The experiment in this chapter is quite interesting. Simply record the practice.
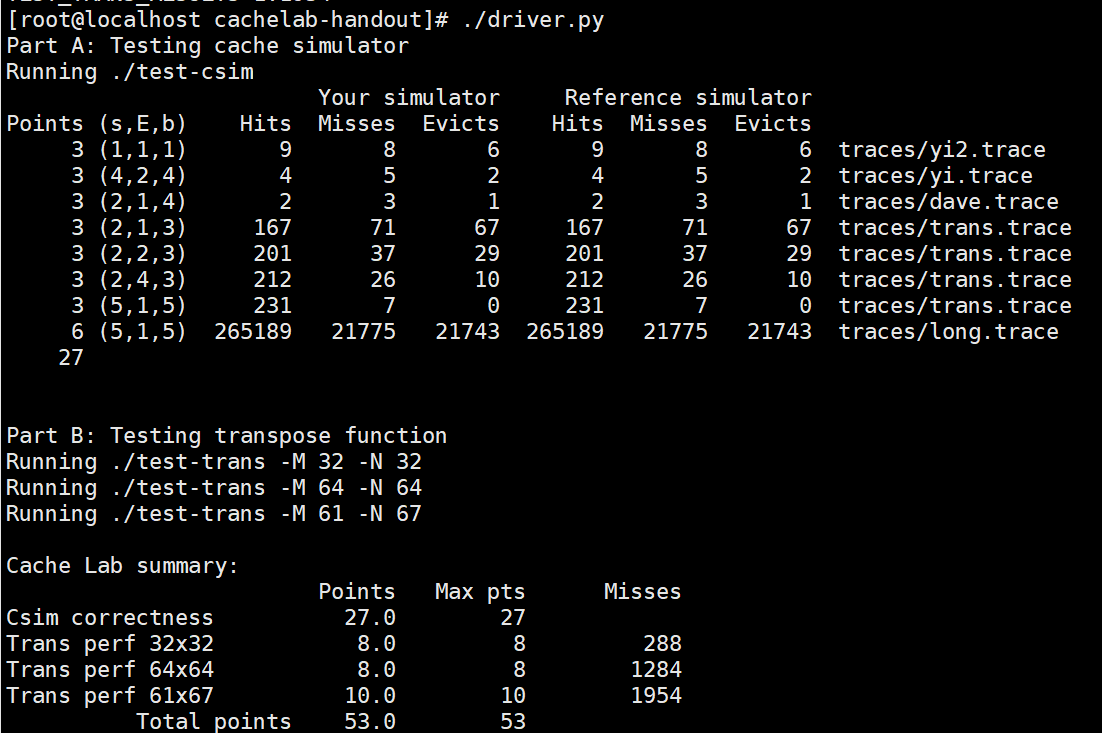
1, partA
partA is relatively simple. It should be noted that the use of LRU and different lines in the same set do not store continuous addresses. Take s = 1, E = 2, b = 1 as an example: the first row of the first set stores 0x2 0xa ···, and the second row stores 0x6 0xd ···.
2, partB 32*32
As mentioned in the manual, the key here is the diagonal conflict.
First, it is not difficult to find that since there are 32 * 32 = 1024 bytes in the cache, conflicts will occur every 1024 / 4 / 32 = 8 rows in the matrix. Therefore, we'd better choose blocksize = 8*8. However, this will cause the blocks of a and B on the diagonal to operate at the same time, resulting in address conflict, that is, A[0][0]-A[7][7] and B[0][0]-B[7][7]... Are in conflict. After observation, we can see that when we load A[0][0], conflicts are triggered due to the need to write B[0][0] (subsequent conflicts are similar). This causes the subsequent reading of A[0][1] to produce a miss. Therefore, we hope to improve the program by changing A[0][0]-A[0][7] to only have A[0][0] miss once. Finally, we chose to use a temporary variable to save the diagonal elements. After reading the row, write the element back to B.
int i, j, ii, jj, tmp, diagonal;
int msize = 8;
int nsize = 8;
for (ii = 0; ii < N; ii += nsize)
{
for (jj = 0; jj < M; jj += msize)
{
if (ii != jj)
{
for (i = ii; i < ii + nsize; i++)
{
for (j = jj; j < jj + msize; j++)
{
tmp = A[i][j];
B[j][i] = tmp;
}
}
continue;
}
for (i = ii; i < ii + nsize; i++)
{
diagonal = A[i][i];
for (j = jj; j < jj + msize; j++)
{
if (i == j)
{
continue;
}
tmp = A[i][j];
B[j][i] = tmp;
}
B[i][i] = diagonal;
}
}
}
Pass II= JJ's judgment to distinguish whether it is a diagonal block.
