Today we'll discuss how to use the big data development suite for incremental synchronization.
We divide data that need synchronization into data that will change (personnel table, for example, personnel status will change) and data that will not change (usually log data) according to whether the data will change after writing. For these two scenarios, we need to design different synchronization strategies. Here we take the synchronization of business RDS database data to MaxCompute as an example to illustrate that other data sources are the same. According to the principle of idempotency (i.e. a task, the result of multiple runs is the same, so that the rescheduling can be supported. If the task is wrong, it's easier to clean up dirty data. Every time I import data, I either import it into a separate table/partition or overwrite the historical records in it.
The test time of this paper is 2016-11-14. Full synchronization is done on the 14th. The historical data is synchronized into the partition ds=20161113. As for the incremental synchronization scenario in this paper, automatic scheduling is configured to synchronize the incremental data into the partition ds=20161114 in the early morning of the 15th. There is a time field optime in the data, which is used to indicate the modification time of the data, so as to determine whether the data is incremental.
Invariant data
Corresponding to this scenario, because the data will not change after generation, we can easily partition according to the law of data generation, more common is partitioning according to date, such as one partition per day. The following are the test data:
drop table if exists oplog; create table if not exists oplog( optime DATETIME, uname varchar(50), action varchar(50), status varchar(10) ); Insert into oplog values(str_to_date('2016-11-11','%Y-%m-%m'),'LiLei','SELECT','SUCCESS'); Insert into oplog values(str_to_date('2016-11-12','%Y-%m-%m'),'HanMM','DESC','SUCCESS');
