Preface
This is a literacy article
Clean up unknown concepts and develop awareness of service assurance
I. What is SLA
sla is an agreement to quantify software quality of service
SLA
A service level agreement (SLA) is a mutually agreed agreement defined between a service provider and a user to guarantee the performance and availability of a service at a cost. SLA contains SLI and SLO.
SLI
Service Level Key Quantitative Indicators (SLI, full name: service level indicator)

| index | Meaning | Scenarios applicable |
|---|---|---|
| HA: High Availability | Service Availability | Universal, commonly referred to as 99.9% 99.99% |
| QPS: Concurrent quantities per second (Queries Per Second) | Query Return Capability (per second) | Suitable for concurrent query services |
| RPS: Processing capacity per second (Response Per Second) | Operation Return Capability (per second) | Suitable for interface multitask services |
| TPS: Throughput per second (Transactions Per Second) | Transaction capacity (per second) | Suitable for asynchronous multitask services |
| RT: Response Time | Request Response Time (per second) | Suitable for all interface services Normally focus on 90% request arithmetic average |
| Concurrent Quantity | Number of interface user requests per second | Not accurately estimated with QPS |
| MTBF: Mean Time Between Fail | MTBF = MTTF + MTTR | Service stability measurement, bigger is better |
| MTTR: Mean Time To Repair | Service stability measurement, smaller is better | |
| MTTF: Mean time to Failure | Service stability measurement, bigger is better |
Some of these metrics are quantified
HA = Schedule Available Time/(Schedule Available Time+Failure Time)*100 HA = Request succeeded/(Request succeeded+request was aborted)*100 # Distributed systems often use this calculation formula to simplify complex situations 99% Failure time not exceeding 432 minutes/Month 7.2 hour/month 99.9% Failure time not exceeding 43.2 Minute/month 99.99% Failure time not exceeding 4.32 Minute/month # The following indicators are usually subdivisions of HA conditions and can also define failure times or number of request failures QPS = Total number of successful requests/unit time TPS = Total number of tasks/unit time RT = Total request response time per unit time/Total Requests Concurrent Quantity ~= QPS * RT
Stability Quantization
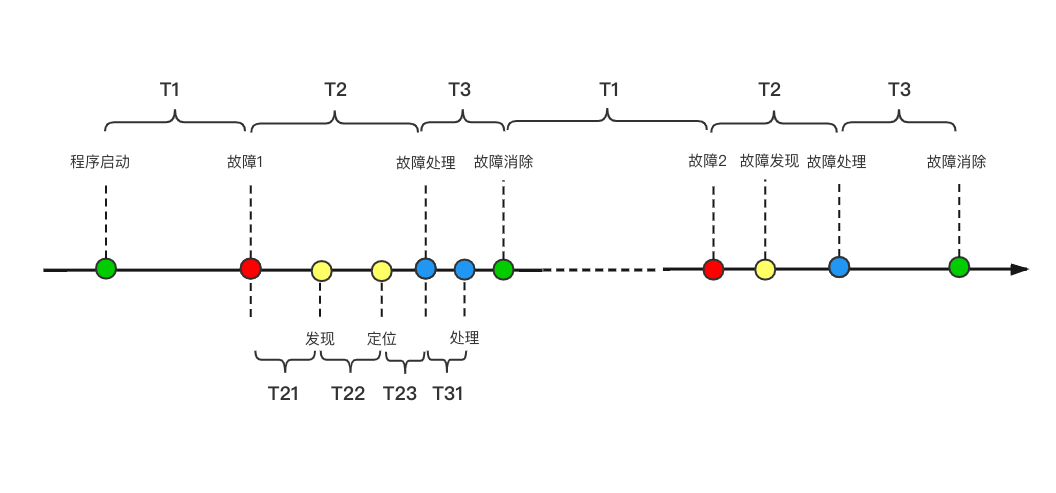
Image above N:Two failures T1:Fail-free time T2:Failure Waiting Repair Time T3:Failure Repair Time T21:Failure Discovery Time T22:Fault Discovery Location Time T23:Failure Location to Processing Time T31:Failure handling time MTTF =∑T1/ N #The average time a system has been running without failures, and the average time between the start of normal operation of all systems and the occurrence of a failure MTTR =∑(T2+T3)/ N #Average value of the time period from failure to end of repair for the system MTBF =∑(T2+T3+T1)/ N #Mean value of the time period between two failures of the system
SLO
Service Level Objects (SLO) specify a desired state of functionality provided by a service, including all the information that describes what functionality the service should provide.
