Information mark
- The tagged information can form an information organization structure and increase the information dimension.
- The structure of markers is as valuable as information.
- Marked information can be used for communication, storage or display.
- Marked information is more conducive to program understanding and Application

HTML is predefined by <>. </> Label format organizes different types of information
Types of Information Markers
- XML
- JSON
- YAML
XML



JSON




YAML





Comparison of Three Marker Types
- The earliest general information markup language of XML is extensible but complicated.
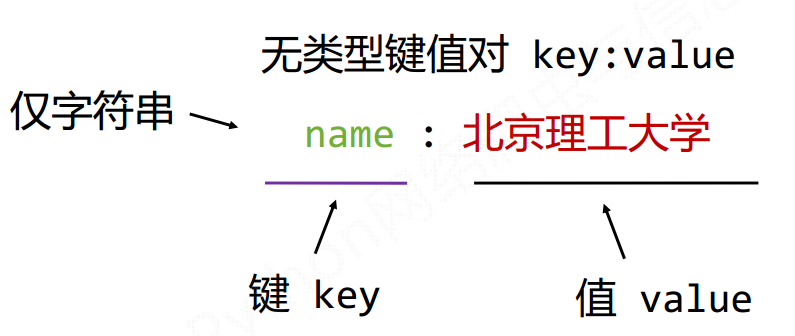
- JSON information is typed and suitable for program processing (js), which is simpler than XML.
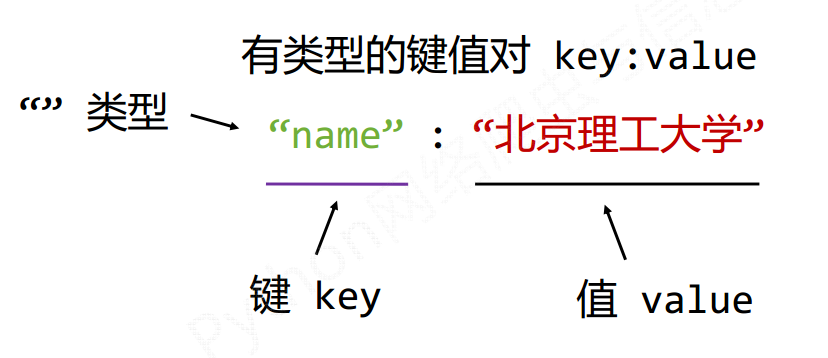
- YAML information has no type, the proportion of text information is the highest, and the readability is good.
- Information Interaction and Transfer on XML Internet
- Information communication between cloud and node in JSON mobile application, no comment
- YAML Configuration Files for Various Systems, Annotated and Readable
information extraction
Extracting Concerned Contents from Marked Information
Method 1: Completely parse the marker form of information, and then extract the key information.
XML JSON YAML
Markup parsers are required, such as label tree traversal of bs4 Libraries
Advantages: accurate information analysis
Disadvantage: The extraction process is tedious and slow.Method 2: Ignore the marker form and search key information directly
search
Text lookup function for information
Advantages: The extraction process is simple and fast.
Disadvantage: Accuracy of extraction results is related to information contentFusion Method: Combining Formal Analysis and Search Method to Extract Key Information
XML JSON YAML Search
Need to tag parsers and text lookup functions
Example
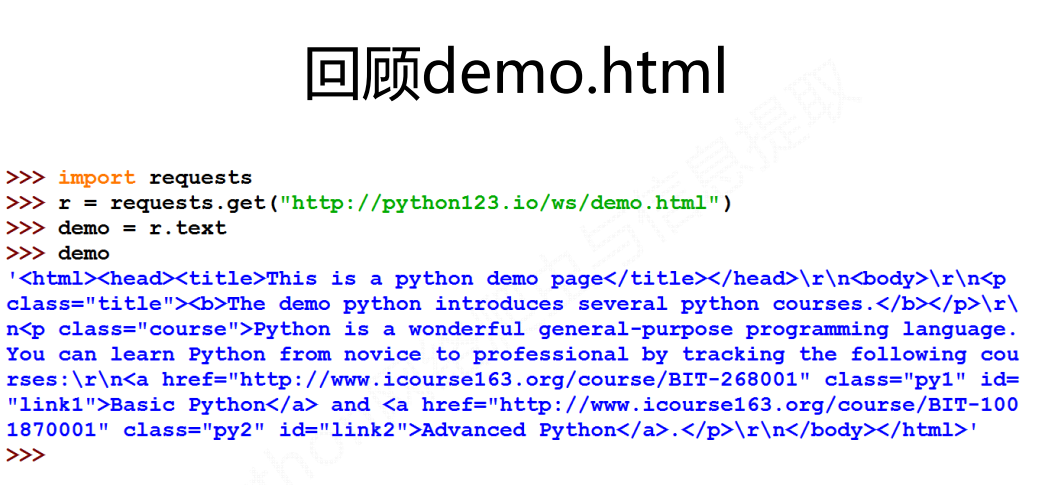
Extract all URL links in HTML
Train of thought:
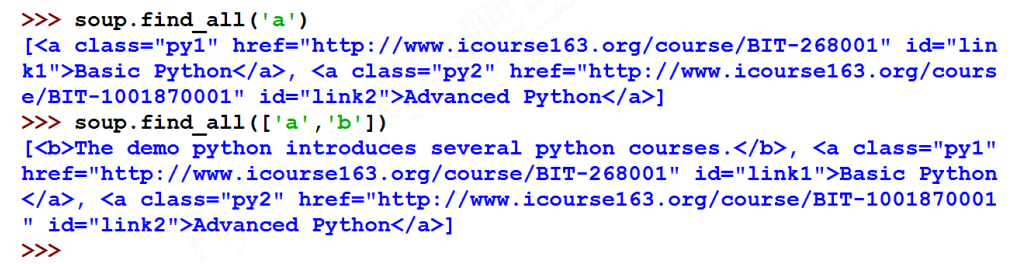
- Search for all < a > tags
- Parse < a > tag format and extract the link content after href
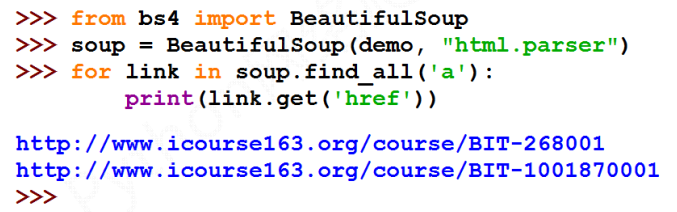
An example of extracting html information based on bs4
<>.find_all(name, attrs, recursive, string, **kwargs)
_name: Retrieval string for tag name
Returns a list type to store the results of the lookup

