Introduction to Pandas (Learning Notes 1) - Data Structure of Pandas
Data structure of Pandas
Pandas has two main and most important data structures: Series and DataFrame
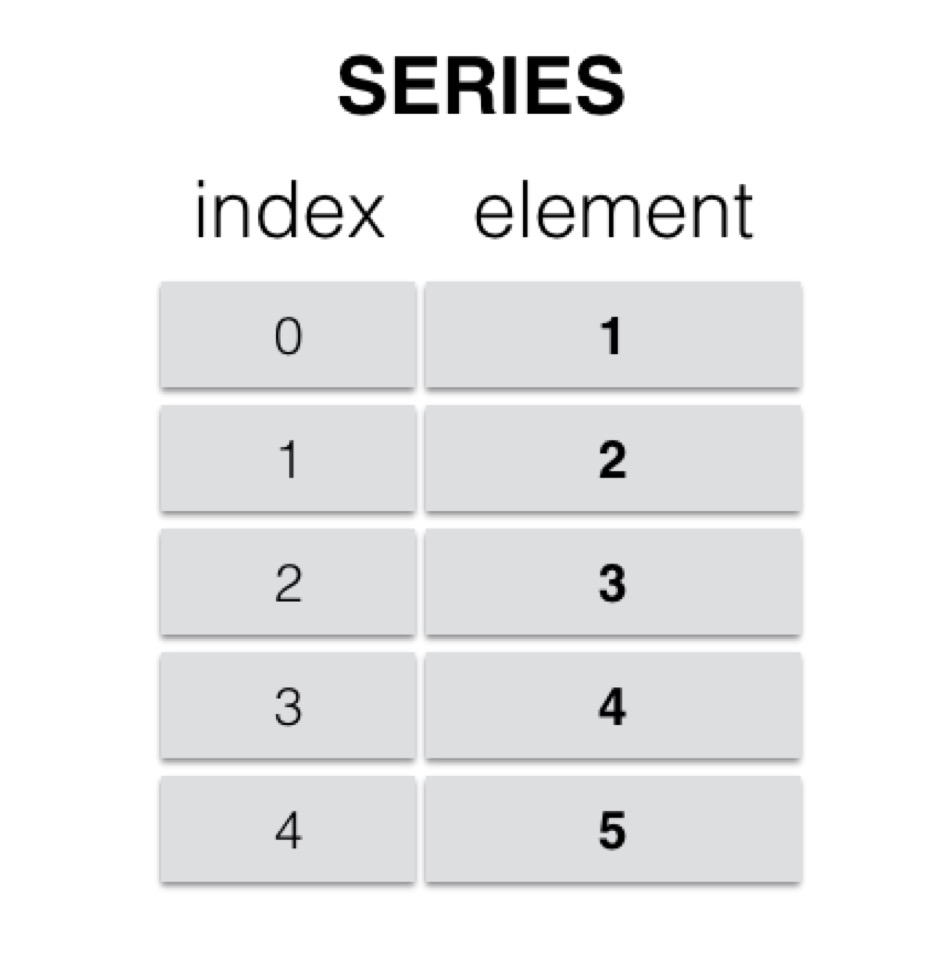
Series
Series is an object similar to a one-dimensional array, consisting of a set of data (various NumPy data types) and a set of corresponding indexes (data labels).
- Objects similar to one-dimensional arrays
- Composed of data and indexes
- The index is on the left and the values are on the right.
- Indexes are automatically created
1. Build Series by list
ser_obj = pd.Series(range(10))
Sample code:
# Build Series through list ser_obj = pd.Series(range(10, 20)) print(ser_obj.head(3)) print(ser_obj) print(type(ser_obj))
Operation results:
0 10 1 11 2 12 dtype: int64 0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 dtype: int64 <class 'pandas.core.series.Series'>
2. Access to data and indexes
ser_obj.index and ser_obj.values
Sample code:
# get data print(ser_obj.values) # Getting Index print(ser_obj.index)
Operation results:
[10 11 12 13 14 15 16 17 18 19] RangeIndex(start=0, stop=10, step=1)
3. Obtaining data through index
ser_obj[idx]
Sample code:
#Obtaining data by indexing print(ser_obj[0]) print(ser_obj[8])
Operation results:
