Hello, I haven't seen you for a long time. Yesterday I finally planned to write another example of a crawler. So today I will share the results decisively.
This code is written in Python.
Analysis page
First of all, we need to have a wall-turning tool. After all, Instagram is already outside the wall. Here it is. Choose it. Firefly As a tool to turn over the wall.
Be careful not to turn over the wall and look at illegal things so as not to be caught.
Then, let's open it first. Instagram Web site, confirm that it can be opened to show that the normal wall. Because this issue mainly crawls pictures, so I chose a beautiful woman's Instagram as an example. The scale is not high. We opened the debugging function of Chrome F12 and clicked on the Network Tab page.
According to convention, first check whether there is an image link in the HTML file of the index page.
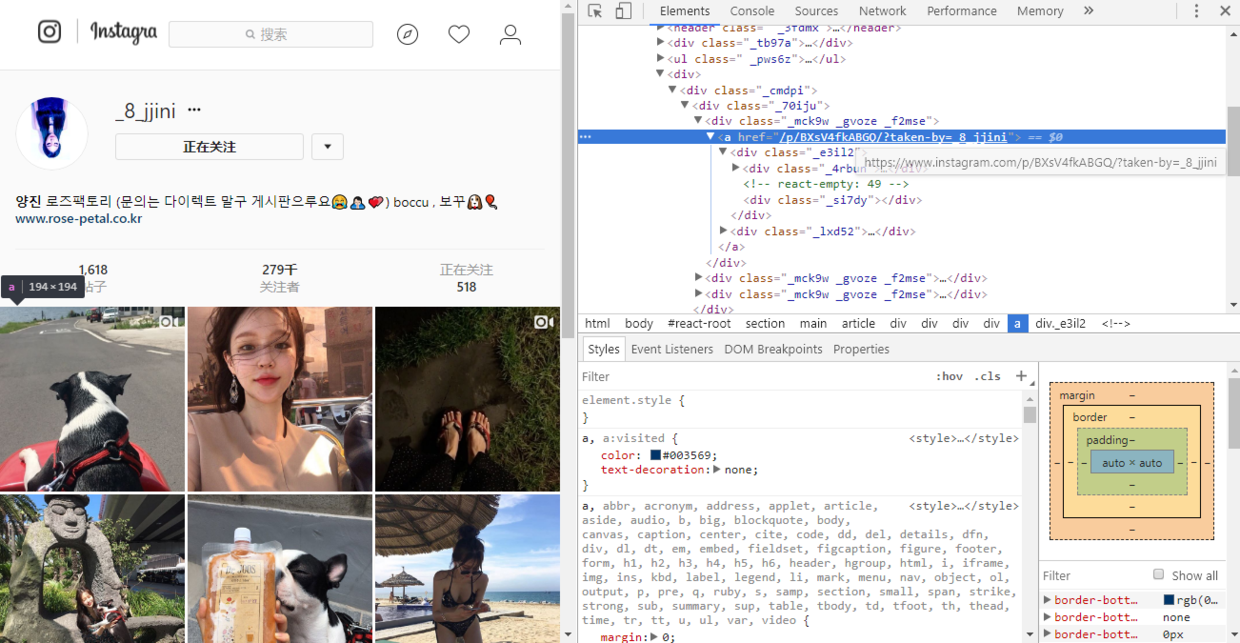
Here we copy the string of class = _mck9w_gvoze_f2mse and look under the Source Tab page. We find that there is no result. We copy it out and find that the contents are dynamically generated.
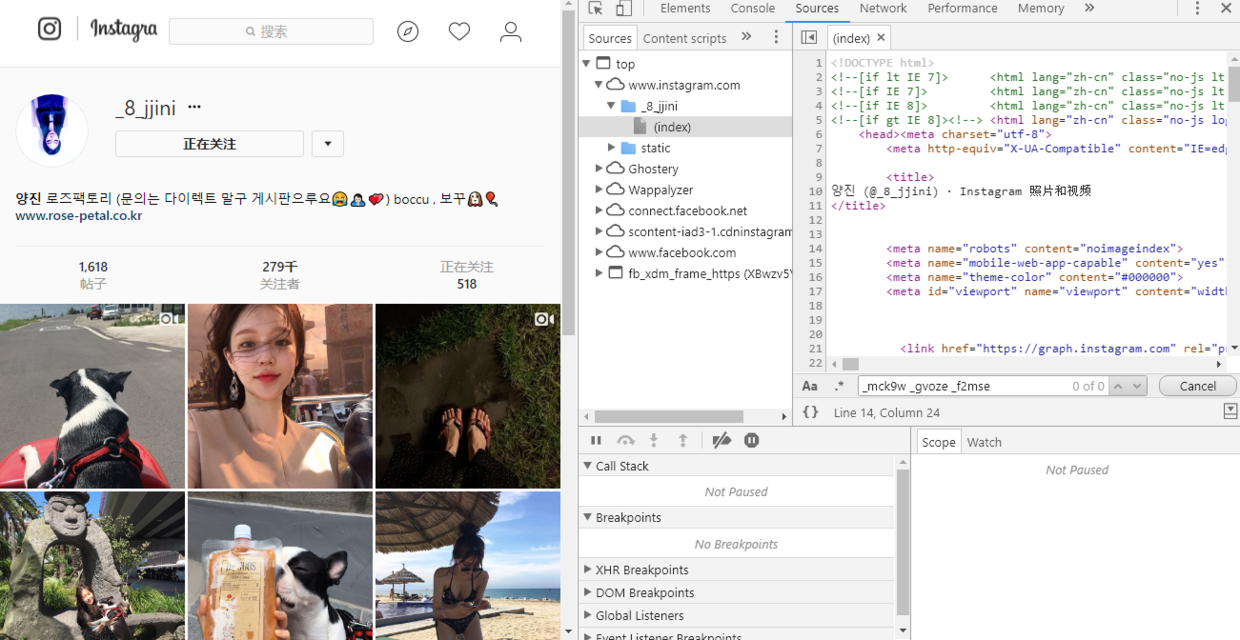
It has to be doubted whether all the data is placed in the home HTML file in other forms or asynchronously requested through Ajax. We copied a link to an image from the Network, as follows, and then searched it in an HTML file. The result appeared.

