Influxdb provides two ways to integrate data: Continuous Queries (CQ: Continuous Queries) and Retention Policies (RP: Retention Policies). The combination of these two methods can not only preserve the data of a long time ago, but also reduce the system resources occupied by the data on the premise of reducing the accuracy. Generally, continuous queries are used as data sampling. I believe all the friends who read this article know something about them.
The maximum accuracy of data sampling provided on the official website can only be up to a week. If I want to achieve monthly sampling, quarterly sampling and annual sampling, the use of Influxdb's CQ is impossible, and I have to deal with it by myself.
Here we talk about using JAVA to realize the custom time sampling of data, other languages are the same reason, can also refer to.
First of all, let's talk about the demand for daily and monthly sampling of existing data.
Prefabricated data:
Hundreds of hours from now on, one per hour, where myname and address are tag s and age are field s, are sampled according to the average age. 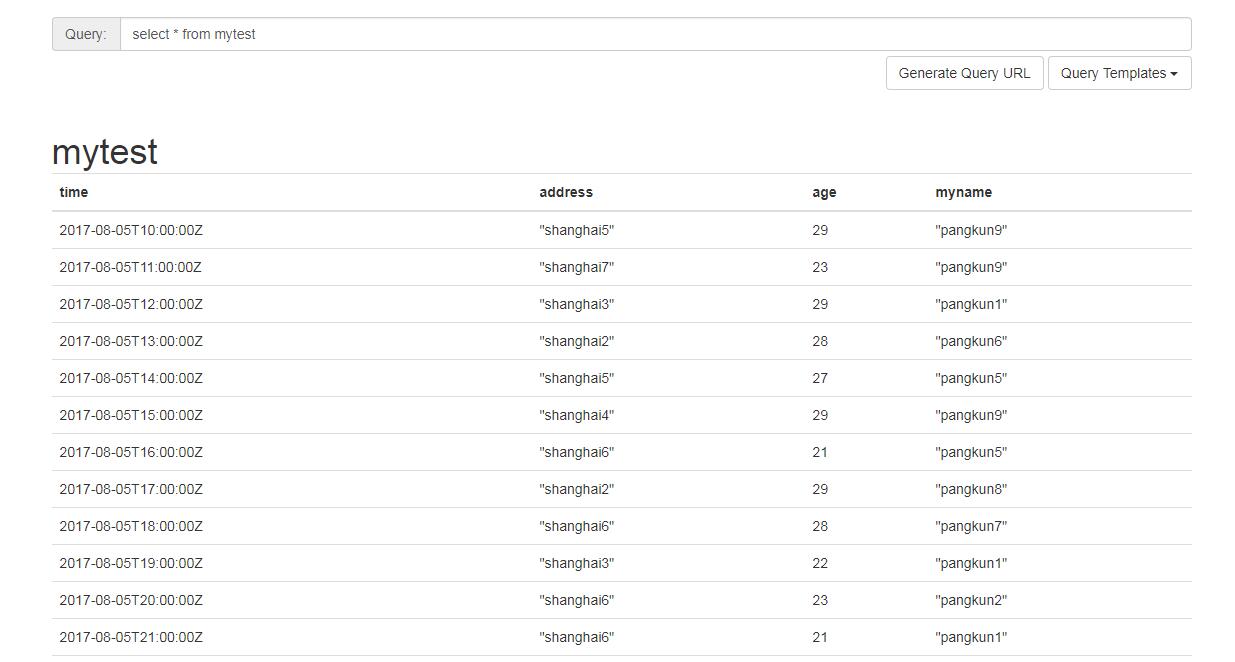
Note: name in Influxdb is similar to the existence of keywords, so it's better not to use it. If you use it, you need quotation marks in general queries.
First of all, according to daily sampling, the function of Influxdb's CQ can be completed, here we use the code to achieve, to facilitate the next month's sampling understanding.
First, the sql executed by the downsampling is explained.
select mean(age) as age into database.rp.day_test from database.rp.mytest where time >=startTime and time <endTime group by time(1h),*Note:
1. This sql can be retrieved from the influx log when CQ is executed.
2. The sampled tables can not be queried when I add database and rp to them. Next, I will omit the database and retention strategy of the sampled tables. However, the data insertion table after sampling must specify the database and retention strategy.