10 18
4. The corresponding relationship between index and data is not affected by the result of operation.
Sample code:
# The corresponding relationship between index and data is not affected by the result of operation. print(ser_obj * 2) print(ser_obj > 15)
Operation results:
0 20 1 22 2 24 3 26 4 28 5 30 6 32 7 34 8 36 9 38 dtype: int64 0 False 1 False 2 False 3 False 4 False 5 False 6 True 7 True 8 True 9 True dtype: bool
5. Building Series through dict
Sample code:
# Building Series through dict year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5} ser_obj2 = pd.Series(year_data) print(ser_obj2.head()) print(ser_obj2.index)
Operation results:
2001 17.8 2002 20.1 2003 16.5 dtype: float64 Int64Index([2001, 2002, 2003], dtype='int64')
name attribute
- Object name: ser_obj.name
- Object index name: ser_obj.index.name
Sample code:
# name attribute ser_obj2.name = 'temp' ser_obj2.index.name = 'year' print(ser_obj2.head())
Operation results:
year 2001 17.8 2002 20.1 2003 16.5 Name: temp, dtype: float64
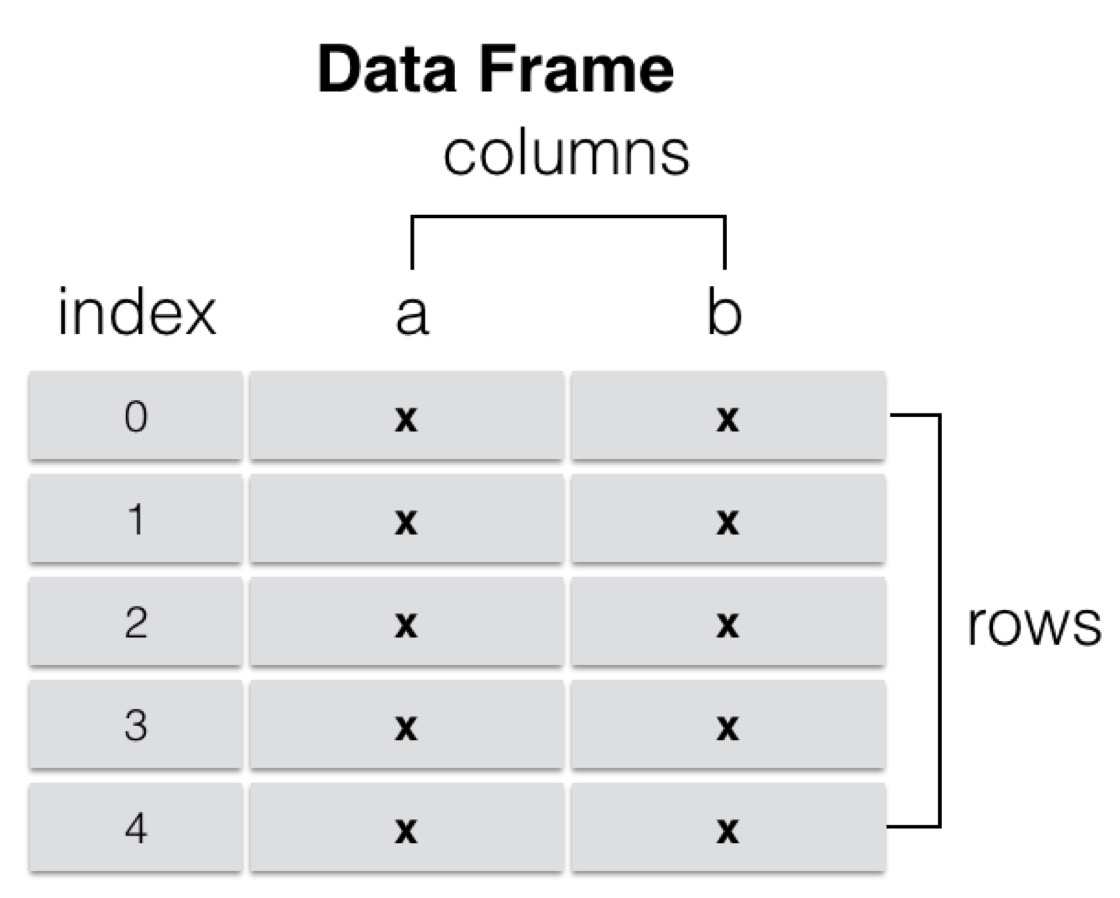
DataFrame
A DataFrame is a tabular data structure that contains an ordered set of columns, each of which can be of different types of values. DataFrame has both row index and column index. It can be regarded as a dictionary composed of Series (sharing the same index). Data is stored in a two-dimensional structure.
