1. Overview and principle of MapReduce
MapReduce is a distributed computing model
MapReduce runs distributed and consists of two stages: Map and reduce. The Map stage is an independent program, with many nodes running at the same time, and each node processes part of the data. The reduce phase is an independent program, with many nodes running at the same time, and each node processes part of the data [here, reduce can be understood as a separate aggregation program]. The MapReduce framework has a default implementation. Users only need to override the map() and reduce() functions to realize distributed computing, which is very simple. The formal parameters and return values of these two functions are < key, value >, so be sure to construct < K, V > when using them.
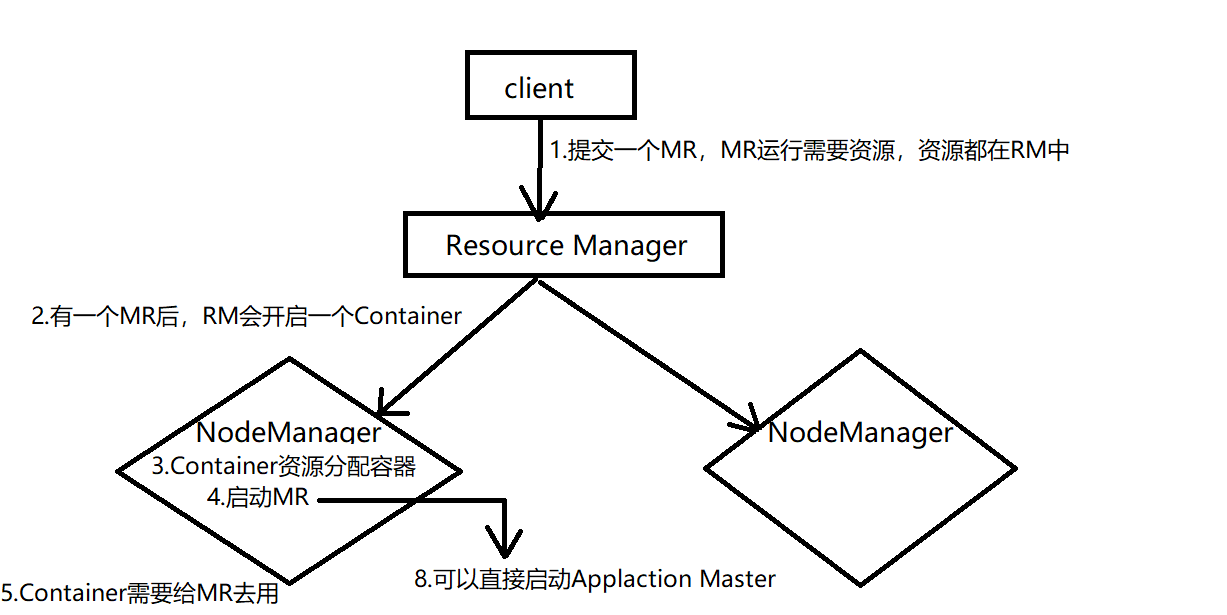
2. Execution process of MapReduce on yarn

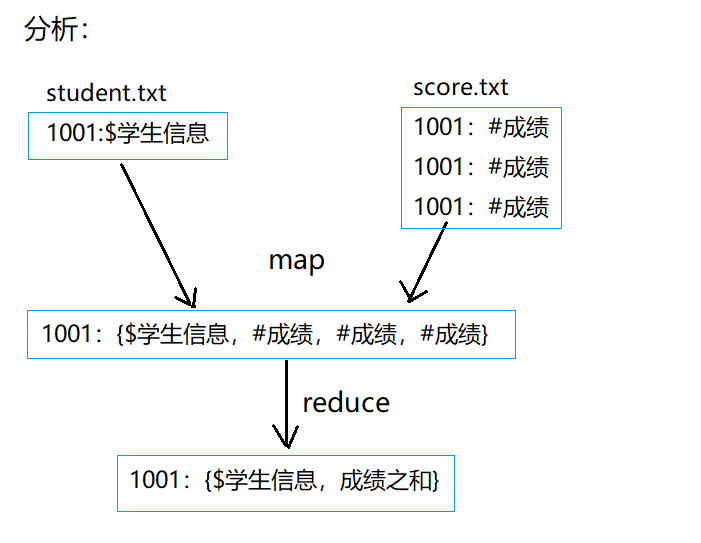
3,reduce join
/**
* map Read two files and splice the two files
* map 1.Judge the data source
* 2.Mark according to data source
* reduce 3.Cyclic data acquisition
* 4.Judge the data mark and what number is obtained
* 5.Do different processing according to different data
*/
public class MR07Join {
public static class JoinMapper extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//The block address can be obtained through InputSplit
//Get slices through context (student.txt,score.txt)
InputSplit inputSplit = context.getInputSplit();
FileSplit fileSplit =(FileSplit) inputSplit;
//Get the path, there are two (stu, sco)
String path = fileSplit.getPath().toString();
//Judgment path
if(path.contains("student")) {
String id = value.toString().split(",")[0];
String stu = "$"+value.toString();
context.write(new Text(id),new Text(stu));
}else{
String id = value.toString().split(",")[0];
String sco="#"+value.toString();
context.write(new Text(id),new Text(sco));
}
}
}
//id: {$student information, # grade, # grade, # grade}
public static class JoinReducer extends Reducer<Text,Text,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String stu =null;
ArrayList<Integer> scos = new ArrayList<Integer>();
for (Text value : values) {
String s = value.toString();
if (s.startsWith("$")){//Student information
stu=s;
}else{//It's achievement
int scoce = Integer.parseInt(s.split(",")[2]);
scos.add(scoce);
}
}
//Sum first, then splice
long sum=0;
for (Integer sco : scos) {
sum+=sco;
}
stu=stu+","+sum;
context.write(new Text(stu),NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Job job = Job.getInstance();
job.setJobName("join");
job.setJarByClass(MR07Join.class);
job.setMapperClass(JoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(JoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
Path input1 = new Path("/student.txt");
FileInputFormat.addInputPath(job,input1);
Path input2 = new Path("/score.txt");
FileInputFormat.addInputPath(job,input2);
Path output = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
if(fs.exists(output)){
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
job.waitForCompletion(true);
System.out.println("join");
}
}
4,map join
In the map phase, you cannot get all the required join fields, that is, the fields corresponding to the same key may be located in different maps. Reduce side join is very inefficient because a large amount of data transmission is required in the shuffle phase.