3. group by time(1h) The time here is set according to its own sampling interval. If the time is not more than 1h, the unit can be set directly. If it is more than 1h, if it is 1d, time offset should be considered. The start time and end time are our sampling intervals, which directly determine the time in the time, so we save time(), which is also the key to the realization of monthly sampling or quarterly annual sampling. When removed, startTime becomes the time for all data to be sampled, and the integration meets the requirements.
4. The * in group by represents all tags, which can be listed separately if only some tags are needed.
Daily sampling, we set it to be executed once a day (or several times), which is the same as CQ logic. Look at the code:
public void dayCQ(){
HashMap<String,String> hashMap=this.yesterdayTimeZone();
String url="http://localhost:8086/query?db=billingrecord";
MultiValueMap<String,String> postParameter=new LinkedMultiValueMap<>();
String q="SELECT mean(age) as age INTO billingrecord.rp_90d.day_test FROM mytest WHERE time >="+hashMap.get("startTime")+" AND time < "+hashMap.get("endTime")+" group by *";
System.out.println("q:"+q);
postParameter.add("q",q);
RestTemplate restTemplate=new RestTemplate();
restTemplate.postForObject(url,postParameter,Object.class);
}
//Get the start time and the end time. To avoid the time lag, I use the timestamp directly here.
public static HashMap yesterdayTimeZone(){
long zero = System.currentTimeMillis()/(1000*3600*24)*(1000*3600*24) - TimeZone.getDefault().getRawOffset();
long startTime=zero-3600*24*1000;
long endTime=zero;
HashMap<String,String> hashMap=new HashMap();
hashMap.put("startTime",startTime+"000000");
hashMap.put("endTime",endTime+"000000");
return hashMap;
}The day_test table after execution: 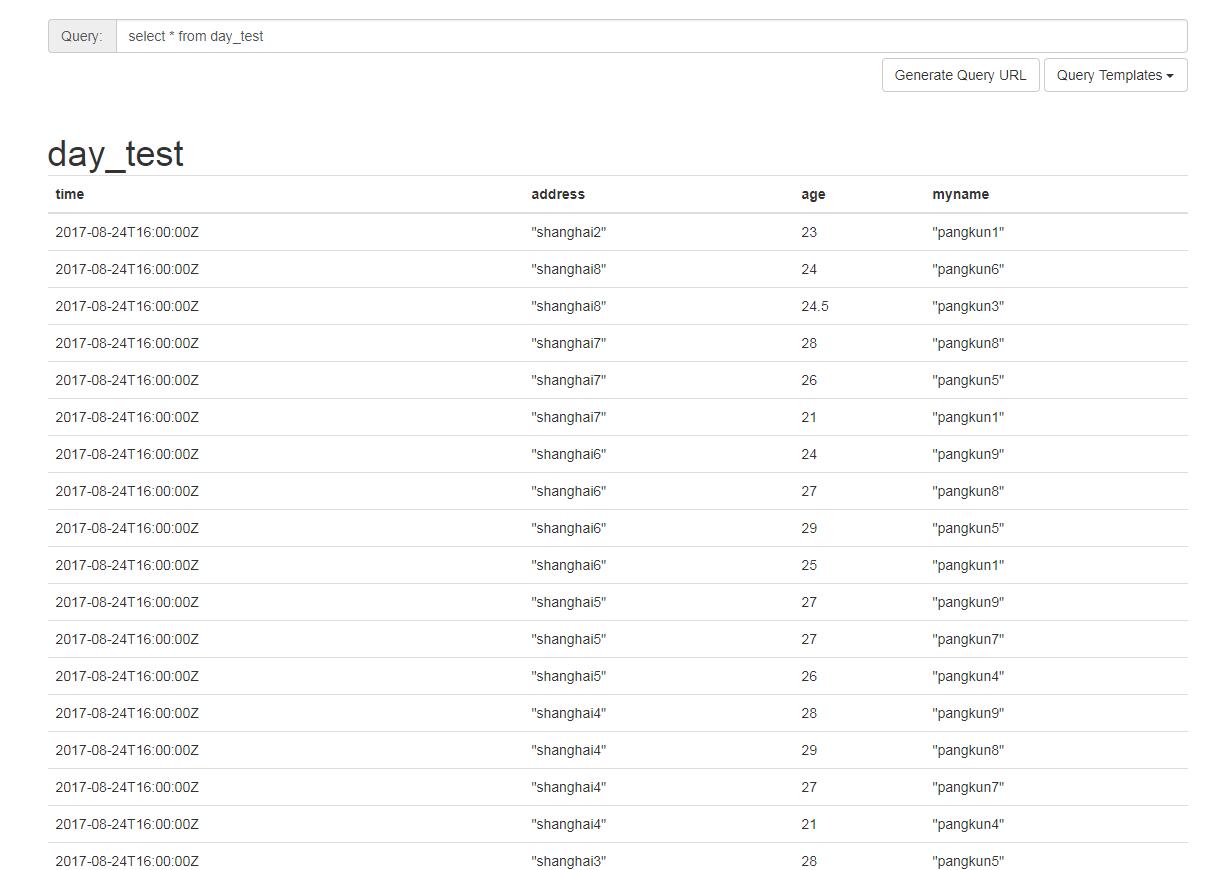
All the time points fall at 16:00 Utc time on the 24th, and the time for the transition to Eastern Eighth District is exactly 10:00 on the 15th.
For special processing, all data in mytest are sampled daily so that we can perform monthly sampling:
public void dayCQ(){
for(int i=1;i<100;i++){
HashMap<String,String> hashMap=this.yesterdayTimeZone(i);
String url="http://localhost:8086/query?db=billingrecord";
MultiValueMap<String,String> postParameter=new LinkedMultiValueMap<>();
String q="SELECT mean(age) as age INTO billingrecord.rp_90d.day_test FROM mytest WHERE time >="+hashMap.get("startTime")+" AND time < "+hashMap.get("endTime")+" group by *";
