From the pool technology to the bottom layer implementation, an article takes you through the thread pool technology.
1. Introduction to pool technology
In the process of system development, we often use pooling technology to reduce system consumption and improve system performance. In the field of programming, the typical pooling technologies are: thread pool, connection pool, memory pool, object pool, etc.
Object pool reduces the overhead of creating objects and garbage collection by reusing objects; connection pool (database connection pool, Redis connection pool, HTTP connection pool, etc.) reduces the time of creating and releasing connections by reusing TCP connections. Thread pool improves performance by reusing threads. In short, pooling technology is to improve performance through reuse.
The connection objects of thread, memory and database are all resources. In the program, when you create a thread or apply for a piece of memory on the heap, it involves a lot of system calls and consumes CPU very much. If your program needs many similar working threads or needs to frequently apply to release small blocks of memory, without optimizing this aspect, this part of code is likely to become a bottleneck affecting your entire program performance.
If you create threads - > execute tasks - > Destroy threads every time, it will cause a lot of performance overhead. Reusing the created threads can improve the performance of the system. With the help of the idea of pooling technology, many threads can be created in advance and put in the pool, which can be obtained directly when the threads need to be used, so as to avoid the overhead of repeated creation and destruction.
(1) Advantages of thread pool
- Threads are scarce resources. Using thread pool can reduce the number of threads created and destroyed, and each worker thread can be reused.
- The number of worker threads in the thread pool can be adjusted according to the tolerance of the system to prevent the server from crashing due to excessive memory consumption.
(2) Risks of thread pool
Although thread pool is a powerful mechanism for building multithreaded applications, there is no risk in using it. Applications built with thread pools are vulnerable to all the concurrency risks that any other multithreaded application is vulnerable to, such as synchronization errors and deadlocks. It is also vulnerable to a few other risks specific to thread pools, such as pool related deadlocks, insufficient resources, and thread leaks.
- deadlock
Any multithreaded application has A deadlock risk. When each of A group of processes or threads is waiting for an event that only another process in the group can cause, we say that this group of processes or threads are deadlocked. The simplest case of deadlock is that thread A holds the exclusive lock of object x and waits for the lock of object Y, while thread B holds the exclusive lock of object Y but waits for the lock of object X. Unless there is A way to break the wait for A lock, which Java locks do not support, the thread of the deadlock will wait forever.
- Insufficient resources
One advantage of thread pools is that they usually perform well relative to other alternative scheduling mechanisms, some of which we have discussed. But this is only true if the thread pool size is properly adjusted.
Threads consume a lot of resources, including memory and other system resources. In addition to the memory required for the Thread object, each Thread requires two potentially large execution call stacks. In addition, the JVM may create a native Thread for each Java Thread that consumes additional system resources. Finally, although the scheduling overhead of switching between threads is very small, if there are many threads, the environment switching may also seriously affect the performance of the program.
If the thread pool is too large, the resources consumed by those threads may seriously affect the system performance. Switching between threads is a waste of time, and using more threads than you actually need can cause a shortage of resources, because pool threads are consuming some resources, which may be used more effectively by other tasks.
In addition to the resources used by the thread itself, other resources, such as JDBC connection, socket or file, may be needed for the work done during the service request. These are also limited resources. Too many concurrent requests may cause failure, such as unable to allocate JDBC connection.
- Concurrent error
Thread pools and other queuing mechanisms rely on the use of wait() and notify() methods, both of which are difficult to use. If the encoding is not correct, notifications may be lost, causing the thread to remain idle, even though there is work in the queue to be processed. Use these methods with great care; even experts can make mistakes on them. It's best to use an existing implementation that you already know works, such as in the util.concurrent package.
- Thread leakage
A serious risk in various types of thread pools is thread leakage, which occurs when a thread is removed from the pool to perform a task, but the thread does not return to the pool after the task is completed. A situation in which a thread leak occurs when a task throws a RuntimeException or an Error.
If the pool class doesn't catch them, the threads will only exit and the size of the thread pool will be permanently reduced by one. When this happens enough times, the thread pool eventually becomes empty and the system stops because there are no threads available to process the task.
- Request overload
It's possible that requests alone can crush the server. In this case, we may not want to queue every incoming request to our work queue, because the tasks in the queue waiting for execution may consume too much system resources and cause resource shortage. In this case, it's up to you to decide what to do; in some cases, you can simply discard the request, rely on a higher-level protocol to retry the request later, or you can reject the request with a response indicating that the server is temporarily busy.
