1, Introduction
RocketMQ is Alibaba's open source distributed messaging middleware. It draws on Kafka's implementation and supports functions such as message subscription and publishing, sequential message, transaction message, timing message, message backtracking, dead letter queue and so on. RocketMQ architecture is mainly divided into four parts, as shown in the following figure:
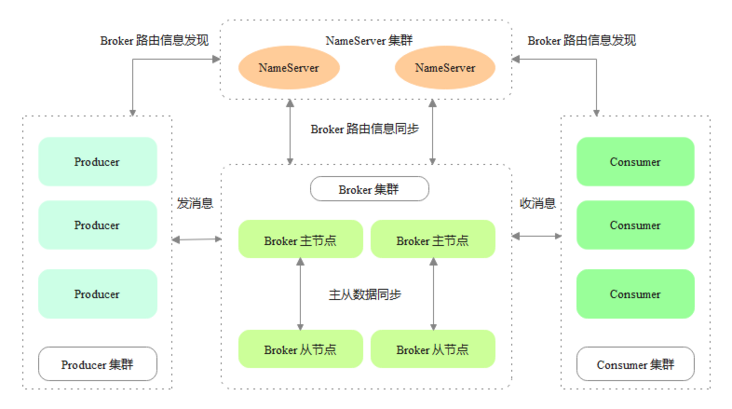
- Producer: Message producer, which supports distributed cluster deployment.
- Consumer: message consumer, which supports distributed cluster deployment.
- NameServer: NameServer is a very simple Topic routing registry, which supports dynamic registration and discovery of brokers. Producer s and consumers dynamically perceive the routing information of brokers through NameServer.
- Broker: broker is mainly responsible for message storage, forwarding and query.
Based on Apache rocketmq version 4.9.1, this paper analyzes how the message storage module in Broker is designed.
2, Storage architecture
The message file path of RocketMQ is shown in the figure.
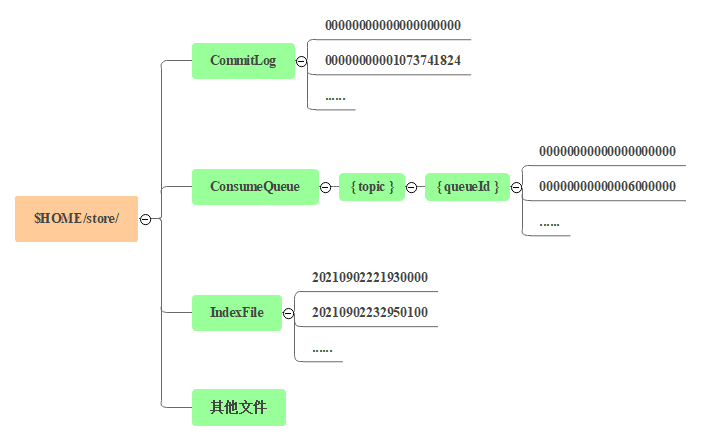
CommitLog
The message body and metadata storage body store the message body content written by the Producer side. The message content is not fixed length. The default size of a single file is 1G, the length of the file name is 20 bits, the left is filled with zero, and the rest is the starting offset. For example, 00000000000000000000 represents the first file, the starting offset is 0, and the file size is 1G=1073741824; When the first file is full, the second file is 0000000000 1073741824, the starting offset is 1073741824, and so on.
ConsumeQueue
For message consumption queue, the ConsumeQueue file can be regarded as an index file based on CommitLog. The ConsumeQueue file adopts a fixed length design. Each entry has a total of 20 bytes, including 8-byte CommitLog physical offset, 4-byte message length and 8-byte tag hashcode. A single file consists of 30W entries. Each entry can be accessed randomly like an array. The size of each ConsumeQueue file is about 5.72M.
IndexFile
The index file provides a method to query messages through key or time interval. The size of a single IndexFile is about 400M. An IndexFile can store 2000W indexes. The underlying storage design of IndexFile is similar to the HashMap data structure of JDK.
Other files: including config folder to store runtime configuration information; abort file, indicating whether the Broker is closed normally; The checkpoint file stores the timestamp of the last disk swiping of Commitlog, ConsumeQueue and Index files. These are beyond the scope of this article.
Compared with Kafka, each partition of each Topic in Kafka corresponds to a file, which is written in sequence and flushed regularly. However, once there are too many topics in a single Broker, sequential writes will degenerate into random writes. All topics of a single RocketMQ Broker are written sequentially in the same CommitLog, which can ensure strict sequential writing. RocketMQ needs to get the actual physical offset of the message from ConsumeQueue before reading the message content from CommitLog, which will cause random reading.
2.1 Page Cache and mmap
Before formally introducing the implementation of Broker message storage module, first explain the two concepts of Page Cache and mmap.