System.out.println("q:"+q);
postParameter.add("q",q);
RestTemplate restTemplate=new RestTemplate();
restTemplate.postForObject(url,postParameter,Object.class);
}
}
public static HashMap yesterdayTimeZone(int num){
long zero = System.currentTimeMillis()/(1000*3600*24)*(1000*3600*24) - TimeZone.getDefault().getRawOffset();
long startTime=(zero/1000-3600*24*num)*1000;
long endTime=(zero/1000-3600*24*(num-1))*1000;
HashMap<String,String> hashMap=new HashMap();
hashMap.put("startTime",startTime+"000000");
hashMap.put("endTime",endTime+"000000");
return hashMap;
}This is not used in normal sampling, just for testing and writing, and pay attention to processing time data, it is likely that there will be numerical crossing.
Now we do monthly sampling on the basis of daily sampling.
public void monthCQ(){
HashMap<String,String> hashMap=this.lastMonthTimeZone();
String url="http://localhost:8086/query?db=billingrecord";
MultiValueMap<String,String> postParameter=new LinkedMultiValueMap<>();
String q="SELECT mean(age) as age INTO billingrecord.rp_90d.month_test FROM rp_90d.day_test WHERE time >="+hashMap.get("startTime")+" AND time < "+hashMap.get("endTime")+" group by *";
postParameter.add("q",q);
RestTemplate restTemplate=new RestTemplate();
restTemplate.postForObject(url,postParameter,Object.class);
}
public static HashMap lastMonthTimeZone(){
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM");
Calendar cal=Calendar.getInstance();
String endTime=sdf.format(cal.getTime());
cal.add(Calendar.MONTH,-1);
String startTime=sdf.format(cal.getTime());
try {
startTime=sdf.parse(startTime).getTime()+"000000";
endTime=sdf.parse(endTime).getTime()+"000000";
}catch (Exception e){
System.err.println("InfluxDB time deal error");
}
HashMap<String,String> hashMap=new HashMap();
hashMap.put("startTime",startTime);
hashMap.put("endTime",endTime);
return hashMap;
}The sql executed is:
SELECT mean(age) as age INTO billingrecord.rp_90d.month_test FROM rp_90d.day_test WHERE time >=1498838400000000000 AND time < 1501516800000000000 group by *Note: I don't know why, this test time < 1501516800000000 has not been able to use, in other tables are ok, as long as add time < this judgment will not have data, but the first day of the month is actually not time <, sampling the day, the data obtained are the same. I will continue to test this to find out the specific reasons.