2. How to configure thread pool size configuration
Generally, you need to configure the thread pool size according to the task type:
- If it is a CPU intensive task, you need to squeeze the CPU as much as possible. The reference value can be set to NCPU 1
- If it is an IO intensive task, the reference value can be set to 2*NCPU
Of course, this is only a reference value, and specific settings need to be adjusted according to the actual situation. For example, you can set the thread pool size as a reference value first, and then observe the task operation, system load and resource utilization to make appropriate adjustments.
3. The underlying principle of thread pool
(1) Status of thread pool
Thread pool has its own state as thread. A volatile variable runState is defined in ThreadPoolExecutor class to represent the state of thread pool. Thread pool has four states, namely RUNNING, SHURDOWN, STOP and TERMINATED.
- Thread pool is in RUNNING state after creation.
- When shutdown is called, it is in shutdown state. The thread pool cannot accept new tasks. It will wait for the task of buffer queue to complete.
- When shutdown now is called, it is in the STOP state. The thread pool cannot accept new tasks and attempts to terminate the executing tasks.
- When the thread pool is in SHUTDOWN or STOP state, and all the working threads have been destroyed, the task cache queue has been emptied or the execution has ended, the thread pool is set to TERMINATED state.
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }Among them, ctl, the AtomicInteger, has powerful functions. Its upper three bits are used to maintain the running state of the thread pool, and the lower 29 bits are used to maintain the number of threads in the thread pool
RUNNING: -1
SHUTDOWN: 0
STOP: 1
TIDYING: 2
TERMINATED: 3
These states are represented by int type, and the size relationship is RUNNING
- runStateOf(int c) method: C & the ~ CAPACITY with the high 3 bits of 1 and the low 29 bits of 0 is used to obtain the thread pool state saved by the high 3 bits
- workerCountOf(int c) method: C & CAPACITY with high 3 bits of 0 and low 29 bits of 1, used to get the number of threads with low 29 bits
- ctlOf(int rs, int wc) method: the parameter rs represents runState, and the parameter wc represents workerCount, that is, according to runState and workerCount, it is packed and merged into ctl
(2) Why ctl is responsible for two roles
In the design of Doug Lea, ctl is responsible for two roles to avoid redundant synchronization logic.
Many people will think that a variable representing two values saves storage space, but it's obviously not designed to save space. Even if this value is divided into two Integer values, a thread pool will have four bytes more. It's obviously not the original intention of Doug Lea to design a large-scale communication for these four bytes.
In the multithreaded environment, the running state and the number of effective threads often need to be unified. If they are placed in the same atomicinter and atomic operation of atomicinter is used, the two values can always be unified.
(3) Thread pool workflow
Some threads are started in advance, and the thread infinite loop obtains a task from the task queue for execution until the thread pool is closed. If a thread is terminated due to an exception in executing a task, it is only necessary to recreate a new thread, so on and on.
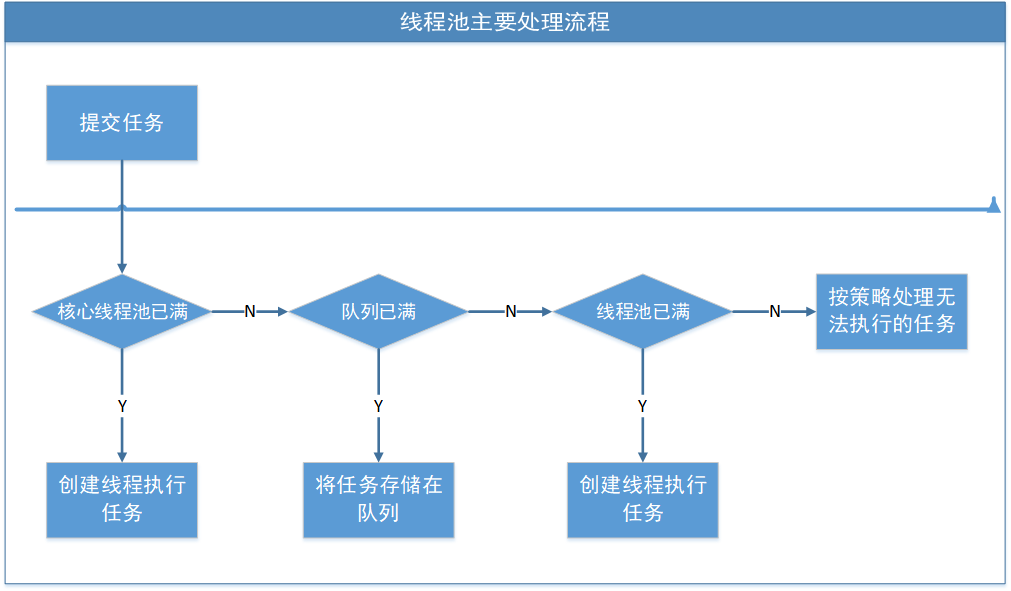
The process of a task from submission to completion is as follows:
Step 1: if the number of threads in the current thread pool is less than corePoolSize, a thread will be created to execute each task;
Step 2: if the number of threads in the current thread pool is > = corepoolsize, each task will be added to the task cache queue. If it is added successfully, the task will wait for the idle thread to take it out for execution. If the addition fails (generally speaking, the task cache queue is full), a new thread will be created to execute the task;
Step 3: if the number of threads in the thread pool is greater than or equal to corePoolSize, and the queue workQueue is full, but the number of threads in the thread pool is less than maximumPoolSize, a new thread will be created to process the added task
Step 4: if the number of threads in the current thread pool reaches maximumPoolSize, the task rejection policy will be adopted for processing;
The flow chart is as follows:
4. ThreadPoolExecutor parsing
ThreadPoolExecutor inherits from AbstractExecutorService and implements ExecutorService interface. It is also the default thread pool implementation class of Executor framework. Generally, we use thread pool. If there is no special requirement, we directly create ThreadPoolExecutor and initialize a thread pool. If a special thread pool is needed, we directly inherit ThreadPoolExecutor and implement specific functions , such as ScheduledThreadPoolExecutor, which is a thread pool with scheduled tasks.
