preface
This article summarizes that if you use Submarin to integrate spark ranger, you can control the permissions of spark sql through ranger
premise
Spark, Hive, kerberos and ranger have been installed, and Hive has integrated Ranger. The environment in this article is based on Ambari
Submarine spark security plug-in packaging
Official website document https://submarine.apache.org/docs/userDocs/submarine-security/spark-security/README (version 0.6.0)
git clone https://github.com/apache/submarine
There is no submarine spark security module in the current master branch (0.7.0). You need to switch to tag:release-0.6.0-RC0
Then use the mvn command to package
mvn clean package -Dmaven.javadoc.skip=true -DskipTests -pl :submarine-spark-security -Pspark-2.4 -Pranger-1.2
Type submarine-spark-security-0.6.0.jar in the directory submarine \ submarine-security \ spark security \ target
Then upload submarine-spark-security-0.6.0.jar to $SPARK_HOME/jars
Spark Server policy is added to Ranger Admin interface
Address: http://yourIp:16080/)
Under the original Hive module, add a sparkServer policy with a custom name


The following three key s must be filled in spark. If they are not filled in, there may be problems. As for whether they are required and what the specific meaning is, there is no research yet
tag.download.auth.users policy.download.auth.users policy.grantrevoke.auth.users
jdbc.url is the same as that in hive policy, and then test the connection. After completion, it is shown in the figure below
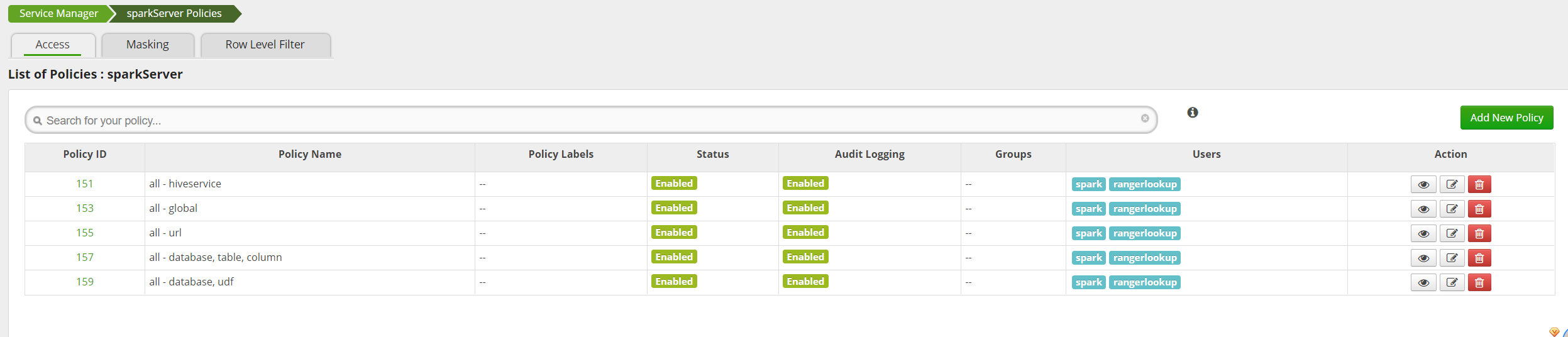
In order to test the effect, we delete other policies first and only keep all database, table and column. This is the default and has spark users

Configure Spark
According to the official website documents, in $SPARK_HOME/conf creates the following two configuration files
ranger-spark-security.xml
<configuration>
<property>
<name>ranger.plugin.spark.policy.rest.url</name>
<value>http://yourIp:16080</value>
