In-depth Learning Foundation Series: GoogleNet
Introduction to GoogleNet
In 2014, GoogLeNet and VGG were the duo of the ImageNet Challenge (ILSVRC14). GoogLeNet won the first place and VGG the second. The common feature of these two types of model structures is that they have a deeper level.VGG inherits some of LeNet's and AlexNet's frameworks, while GoogLeNet makes bolder attempts to build a network that is much smaller than AlexNet and VGG, although only 22 layers deep. There are 5 million GoogleNet parameters, 12 times as many AlexNet parameters as GoogleNet parameters, and 3 times as many VGNet parameters as AlexNet parameters.Or when computing resources are limited, GoogleNet is a better choice; from the model results, the performance of GoogLeNet is better.
Overview of the GoogleNet Series Network
- InceptionV1, by stacking convolution cores of different sizes such as 1x1,3x3,5x5, increases the network's adaptability to different scales.By adding 1x1 to a 3x3 network and a 5x5 network, the computational complexity of the network is reduced, and the degree of non-linearity of the network is improved, based on stronger representation capabilities.
- InceptionV2, which adds the BatchNormalization layer, reduces the Internal Variance Shift.By making the output distribution of each pass satisfy the specified Gaussian distribution, the mismatch between the distribution of the training set and the test set can be prevented, and the convergence speed of the network can be accelerated and the over-fitting can be prevented.
- Inception V3, in Inception V3 google used the decomposition idea to the extreme, splitting a two-dimensional convolution kernel (NxN) into one-dimensional convolution kernels (Nx1,1xN) in two directions.This not only speeds up the operation of the network, but also increases the non-linearity of the network and improves the characterization ability of the network by increasing the number of layers of the network.
- Inception V4, trying to combine the structure of Inception with that of Resnet, has designed a deeper and better network Inception V4.
Introduction to InceptionV1 module
To understand the structure of Googlenet, the first step must be to know the structure of Inception because it is composed of multiple Inception structures.As shown in Fig.2 below, (a) an inception V1 diagram for a plain version, (b) an Inception V1 diagram for a reduced-dimension version.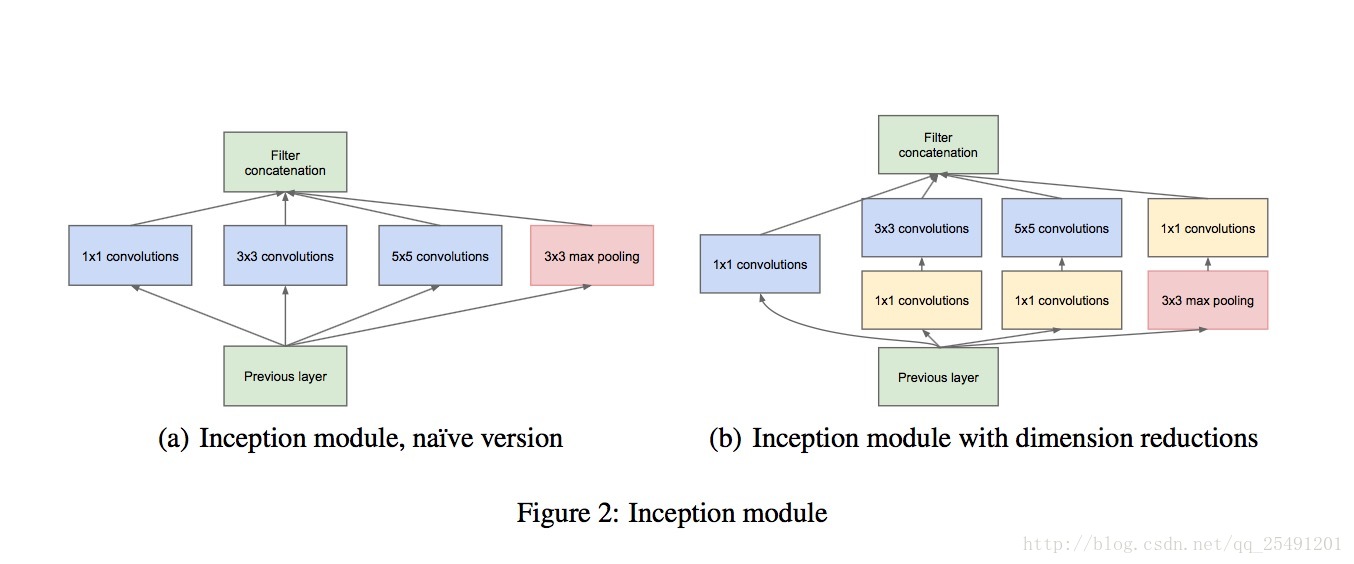
Inception's main idea is based on the idea that local sparse optimal structures within a convolution network can often be approximated or replaced by simple reusable dense combinations.Just like in (a), the convolution layer of 1x1,3x3,5x5, combined with the pooled layer of 3x3, is an inception.Some instructions for doing this:
- Convolution cores of different sizes can extract information at different scales.