Map side join is optimized for the following scenarios: one of the two tables to be connected is very large and the other is very small, so that the small table can be stored directly in memory. In this way, we can copy multiple copies of the small table so that there is one copy in the memory of each map task (for example, stored in the hash table), and then only scan the large table: for each record key/value in the large table, find out whether there are records with the same key in the hash table. If so, connect and output.
public class MR08MapJoin {
public static class MapJoinMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
//Use HashMap to store the data in the small table student
HashMap<String ,String > stus =new HashMap<String,String>();
@Override
//setup (execute before the map task, execute every time, and read the small table)
protected void setup(Context context) throws IOException, InterruptedException {
FileSystem fs = FileSystem.get(new Configuration());
Path path = new Path("/student.txt");
FSDataInputStream open = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(open));
String line;
if((line=br.readLine())!=null){
stus.put(line.split(",")[0],line);
}
super.setup(context);
}
@Override
//map (each piece of data is executed once)
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
String id = line.split(",")[0];
//join stu + score
String stu = stus.get(id);
String str =stu+","+split[2];
context.write(new Text(str),NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJobName("MapJoin");
job.setJarByClass(MR08MapJoin.class);
//If reduce is not available, the parameter must be set to 0
//There is a default reduce code in mapreduce, and the reduce task defaults to 1
job.setNumReduceTasks(0);
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
Path input = new Path("/score.txt");
Path output = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
if(fs.exists(output)){
fs.delete(output,true);
}
FileInputFormat.addInputPath(job,input);
FileOutputFormat.setOutputPath(job,output);
job.waitForCompletion(true);
}
}
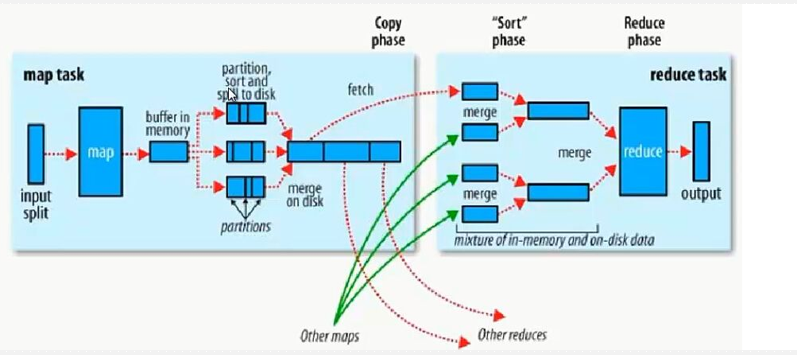
5. shuffle principle of MapReduce
1) block for split segmentation
2) A split slice corresponds to a maptask
3) Each map has a ring memory buffer for storing the output of the map. The default size is 100MB. Once the threshold value of 80% is reached, the data is written to the disk (data landing).
4) Before writing to the disk, partition and sort (partition sort) should be
5) When the final record is written, merge all files into one partition and sorted files.
6) Merge save to disk (data landing)
7) Get the complete file and send it to hdfs through reduce
Note: Data landing occurs twice during shuffle
6. Combiner prepolymerization
combiner performs the reduce operation on the map side. The function is to reduce the output of the map end, reduce the amount of data transmitted by the network in the shuffle process, and improve the execution efficiency of the job.
Combiner is only the reduce of a single map task. It does not reduce the output of all maps. If combiner is not used, all results are completed by reduce, and the efficiency will be relatively low. Using combiner, the first completed map will be aggregated locally to improve the speed.
Note: the output of combiner is the input of Reducer. Combiner must not change the final calculation result. Therefore, Combine is suitable for exponentiation operations, such as accumulation, maximum, etc. Averaging is not appropriate
/**
* combine Prepolymerization
* map Before and after reduce
*/
public class MR05Gender {
public static class GenderMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
if("male".equals(split[3])){
context.write(new Text("male"),new LongWritable(1));
}
}
}
public static class CombineReducer extends Reducer <Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count=0;
for (LongWritable value : values) {
count+=value.get();
}
context.write(key,new LongWritable(count));
}
}
public static class GenderReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count=0;
for (LongWritable value : values) {
count+=value.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJobName("combine Prepolymerization");
job.setJarByClass(MR05Gender.class);
job.setMapperClass(GenderMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setCombinerClass(CombineReducer.class);
job.setReducerClass(GenderReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
Path input = new Path("/student.txt");
FileInputFormat.addInputPath(job,input);
Path output = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
if(fs.exists(output)){
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
job.waitForCompletion(true);
System.out.println("combine Prepolymerization");
}
}
7. MapReduce optimization summary
1) Control the amount of map data by modifying the slice size of the map (try to keep consistent with the block size)
2) Merge small files. Because a file will generate at least one map
3) Avoid data skew, i.e. uneven distribution of keys (keys can be marked and time stamped manually)
4) combine operation (map side pre aggregation)
5) mapjoin operation (map small table broadcast)
6) Appropriate backup, because multiple backups can localize the map generation task