- Similar to multidimensional array/table data (e.g., excel)
- Each column of data can be of different types
- Index includes column index and row index
1. Building DataFrame through ndarray
Sample code:
import numpy as np # Building DataFrame through ndarray array = np.random.randn(5,4) print(array) df_obj = pd.DataFrame(array) print(df_obj.head())
Operation results:
[[ 0.83500594 -1.49290138 -0.53120106 -0.11313932] [ 0.64629762 -0.36779941 0.08011084 0.60080495] [-1.23458522 0.33409674 -0.58778195 -0.73610573] [-1.47651414 0.99400187 0.21001995 -0.90515656] [ 0.56669419 1.38238348 -0.49099007 1.94484598]] 0 1 2 3 0 0.835006 -1.492901 -0.531201 -0.113139 1 0.646298 -0.367799 0.080111 0.600805 2 -1.234585 0.334097 -0.587782 -0.736106 3 -1.476514 0.994002 0.210020 -0.905157 4 0.566694 1.382383 -0.490990 1.944846
2. Building DataFrame through dict
ser_obj[idx]
Sample code:
# Building DataFrame through dict dict_data = {'A': 1, 'B': pd.Timestamp('20170426'), 'C': pd.Series(1, index=list(range(4)),dtype='float32'), 'D': np.array([3] * 4,dtype='int32'), 'E': ["Python","Java","C++","C"], 'F': 'ITCast' } #print dict_data df_obj2 = pd.DataFrame(dict_data) print(df_obj2)
Operation results:
A B C D E F 0 1 2017-04-26 1.0 3 Python ITCast 1 1 2017-04-26 1.0 3 Java ITCast 2 1 2017-04-26 1.0 3 C++ ITCast 3 1 2017-04-26 1.0 3 C ITCast
3. Getting column data (Series type) through column index
df_obj[col_idx] or df_obj.col_idx
Sample code:
# Getting column data through column index print(df_obj2['A']) print(type(df_obj2['A'])) print(df_obj2.A)
Operation results:
0 1.0 1 1.0 2 1.0 3 1.0 Name: A, dtype: float64 <class 'pandas.core.series.Series'> 0 1.0 1 1.0 2 1.0 3 1.0 Name: A, dtype: float64
4. Increase column data
df_obj[new_col_idx] = data
Python-like dict adds key-value
Sample code:
# Additional columns df_obj2['G'] = df_obj2['D'] + 4 print(df_obj2.head())
Operation results:
A B C D E F G 0 1.0 2017-01-02 1.0 3 Python ITCast 7 1 1.0 2017-01-02 1.0 3 Java ITCast 7 2 1.0 2017-01-02 1.0 3 C++ ITCast 7 3 1.0 2017-01-02 1.0 3 C ITCast 7
5. Delete columns
del df_obj[col_idx]
Sample code:
# Delete columns del(df_obj2['G'] ) print(df_obj2.head())
Operation results:
A B C D E F 0 1.0 2017-01-02 1.0 3 Python ITCast 1 1.0 2017-01-02 1.0 3 Java ITCast 2 1.0 2017-01-02 1.0 3 C++ ITCast 3 1.0 2017-01-02 1.0 3 C ITCast