Page Cache is the OS Cache of files, which is used to speed up the reading and writing of files. Generally speaking, the speed of sequential reading and writing of files by the program is almost close to that of memory. The main reason is that the OS uses the page Cache mechanism to optimize the performance of reading and writing access operations, and uses part of the memory as page Cache. For data writing, the OS will write to the Cache first, and then the pdflush kernel thread will brush the data in the Cache to the physical disk asynchronously. For data reading, if the page Cache is missed when reading a file, the OS will pre read the data files of other adjacent blocks while accessing the read file from the physical disk.
mmap maps the physical files on the disk directly to the memory address of the user state, which reduces the performance overhead of traditional IO copying the disk file data back and forth between the buffer of the operating system kernel address space and the buffer of the user application address space. FileChannel in Java NIO provides a map() method to implement mmap. The read-write performance of FileChannel and mmap can be compared by reference This article.
2.2 Broker module
The following figure is the Broker storage architecture diagram, showing the business flow process of the Broker module from receiving a message to returning a response.
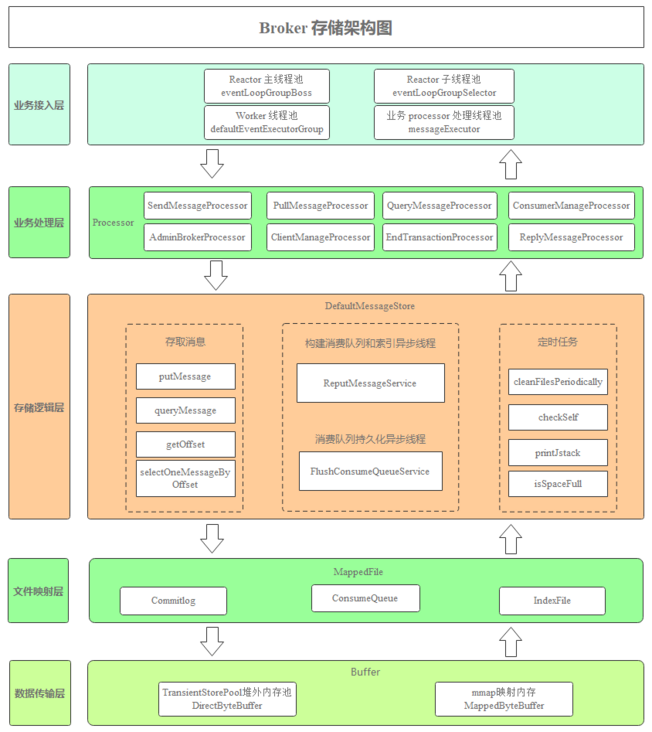
Service access layer: RocketMQ implements the underlying communication based on the Reactor multithreading model of Netty. The Reactor main process pool eventLoopGroupBoss is responsible for creating TCP connections. By default, there is only one thread. After the connection is established, it is sent to the Reactor sub thread pool eventLoopGroupSelector for reading and writing events.
defaultEventExecutorGroup is responsible for SSL authentication, encoding and decoding, idle check and network connection management. Then, according to the business request code of RomotingCommand, find the corresponding processor in the local cache variable processorTable, encapsulate it into a task task, and submit it to the corresponding business processor processing thread pool for execution. The Broker module improves the system throughput through the four level thread pool.
Business processing layer: processes various business requests called through RPC, including:
- SendMessageProcessor is responsible for processing the request of Producer to send messages;
- PullMessageProcessor is responsible for processing the request of Consumer consumption message;
- QueryMessageProcessor is responsible for processing requests to query messages according to message keys.
Storage logic layer: DefaultMessageStore is the core storage logic class of RocketMQ, which provides message storage, reading, deletion and other capabilities.
File mapping layer: map Commitlog, ConsumeQueue and IndexFile files to storage object MappedFile.
Data transport layer: it supports reading and writing messages based on mmap memory mapping, as well as reading and writing messages based on mmap and writing messages to out of heap memory.
The following chapters will analyze how RocketMQ implements high-performance storage from the perspective of source code.
3, Message writing
Taking single message production as an example, the message writing timing logic is shown in the figure below, and the business logic flows between layers as shown in the Broker storage architecture above.
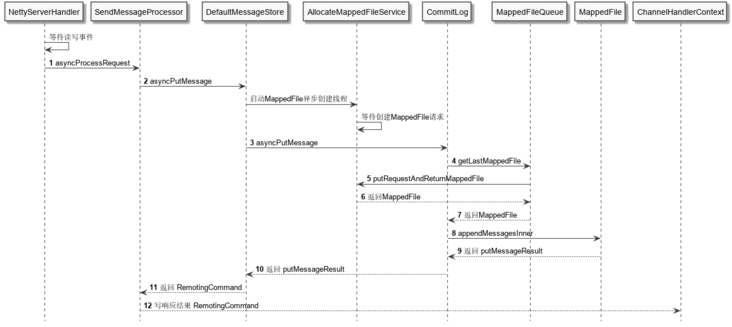
The bottom message is written to the core code. In the asyncPutMessage method of CommitLog, it is mainly divided into three steps: obtaining MappedFile, writing message to buffer and submitting disk flushing request. It should be noted that there are spin locks or ReentrantLock locks before and after these three steps to ensure that the messages written by a single Broker are serial.
