1. Introduction to scikit learn dataset API
- sklearn.datasets
- Load get popular dataset
- datasets.load_*()
- Obtain small-scale data sets, and the data is contained in datasets
- datasets.fetch_*(data_home=None)
- To obtain large-scale data sets, you need to download them from the network. The first parameter of the function is data_home indicates the directory where the dataset is downloaded. The default is ~ / scikit_learn_data/
1.1.1 sklearn small data set
-
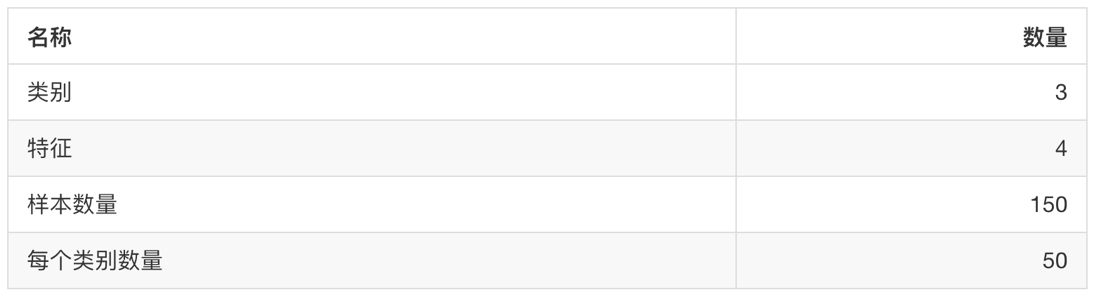
sklearn.datasets.load_iris()
Load and return iris dataset
1.1.2 sklearn big data set
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train')
- subset: 'train' or 'test', 'all', optional. Select the dataset to load.
- "Training" of training set, "testing" of test set, and "all" of both
1.2 introduction to return value of sklearn dataset
- Data type returned by load and fetch datasets.base.bunch (dictionary format)
- Data: feature data array, which is a two-dimensional numpy.ndarray array of [n_samples * n_features]
- target: tag array, n_ One dimensional numpy.ndarray array of samples
- Desc: Data Description
- feature_names: feature name, news data, handwritten digits, regression data set
- target_names: tag name
from sklearn.datasets import load_iris # Get iris dataset iris = load_iris() print("Return value of iris dataset:\n", iris) # The return value is an inherited from the dictionary Bench print("Eigenvalues of iris:\n", iris["data"]) print("Target value of iris:\n", iris.target) print("Iris characteristic Name:\n", iris.feature_names) print("Name of iris target value:\n", iris.target_names) print("Description of iris:\n", iris.DESCR)
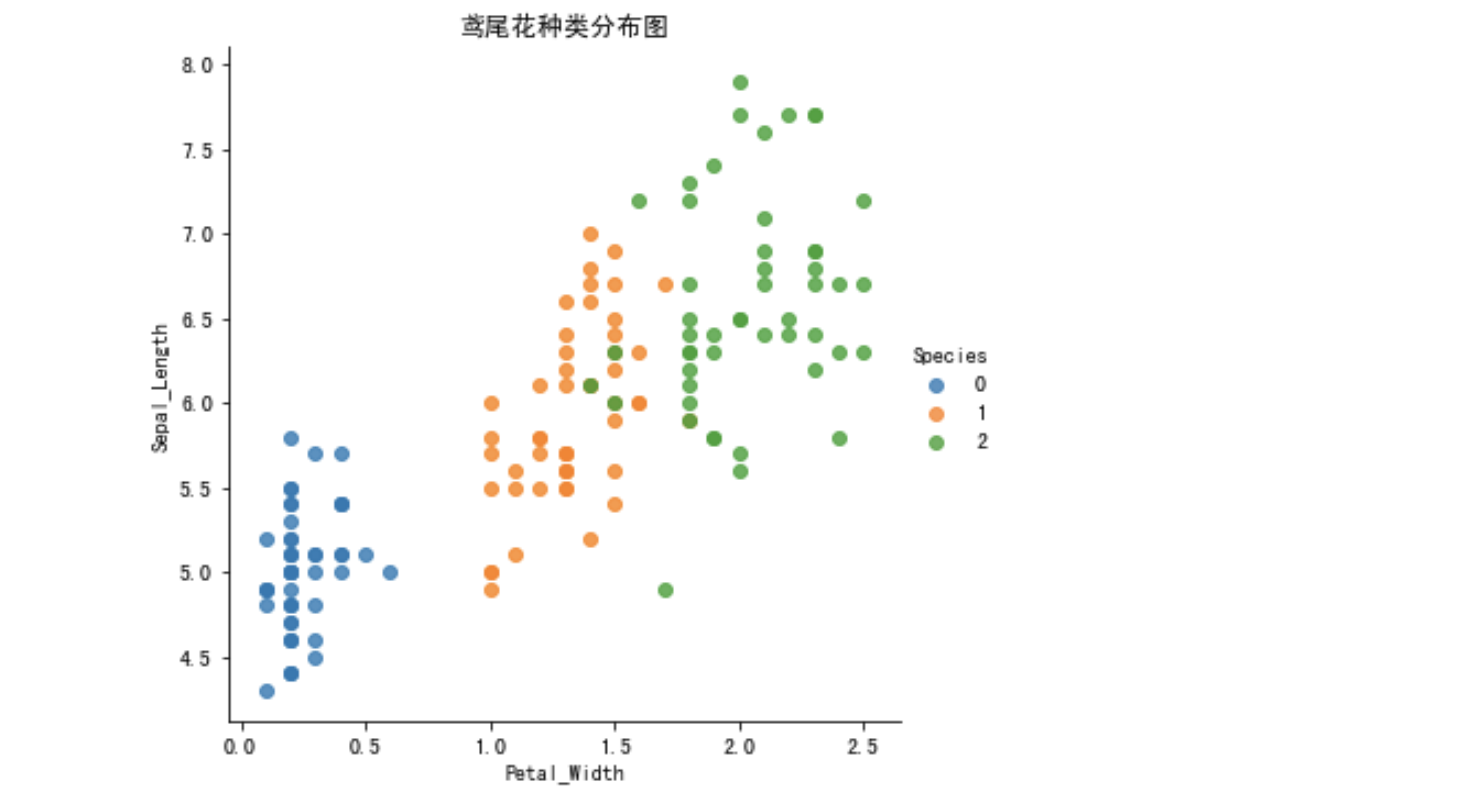
1.3 viewing data distribution
Create some diagrams to see how different categories are distinguished by characteristics. Ideally, label classes will be perfectly separated by one or more feature pairs. In the real world, this ideal situation rarely happens.
-
Seaborn Introduction (official link: http://seaborn.pydata.org/ )
- Seaborn is a higher-level API package based on the Matplotlib core library, which allows you to easily draw more beautiful graphics. The beauty of Seaborn is mainly reflected in the more comfortable color matching and the more delicate style of graphic elements.
