Article catalog title
Introduction and characteristics
Sqoop is a Hadoop And data transfer tools in relational database, which can transfer a relational database database (for example, mysql, Oracle, Postgres, etc.) data can be imported into HDFS of Hadoop, or into relational database.
For some NoSQL Database it also provides connectors. Sqoop, similar to other ETL tools, uses metadata model to determine data type and ensure type safe data processing when data is transferred from data source to Hadoop. Sqoop is designed for big data Batch transmission design, which can split data sets and create Hadoop tasks to process each block.
summary
sqoop is one of apache's "data transfer tools between Hadoop and relational database servers".
Import data: MySQL, Oracle import data to HDFS, HIVE, HBASE and other data storage systems of Hadoop;
Export data: export data from Hadoop file system to relational database mysql, etc.
Working mechanism
Translate the import or export command into mapreduce program.
In the translated mapreduce, input format and output format are mainly customized.
Installation and configuration
1. Download, upload and unzip to / usr/local folder
Latest download address http://ftp.wayne.edu/apache/sqoop/1.4.6/
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/
2. Modify the file sqoop in the configuration directory- env.sh
Go to the specified directory: / usr/local/sqoop-1.4.7.bin__hadoop-2.6.0/conf
rename profile
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh export HADOOP_COMMON_HOME=/usr/local/hadoop-2.7.7 export HADOOP_MAPRED_HOME=/usr/local/hadoop-2.7.7 export HIVE_HOME=/usr/local/apache-hive-1.2.2-bin
3. Make MySQL driver package mysql-connector-java-5.1.46-bin.jar Copy to the lib folder under the Sqoop installation directory
4. Configure environment variables
vi ~/.bashrc #sqoop export SQOOP_HOME=/usr/local/sqoop-1.4.7.bin__hadoop-2.6.0 export PATH=$PATH:$SQOOP_HOME/bin source ~/.bashrc
Check whether the configuration is successful and the version number
sqoop version
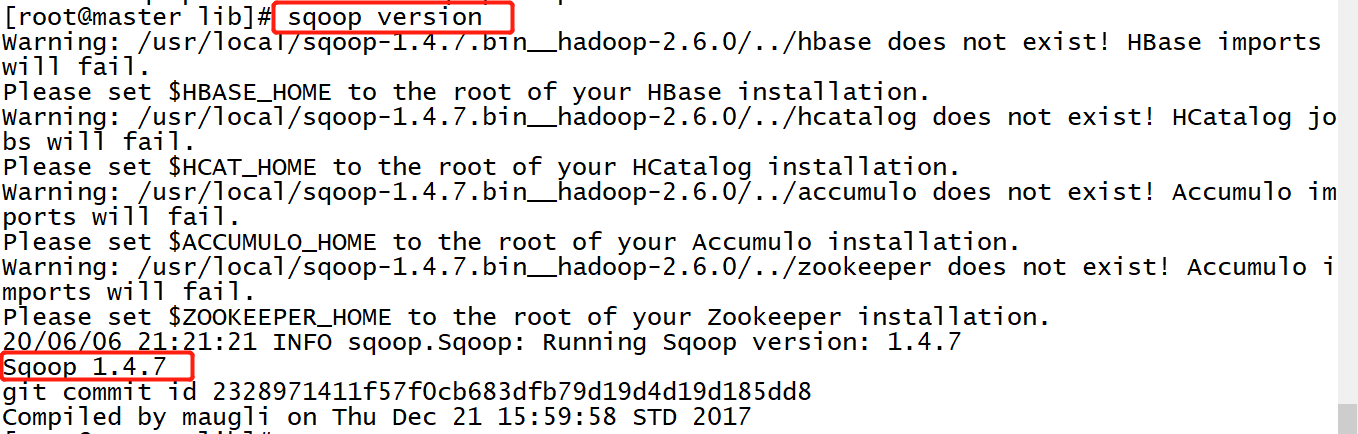
Here, the installation process of brother Zhang of Sqoop is over!
Common command operations of Sqoop
sqoop help Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information
5. Test the connectivity from sqoop to mysql
view the database
bin/sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root --password 123456
The databases displayed are the same as those displayed in mysql