Look at the results: 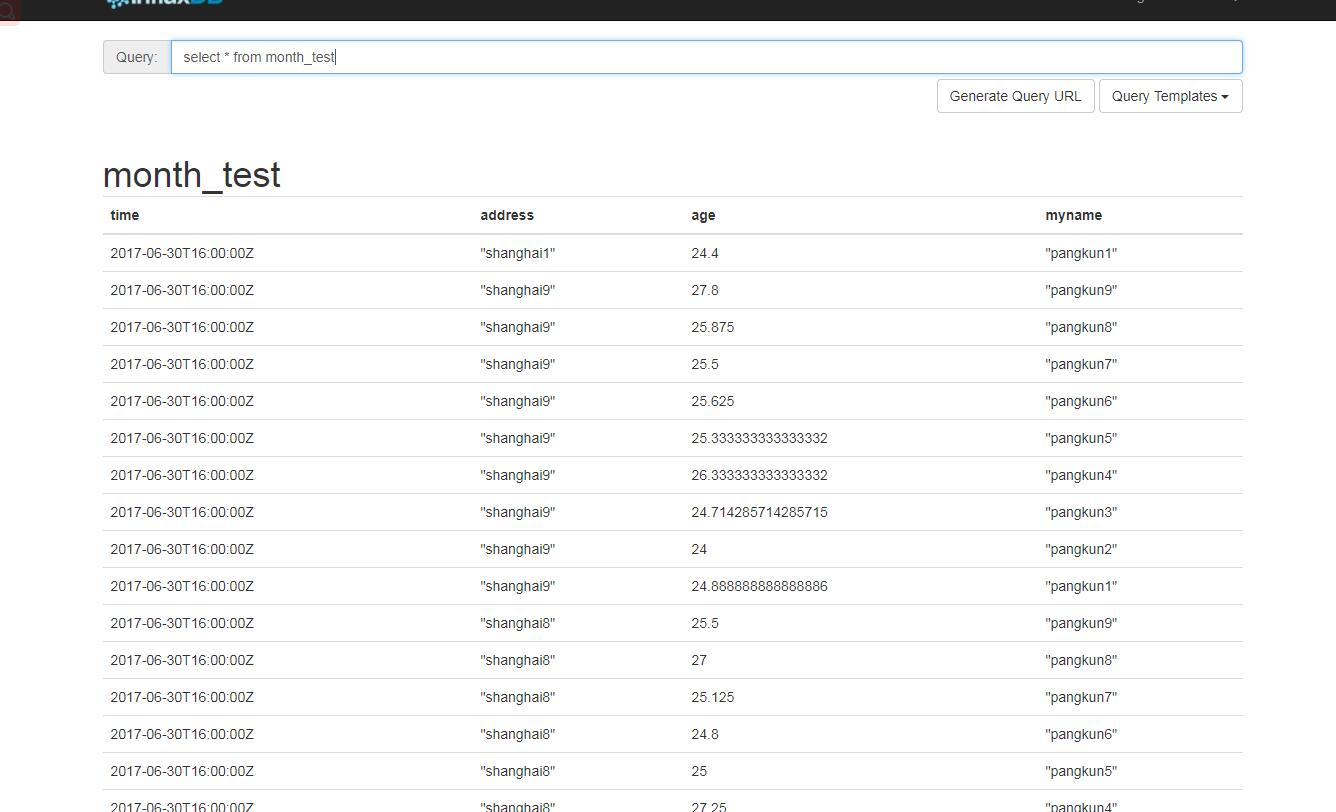
Converted to Eastern Eighth District, the time has fallen to zero on July 1.
Quarterly sampling and annual sampling are also performed in this way on OK.