Generally described as:
- Average QPS > 100k/s per minute
- 99% RT < 500ms
- 99% IO > 200MB/s
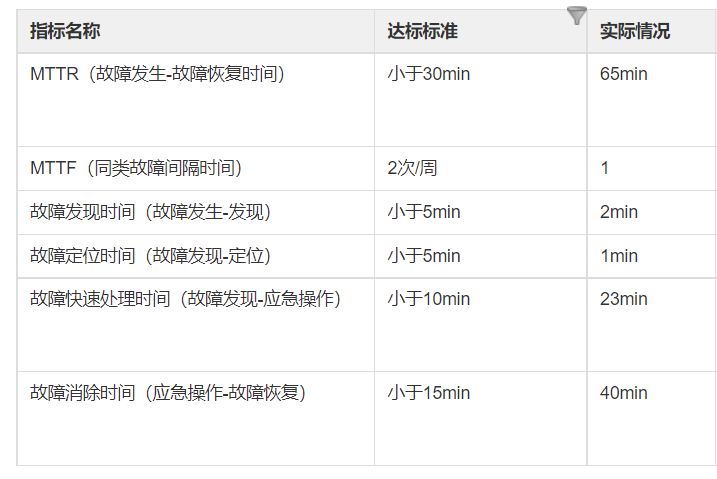
- MTTR<30min
- MTTF<1/week
- Failure Occurs - Discovery <5min
- Fault Discovery-Location <5min
- Failure Discovery-Handling <10 min
- Troubleshooting-Elimination <15min
The following is a legend for a failover disk
2. Why SLA is needed?
SLA enables fuzzy quality issues to be qualitative and quantitative, promoting communication and cooperation between the two sides
-
A commercial contract defines quantified claims and disclaimers for service content.
-
Services rely on contract service stability/stability quantification, Specification between services and overall link reliability.
Usually service providers talk to demand providers
Demand side: Need to use xxxxapi,Query related document locations to use your service,Please evaluate whether you can undertake objective:xxxx, input parameter:xxxx, Return parameters:xxxx, response RT<500ms, Frequency of use <1000/day, Peak value QPS<10/s, Expect SLA>99.9% Server: after api Analog Call Test,satisfy RT/QPS Requirement,About 20%Service capacity,Ability to undertake services. The service will be created token As Access Identity token Authorize interface access, token do QPS Peak rejection error code xxxx, token Do Daily Upper Rejection Error Code xxxx. If present SLA Members will be notified of the normal maintenance meeting, If present SLA The internal exception will be handled and notified. The service guarantee scheme is as follows xxxxxxx Demand side: Five star reviews! Interfaces will be used strictly in accordance with regulations, Service Interface Failure Preparedness in Assurance Scheme,Communicate in time.
3. How to guarantee service SLA?
What affects SLA?
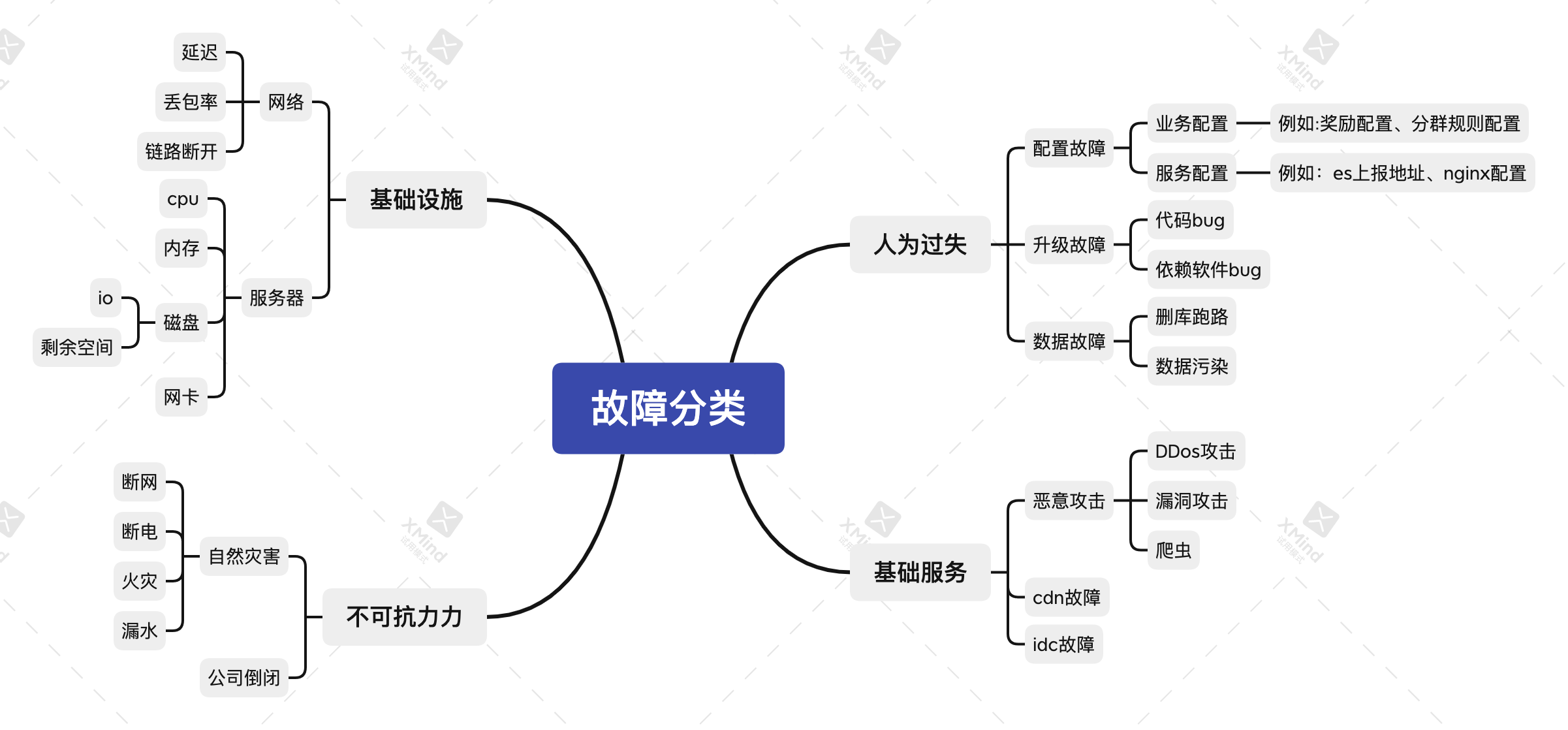
- Force Majeure
- Infrastructure failure
- Basic Services
- human error
a.Software Upgrade
b.Configuration changes
c, data changes
How to improve SLA?
0. Value sla
Value and reverence codes can reduce most human-caused failures. Check and feedback in a timely manner to achieve early professional accomplishment and image.

1. Architecture Design
High Availability Architecture: Active, Dual Primary Synchronization, Disaster Preparedness, Elastic Services. Internal service break, peak clipping, flow limiting, downgrade, etc.
Demand is coming A Classmate: Functionality is implemented on demand and a single service is deployed in a Computer room. B Classmate: Design an overall architecture for functionality and potential risks assessed against demand, using lvs+ha+keepalive+MultiLiving Services in ab Computer room. One night a Room power off A Classmate: Wake up overnight deployment b Computer room B Classmate: hear me roar... One day business went up, service alert was raised A Classmate: Analysis of Waking Up Overnight a Room Service Monitoring B Classmate: hear me roar... Three parties depend on service to follow on one day a Problem with computer room network A Classmate: Wake up overnight deployment b Computer room B Classmate: Get up and watch the next time,hear me roar...