//org.apache.rocketmq.store.CommitLog::asyncPutMessage
public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) {
...
putMessageLock.lock(); //spin or ReentrantLock ,depending on store config
try {
//Get the latest MappedFile
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
...
//Write message to buffer
result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext);
...
//Submit disk brushing request
CompletableFuture<PutMessageStatus> flushResultFuture = submitFlushRequest(result, msg);
...
} finally {
putMessageLock.unlock();
}
...
}Here's what these three steps do.
3.1 MappedFile initialization
The AllocateMappedFileService asynchronous thread that manages MappedFile creation is started when the Broker is initialized. The message processing thread and the AllocateMappedFileService thread are associated through the queue requestQueue.
When writing a message, call the putRequestAndReturnMappedFile method of AllocateMappedFileService to put the submit MappedFile creation request into the requestQueue. Here, two allocaterequests will be built and put into the queue at the same time.
The AllocateMappedFileService thread loops to get the AllocateRequest from the requestQueue to create a MappedFile. The message processing thread waits for the first MappedFile to be obtained through CountDownLatch, and returns when the creation is successful.
When the message processing thread needs to create the MappedFile again, it can directly obtain the previously pre created MappedFile. This reduces the waiting time for file creation by pre creating mappedfiles.
//org.apache.rocketmq.store.AllocateMappedFileService::putRequestAndReturnMappedFile
public MappedFile putRequestAndReturnMappedFile(String nextFilePath, String nextNextFilePath, int fileSize) {
//Request to create MappedFile
AllocateRequest nextReq = new AllocateRequest(nextFilePath, fileSize);
boolean nextPutOK = this.requestTable.putIfAbsent(nextFilePath, nextReq) == null;
...
//Request to pre create the next MappedFile
AllocateRequest nextNextReq = new AllocateRequest(nextNextFilePath, fileSize);
boolean nextNextPutOK = this.requestTable.putIfAbsent(nextNextFilePath, nextNextReq) == null;
...
//Get MappedFile created this time
AllocateRequest result = this.requestTable.get(nextFilePath);
...
}
//org.apache.rocketmq.store.AllocateMappedFileService::run
public void run() {
..
while (!this.isStopped() && this.mmapOperation()) {
}
...
}
//org.apache.rocketmq.store.AllocateMappedFileService::mmapOperation
private boolean mmapOperation() {
...
//Get AllocateRequest from queue
req = this.requestQueue.take();
...
//Determine whether to open the off heap memory pool
if (messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
//Open MappedFile of off heap memory
mappedFile = ServiceLoader.load(MappedFile.class).iterator().next();
mappedFile.init(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool());
} else {
//Normal MappedFile
mappedFile = new MappedFile(req.getFilePath(), req.getFileSize());
}
...
//MappedFile preheating
if (mappedFile.getFileSize() >= this.messageStore.getMessageStoreConfig()
.getMappedFileSizeCommitLog()
&&
this.messageStore.getMessageStoreConfig().isWarmMapedFileEnable()) {
mappedFile.warmMappedFile(this.messageStore.getMessageStoreConfig().getFlushDiskType(),
this.messageStore.getMessageStoreConfig().getFlushLeastPagesWhenWarmMapedFile());
}
req.setMappedFile(mappedFile);
...
}Each time a new ordinary MappedFile request is created, a mappedByteBuffer will be created. The following code shows how Java mmap is implemented.
//org.apache.rocketmq.store.MappedFile::init
private void init(final String fileName, final int fileSize) throws IOException {
...
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
...
}If off heap memory is enabled, that is, when transientStorePoolEnable = true, mappedByteBuffer is only used to read messages, and off heap memory is used to write messages, so as to realize the separation of reading and writing messages. The out of heap memory object does not need to be created every time a MappedFile is created, but is initialized according to the size of the out of heap memory pool at system startup. Each out of heap memory DirectByteBuffer has the same size as the CommitLog file. By locking the out of heap memory, it is ensured that it will not be replaced into virtual memory.
//org.apache.rocketmq.store.TransientStorePool
public void init() {
for (int i = 0; i < poolSize; i++) {
//Allocate out of heap memory of the same size as the CommitLog file
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(fileSize);
final long address = ((DirectBuffer) byteBuffer).address();
Pointer pointer = new Pointer(address);
//Lock out of heap memory to ensure that it will not be replaced into virtual memory
LibC.INSTANCE.mlock(pointer, new NativeLong(fileSize));
availableBuffers.offer(byteBuffer);
}
}There is a MappedFile preheating logic in the mmapOperation method above. Why do I need to preheat files? How to preheat files?
