- reference resources:
- Introduction and practice of deep learning framework PyTorch -- Chen Yun
- Hands on deep learning (PyTorch version) - Li Mu
- Note: since this article is converted from the jupyter document, the code may not run directly. Some comments are the interaction results given by jupyter, not the running results!!
- In PyTorch, tensor torch.Tensor is the main tool for storing and transforming data
- Tensor is very similar to NumPy's multidimensional array ndarray. In contrast, tensor provides more functions such as GPU calculation and automatic gradient calculation, making it more suitable for deep learning.
1. Create Tensor
- The creation method is similar to NumPy's ndarray. Some common API s are as follows
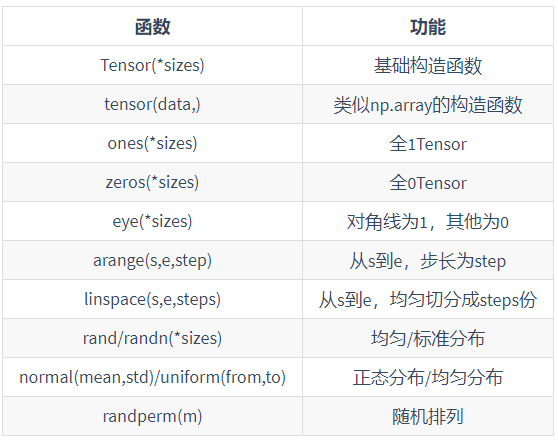
- Example:
import torch print('Create a 5 x3 The is not initialized tensor') x = torch.empty(5,3) print(x,'\n') print('Create a 5 x3 Random initialization of tensor,The data is an integer') x = torch.IntTensor(5,3) # rnadn() generates floating-point data of the specified dimension, which follows the normal distribution with mean value of 0 and variance of 1 print(x,'\n') print('Create a 5 x3 Random initialization of tensor,The data is floating point') x = torch.FloatTensor(5,3) # rnadn() generates floating-point data of the specified dimension, which follows the normal distribution with mean value of 0 and variance of 1 print(x,'\n') print('Create a 5 x3 Random initialization of tensor,The data is floating point, subject to 0-1 Interval uniform distribution') x = torch.rand(5,3) # rnad() generates floating-point data of the specified dimension, and the data is evenly distributed in the 0-1 interval print(x,'\n') print('Create a 5 x3 Random initialization of tensor,The data is floating-point and follows the normal distribution with mean value of 0 and variance of 1') x = torch.rand(5,3) # rnadn() generates floating-point data of the specified dimension, which follows the normal distribution with mean value of 0 and variance of 1 print(x,'\n') print('Create a closed left and open right according to the start, stop and step size range Sequence, similar Numpy Medium arange()') x = torch.arange(0,11,2,dtype = torch.int) # rnadn() generates floating-point data of the specified dimension, which follows the normal distribution with mean value of 0 and variance of 1 print(x,'\n') print('Create a 5 x3 of long Type all zero Tensor') x = torch.zeros(5,3,dtype=torch.long) print(x,'\n') print('Direct basis pythons Data creation, you can specify the data type') x = torch.tensor([5.5,3],dtype = torch.int32) print(x,'\n') print('Through existing tensor To create and reuse attributes such as data types by default, unless you customize these attributes') x = torch.ones(5,3,dtype=torch.float64) print(x) print("Borrow the shape and specify a new data type") x = torch.randn_like(x,dtype=torch.float) print(x) - You can obtain the shape of Tensor through. Shape or. size(). The returned torch.Size is a tuple, which supports all tuple operations
x = torch.zeros(5,5) print(x.size()) # torch.Size([5, 5]) print(x.shape) # torch.Size([5, 5])
2. Operation
- Tensor in PyTorch supports more than 100 operations, including transpose, index, slice, mathematical operation, linear algebra, random number, etc. for reference Official documents
2.1 arithmetic operation
-
In pytoch, the same operation may take many forms. Take addition as an example