(1) Executor framework
Before going deep into the source code, first look at the thread pool class diagram in the J.U.C package:
At the top is an Executor interface, which has only one method:
public interface Executor {
void execute(Runnable command);
}
It provides a simple way to run new tasks, also known as the Executor framework.
ExecutorService extends Executor, adds methods to control the life cycle of thread pool, such as shutDown(), shutDownNow(), and extends methods that can asynchronously track the execution task to generate the return value Future, such as submit().
(2) Worker resolution
The Worker class inherits AQS and implements the Runnable interface. It has two important member variables: firstTask and thread. The first task is used to save the task created for the first time; thread is the thread created through ThreadFactory when calling the construction method, which is used to process the task.
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}It should be noted that the data structure of workers is HashSet, which is not thread safe. Therefore, synchronization lock should be added to operate workers. After the add step is completed, start the thread to execute the task.
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet<Worker> workers = new HashSet<Worker>();
(3) How to add tasks to the process pool
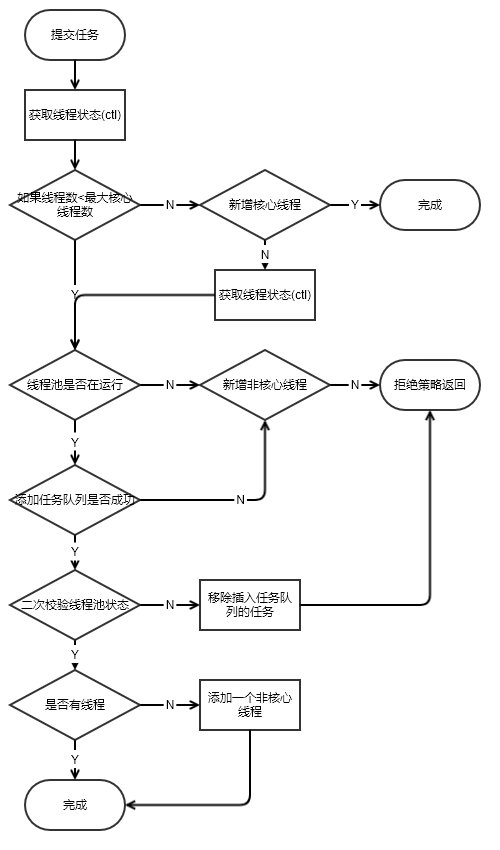
To execute a task, the thread pool must first add a task. Although execute() means to execute a task, it also includes the steps to add a task. The source code is as follows:
public void execute(Runnable command) {
// If the add order task is empty, the null pointer is abnormal
if (command == null)
throw new NullPointerException();
// Get ctl value
int c = ctl.get();
// 1. If the current number of valid threads is less than the number of core threads, call addWorker to execute the task (that is, create a thread to execute the task)
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2. If the current effective thread is greater than or equal to the number of core threads, and the current thread pool state is running, add the task to the blocking queue and wait for the idle thread to get out of the queue for execution
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3. If the blocking queue is full, call addWorker to execute the task (that is, create a thread to execute the task)
else if (!addWorker(command, false))
// If the thread creation fails, the thread rejection policy is called
reject(command);
}addWorker adds tasks. The source code of the method is a little long. It is divided into two parts according to the logic
java.util.concurrent.ThreadPoolExecutor#addWorker:
retry:
for (;;) {
int c = ctl.get();
// Get the current running state of thread pool
int rs = runStateOf(c);
// If rs is greater than SHUTDOWN, the thread pool is no longer accepting new tasks
// If rs is equal to SHUTDOWN, and the first task is empty, and if there is a task in the blocking queue, continue to execute the task
// It also means that if the thread pool is in SHUTDOWN state, you can continue to perform tasks in the blocking queue, but you cannot continue to add tasks to the thread pool
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// Get the number of valid threads
int wc = workerCountOf(c);
// You cannot add a task if the number of valid threads is greater than or equal to the maximum number of threads in the thread pool, which is almost impossible
// Or the number of valid threads is greater than or equal to the current limit, and the task cannot be added
// Limit the number of threads. The core thread is used to execute tasks. core=true
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// Using AQS to increase the number of effective threads
if (compareAndIncrementWorkerCount(c))
break retry;
// If you get the ctl variable value again
c = ctl.get(); // Re-read ctl
// Compare the operation status again. If it is inconsistent, execute the cycle again
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
It is particularly emphasized here that the first task is the first task to start thread execution, and then the tasks executed by threads resident in the thread pool are taken out of the blocking queue, which needs attention.
