Why use in-map aggregation? What's the difference between in-map aggregation and combine? When use combiner? When use in-map aggregation?
Let's start with a picture to see where combiner is in a mr job.
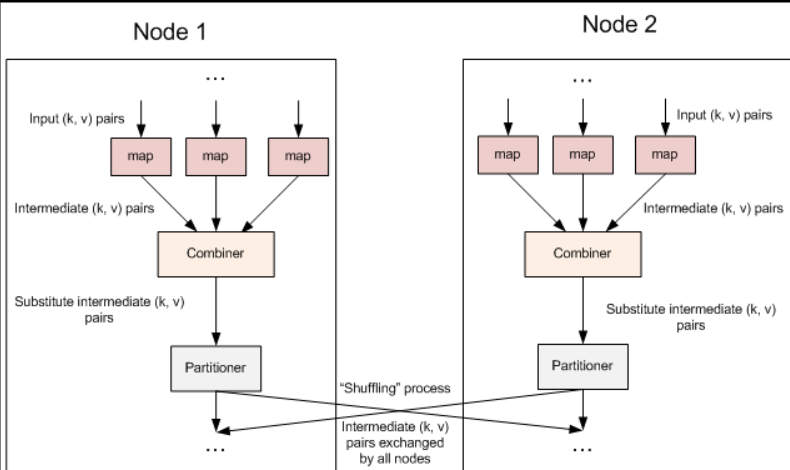
Dry goods below:
Data files are read by InputFormat and processed in the Map phase. After the Map is processed, the result key value pair is written to a ring buffer in the memory of the Map task node. Key Value pairs written to the cache are already serialized, which is a key point!
Then when the map task ends or the buffer utilization reaches a certain stage, spill overwriting (at least once disk writing occurs on the map side) occurs, and Combine is invoked to aggregate before spill overwriting.
When Combine gets the serialized key value pair, it first deserializes it, then aggregates it, and then serializes it to disk. This is the process of Combine.
What is the concept of in-map aggregation?
in-map aggregation refers to the aggregation of map results when they are output, thus avoiding the process of deserialization-processing-re-serialization.
The specific implementation uses two methods of Map: setup () and cleanup().
setup: A method that is first executed before the map task runs.
Cleaup: A method that is executed at the end of the current map task run.
Specifically through the code experience: Note that context.write is executed in the cleanup method.
public static class MyWordCountMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
Logger log = Logger.getLogger(MyWordCountJob.class);
Map<Character,Integer> map = new HashMap<Character,Integer>();
Text mapKey = new Text();
IntWritable mapValue = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
for(char c :value.toString().toLowerCase().toCharArray()){
if(c>='a' && c <='z'){
map.put(c,map.get(c)+1);
}
}
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
for(char key : map.keySet()){
mapKey.set(String.valueOf(key));
mapValue.set(map.get(key));
context.write(mapKey, mapValue);
}
}
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
for(char c='a';c<='z' ;c++){
map.put(c, 0);
}
}
}Look at the results of implementation
16/05/11 06:25:30 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=630
FILE: Number of bytes written=338285
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=556
HDFS: Number of bytes written=107
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=515880
Total time spent by all reduces in occupied slots (ms)=68176
Map-Reduce Framework
Map input records=8
Map output records=78
Map output bytes=468
Map output materialized bytes=642
Input split bytes=399
Combine input records=0
Combine output records=0
Reduce input groups=26
Reduce shuffle bytes=642
Reduce input records=78
Reduce output records=26
Spilled Records=156
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=164
CPU time spent (ms)=3490
Physical memory (bytes) snapshot=1089146880
Virtual memory (bytes) snapshot=3962114048
Total committed heap usage (bytes)=868352000
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=157
File Output Format Counters
Bytes Written=107Through Counter, we can see that the input of Reducer is 78, and the effect of using Combiner is the same. Map output was reduced to 78 records.
Continuing with this example, you can see that the code defines a map to store the number of characters. The maximum number of records in this map is 26, which occupies little memory, so this is applicable.
If we count the number of words, and the number of words is very large, it may lead to map task memory can not be stored, then this situation is not applicable! uuuuuuuuuuuu