AB students are excellent, but B students who know how to protect SLA seem much easier.
2. Code Design and Testing
90% of failures occur when external exceptions are not actively handled. For example, parameter format send changes/parameters exceed boundaries/dependent on underlying service queues/caching/storage is slower.
- In addition to dealing with high cohesion and low coupling, attention should also be paid to the robustness of the code.
- Focus on mono-testing and performance testing. Interesting to learn about TDD.
Demand is coming A Classmate: A Is an upstream service. B Classmate: B Is a downstream service, B Yes A All parameters are unit test overridden. Results are cached based on validity. One day A Class Service Upgrade Modified Parameters B Classmate: Received A The students changed the parameters after upgrading, causing an exception alarm, the first time to tell A Code changes affected. A Classmate: Quickly return code One day A Class Service Hang Up B Classmate: Received A Abnormal Alarm for Class Service,Because the cache is valid,No impact on service, give A Snoring after message... A Classmate: Wake up overnight to resume service,And notify B Classmate,find B Messages from classmates... Double the magnitude of service one day A Classmate: Fear over B Classmate: Based on performance tests, it's easy to find hold Hold, snore...
AB students are excellent, but B students who know code design don't have to worry every time.
3. Monitor abnormal alarm
The most important thing for SLA is to discover faults as soon as possible. So related alarms are very important!

4. Emergency plans
Step 1 Failure Sensing
Predictable failures such as power outage, power outage, device migration, etc. can be notified in advance
Unforeseeable failures, such as network problems, human errors, malicious attacks, etc., can be detected as early as possible by probe services.
Depends on Probe Service + Monitoring System to detect failures.
For perceived failures. Define impact surface, process priority, and eliminate failure steps.
Step 2 Failover
The first time, the first time, the first time to reduce the impact of the failure, do not, do not, do not just analyze the cause.
Upgrade Failure Returns Upgrade
Configuration failure falls back on configuration
Notify the reserve machine on main failure, etc.
Step 3 Troubleshooting
Usually a rehearsal is one in which the infrastructure and infrastructure services are built to do some routine troubleshooting and rehearsal.
Each service improves the emergency plan according to its own failure plan disposal.
Step 4 Update and perfect in time
As the environment changes or software services are upgraded, the corresponding priority processing steps of the fault-aware impact surface will change and need to be updated in time.
Continuously streamline troubleshooting and reduce MTTR
4. Summary
SLA not only improves the quality of service, but also the hard power of programmers.