</property>
<property>
<name>ranger.plugin.spark.service.name</name>
<value>sparkServer</value>
</property>
<property>
<name>ranger.plugin.spark.policy.cache.dir</name>
<value>/etc/ranger/sparkServer/policycache</value>
</property>
<property>
<name>ranger.plugin.spark.policy.pollIntervalMs</name>
<value>30000</value>
</property>
<property>
<name>ranger.plugin.spark.policy.source.impl</name>
<value>org.apache.ranger.admin.client.RangerAdminRESTClient</value>
</property>
</configuration>ranger-spark-audit.xml
<configuration>
<property>
<name>xasecure.audit.is.enabled</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db</name>
<value>false</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.driver</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.url</name>
<value>jdbc:mysql://yourIp:3306/ranger</value>
</property>
<property>
<name>xasecure.audit.destination.db.password</name>
<value>ranger</value>
</property>
<property>
<name>xasecure.audit.destination.db.user</name>
<value>ranger</value>
</property>
<property>
<name>xasecure.audit.jaas.Client.option.keyTab</name>
<value>/etc/security/keytabs/hive.service.keytab</value>
</property>
<property>
<name>xasecure.audit.jaas.Client.option.principal</name>
<value>hive/_HOST@INDATA.COM</value>
</property>
</configuration>The specific ip, port, user name and password information can be viewed in the previously configured hive Ranger plug-in configuration file or searched in the ambari interface
Start spark SQL sparkserver
Spark-SQL
spark-sql --master yarn --deploy-mode client --conf 'spark.sql.extensions=org.apache.submarine.spark.security.api.RangerSparkSQLExtension' --principal spark/youIp@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab
SparkServer
spark-submit --master yarn --deploy-mode client --executor-memory 2G --num-executors 3 --executor-cores 2 --driver-memory 4G --driver-cores 2 --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name Thrift-11111 --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' --principal spark/yourIp --keytab /etc/security/keytabs/spark.service.keytab --hiveconf hive.server2.thrift.http.port=11111
