Conversion operation of DStream
The DStream API provides the following methods related to transformation operations: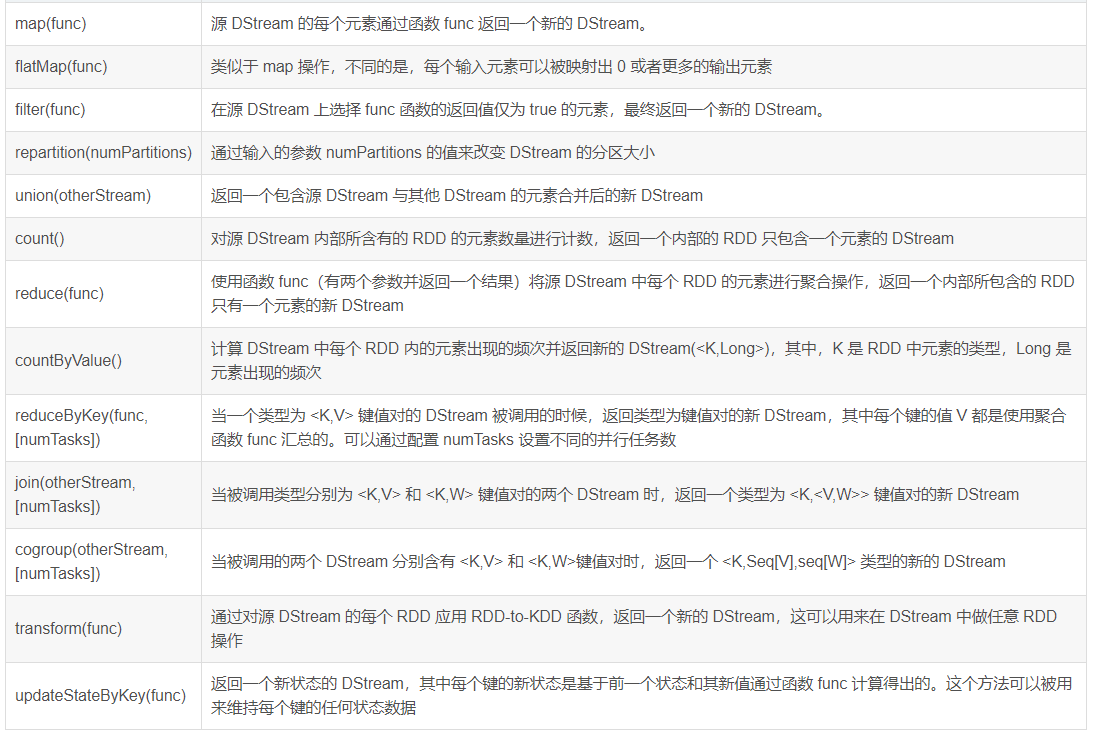
Examples of transform(func) and updateStateByKey(func) methods are given below:
(1), transform(func) method
transform methods and similar transformWith(func) methods allow any RDD-to-RDD function to be applied on DStream and can be applied to any RDD operation that is not exposed in the DStream API.
The following example demonstrates how to use the transform(func) method to separate a line of statements into multiple words, using the following steps:
A. Execute the command nc-lk 9999 in Liunx to start the server and listen for socket services, and enter the data I like spark streaming and Hadoop as follows:
B. Open IDEA development tools, create a Maven project, and configurePom.xmlFile, introducing dependent packages related to Spark Streaming,Pom.xmlThe file configuration is as follows:
<!--Set Dependent Version Number-->
<properties>
<spark.version>2.1.1</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>Note: ConfiguredPom.xmlAfter the file, you need to create scala directories in the project's/src/main and/src/test directories, respectively.
C. Create a package in the project's/src/main/scala directory, then create a Scala class named TransformTest, which is mainly used to write SparkStreaming applications to separate one line of statements into multiple words, as follows (with comments):
package SparkStreaming
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object TransformTest {
def main(args: Array[String]): Unit = {
//Create SparkConf Object
val sparkconf = new SparkConf().setAppName("TransformTest").setMaster("local[2]")
//Create SparkContext Object
val sc = new SparkContext(sparkconf)
//Set Log Level
sc.setLogLevel("WARN")
//To create a StreamingContext, you need to create two parameters, SparkContext and Batch Interval
val ssc = new StreamingContext(sc,Seconds(5))
//Connecting to a socket service requires the socket service address, port number, and storage level (default)
val dstream:ReceiverInputDStream[String] = ssc.socketTextStream("192.168.169.200",9999)
//Separate by spaces
val words:DStream[String] = dstream.transform(line => line.flatMap(_.split(" ")))
//Print Output Results
words.print()
//Turn on streaming
ssc.start()
//Used to protect program from running normally
ssc.awaitTermination()
}
}D. Running the program, you can see that statements I like spark streaming and Hadoop are divided into six words in five seconds, the result is as follows:
(2) updateStateByKey(func) method
The updateStateByKey(func) method can remain arbitrary while allowing continuous updates of new information.
The following example demonstrates how to use the updateStateByKey(func) method for word frequency statistics:
Create a package in the project's/src/main/scala directory, then create a Scala class named UpdateStateByKeyTest, which is mainly used to write SparkStreaming applications to implement word frequency statistics as follows:
package SparkStreaming
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object UpdateStateByKeyTest {
def updateFunction(newValues:Seq[Int],runningCount:Option[Int]) : Option[Int] = {
val newCount = runningCount.getOrElse(0)+newValues.sum
Some(newCount)
}
def main(args: Array[String]): Unit = {
//Create SparkConf Object
val sparkconf = new SparkConf().setAppName("UpdateStateByKeyTest").setMaster("local[2]")
//Create SparkContext Object
val sc = new SparkContext(sparkconf)
//Set Log Level
sc.setLogLevel("WARN")
//To create a StreamingContext, you need to create two parameters, SparkContext and Batch Interval
val ssc = new StreamingContext(sc,Seconds(5))
//Connecting to a socket service requires the socket service address, port number, and storage level (default)
val dstream:ReceiverInputDStream[String] = ssc.socketTextStream("192.168.169.200",9999)
//Separate the first and second fields by commas
val words:DStream[(String,Int)] = dstream.flatMap(_.split(" ")).map(word => (word,1))
//Call updateStateByKey operation
var result:DStream[(String,Int)] = words.updateStateByKey(updateFunction)
//If updateStateByKey is used, add it hereSsc.checkpoint("Catalog") or you will get an error:
// The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
//Why checkpoint is used?Because the previous cases are stateless, they will be discarded after they are used up, which is not necessary.
// But to use that data now, keep the previous state
//"." means the current directory
ssc.checkpoint(".")
//Print Output Results
result.print()
//Turn on streaming
ssc.start()
//Used to protect program from running normally
ssc.awaitTermination()
}
}Then enter words on port 9999 as follows:

From the results of the console output, the running program can see that it accepts data every 5 seconds, twice in total, and every time it accepts data, it performs word frequency statistics and outputs the results.