1. sklearn feature extraction
1.1 Install sklearn
pip install Scikit-learn -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
No error, Import command to see if available:
import sklearn
Note: Numpy,pandas and other libraries are required to install scikit-learn s.
1.2 Feature Extraction
Example:
# feature extraction # Import Package from sklearn.feature_extraction.text import CountVectorizer # instantiation CountVectorizer vector = CountVectorizer() # call fit_transform Enter and convert data res = vector.fit_transform(["life is short,i like python","life is too long,i dislike python"]) # Print results print(vector.get_feature_names()) print(res.toarray())
Run result:
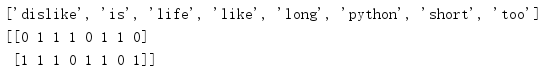
With an example, we can conclude that feature extraction is used to eigenvaluate data such as text.(
1.3 Dictionary Feature Extraction
Role: Feature dictionary data.
Class: sklearn.feature_extraction.DictVectorizer
DictVectorizer syntax:
DictVectorizer(sparse=True,...)
- DictVectorizer.fit_transform(X)
- X: Dictionary or Iterator with Dictionary
- Return value: Return sparse matrix
- DictVectorizer.inverse_transform(X)
- X:array array array or sparse matrix
- Return value: data format before conversion
- DictVectorizer.get_feature_names()
- - Return category name
- DictVectorizer.transform(X)
- Conversion to original standards
from sklearn.feature_extraction import DictVectorizer def dictvec(): """ //Dictionary Data Extraction :return: None """ # instantiation dict = DictVectorizer() # call fit_transform data = dict.fit_transform([{'city': 'Beijing','temperature': 100}, {'city': 'Shanghai','temperature':60}, {'city': 'Shenzhen','temperature': 30}]) print(dict.get_feature_names()) print(dict.inverse_transform(data)) print(data) return None if __name__ == "__main__": dictvec()
Run result:

Modify attributes to make the data more intuitive.
from sklearn.feature_extraction import DictVectorizer def dictvec(): """ //Dictionary Data Extraction :return: None """ # instantiation dict = DictVectorizer(sparse=False) # call fit_transform data = dict.fit_transform([{'city': 'Beijing','temperature': 100}, {'city': 'Shanghai','temperature':60}, {'city': 'Shenzhen','temperature': 30}]) print(dict.get_feature_names()) print(dict.inverse_transform(data)) print(data) return None if __name__ == "__main__": dictvec()
Run result:

1.4 Text Feature Extraction
Role: Feature text data.
Class: sklearn.feature_extraction.text.CountVectorizer
CountVectorizer syntax:
CountVectorizer(max_df=1.0,min_df=1,...)
- Return frequency matrix
- CountVectorizer.fit_transform(X,y)
- X: Text or Iterable Objects Containing Text Strings
- Return value: Return sparse matrix
- CountVectorizer.inverse_transform(X)
- X:array array array or sparse matrix
- Return value: data format before conversion
- CountVectorizer.get_feature_names()
- Return value: Word list
from sklearn.feature_extraction.text import CountVectorizer def countvec(): """ //Eigenvaluating text :return: None """ cv = CountVectorizer() data = cv.fit_transform(["Life is short, I like it python", "Life is long, don't use it python"]) print(cv.get_feature_names()) print(data.toarray()) return None if __name__ == "__main__": countvec()
Run result:
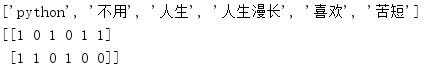
When we are working with text, it is impossible to split words one by one, so we will use a tool called jieba.(
pip install jieba -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
from sklearn.feature_extraction.text import CountVectorizer import jieba def cutword(): con1 = jieba.cut("Today is cruel, tomorrow is crueller, the day after tomorrow is beautiful, but most of them die tomorrow evening, so everyone should not give up today.") con2 = jieba.cut("We see light coming from distant galaxies millions of years ago, so when we see the universe, we are looking at its past.") con3 = jieba.cut("If you know something in only one way, you don't really know it.The secret to knowing what things really mean depends on how they relate to what we know.") # Convert to List content1 = list(con1) content2 = list(con2) content3 = list(con3) # Bar list to string c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1, c2, c3 def hanzivec(): """ //Chinese eigenvaluation :return: None """ c1, c2, c3 = cutword() print(c1, c2, c3) cv = CountVectorizer() data = cv.fit_transform([c1, c2, c3]) print(cv.get_feature_names()) print(data.toarray()) return None if __name__ == "__main__": hanzivec()
Run result:
Building prefix dict from the default dictionary ... Dumping model to file cache C:\Users\ACER\AppData\Local\Temp\jieba.cache Loading model cost 0.839 seconds. Prefix dict has been built successfully. Today is cruel, tomorrow is crueller, the day after tomorrow is beautiful, but most of them die tomorrow evening, so everyone should not give up today.We see light coming from distant galaxies millions of years ago, so when we see the universe, we are looking at its past.If you know something in only one way, you don't really know it.The secret to knowing what things really mean depends on how they relate to what we know. ['one','won','no','don','don','before','know','things','today','Light is','millions of years','emit','depend','Just use','acquired','acquired','meaning','mostly','how','most','how','if','cosmic','us','us','so','Give up','way','tomorrow','galaxy','galaxy''','night','something','cruel','every','see'',''','''','''''', real secretsecret,''''','''''''secret''Absolute','Beautiful','Contact','Past','This'] [[0 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 0] [0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 1] [1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0]]
1.5 TF-IDF
The main idea of TF-IDF is that if a word or phrase has a high probability of appearing in one article and is seldom found in other articles, it is considered to be a good category discriminator and suitable for classification.