<>.find_all(name, attrs, recursive, string, **kwargs)
_name: Retrieval string for tag name
_attrs: Retrievable string for tag attribute values that can be tagged for attribute retrieval
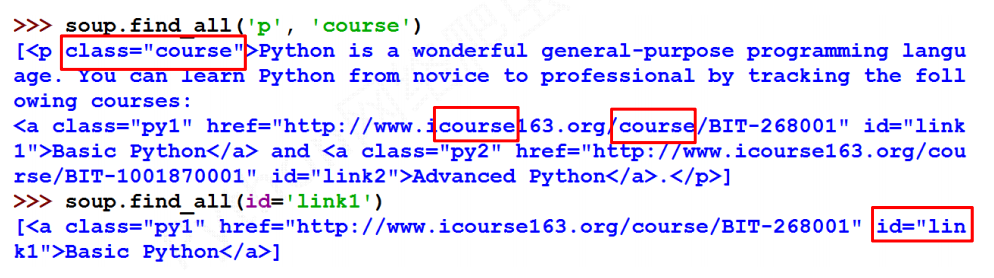
>>> soup.find_all('p', 'course') [<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>] >>> soup.find_all('p','course') [<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>] >>> soup.find_all('p','title') [<p class="title"><b>The demo python introduces several python courses.</b></p>] >>> soup.find_all(id = 'link1') [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>] >>>
<>.find_all(name, attrs, recursive, string, **kwargs)
_name: Retrieval string for tag name
_attrs: Retrievable string for tag attribute values that can be tagged for attribute retrieval
>>> soup.find_all(id = re.compile('link')) [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
<>.find_all(name, attrs, recursive, string, **kwargs)
_name: Retrieval string for tag name
_attrs: Retrievable string for tag attribute values that can be tagged for attribute retrieval
_recursive: Whether to retrieve all descendants, default True
>>> soup.find_all('a') [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>] >>> soup.find_all('a',recursive=False) []
<>.find_all(name, attrs, recursive, string, **kwargs)
_name: Retrieval string for tag name
_attrs: Retrievable string for tag attribute values that can be tagged for attribute retrieval
_recursive: Whether to retrieve all descendants, default True
_string: <>. Retrieval strings for string regions in </>
>>> soup <html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p> </body></html> >>> soup.find_all(string='Basic Python') ['Basic Python'] >>> import re >>> soup.find_all(string=re.compile('python')) ['This is a python demo page', 'The demo python introduces several python courses.']
<tag>(.) is equivalent to <tag>.find_all(.)
Sop (..) is equivalent to soup.find_all(..)
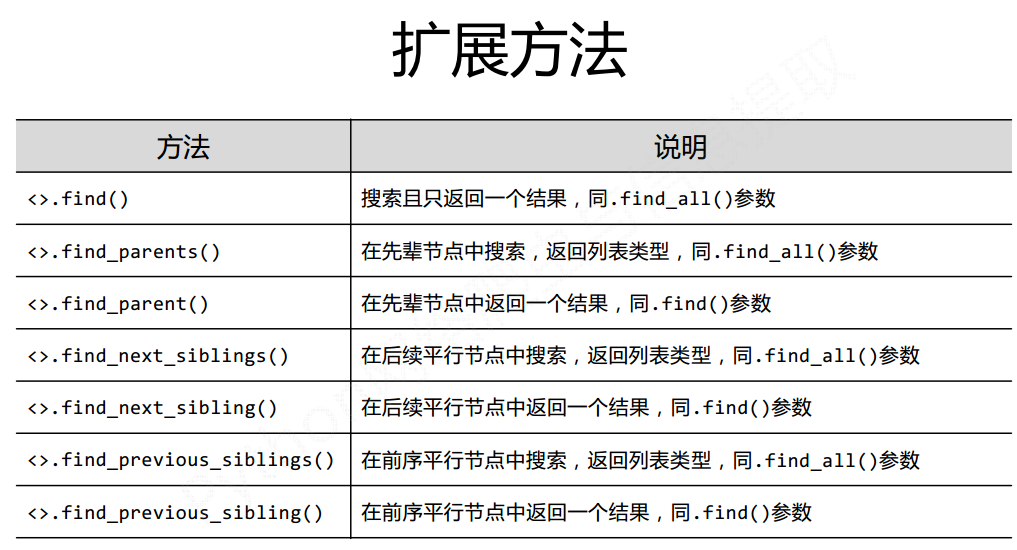
Summary