- It is easy to align with 1x1,3x3,5x5, padding 0, 1, 2 respectively.
- Due to the successful use of the pooling layer in the CNN network, the pooling layer is also considered as part of the combination.
- Because Googlenet is a stack of several Inception modules, and often the Inception module that follows extracts more advanced Abstract features, the time domain linkage of the advanced abstract features decreases.(To add a little personal understanding here, when the extracted features are relatively simple, such as edges and outlines, it usually only needs to extract a few pixels near a pixel, and then the convolution core is smaller, no problem.But when the extracted features become complex, such as human nose and ear, you may need tens or hundreds of pixels next to a pixel.Of course, the pixels I'm talking about refer to the pixels in the signature map.) So in order to get these advanced information, we need to increase the proportion of 3x3,5x5 large convolution cores in the later Inception modules.
But by doing so, the problem arises again, and if you increase the proportion of large convolution cores, that means the computational complexity is soaring.For this reason, engineers at google have proposed (b) this Inception structure
Architecture of Inception
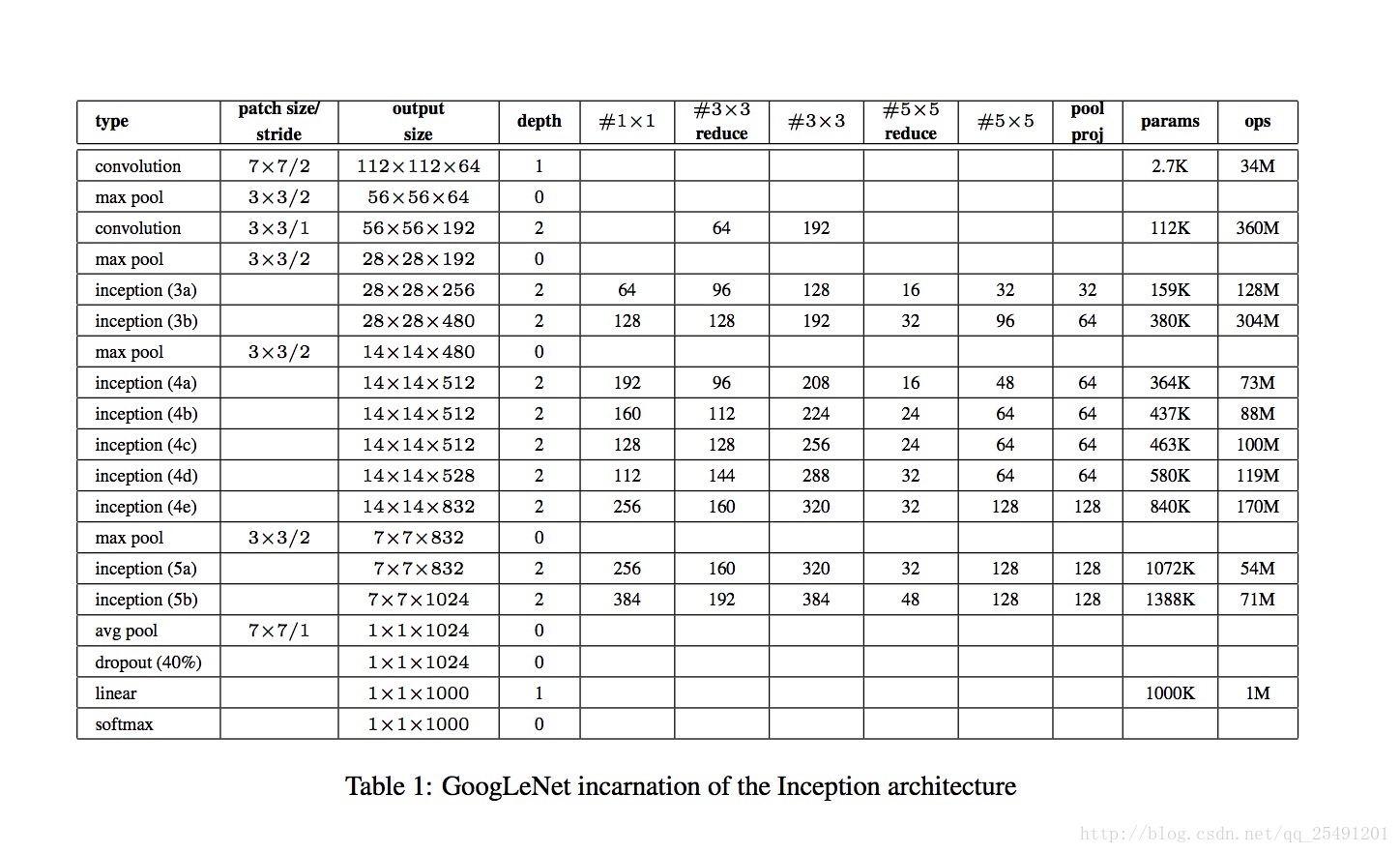
Table.1 below shows how Googlenet consists of an Inception module and some traditional convolution and pooling layers.Comparing Inception(3a) with Inception(5b), we can see that the proportion of filters with large convolution kernels has increased.Finally, two points need to be noted. The network uses avg pool instead of the first full connection layer, which greatly reduces the number of parameters.A full connection layer is added after the avg pool to facilitate fine-tuning.