The above for loop code is mainly used to determine whether tasks can be added to the current state of ctl variables. It is particularly explained that if the thread pool is in SHUTDOWN state, tasks in the blocking queue can continue to be executed, but tasks cannot be added to the thread pool. At the same time, AQS is used to increase the number of working threads for synchronization. If synchronization fails, the loop execution will continue.
// Whether the task has been executed
boolean workerStarted = false;
// Whether the task has been added
boolean workerAdded = false;
// Task wrapper class, our tasks need to be added to Worker
Worker w = null;
try {
// Create a Worker
w = new Worker(firstTask);
// Get the Thread value in Worker
final Thread t = w.thread;
if (t != null) {
// Operation of workers HashSet data structure needs to be locked synchronously
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// Get the running status of the current thread pool
int rs = runStateOf(ctl.get());
// RS < shutdown indicates RUNNING status;
// If rs is RUNNING or rs is SHUTDOWN and firstTask is null, add threads to the thread pool.
// Because new tasks will not be added during SHUTDOWN, but tasks in workQueue will still be executed
// When rs is RUNNING, create a thread to execute the task directly
// When rs is equal to SHUTDOWN, and firstTask is empty, you can also create a thread to execute tasks, which means that when SHUTDOWN is in the state, you will not accept new tasks
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// Start thread execution task
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
The main function of the above source code is to create a Worker object, and load new tasks into the Worker, enable synchronization and add the Worker to the workers. Here, it should be noted that the data structure of the workers is HashSet, which is non thread safe. Therefore, synchronization lock is required to operate the workers. After the adding step is completed, start the thread to execute the task, and continue to look down.
(4) Front and back hooks
If you need to insert logic before and after task execution, you can implement ThreadPoolExecutor in two ways:
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Runnable r, Throwable t) { }In this way, the task execution can be monitored in real time.
5. Thread pool summary
Key technologies of thread pool principle: lock (CAS), blocking queue, hashSet (resource pool)
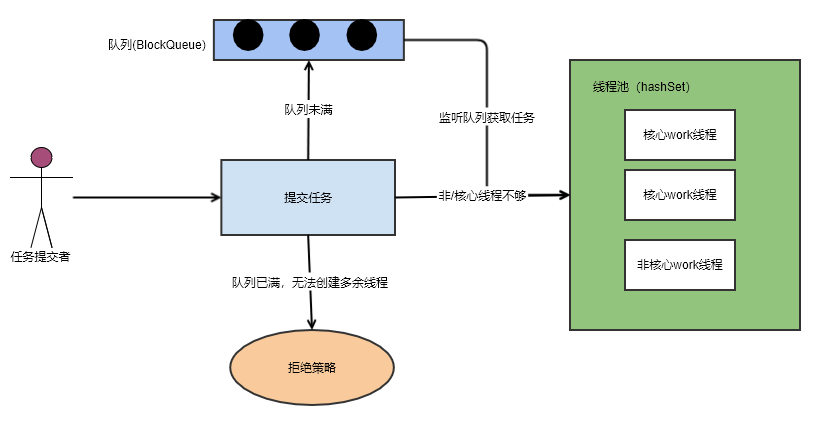
The so-called thread pool is essentially a hashSet of Worker objects, and redundant tasks will be placed in the blocking queue. Only when the blocking queue is full, can the creation of non core threads be triggered. Non core threads only temporarily come to do miscellaneous work until they are idle, and then close by themselves. The thread pool provides us with two hooks (before execute, after execute). We inherit the thread pool and do something before and after the task.
Pay attention to the public number: architecture evolution theory, get first-hand technical information and original articles.