Because the mmap mapping only establishes the mapping relationship between the process virtual memory address and the physical memory address, and does not load the Page Cache into memory. When reading and writing data, if the Page Cache is not hit, a page missing interrupt occurs, and the data is reloaded from the disk to memory, which will affect the reading and writing performance. In order to prevent page missing exceptions and prevent the operating system from scheduling related memory pages to the swap space, RocketMQ preheats files as follows.
//org.apache.rocketmq.store.MappedFile::warmMappedFile
public void warmMappedFile(FlushDiskType type, int pages) {
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
int flush = 0;
//The operating system allocates physical memory space by writing 1G byte 0. If there is no fill value, the operating system will not actually allocate physical memory to prevent page missing exceptions when writing messages
for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) {
byteBuffer.put(i, (byte) 0);
// force flush when flush disk type is sync
if (type == FlushDiskType.SYNC_FLUSH) {
if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) {
flush = i;
mappedByteBuffer.force();
}
}
//prevent gc
if (j % 1000 == 0) {
Thread.sleep(0);
}
}
//force flush when prepare load finished
if (type == FlushDiskType.SYNC_FLUSH) {
mappedByteBuffer.force();
}
...
this.mlock();
}
//org.apache.rocketmq.store.MappedFile::mlock
public void mlock() {
final long beginTime = System.currentTimeMillis();
final long address = ((DirectBuffer) (this.mappedByteBuffer)).address();
Pointer pointer = new Pointer(address);
//Lock the Page Cache of the file through the system call mlock to prevent it from being exchanged to the swap space
int ret = LibC.INSTANCE.mlock(pointer, new NativeLong(this.fileSize));
//The system calls madwise to advise the operating system that the file will be accessed in the near future
int ret = LibC.INSTANCE.madvise(pointer, new NativeLong(this.fileSize), LibC.MADV_WILLNEED);
}To sum up, RocketMQ pre creates a file every time to reduce the file creation delay, and avoids the page missing exception during reading and writing through file preheating.
3.2 message writing
3.2.1 write CommitLog
The logical view of each message storage in CommitLog is shown in the following figure. TOTALSIZE is the storage space occupied by the whole message.
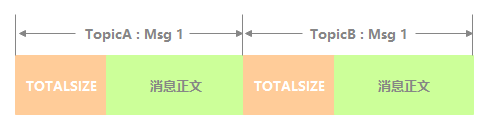
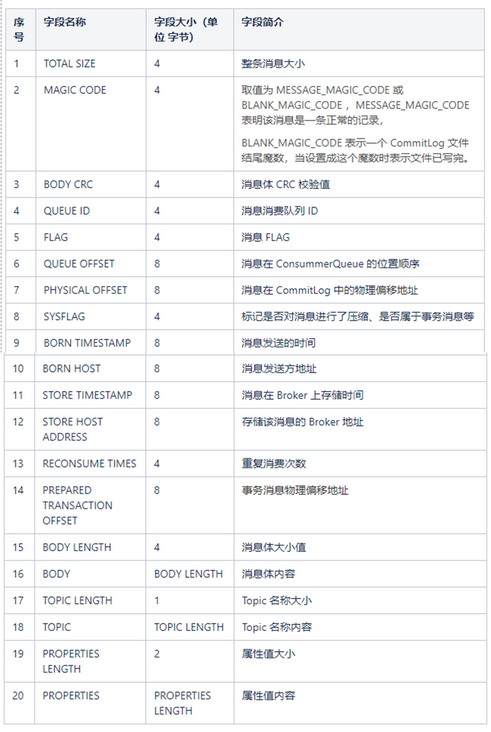
The following table describes which fields are included in each message, as well as the space occupied by these fields and field introduction.
The message is written by calling the appendMessagesInner method of MappedFile.
//org.apache.rocketmq.store.MappedFile::appendMessagesInner
public AppendMessageResult appendMessagesInner(final MessageExt messageExt, final AppendMessageCallback cb,
PutMessageContext putMessageContext) {
//Determine whether to use DirectBuffer or MappedByteBuffer for write operation
ByteBuffer byteBuffer = writeBuffer != null ? writeBuffer.slice() : this.mappedByteBuffer.slice();
..
byteBuffer.position(currentPos);
AppendMessageResult result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos,
(MessageExtBrokerInner) messageExt, putMessageContext);
..
return result;
}
//org.apache.rocketmq.store.CommitLog::doAppend
public AppendMessageResult doAppend(final long fileFromOffset, final ByteBuffer byteBuffer, final int maxBlank,
final MessageExtBrokerInner msgInner, PutMessageContext putMessageContext) {
...