Here are two pieces of data, as historical data. First I do a full data synchronization, to yesterday's partition. The configuration method is as follows:
First create a table in MaxCompute:
--Create well MaxCompute Table, divided by day create table if not exists ods_oplog( optime datetime, uname string, action string, status string ) partitioned by (ds string);
Then the historical data synchronization is configured: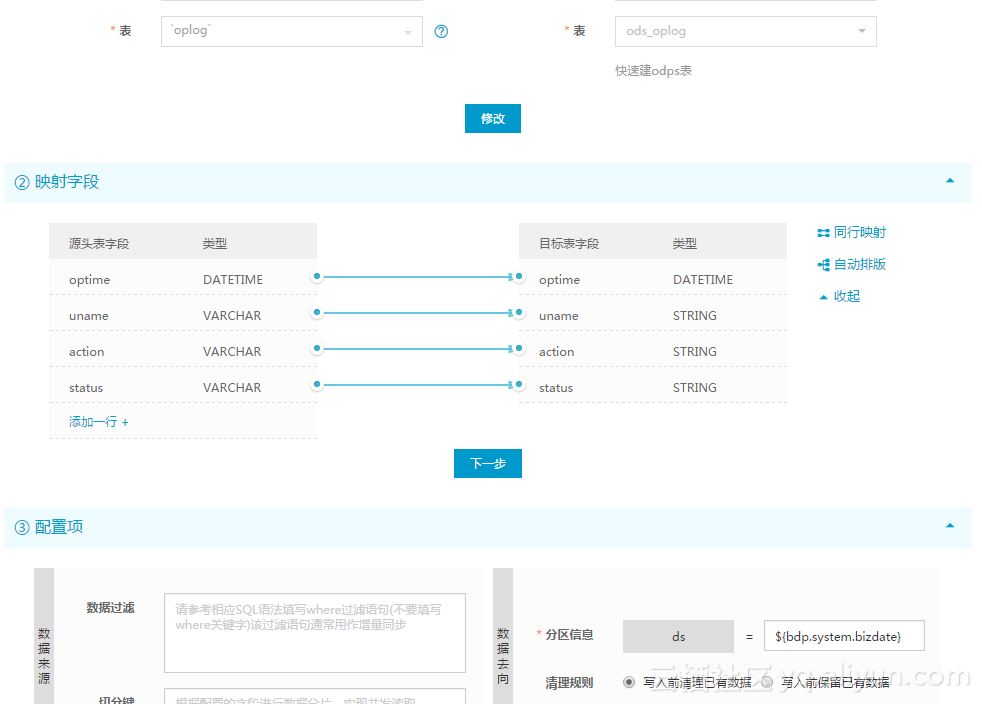
Because you only need to run once, do the following tests. After testing, change the status of the task to pause (the rightmost scheduling configuration) and redistribute it in data development, so that he won't continue running tomorrow. Then go to MaxCompute and see the results: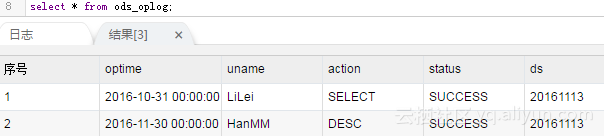
After passing the test. Write more data into Mysql as incremental data:
insert into oplog values(CURRENT_DATE,'Jim','Update','SUCCESS'); insert into oplog values(CURRENT_DATE,'Kate','Delete','Failed'); insert into oplog values(CURRENT_DATE,'Lily','Drop','Failed');
Then configure the synchronization task as follows. Particular attention should be paid to the configuration of data filtering, through which you can query the new data of No. 14 in the morning of the 15th, and then synchronize to the incremental partition.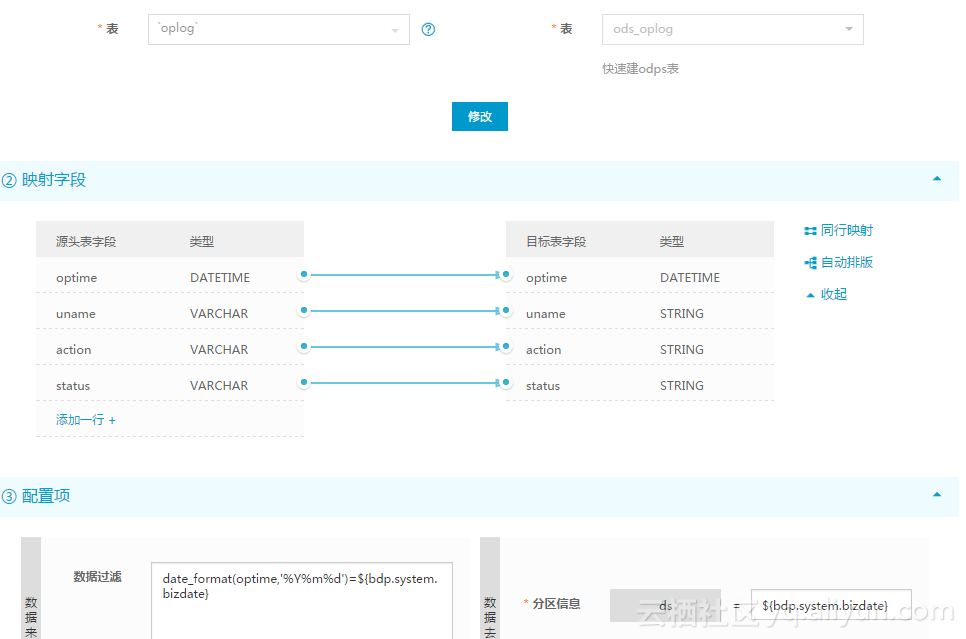
This task needs to be published. Set the scheduling cycle to schedule every day. The next day, when you come to see it, the data in MaxCompute becomes: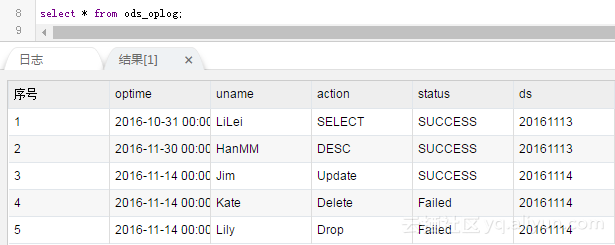
Variable data
For example, data such as personnel table and order table that will change, according to the requirement of historical change reflected in the four characteristics of data warehouse, we recommend that data be synchronized in full every day. That is to say, all the data are saved every day, so that historical data and current data can be easily obtained. However, in a real scenario, incremental synchronization is required every day because MaxCompute does not support Update statements to modify data, and can only be implemented in other ways. The specific methods of the two synchronization strategies are as follows:
First we need to create some data:
drop table if exists user ; create table if not exists user( uid int, uname varchar(50), deptno int, gender VARCHAR(1), optime DATETIME ); --historical data insert into user values (1,'LiLei',100,'M',str_to_date('2016-11-13','%Y-%m-%d')); insert into user values (2,'HanMM',null,'F',str_to_date('2016-11-13','%Y-%m-%d')); insert into user values (3,'Jim',102,'M',str_to_date('2016-11-12','%Y-%m-%d')); insert into user values (4,'Kate',103,'F',str_to_date('2016-11-12','%Y-%m-%d')); insert into user values (5,'Lily',104,'F',str_to_date('2016-11-11','%Y-%m-%d')); --Incremental data update user set deptno=101,optime=CURRENT_TIME where uid = 2; --null Change to non-existent null update user set deptno=104,optime=CURRENT_TIME where uid = 3; --wrong null Change to non-existent null update user set deptno=null,optime=CURRENT_TIME where uid = 4; --wrong null Change to null delete from user where uid = 5; insert into user(uid,uname,deptno,gender,optime) values (6,'Lucy',105,'F',CURRENT_TIME);
Full synchronization per day
Full synchronization per day is relatively simple:
--Full synchronization create table ods_user_full( uid bigint, uname string, deptno bigint, gender string, optime DATETIME ) partitioned by (ds string);
Then configure synchronization as: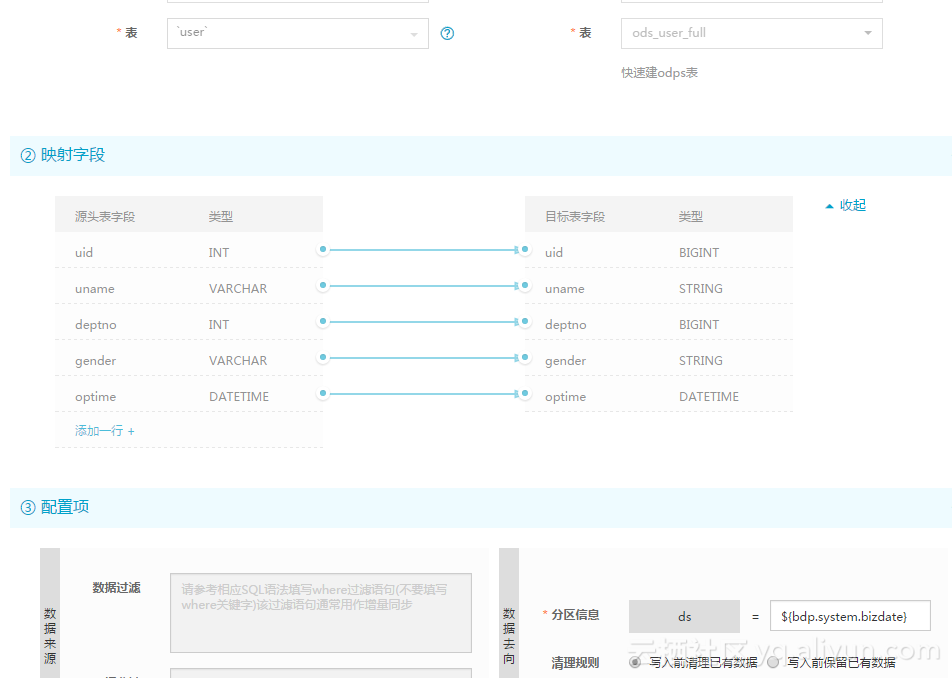
The test results are as follows: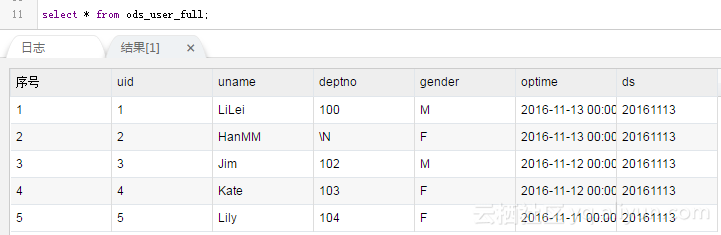
Because every day is synchronized in full, there is no difference between full and incremental, so the next day you can see that the data results are as follows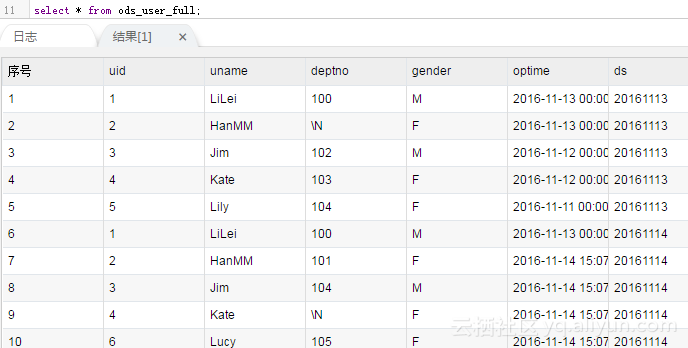
If you need to query, use where ds = 20161114 to fetch the full amount of data.