TF-IDF Role: Used to assess the importance of a word to a file set or one of the files in a corpus.
Class: sklearn.feature_extraction.text.TfidfVectorizer
TfidfVectorizer syntax:
TfidfVectorizer(stop_words=None,...)
- Returns the weight matrix of words
- TfidfVectorizer.fit_transform(X,y)
- X: Text or Iterable Objects Containing Text Strings
- Return value: Return sparse matrix
- TfidfVectorizer.inverse_transform(X)
- X:array array array or sparse matrix
- Return value: data format before conversion
- TfidfVectorizer.get_feature_names()
- Return value: Word list
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer import jieba def cutword(): con1 = jieba.cut("Today is cruel, tomorrow is crueller, the day after tomorrow is beautiful, but most of them die tomorrow evening, so everyone should not give up today.") con2 = jieba.cut("We see light coming from distant galaxies millions of years ago, so when we see the universe, we are looking at its past.") con3 = jieba.cut("If you know something in only one way, you don't really know it.The secret to knowing what things really mean depends on how they relate to what we know.") # Convert to List content1 = list(con1) content2 = list(con2) content3 = list(con3) # Convert List to String c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1, c2, c3 def tfidfvec(): """ //Chinese eigenvaluation :return: None """ c1, c2, c3 = cutword() print(c1, c2, c3) tf = TfidfVectorizer() data = tf.fit_transform([c1, c2, c3]) print(tf.get_feature_names()) print(data.toarray()) return None if __name__ == "__main__": tfidfvec()
Run result:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\ACER\AppData\Local\Temp\jieba.cache Loading model cost 0.633 seconds. Prefix dict has been built successfully. Today is cruel, tomorrow is crueller, the day after tomorrow is beautiful, but most of them die tomorrow evening, so everyone should not give up today.We see light coming from distant galaxies millions of years ago, so when we see the universe, we are looking at its past.If you know something in only one way, you don't really know it.The secret to knowing what things really mean depends on how they relate to what we know. ['one','won','no','don','don','before','know','things','today','Light is','millions of years','emit','depend','Just use','acquired','acquired','meaning','mostly','how','most','how','if','cosmic','us','us','so','Give up','way','tomorrow','galaxy','galaxy''','night','something','cruel','every','see'',''','''','''''', real secretsecret,''''','''''''secret''Absolute','Beautiful','Contact','Past','This'] [[0. 0. 0.21821789 0. 0. 0. 0.43643578 0. 0. 0. 0. 0. 0.21821789 0. 0.21821789 0. 0. 0. 0. 0.21821789 0.21821789 0. 0.43643578 0. 0.21821789 0. 0.43643578 0.21821789 0. 0. 0. 0.21821789 0.21821789 0. 0. 0. ] [0. 0. 0. 0.2410822 0. 0. 0. 0.2410822 0.2410822 0.2410822 0. 0. 0. 0. 0. 0. 0. 0.2410822 0.55004769 0. 0. 0. 0. 0.2410822 0. 0. 0. 0. 0.48216441 0. 0. 0. 0. 0. 0.2410822 0.2410822 ] [0.15698297 0.15698297 0. 0. 0.62793188 0.47094891 0. 0. 0. 0. 0.15698297 0.15698297 0. 0.15698297 0. 0.15698297 0.15698297 0. 0.1193896 0. 0. 0.15698297 0. 0. 0. 0.15698297 0. 0. 0. 0.31396594 0.15698297 0. 0. 0.15698297 0. 0. ]]
By contrast, we can see which words have a higher weight in the text.