ByteBuffer preEncodeBuffer = msgInner.getEncodedBuff();
...
//The message is only written to the buffer, and the disk has not been actually flushed
byteBuffer.put(preEncodeBuffer);
msgInner.setEncodedBuff(null);
...
return result;
}So far, the message is finally written to ByteBuffer and has not been persisted to disk. When will it be persisted? The next section will talk about the disk brushing mechanism. Here's a question: how are ConsumeQueue and IndexFile written?
The answer is to store the ReputMessageService of the logical layer in the storage architecture diagram. When the MessageStore is initialized, it will start a ReputMessageService asynchronous thread. After it is started, it will continuously call the doReput method in the loop to notify ConsumeQueue and IndexFile to update. The reason why ConsumeQueue and IndexFile can be updated asynchronously is that the CommitLog stores the queue, Topic and other information required to recover ConsumeQueue and IndexFile. Even if the Broker service is abnormally down, the Broker can recover ConsumeQueue and IndexFile according to the CommitLog after restart.
//org.apache.rocketmq.store.DefaultMessageStore.ReputMessageService::run
public void run() {
...
while (!this.isStopped()) {
Thread.sleep(1);
this.doReput();
}
...
}
//org.apache.rocketmq.store.DefaultMessageStore.ReputMessageService::doReput
private void doReput() {
...
//Get new messages stored in CommitLog
DispatchRequest dispatchRequest =
DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false);
int size = dispatchRequest.getBufferSize() == -1 ? dispatchRequest.getMsgSize() : dispatchRequest.getBufferSize();
if (dispatchRequest.isSuccess()) {
if (size > 0) {
//If there is a new message, call commitlogdispatcher buildconsumequeue and commitlogdispatcher buildindex to build consummequeue and IndexFile respectively
DefaultMessageStore.this.doDispatch(dispatchRequest);
}
...
}
3.2.2 write ConsumeQueue
As shown in the figure below, each record of ConsumeQueue has 20 bytes in total, including 8-byte CommitLog physical offset, 4-byte message length and 8-byte tag hashcode.
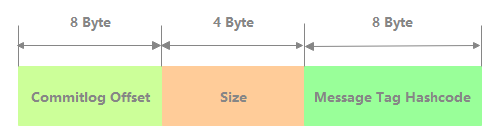
The persistence logic of ConsumeQueue records is as follows.
//org.apache.rocketmq.store.ConsumeQueue::putMessagePositionInfo
private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
final long cqOffset) {
...
this.byteBufferIndex.flip();
this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
this.byteBufferIndex.putLong(offset);
this.byteBufferIndex.putInt(size);
this.byteBufferIndex.putLong(tagsCode);
final long expectLogicOffset = cqOffset * CQ_STORE_UNIT_SIZE;
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile(expectLogicOffset);
if (mappedFile != null) {
...
return mappedFile.appendMessage(this.byteBufferIndex.array());
}
}3.2.3 writing IndexFile
The logical structure of IndexFile is shown in the following figure, which is similar to the array and linked list structure of HashMap in JDK. It is mainly composed of Header, Slot Table and Index Linked List.
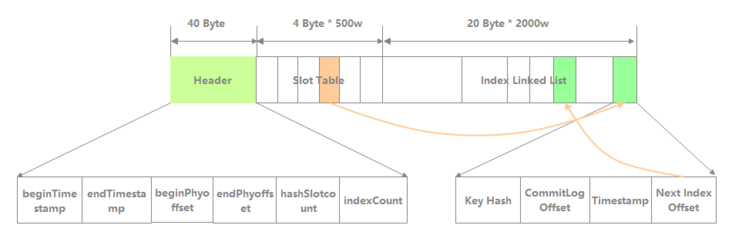
Header: the header of IndexFile, accounting for 40 bytes. It mainly includes the following fields:
- beginTimestamp: the minimum storage time of messages contained in the IndexFile.
- endTimestamp: the maximum storage time of messages contained in the IndexFile file.
- beginPhyoffset: the minimum CommitLog file offset of the message contained in the IndexFile.
- endPhyoffset: the maximum CommitLog file offset of the message contained in the IndexFile file.
- hashSlot count: the total number of hashslots contained in the IndexFile.
- indexCount: the number of Index entries used in the IndexFile.
Slot Table: contains 500w hash slots by default. Each hash slot stores the first IndexItem storage location of the same hash value.
Index Linked List: up to 2000w indexitems by default. Its composition is as follows:
- Key Hash: the hash of the message key. When searching according to the key, the hash is compared, and then the key itself is compared.
- CommitLog Offset: the physical displacement of the message.
- Timestamp: the difference between the message storage time and the timestamp of the first message.
- Next Index Offset: the location of the next IndexItem saved after a hash conflict.