3, partB 64*64
This part is the most interesting part of the experiment. Similarly, it is not difficult to analyze that every four rows in each matrix will cause a conflict. Therefore, the first thing we think of here is to use 4 * 4 matrix. However, since the block in each set can hold 32 bytes, we need to analyze how to maximize the utilization of the remaining bytes in the cache. If you want to make full use of all bytes, you must consider the 8 * 8 matrix. The following is discussed in two cases:
1. 8 * 8 matrix on diagonal
For such matrices, a and B matrices are loaded into the same buffer, which will conflict with each other. Among them, 1-4 rows of matrix A, 5-8 rows of matrix A, 1-4 rows of matrix B and 5-8 rows of matrix B will all be mapped to the same block. Suppose the serial numbers of these blocks are 1, 9, 17 and 25 respectively. We can divide each 8 * 8 matrix into four 4 * 4 matrices:

Consider area 1 first. If we use the previous diagonal optimization method to access the No. 1 sub matrix in matrix A from left to right and from top to bottom as shown in the following figure:
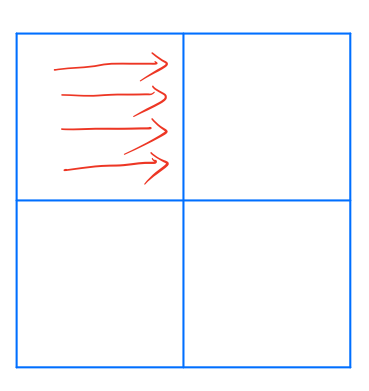
When accessing the first row in the A matrix, the missing hits (ignoring conflicts) should be:
A[0][0] m A[0][1] h B[1][0] m A[0][2] h B[2][0] m A[0][3] h B[3][0] m B[0][0] m
After all four rows are accessed, the block s with the above serial numbers of 1, 9, 17 and 25 should store the data of rows 0-4 of matrix B. This determines which 4 * 4 matrix we should access below. Since columns 5-8 of matrix B have not been accessed, it should correspond to sub matrix 3 of matrix A. Similarly, after transposing matrix 3 of matrix A, rows 0-4 in B are still stored in the cache. But all these data have been used up. Therefore, in this case, there are no special requirements for the access order of the 2,4 matrix.
2. 8 * 8 matrix on non diagonal
For such matrices, a and B matrices are not cached on the same row. However, we can still access in the order of 1 and 3 to optimize the utilization of B matrix cache. However, at this time, we have requirements for the order of 2 and 4 matrices. After accessing matrix 3 in a, rows 5-8 of matrix A are still saved in the cache, while columns 5-8 are not used. Therefore, we can consider giving priority to matrix 4 in matrix A and then matrix 2. The processing sequence thus determined is:

3. Temporary variable cache
In this release, we have improved the problem of diagonal element caching. In the above access process, after processing the sub matrix with sequence number 1 in matrix A, we did not make full use of the cache of matrix A, and its 5-8 columns of data were discarded. Therefore, we can choose to save a total of 8 temporary variables in columns 5-8 in rows 1 and 2, and then we can directly extract data from the temporary variables when processing sub matrix 4.
4. Realize
The following version is the version whose number of temporary variables exceeds the limit, with a total of 15 temporary variables. However, this version can restore the above optimization process. I implement the version that meets the variable requirements by removing j, ii and offset. But the code is hard to read, so it's not posted here.
void transpose_save_diagonal64(int M, int N, int A[N][M], int B[M][N])