x = torch.tensor([[5,3],[4,6]]) y = torch.tensor([[5,3],[4,6]]) # Method 1: directly use operation symbols print(x+y,'\n') # Method 2: using the torch.add static method, you can specify the output through the out parameter (consistent size is required) res = torch.empty(2,2) torch.add(x,y,out = res) print(res,'\n') # Method 3: inplace form (this form will modify the value of y) y.add_(x) print(y,'\n')
-
Note: the inplace version of pytoch operation has suffix, E.g. y.add_(x),y.copy_(y),y.t_ () and so on. The inplace method will modify the value of Y, which can avoid reopening the memory and is faster
2.2 index
- You can use an index operation similar to NumPy to access part of Tensor. It should be noted that the indexed results share memory with the original data, that is, if you modify one, the other will be modified
x = torch.tensor([[5,3],[4,6]]) print(x) y = x[0,:][0] y += 1 x[0,:][1] -= 1 print(x) # output tensor([[5, 3], [4, 6]]) tensor([[6, 2], [4, 6]]) - There are many special indexes that can be checked when they are used
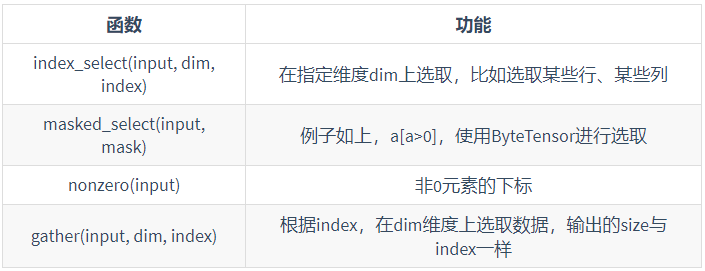
x = torch.tensor([[1,2],[3,4],[5,6]]) print(torch.index_select(x,1,torch.tensor([1]))) print(torch.masked_select(x,x>4)) # output tensor([[2], [4], [6]]) tensor([5, 6])
2.3 changing Tensor shape
-
Use tensor.view() to change the shape of Tensor. Note that the Tensor returned by view() shares data with the source Tensor, that is, changing one of them will change the other. (as the name suggests, view only changes the observation angle of this Tensor, and the internal data does not change)
x = torch.randn(5,3) y = x.view(15) z = x.view(-1,5) # -The dimension referred to in 1 can be derived from the values of other dimensions print(x.size(),y.size(),z.size()) # torch.Size([5, 3]) torch.Size([15]) torch.Size([3, 5])
-
If you want to return a real copy, you can first create a copy using the Tensor.clone() method, and then modify the shape using the Tensor.view() method, as shown below
x = torch.rand(5,3) y = x.clone().view(15) y[y<0.5] = 0 print(x) print(y) # output tensor([[0.2987, 0.1410, 0.2219], [0.3753, 0.8129, 0.4814], [0.1228, 0.0604, 0.6366], [0.1716, 0.1970, 0.1454], [0.8926, 0.3561, 0.2427]]) tensor([0.0000, 0.0000, 0.0000, 0.0000, 0.8129, 0.0000, 0.0000, 0.0000, 0.6366, 0.0000, 0.0000, 0.0000, 0.8926, 0.0000, 0.0000])Note: another advantage of using clone is that it will be recorded in the calculation diagram, that is, when the gradient is returned to the copy, it will also be transferred to the source Tensor
-
Another common function is Tensor.item(), which converts a scalar Tensor to Python member
x = torch.FloatTensor(1) print(x) print(x.item()) # output tensor([1.4013e-45]) 1.401298464324817e-45
2.4 linear algebra
- Common methods, which can be checked when used
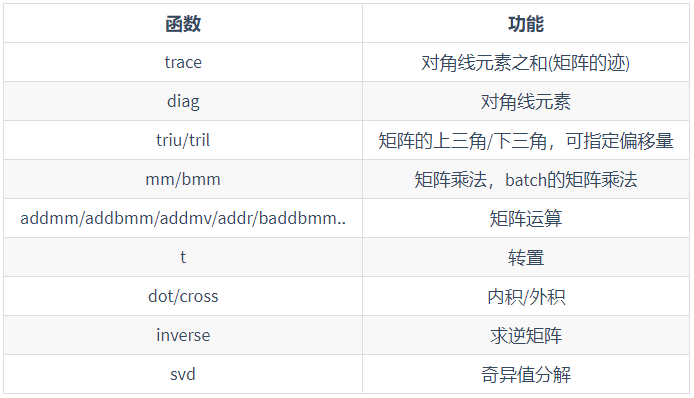
3. Broadcasting mechanism
-
Two tensors with the same shape can be calculated by element intuitively
-
Two tensors with different shapes may trigger the boardcasting mechanism when calculating by element: first copy the elements appropriately to make the two tensors have the same shape, and then operate by element, for example
x = torch.arange(1, 3).view(1, 2) # size = 2 -> size = (1,2) print(x) y = torch.arange(1, 4).view(3, 1) # size = 3 -> size = (3,1) print(y) print(x + y) # output tensor([[1, 2]]) tensor([[1], [2], [3]]) tensor([[2, 3], [3, 4], [4, 5]])Here, X and y are matrices of (1,2) and (3,1), respectively. If x + y is to be calculated, then
- The 2 elements of the first line in x are broadcast (copied) to the second and third lines
- The three elements of the first column in y are broadcast (copied) to the second column
In this way, two (3,2) matrices can be added by elements.