Each hash slot in the Slot Table stores the position of IndexItem in the Index Linked List. In case of hash conflict, the new IndexItem is inserted into the chain header, and its Next Index Offset stores the previous IndexItem position in the chain header. At the same time, the hash slot in the Slot Table is overwritten as the latest IndexItem position. The code is as follows:
//org.apache.rocketmq.store.index.IndexFile::putKey
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
...
//Get the current latest message location from Slot Table
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
...
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
//IndexItem position of chain header before storage
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
//Update the value of the hash slot in the Slot Table to the latest message location
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
if (invalidIndex == slotValue) {
this.indexHeader.incHashSlotCount();
}
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
...
}To sum up, a complete message writing process includes synchronous writing to the Commitlog file cache and asynchronous construction of ConsumeQueue and IndexFile files.
3.3 message disk brushing
RocketMQ message disk brushing mainly includes synchronous disk brushing and asynchronous disk brushing.
(1) Synchronous disk brushing: only after the message is really persisted to the disk, the Broker side of RocketMQ will really return a successful ACK response to the Producer side. Synchronous disk brushing is a good guarantee for the reliability of MQ messages, but it will have a great impact on performance. This mode is widely used in general financial services.
(2) Asynchronous disk brushing: it can take full advantage of the Page Cache of the OS. As long as the message is written to the Page Cache, the successful ACK can be returned to the Producer. Message disk brushing is carried out by background asynchronous thread submission, which reduces the read-write delay and improves the performance and throughput of MQ. Asynchronous disk brushing includes two ways: opening out of heap memory and not opening out of heap memory.
When submitting a disk brushing request in CommitLog, you will decide whether to brush the disk synchronously or asynchronously according to the current Broker configuration.
//org.apache.rocketmq.store.CommitLog::submitFlushRequest
public CompletableFuture<PutMessageStatus> submitFlushRequest(AppendMessageResult result, MessageExt messageExt) {
//Synchronous brush disc
if (FlushDiskType.SYNC_FLUSH == this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
final GroupCommitService service = (GroupCommitService) this.flushCommitLogService;
if (messageExt.isWaitStoreMsgOK()) {
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes(),
this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
service.putRequest(request);
return request.future();
} else {
service.wakeup();
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}
//Asynchronous brush disk
else {
if (!this.defaultMessageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
flushCommitLogService.wakeup();
} else {
//Enable asynchronous disk flushing of off heap memory
commitLogService.wakeup();
}
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}The inheritance relationship of GroupCommitService, FlushRealTimeService and CommitRealTimeService is shown in the figure;
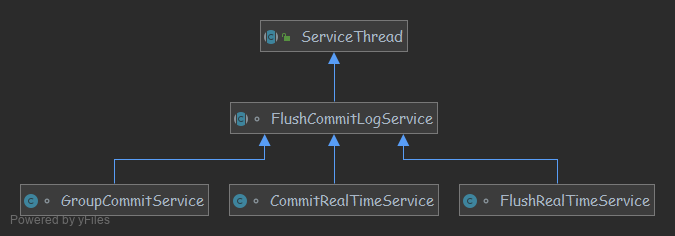
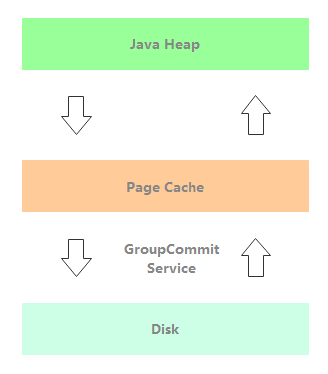
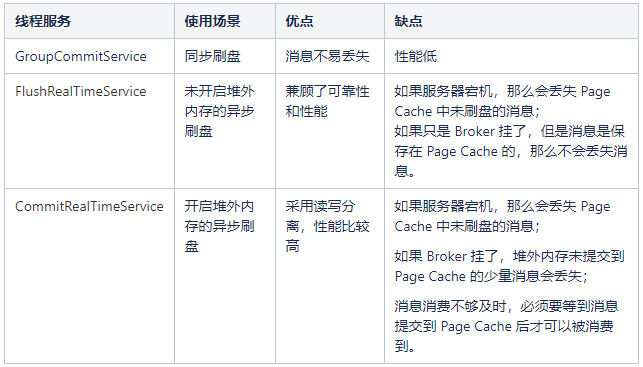
GroupCommitService: synchronize the disk brushing thread. As shown in the following figure, after the message is written to the Page Cache, the disk flushing is synchronized through GroupCommitService, and the message processing thread is blocked waiting for the disk flushing result.
//org.apache.rocketmq.store.CommitLog.GroupCommitService::run
public void run() {
...
while (!this.isStopped()) {
this.waitForRunning(10);
this.doCommit();
}
...