In the process of searching records, we found a surprising place, that is, windows._shareData wrapped in script, where links to pictures are located. What is valuable is whether data format or json format. We extract format separately.
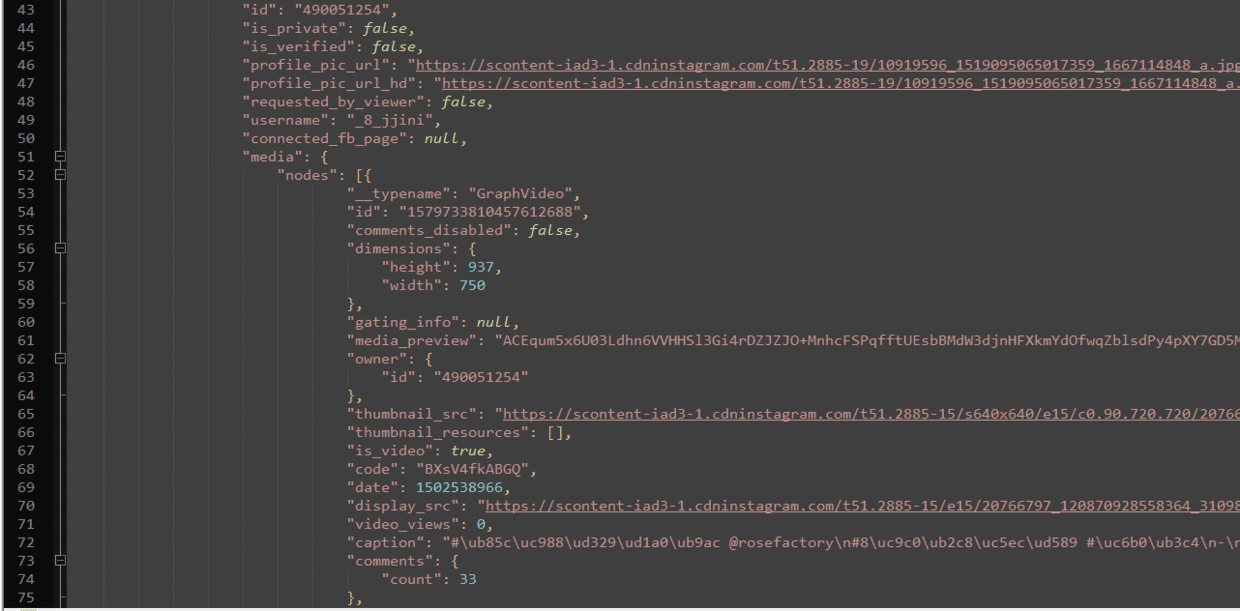
The real image URL is in the nodes data, which is great news.
Code
# -*- coding: utf-8 -*- import json from lxml import etree import requests import click headers = { "Origin": "https://www.instagram.com/", "Referer": "https://www.instagram.com/_8_jjini/", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/58.0.3029.110 Safari/537.36", "Host": "www.instagram.com", "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "accept-encoding": "gzip, deflate, sdch, br", "accept-language": "zh-CN,zh;q=0.8", "X-Instragram-AJAX": "1", "X-Requested-With": "XMLHttpRequest", "Upgrade-Insecure-Requests": "1", } BASE_URL = "https://www.instagram.com/_8_jjini/" proxy = { 'http': 'http://127.0.0.1:38251', 'https': 'http://127.0.0.1:38251' } def crawl(): click.echo('start') try: res = requests.get(BASE_URL, headers=headers, proxies=proxy) html = etree.HTML(res.content.decode()) all_a_tags = html.xpath('//script[@type="text/javascript"]/text()') for a_tag in all_a_tags: if a_tag.strip().startswith('window'): data = a_tag.split('= {')[1][:-1] # Get the json data block js_data = json.loads('{' + data, encoding='utf-8') nodes = js_data["entry_data"]["ProfilePage"][0]["user"]["media"]["nodes"] for node in nodes: click.echo(node["display_src"]) click.echo('ok') except Exception as e: raise e if __name__ == '__main__': crawl()
Running results:


Note that the proxy configuration here can be seen just by starting Firefly.

What, how do you download it? That's the next thing. We haven't crawled all the URL s yet. Have you forgotten more of that button? See you next time.~~