{
int i, j, ii, jj, tmp, diagonal, offset, line[8];
for (jj = 0; jj < M; jj += 8)
{
for (ii = 0; ii < N; ii += 8)
{
offset = ii - jj;
for (i = ii; i < ii + 4; i++)
{
diagonal = A[i][i - offset];
for (j = jj; j < jj + 4; j++)
{
if (i == ii)
{
line[j - jj] = A[i][j + 4];
}
if (i == ii + 1)
{
line[j - jj + 4] = A[i][j + 4];
}
if (i - j == offset)
{
continue;
}
tmp = A[i][j];
B[j][i] = tmp;
}
B[i - offset][i] = diagonal;
}
offset = ii - jj + 4;
for (i = ii + 4; i < ii + 4 * 2; i++)
{
diagonal = A[i][i - offset];
for (j = jj; j < jj + 4; j++)
{
if (i - j == offset)
{
continue;
}
tmp = A[i][j];
B[j][i] = tmp;
}
B[i - offset][i] = diagonal;
}
offset = ii - jj;
for (i = ii + 4; i < ii + 8; i++)
{
diagonal = A[i][i - offset];
for (j = jj + 4; j < jj + 8; j++)
{
if (i - j == offset)
{
continue;
}
tmp = A[i][j];
B[j][i] = tmp;
}
B[i - offset][i] = diagonal;
}
offset = ii - jj - 4;
for (i = ii; i < ii + 4; i++)
{
if (i == ii)
{
B[jj + 4][i] = line[0];
B[jj + 5][i] = line[1];
B[jj + 6][i] = line[2];
B[jj + 7][i] = line[3];
continue;
}
if (i == ii + 1)
{
B[jj + 4][i] = line[4];
B[jj + 5][i] = line[5];
B[jj + 6][i] = line[6];
B[jj + 7][i] = line[7];
continue;
}
diagonal = A[i][i - offset];
for (j = jj + 4; j < jj + 8; j++)
{
if (i - j == offset)
{
continue;
}
tmp = A[i][j];
B[j][i] = tmp;
}
B[i - offset][i] = diagonal;
}
}
}
}
4, partB 61*67
This part is relatively simple. Since 32 bytes are saved in the block in each set, we must process 8 columns at a time. However, since the same column elements between two rows of any matrix basically do not conflict, the number of rows processed at one time can be adjusted. It should be noted that since the rows and columns cannot divide our sub matrix rows and columns, the redundant parts need to be handled separately:
void transpose_save_diagonal61(int M, int N, int A[N][M], int B[M][N])
{
int i, j, ii, jj, tmp;
int msize = 8;
int nsize = 16;
for (ii = 0; ii < N; ii += nsize)
{
if (ii == 64)
{
nsize = 3;
}
for (jj = 0; jj < M; jj += msize)
{
if (jj == 56)
{
msize = 5;
}
for (i = ii; i < ii + nsize; i++)
{
for (j = jj; j < jj + msize; j++)
{
tmp = A[i][j];
B[j][i] = tmp;
}
}
}
msize = 8;
}
}
5, Integration and testing
Since the meaning of the question has explained that optimization can be done according to the matrix dimension, we are not polite:
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
if (M == 32 && N == 32)
{
transpose_save_diagonal32(M, N, A, B);
}
else if (M == 64 && N == 64)
{
transpose_save_diagonal64_rm_variable(M, N, A, B);
}
else if (M == 61 && N == 67)
{
transpose_save_diagonal61(M, N, A, B);
}
else
{
int i, j, ii, jj, tmp;
int msize = 8;
int nsize = 8;
// int en = bsize * (N / bsize); /* Amount that fits evenly into blocks */
for (ii = 0; ii < N; ii += nsize)
{
for (jj = 0; jj < M; jj += msize)
{
for (i = ii; i < ii + nsize; i++)
{
for (j = jj; j < jj + msize; j++)
{
tmp = A[i][j];
B[j][i] = tmp;
}
}
}
}
}
}
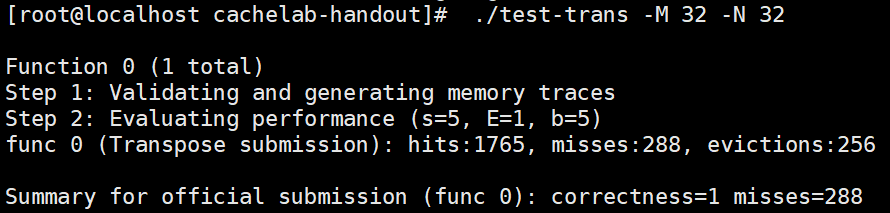
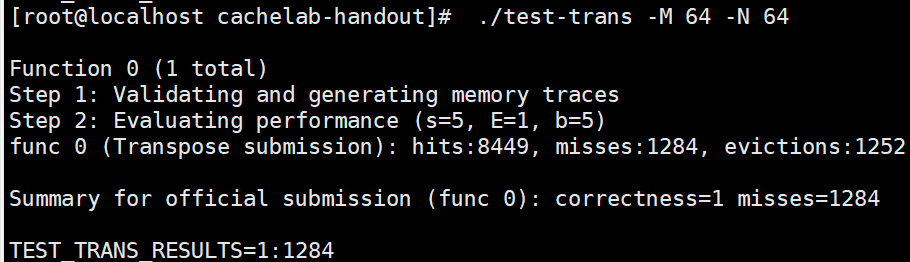
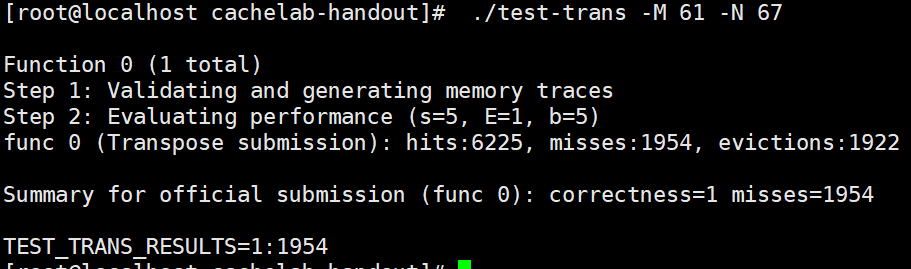
6, Other solutions
The blog I often read when reading this book also provides a solution, which has better performance than mine—— CS:APP3e deep understanding of computer systems_ 3e CacheLab experiment