}
//org.apache.rocketmq.store.CommitLog.GroupCommitService::doCommit
private void doCommit() {
...
for (GroupCommitRequest req : this.requestsRead) {
boolean flushOK = CommitLog.this.mappedFileQueue.getFlushedWhere() >= req.getNextOffset();
for (int i = 0; i < 2 && !flushOK; i++) {
CommitLog.this.mappedFileQueue.flush(0);
flushOK = CommitLog.this.mappedFileQueue.getFlushedWhere() >= req.getNextOffset();
}
//Wake up the message processing thread waiting for the completion of disk brushing
req.wakeupCustomer(flushOK ? PutMessageStatus.PUT_OK : PutMessageStatus.FLUSH_DISK_TIMEOUT);
}
...
}
//org.apache.rocketmq.store.MappedFile::flush
public int flush(final int flushLeastPages) {
if (this.isAbleToFlush(flushLeastPages)) {
...
//When writeBuffer is used or the position of fileChannel is not 0, fileChannel is used for forced disk flushing
if (writeBuffer != null || this.fileChannel.position() != 0) {
this.fileChannel.force(false);
} else {
//Forced disk brushing using MappedByteBuffer
this.mappedByteBuffer.force();
}
...
}
}FlushRealTimeService: asynchronous disk flushing thread of out of heap memory is not enabled. As shown in the following figure, after the message is written to the Page Cache, the message processing thread immediately returns and asynchronously swipes the disk through the FlushRealTimeService.
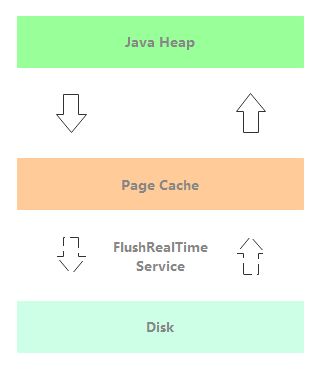
//org.apache.rocketmq.store.CommitLog.FlushRealTimeService
public void run() {
...
//Judge whether it is necessary to brush the disc periodically
if (flushCommitLogTimed) {
//Fixed sleep interval
Thread.sleep(interval);
} else {
// If awakened, brush the disc, non periodic brush the disc
this.waitForRunning(interval);
}
...
// The same forced disk brushing method is used here as GroupCommitService
CommitLog.this.mappedFileQueue.flush(flushPhysicQueueLeastPages);
...
}CommitRealTimeService: start the asynchronous disk flushing thread of off heap memory. As shown in the figure below, the message processing thread returns immediately after writing the message to the off heap memory. Subsequently, the message is asynchronously submitted to the Page Cache from the out of heap memory through CommitRealTimeService, and then the FlushRealTimeService thread brushes the disk asynchronously.
Note: after the message is asynchronously submitted to the Page Cache, the business can read the message from the MappedByteBuffer.
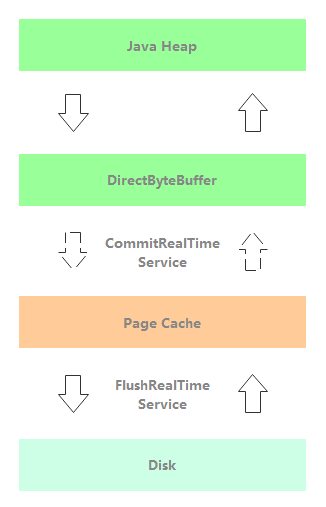
After the message is written to the writeBuffer in the out of heap memory, the isAbleToCommit method will be used to determine whether it has accumulated to at least the number of committed pages (4 pages by default). If the number of pages reaches the minimum number of submitted pages, batch submission is required; Otherwise, it still resides in off heap memory, and there is a risk of message loss. Through this batch operation, the read and write Page Cahe will be separated by several pages, which reduces the probability of Page Cahe read-write conflict and realizes the separation of read and write. The specific implementation logic is as follows:
//org.apache.rocketmq.store.CommitLog.CommitRealTimeService
class CommitRealTimeService extends FlushCommitLogService {
@Override
public void run() {
while (!this.isStopped()) {
...
int commitDataLeastPages = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getCommitCommitLogLeastPages();
...
//Commit the message to the memory buffer, and finally call the MappedFile::commit0 method. Only when the minimum number of submitted pages is reached can the message be submitted successfully, otherwise it is still in the memory outside the heap
boolean result = CommitLog.this.mappedFileQueue.commit(commitDataLeastPages);
if (!result) {
//Wake up the flushCommitLogService to force disk brushing
flushCommitLogService.wakeup();
}
...
this.waitForRunning(interval);
}
}
}
//org.apache.rocketmq.store.MappedFile::commit0
protected void commit0() {
int writePos = this.wrotePosition.get();
int lastCommittedPosition = this.committedPosition.get();
//The message is submitted to the Page Cache without actually flushing the disk
if (writePos - lastCommittedPosition > 0) {
ByteBuffer byteBuffer = writeBuffer.slice();
byteBuffer.position(lastCommittedPosition);
byteBuffer.limit(writePos);
this.fileChannel.position(lastCommittedPosition);
this.fileChannel.write(byteBuffer);
this.committedPosition.set(writePos);
}
}The following summarizes the use scenarios, advantages and disadvantages of the three disk brushing mechanisms.
