1: Prepare picture data, a training data, a test data. The structure is as follows: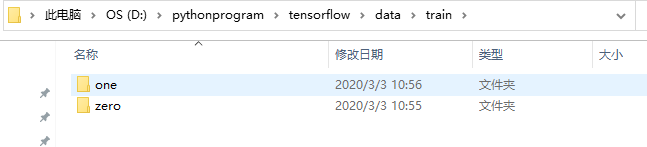
Download the retrain.py program (https://github.com/tensorflow/hub). In the image train under the example folder, if the retrain.py program downloaded from the above link reports an error that cannot be connected during training, use the following retrain.py instead (I haven't figured out what has been changed internally).
https://github.com/zxq201988/deeplearning-code
Save the downloaded retry.py to D: \ tensorflow \ retry \
3: Download inception-v3 model
http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
Save the compressed package in the D: \ tensorflow \ inception \ model folder. You do not need to unzip it.
Create the batch command file retry.bat. The contents are as follows:
Path to Python e: / tensorflow / retry / retry.py ^ ා retry.py file
– bottleneck ﹐ dir bottleneck ^ ﹐ the path of the bottleneck folder, which is the same folder as the retrain.py by default
– how many training steps 200 iterations
– model? Dir e: / tensorflow / inception? Model / ^? Compression package path of the inception-v3 model
– output? Graph output? Graph.pb ^? The model file name of the output
– output? Labels output? Labels.txt ^
– image? Dir e: \ tensorflow \ retrain \ data \ train? Own training data set storage path
pause
Create a new folder named bottleneck under D:\TensorFlow\retrain \ to store the. txt file of each picture after batch processing.
The final directory structure is shown in the figure below: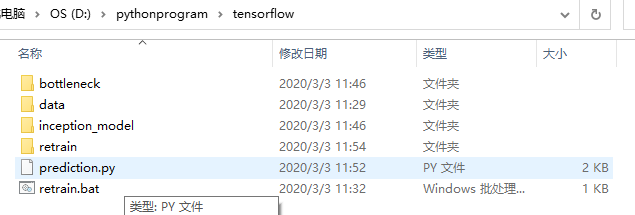
After that, run the retrain.bat file to train the model on the command line,
After the training, you can use the test data to test the quality of your model. The following is the test code. Just change the path of the test data in the code and run it in the python environment
# coding: utf-8 import tensorflow as tf import os import numpy as np import re from PIL import Image import matplotlib.pyplot as plt lines = tf.gfile.GFile('retrain/output_labels.txt').readlines() uid_to_human = {} #Read data line by line for uid,line in enumerate(lines) : #Remove line breaks line=line.strip('\n') uid_to_human[uid] = line def id_to_string(node_id): if node_id not in uid_to_human: return '' return uid_to_human[node_id] #Create a graph to store google trained models with tf.gfile.FastGFile('retrain/output_graph.pb', 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) tf.import_graph_def(graph_def, name='') with tf.Session() as sess: softmax_tensor = sess.graph.get_tensor_by_name('final_result:0') #Traversal directory for root,dirs,files in os.walk('data/test/'): #Test picture storage location for file in files: #Load Images image_data = tf.gfile.FastGFile(os.path.join(root,file), 'rb').read() predictions = sess.run(softmax_tensor,{'DecodeJpeg/contents:0': image_data})#The image format is jpg predictions = np.squeeze(predictions)#Convert results to 1D data #Print image path and name image_path = os.path.join(root,file) print(image_path) #display picture img=Image.open(image_path) plt.imshow(img) plt.axis('off') plt.show() #sort top_k = predictions.argsort()[::-1] print(top_k) for node_id in top_k: #Get category name human_string = id_to_string(node_id) #Obtain the confidence of the classification score = predictions[node_id] print('%s (score = %.5f)' % (human_string, score)) print()
Reference: https://blog.csdn.net/weixin_/article/details/80555341