4. Memory overhead of operation
-
Index operations do not open up new memory, but operations such as y = x + y open up new memory, and then point y to the new memory
-
We can use Python's own ID function to determine whether a new memory has been opened: if the IDs of two instances are the same, their corresponding memory addresses are the same; Otherwise, it is different (indicating that new memory is opened up)
x = torch.tensor([1, 2]) y = torch.tensor([3, 4]) id_before = id(y) y = y + x print(id(y) == id_before) # False
-
If you want to specify the result to the original memory, for example, write the result of x + y into the memory corresponding to y without opening a new space, there are the following methods
- Replace with index: y[:] = x + y
- Use the out parameter in the operation function to set: torch.add(x, y, out=y)
- Use self addition operator: y += x
- Use the operation function of inplace version: y.add_(x)
Note: Although the Tensor returned by the view shares data with the source Tensor, it is still a new Tensor (because Tensor has some other attributes bes id es data), and their IDs (memory addresses) are not consistent.
5. Conversion between tensor and ndarray
-
Tensor in PyTorch and ndarray in NumPy can be easily converted to each other, so that we can combine NumPy's powerful matrix operation ability with Tensor's support for GPIU acceleration. All tensors on CPU (except CharTensor) support mutual conversion with NumPy ndarray
-
Common conversion methods
- Tensor -> ndarray: ndarray = Tensor.numpy()
- ndarray -> Tensor: Tensor = torch.from_numpy(ndarray)
It should be noted that Tensor and ndarray generated by these two functions share the same memory (so the conversion between them is fast). When you change one of them, the other will also change!!!
# Tensor -> ndarray a = torch.ones(5) b = a.numpy() print(a, b) # tensor([1., 1., 1., 1., 1.]) [1. 1. 1. 1. 1.] a += 1 print(a, b) # tensor([2., 2., 2., 2., 2.]) [2. 2. 2. 2. 2.] b += 1 print(a, b) # tensor([3., 3., 3., 3., 3.]) [3. 3. 3. 3. 3.]
# ndarray -> Tensor import numpy as np a = np.ones(5) b = torch.from_numpy(a) print(a, b) # [1. 1. 1. 1. 1.] tensor([1., 1., 1., 1., 1.], dtype=torch.float64) a += 1 print(a, b) # [2. 2. 2. 2. 2.] tensor([2., 2., 2., 2., 2.], dtype=torch.float64) b += 1 print(a, b) # [3. 3. 3. 3. 3.] tensor([3., 3., 3., 3., 3.], dtype=torch.float64)
-
Another common method of ndarray - > tensor is to directly make ndarray construct tensor, that is, use the torch.tensor() method. This method will always copy the data (which will consume more time and space), so the returned tensor and the original data will no longer share memory
a = np.ones(5) c = torch.tensor(a) a += 1 print(a, c) # [2. 2. 2. 2. 2.] tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
6. Tensor on GPU
-
When creating tensors, they are processed in the CPU by default. By setting the device parameter, they can be created as tensors processed in the GPU
-
With the Tensor.to() method, Tensor can be moved between CPU and GPU
-
Using the Tensor.cuda() method, you can convert CPU Tensor to GPU Tensor
x = torch.tensor([1, 2]) # Tensor created directly in this way is processed in the CPU # The following code will only be executed on the PyTorch GPU version if torch.cuda.is_available(): device = torch.device("cuda") # GPU y = torch.ones_like(x, device=device) # By setting the device parameter, the Tensor processed in the GPU can be directly created x = x.to(device) # Equivalent to. to("cuda") z = x + y print(z) print(z.to("cpu", torch.double)) # to() can also change the data type at the same time # output tensor([2, 3], device='cuda:0') tensor([2., 3.], dtype=torch.float64)x = torch.tensor([1, 2]) y = torch.tensor([2, 3]) if torch.cuda.is_available(): x = x.cuda() y = y.cuda() z = x + y print(z) # tensor([3, 5], device='cuda:0')