- Install pip3 install seaborn
-
seaborn.lmplot() is a very useful method. It will automatically complete the regression fitting when drawing a two-dimensional scatter diagram
- X and Y in sns.lmplot() represent the column names of horizontal and vertical coordinates respectively,
- data = is associated to the dataset,
- hue = * represents the display according to the categories of flowers,
- fit_reg = linear fit or not.
Embedded drawing import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # Convert data into dataframe Format of iris_d = pd.DataFrame(iris['data'], columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width']) iris_d['Species'] = iris.target def plot_iris(iris, col1, col2): sns.lmplot(x = col1, y = col2, data = iris, hue = "Species", fit_reg = False) plt.xlabel(col1) plt.ylabel(col2) plt.title('Iris species distribution map') plt.show() plot_iris(iris_d, 'Petal_Width', 'Sepal_Length')
1.4 data set division
The general data set of machine learning is divided into two parts:
- Training data: used for training and building models
- Test data: used in model verification to evaluate whether the model is effective
Division proportion:
- Training set: 70%, 80%, 75%
- Test set: 30% 20% 25%
Dataset partitioning api
- sklearn.model_selection.train_test_split(arrays, *options)
- Eigenvalues of x dataset
- Label value of y dataset
- test_size the size of the test set, usually float
- random_state random number seeds. Different seeds will cause different random sampling results. The same seed sampling results are the same.
- return test set feature, training set feature value, training tag, test tag (random by default)
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split # 1,Get iris dataset iris = load_iris() # Segmentation of iris data set # Eigenvalues of training set x_train Eigenvalue of test set x_test Target value of training set y_train Target value of the test set y_test x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22) print("x_train:\n", x_train.shape) # Random number seed x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6) x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6) print("If the random number seeds are inconsistent:\n", x_train == x_train1) print("If the random number seeds are consistent:\n", x_train1 == x_train2)