View the tables existing in mysql database
bin/sqoop list-tables --connect jdbc:mysql://localhost:3306/mysql --username root --password 123456
Import data from the database into HDFS
Specify output path, specify data separator
–fields-terminated-by '\t'
bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table student --target-dir /sqoop/mysql1 --fields-terminated-by '\t'
Specify Map quantity - m
-m 2
bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table student --target-dir /sqoop/mysql2 --fields-terminated-by '\t' -m 2
Add where condition, note: the condition must be enclosed in quotation marks
id greater than 3: - where 'id > 3'
bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table student --where 'id>3' --target-dir /sqoop/mysql3 --fields-terminated-by '\t'
Add query statement (use \ to wrap statement)
bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 \ --query 'SELECT * FROM student where id > 2 AND $CONDITIONS' --split-by student.id --target-dir /sqoop/mysql4
Note: when using the - query command, you need to pay attention to the parameter after where. AND CONDITIONS must be added and there is a difference between single quotation mark and double quotation mark. If − query is followed by double quotation mark, you need to add the parameter of CONDITIONS
Moreover, there is a difference between single quotation mark and double quotation mark. If -- query is followed by double quotation mark, the parameter CONDITIONS must be added and there is a difference between single quotation mark and double quotation mark. If − query is followed by double quotation mark, then you need to add \ or $CONDITIONS before CONDITIONS
If you set the number of map s to 1, that is - m 1, do not add - split by${ tablename.column }, otherwise add
Start Hadoop first
1. Start mysql and create a table named student (id int, name string) under the test database.
If there is no test database, create a database first
create database test;
# Using the test database use test # Create student table create table student(id int primary key, name varchar(20));
And write content
insert into student values(1, "sartin"),(2, "board"),(3, "zhangsan"),(4, "lishi");

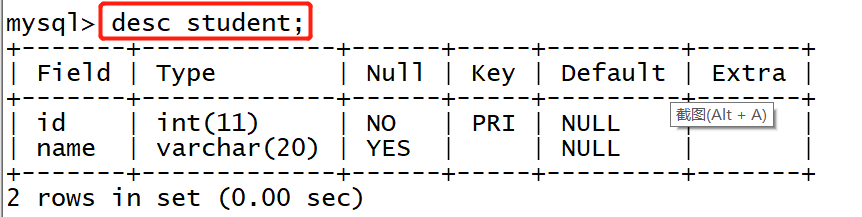
View table structure:
desc student;
To view table data:
select * from student;
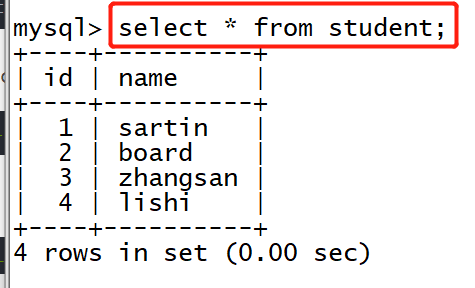
2. Exit mysql and execute the command in the directory of spoon
Execute command to import data into HDFS
bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table student --columns 'id, name' --target-dir /sqoop/mysql
Parameter meaning:
--connect the URL of mysql to the database name --username user name --password --Table table name --columns' column name ' --The HDFS directory accessed by target dir does not need to be created in advance
Check whether hadoop generates corresponding folders:
Because there are four lines of data, there are four part-m-0000xs in do one

View the data results, corresponding to the four rows of data we inserted:

Export data on HDFS to database
1. Start mysql and create a new table hdfsinto in the test database. The table structure is the same as that of student
create table hdfsinto(id int primary key, name varchar(20));
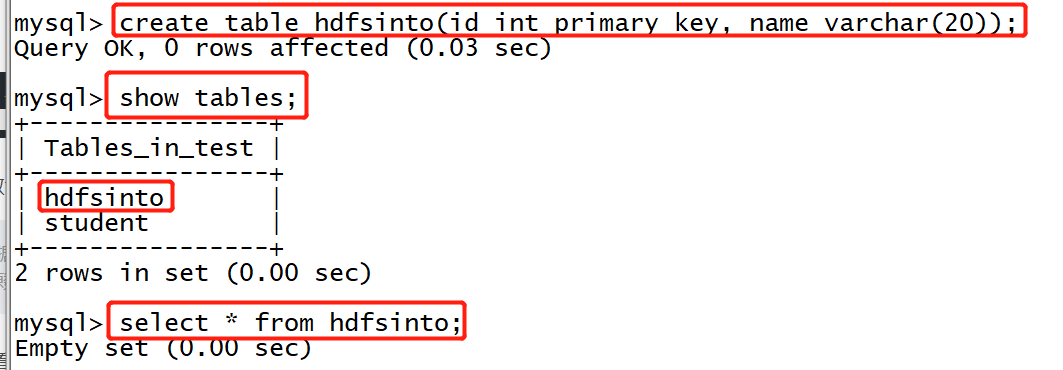
2. Exit mysql and execute the command in the directory of spoon
Execute the command to import the original table student data in HDFS into the table hdfsinto
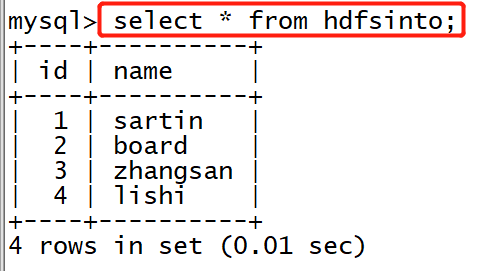
bin/sqoop export --connect "jdbc:mysql://localhost:3306/test" --username root --password 123456 --table hdfsinto --export-dir /sqoop/mysql/*
Parameter meaning:
--Table table name of the table where the data is imported --Location of export dir data
3. Go back to mysql to view the table hdfsinto data