4, Message reading
The message reading logic is much simpler than the writing logic. The following focuses on how to query messages according to offset and key.
4.1 query by offset
The process of reading a message is to first find the physical offset address of the message in the CommitLog from the ConsumeQueue, and then read the entity content of the message from the CommitLog file.
//org.apache.rocketmq.store.DefaultMessageStore::getMessage
public GetMessageResult getMessage(final String group, final String topic, final int queueId, final long offset,
final int maxMsgNums,
final MessageFilter messageFilter) {
long nextBeginOffset = offset;
GetMessageResult getResult = new GetMessageResult();
final long maxOffsetPy = this.commitLog.getMaxOffset();
//Find the corresponding ConsumeQueue
ConsumeQueue consumeQueue = findConsumeQueue(topic, queueId);
...
//Find the MappedFile of the corresponding ConsumeQueue according to offset
SelectMappedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset);
status = GetMessageStatus.NO_MATCHED_MESSAGE;
long maxPhyOffsetPulling = 0;
int i = 0;
//The maximum information size that can be returned cannot be greater than 16M
final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
//CommitLog physical address
long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
maxPhyOffsetPulling = offsetPy;
...
//Get the specific Message from CommitLog according to offset and size
SelectMappedBufferResult selectResult = this.commitLog.getMessage(offsetPy, sizePy);
...
//Put Message into result set
getResult.addMessage(selectResult);
status = GetMessageStatus.FOUND;
}
//Update offset
nextBeginOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
long diff = maxOffsetPy - maxPhyOffsetPulling;
long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE
* (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0));
getResult.setSuggestPullingFromSlave(diff > memory);
...
getResult.setStatus(status);
getResult.setNextBeginOffset(nextBeginOffset);
return getResult;
}4.2 query by key
The process of reading a message is to find a record in the IndexFile index file with topic and key, and read the entity content of the message from the CommitLog file according to the offset of the CommitLog in the record.
//org.apache.rocketmq.store.DefaultMessageStore::queryMessage
public QueryMessageResult queryMessage(String topic, String key, int maxNum, long begin, long end) {
QueryMessageResult queryMessageResult = new QueryMessageResult();
long lastQueryMsgTime = end;
for (int i = 0; i < 3; i++) {
//Gets the physical offset address of the message recorded in the IndexFile index file in the CommitLog file
QueryOffsetResult queryOffsetResult = this.indexService.queryOffset(topic, key, maxNum, begin, lastQueryMsgTime);
...
for (int m = 0; m < queryOffsetResult.getPhyOffsets().size(); m++) {
long offset = queryOffsetResult.getPhyOffsets().get(m);
...
MessageExt msg = this.lookMessageByOffset(offset);
if (0 == m) {
lastQueryMsgTime = msg.getStoreTimestamp();
}
...
//Get the message content in the CommitLog file
SelectMappedBufferResult result = this.commitLog.getData(offset, false);
...
queryMessageResult.addMessage(result);
...
}
}
return queryMessageResult;
}In the IndexFile index file, find the physical offset address of the CommitLog file. The implementation is as follows:
//org.apache.rocketmq.store.index.IndexFile::selectPhyOffset
public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum,
final long begin, final long end, boolean lock) {
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
//Get the first IndexItme storage location of the same hash value key, that is, the first node of the linked list
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
//Traverse linked list nodes
for (int nextIndexToRead = slotValue; ; ) {
if (phyOffsets.size() >= maxNum) {
break;
}
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
if (timeDiff < 0) {
break;
}
timeDiff *= 1000L;
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
//Add phyOffsets to the qualified results
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
//Continue to traverse the linked list
nextIndexToRead = prevIndexRead;
}
...
}5, Summary
This paper introduces the core module implementation of RocketMQ storage system from the perspective of source code, including storage architecture, message writing and message reading.
RocketMQ writes all the messages under the Topic into the CommitLog, realizing strict sequential writing. Prevent the Page Cache from being swapped to the swap space through file preheating, so as to reduce the interruption of missing pages when reading and writing files. Use mmap to read and write the CommitLog file, and convert the operation on the file into direct operation on the memory address, which greatly improves the reading and writing efficiency of the file.
For scenarios with high performance requirements and low data consistency requirements, you can enable off heap memory to realize read-write separation and improve disk throughput. In short, the learning of storage modules requires a certain understanding of the principles of the operating system. The extreme performance optimization scheme adopted by the author is worthy of our good study.
6, References
Author: vivo Internet server team - Zhang Zhenglin