Keras implementation of GoogLeNet:
def Conv2d_BN(x, nb_filter,kernel_size, padding='same',strides=(1,1),name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation='relu',name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Inception(x,nb_filter):
branch1x1 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(branch3x3,nb_filter,(3,3), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(branch5x5,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branchpool = MaxPooling2D(pool_size=(3,3),strides=(1,1),padding='same')(x)
branchpool = Conv2d_BN(branchpool,nb_filter,(1,1),padding='same',strides=(1,1),name=None)
x = concatenate([branch1x1,branch3x3,branch5x5,branchpool],axis=3)
return x
def GoogLeNet():
inpt = Input(shape=(224,224,3))
#Padding ='same', filled with (step-1)/2, or ZeroPadding 2D ((3,3))
x = Conv2d_BN(inpt,64,(7,7),strides=(2,2),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv2d_BN(x,192,(3,3),strides=(1,1),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,64)#256
x = Inception(x,120)#480
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,128)#512
x = Inception(x,128)
x = Inception(x,128)
x = Inception(x,132)#528
x = Inception(x,208)#832
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,208)
x = Inception(x,256)#1024
x = AveragePooling2D(pool_size=(7,7),strides=(7,7),padding='same')(x)
x = Dropout(0.4)(x)
x = Dense(1000,activation='relu')(x)
x = Dense(1000,activation='softmax')(x)
model = Model(inpt,x,name='inception')
return model