Daily increment
This method is not recommended very much. It is only considered in very special situations. First, the delete statement is not supported in this scenario, because the deleted data cannot be found through the filter condition of the SQL statement. Of course, in fact, there are few direct deletions of data in the company code, all using logical deletion, then delete is converted to update to process. But after all, there are some special business scenarios that can not be done. When there are special circumstances, the data may be inconsistent. Another disadvantage is that the new data and historical data should be merged after synchronization. Specific practices are as follows:
First you need to create two tables, one to write the latest current data and one to write incremental data:
--Result table create table dw_user_inc( uid bigint, uname string, deptno bigint, gender string, optime DATETIME ); --Incremental Record Table create table ods_user_inc( uid bigint, uname string, deptno bigint, gender string, optime DATETIME )
Full data can then be written directly to the result table: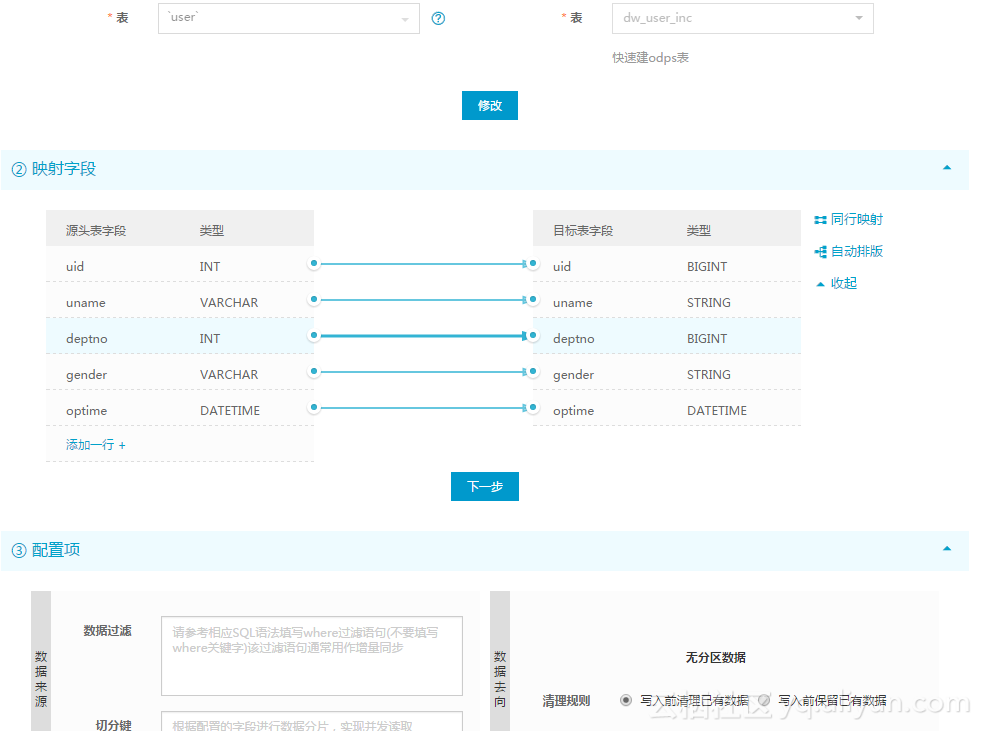
The results are as follows: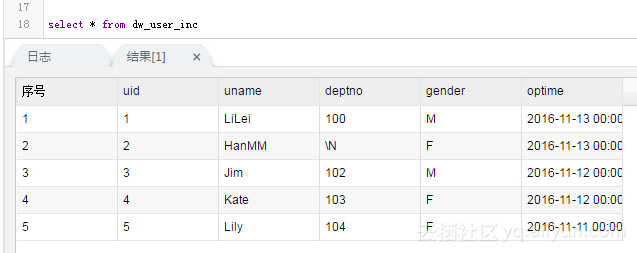
This one only needs to run once, remember to pause after running well.
