1. Analysis before crawling of review data of Haiwang
Haiwang was shown, and then the word of mouth exploded. For us, there's another movie that can be climbed and analyzed. It's so beautiful~
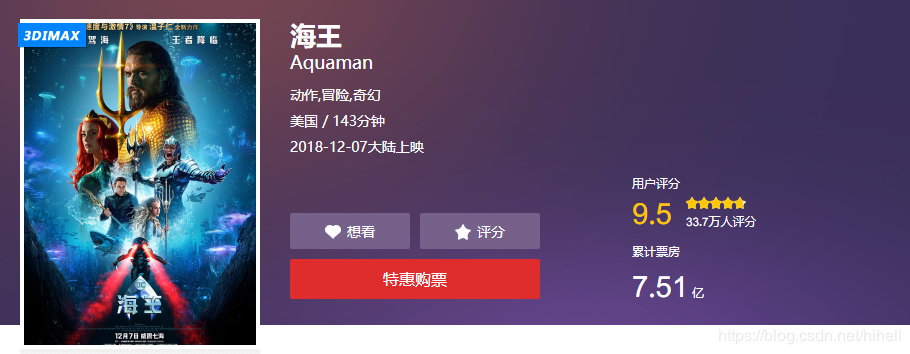
Excerpt a comment
Just after watching zero field, Director Wen's movie has been very good, whether it's speed 7, chainsaw or soul summoning. Fighting and sound effects are excellent, especially shocking. In a word, DC pulls back one point. More than a little bit better than the justice Alliance (my personal feeling). And aimebershild is really beautiful. The people selected by Director Wen are very good.
It's the first time I've seen a movie that's so awesome
2. Haiwang case starts to crawl data
Data crawling is still the comment of cat's eye. In this part, let's use a bull knife and a scrape to crawl. In general, just use requests
Grab address
http://m.maoyan.com/mmdb/comments/movie/249342.json?_v_=yes&offset=15&startTime=2018-12-11%2009%3A58%3A43
key parameter
url:http://m.maoyan.com/mmdb/comments/movie/249342.json offset:15 startTime:Starting time
It's very easy to crawl cat's eye code with the help of scratch. I can separate several py files.
Haiwang.py
import scrapy
import json
from haiwang.items import HaiwangItem
class HaiwangSpider(scrapy.Spider):
name = 'Haiwang'
allowed_domains = ['m.maoyan.com']
start_urls = ['http://m.maoyan.com/mmdb/comments/movie/249342.json?_v_=yes&offset=0&startTime=0']
def parse(self, response):
print(response.url)
body_data = response.body_as_unicode()
js_data = json.loads(body_data)
item = HaiwangItem()
for info in js_data["cmts"]:
item["nickName"] = info["nickName"]
item["cityName"] = info["cityName"] if "cityName" in info else ""
item["content"] = info["content"]
item["score"] = info["score"]
item["startTime"] = info["startTime"]
item["approve"] = info["approve"]
item["reply"] = info["reply"]
item["avatarurl"] = info["avatarurl"]
yield item
yield scrapy.Request("http://m.maoyan.com/mmdb/comments/movie/249342.json?_v_=yes&offset=0&startTime={}".format(item["startTime"]),callback=self.parse)
setting.py
Setting requires configuring headers
DEFAULT_REQUEST_HEADERS = {
"Referer":"http://m.maoyan.com/movie/249342/comments?_v_=yes",
"User-Agent":"Mozilla/5.0 Chrome/63.0.3239.26 Mobile Safari/537.36",
"X-Requested-With":"superagent"
}Some fetching conditions need to be configured
# Obey robots.txt rules ROBOTSTXT_OBEY = False # See also autothrottle settings and docs DOWNLOAD_DELAY = 1 # Disable cookies (enabled by default) COOKIES_ENABLED = False
Pipe opening
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'haiwang.pipelines.HaiwangPipeline': 300,
}
items.py
Get the data you want
import scrapy
class HaiwangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
nickName = scrapy.Field()
cityName = scrapy.Field()
content = scrapy.Field()
score = scrapy.Field()
startTime = scrapy.Field()
approve = scrapy.Field()
reply =scrapy.Field()
avatarurl = scrapy.Field()pipelines.py
Save the data to a csv file
import os
import csv
class HaiwangPipeline(object):
def __init__(self):
store_file = os.path.dirname(__file__) + '/spiders/haiwang.csv'
self.file = open(store_file, "a+", newline="", encoding="utf-8")
self.writer = csv.writer(self.file)
def process_item(self, item, spider):
try:
self.writer.writerow((
item["nickName"],
item["cityName"],
item["content"],
item["approve"],
item["reply"],
item["startTime"],
item["avatarurl"],
item["score"]
))
except Exception as e:
print(e.args)
def close_spider(self, spider):
self.file.close()
begin.py
Write run script
from scrapy import cmdline
cmdline.execute(("scrapy crawl Haiwang").split())
Get up, take care of it, wait for the data to arrive, it's OK