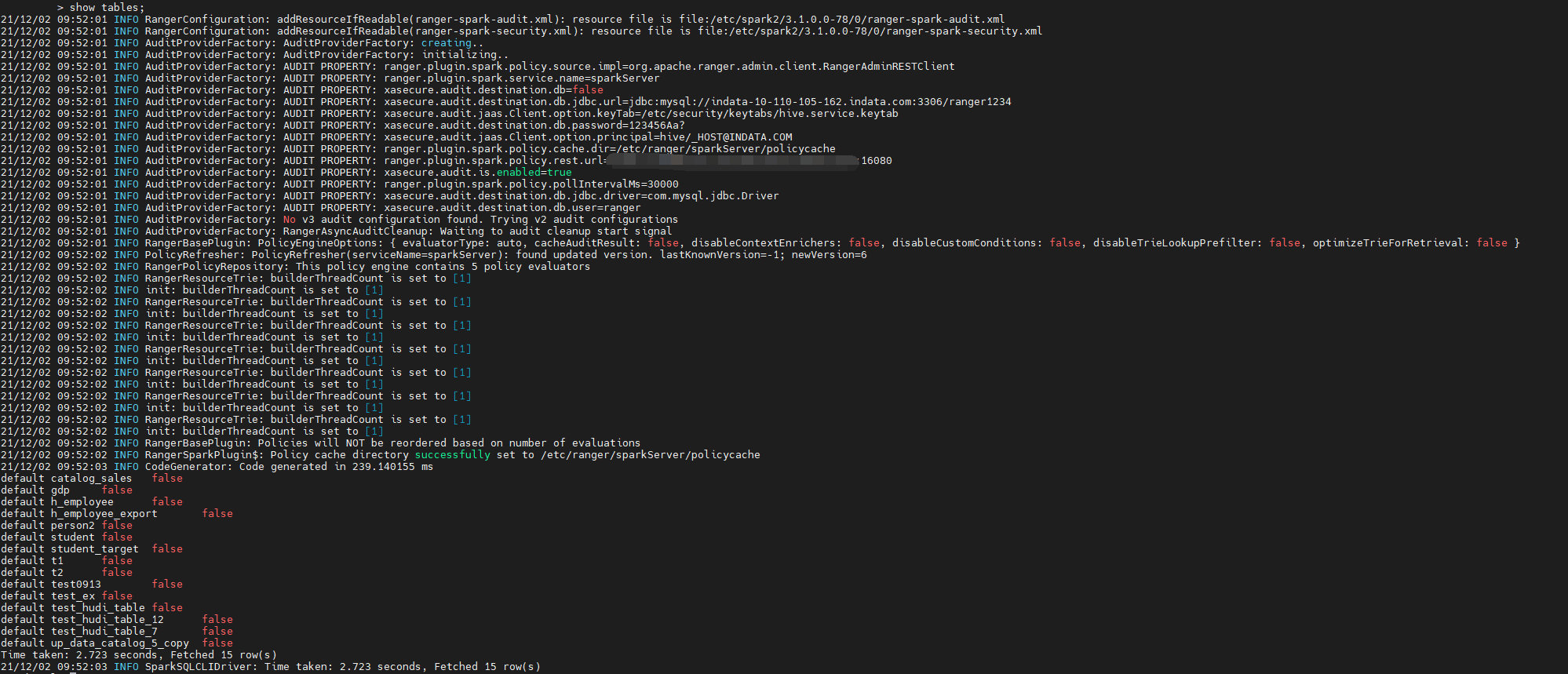
Note that you need to add submarine extensions and authenticate kerberos with spark user, because ranger controls permissions through kerberos authenticated users Here, spark SQL is taken as an example to demonstrate. After starting spark SQL, execute show tables, which will read the sparkServer policy in the ranger according to the configuration file. If the reading and parsing are successful, the corresponding json file will be generated in the configured cache directory, such as:
ll /etc/ranger/sparkServer/policycache/ total 28 -rw-r--r-- 1 root root 27223 Dec 2 09:52 sparkSql_sparkServer.json
At this time, you can see that spark has permission to read table information
Then delete the spark user of the spark server policy in the ranger. After a few seconds, we can see that spark SQL has refreshed the ranger policy and then show tables. At this time, we have no permission to read the table information
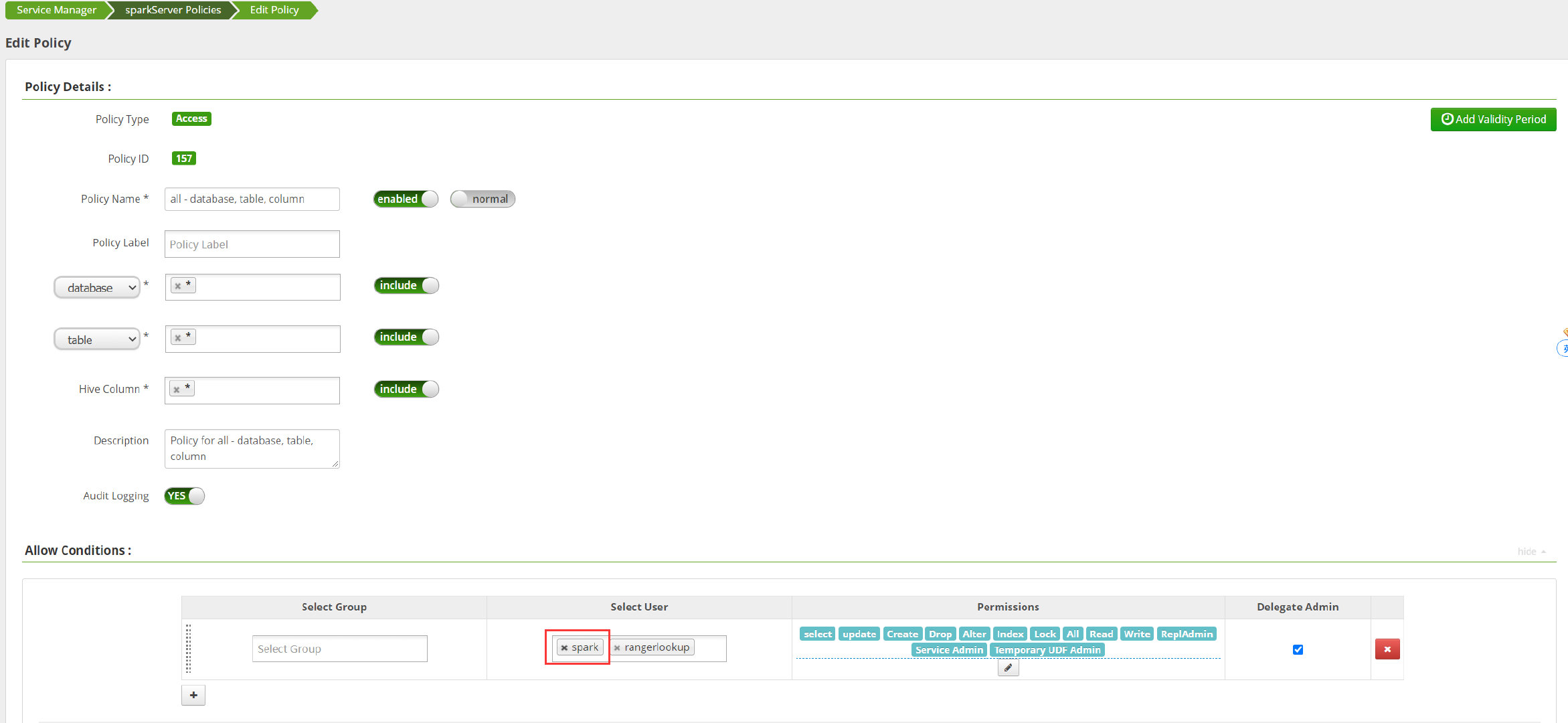
Here, we have verified that we can control the permissions of spark sql through ranger. Later, we can add back the spark user to verify whether the permissions are available again, and we can modify the policies, such as which tables can be viewed, select update and other operation permissions Of course, Spark Server should be used formally
problem
Other kerberos users
When we authenticate other kerberos users, although we can control permissions, exceptions will be thrown. Although Spark Server has no exceptions, it cannot control the permissions of other users
Extend multiple spark.sql.extensions
Because we have extended submarine through spark. SQL. Extensions = org. Apache. Submarine. Spark. Security. API. Rangersmarksqlextension. If hudi is extended at the same time, use spark SQL Conflict creating hudi table