrace();
System.exit(1);
} catch (InterruptedException e) {
e.printStackTrace();
System.exit(1);
}
// Using Connections to Get Collection Objects
cs = db.getCollectionSpace(csName);
cl = cs.getCollection(clName);
// Query with Collection Objects
cursor = cl.query();
try {
while(cursor.hasNext()) {
System.out.println("The inserted record is: " + cursor.getNext());
}
} finally {
cursor.close();
}
// Return the connection object to the connection pool
ds.releaseConnection(db);
}
}
Because SequoiaDB's Java API involves many operations, there are not one example here. Other operations are similar in use, which can be referred to as follows:
http://doc.sequoiadb.com/cn/index/Public/Home/document/208/api/java/html/index.html
SequoiaDB support for persistence layer framework
In software development, almost all large-scale applications use the framework to develop. The framework has reusability, which greatly improves the development speed of an application. Similar to Mybatis, Hibernate and other frameworks, these frameworks encapsulate the process of JDBC operating database, so that developers only need to pay attention to sql itself, and do not need to spend energy to deal with the complicated process code of jdbc, such as registration driver, connection creation, statement creation, manual parameter setting, result set retrieval, etc. Sequoia sql, a suite of SequoiaDB databases, is an extension of PostgreSQL functionality. Through Sequoia sql, users can use sql statements to access Sequoia DB database, and complete the operations of adding, deleting and modifying the database. When Sequoia sql integrates the persistence layer framework, it only needs to use the JDBC connection driver of postgreSQL. Its integration process is the same as that of other frameworks.
Summary
With the explosive growth of data, centralized databases are showing more and more deficiencies, and distributed databases are becoming more and more popular with developers. SequoiaDB is a new SQL database which supports SQL, high concurrency, real-time, distributed, scalable and flexible storage. It supports the connection of Spark, Hadoop, hive and other data products, and provides multi-language drivers for developers to use. SequoiaDB is undoubtedly a good choice when choosing to use distributed databases.