Then the incremental data is written into the incremental scale: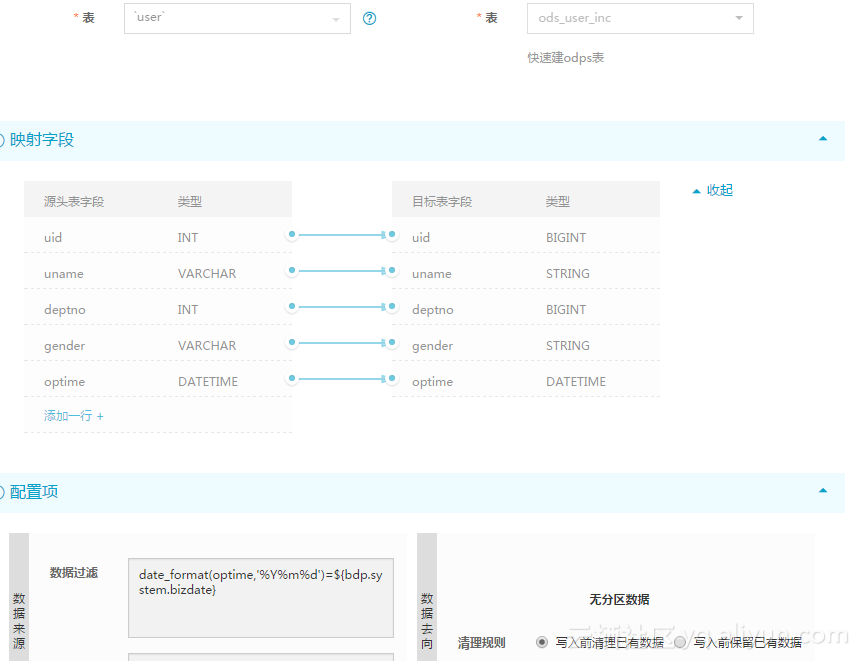
give the result as follows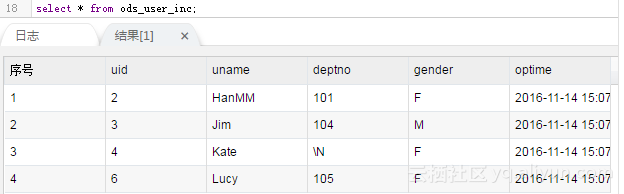
Then do a merger.
insert overwrite table dw_user_inc select --All select Operations, if ODS The table contains data indicating that changes have taken place. ODS Table is correct case when b.uid is not null then b.uid else a.uid end as uid, case when b.uid is not null then b.uname else a.uname end as uname, case when b.uid is not null then b.deptno else a.deptno end as deptno, case when b.uid is not null then b.gender else a.gender end as gender, case when b.uid is not null then b.optime else a.optime end as optime from dw_user_inc a full outer join ods_user_inc b on a.uid = b.uid ;
The end result is: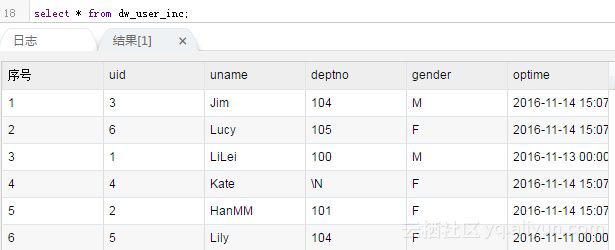
As you can see, the delete record was not synchronized successfully.
Comparing the above two synchronization methods, we can clearly see the differences and advantages and disadvantages of the two synchronization methods. The advantage of the second method is that the amount of synchronized incremental data is relatively small, but the disadvantage may be the risk of data inconsistency, and additional calculation is needed to merge the data. If it is not necessary, the changing data can be used in one way. Lifecycle can be set up if you want to save only a certain amount of time for historical data and delete it automatically when it exceeds time.