1, The core of Git
- Git is a content addressed file system. It sounds cool, but what does that mean? This means that the core part of Git is a simple key value data store, which can insert any type of content into git warehouse, and it will return a unique key, through which the content can be retrieved again at any time.
- The above effect can be demonstrated by the underlying command git hash object, which can save any data in the. git/objects directory (i.e. object database) and return a unique key to the data object.
- First, you need to initialize a new Git version library and confirm that the objects directory is empty:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
- You can see that Git initializes the objects directory and creates the pack and info subdirectories, but both are empty.
- Next, create a new data object with Git hash object and manually store it in the new Git database:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
- In this simplest form, Git hash object will accept what we pass to it, and it will only return a unique key that can be stored in the Git repository- The w option instructs the command not only to return the key, but also to write the object to the database. Finally, the – stdin option instructs the command to read content from standard input; If this option is not specified, the path of the file to be stored must be given at the end of the command.
- This command outputs a checksum with a length of 40 characters, which is a SHA-1 hash value and a checksum obtained by performing SHA-1 verification operation with the data to be stored plus a header. Now you can see how Git stores data:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
- If you view the objects directory again, you can find a file corresponding to the new content, which is the way Git stores the content at the beginning. A file corresponds to a piece of content. The file is named with the SHA-1 checksum of the content plus the specific header information. The first two characters of the checksum are used to name the subdirectory, The remaining 38 characters are used as the file name.
- Once the content is stored in the object database, you can retrieve the data from Git through the cat file command. This command is like a Swiss Army knife for analyzing Git objects. Specifying the - p option for cat file can instruct the command to automatically judge the type of content and display the general content for us:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
- At this point, you have mastered how to store content into Git and how to remove it. Similarly, you can apply these operations to the contents of a file. For example, you can perform simple version control on a file. First, create a new file and store its contents in the database:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
- Then, write new content to the file and store it in the database again:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
- The object database records two different versions of the file. Of course, the first content we saved before is still:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
- Now you can delete the local copy of test.txt and use Git to retrieve its first version from the object database:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2
- However, it is unrealistic to remember the SHA-1 value corresponding to each version of the file; Another problem is that in this (simple version control) system, the file name is not saved, only the contents of the file are saved. The above types of objects are called blob object s. Using the Git cat file - t command, Git can tell us any object type stored internally, as long as the SHA-1 value of the object is given:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
2, Tree object
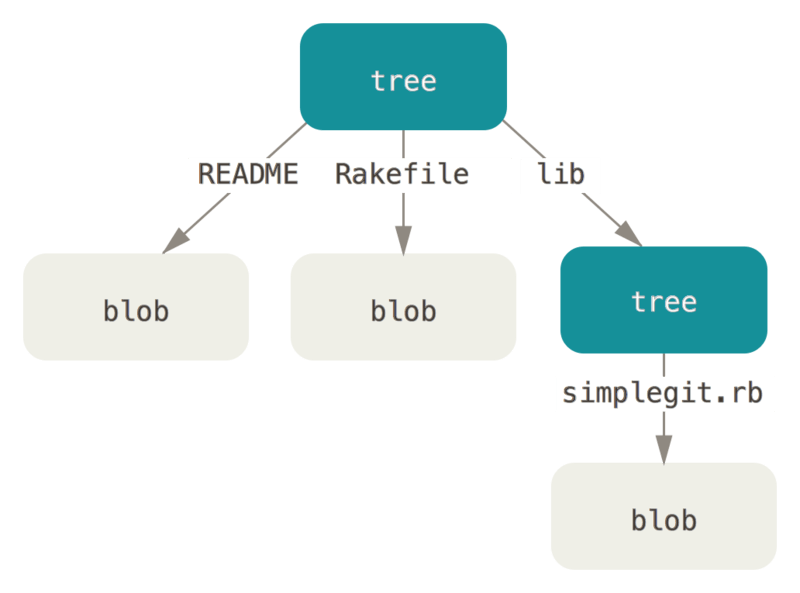
- The GIT object type discussed next is tree object, which can solve the problem of saving file names and allow us to organize multiple files together. Git stores content in a way similar to UNIX file system, but with some simplification, all content is stored in the form of tree objects and data objects, in which tree objects correspond to directory entries in UNIX and data objects roughly correspond to inodes or file contents. A tree object contains one or more tree entries. Each record contains a SHA-1 pointer to the data object or subtree object, as well as the corresponding mode, type and file name information. For example, the latest tree object currently corresponding to an item may be as follows:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
- The master^{tree} syntax indicates the tree object pointed to by the latest Submission on the master branch. However, note that the lib subdirectory (the corresponding tree object record) is not a data object, but a pointer, which points to another tree object:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
- You may encounter errors when using master^{tree} syntax in some shell s:
-
- In CMD of Windows, the character ^ is used for escape, so it must be double written to avoid problems: git cat file - P master^{tree}. When using the character {} in PowerShell, it must be enclosed in quotation marks to avoid parameter parsing errors: git cat file - p 'master^{tree}'.
-
- In ZSH, the character ^ is used in globbing, so the entire expression must be enclosed in quotation marks: git cat file - P "master^{tree}".
- Conceptually, the data stored inside Git is a bit like this:
- You can easily create your own tree objects. Usually, Git creates and records a corresponding tree object according to the state represented by the temporary storage area (i.e. index area, the same below) at a certain time. In this way, you can record a series of tree objects in turn (within a certain time period). Therefore, to create a tree object, you first need to create a staging area by staging some files. You can create a temporary storage area through the underlying command Git update index as a separate file, the first version of our test.txt file. With this command, you can artificially add the first version of the test.txt file to a new temporary storage area. You must specify the -- add option for the above command, because the file was not in the temporary storage area before (you haven't even had time to create a temporary storage area); The -- cacheinfo option is also required, because the file to be added is located in the Git database, not in the current directory. At the same time, you need to specify the file mode, SHA-1 and file name:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
- In this example, the specified file mode is 100644, indicating that this is a common file. Other options include: 100755, indicating an executable file; 120000 represents a symbolic link. The file mode here refers to the common UNIX file mode, but it is far from flexible. The above three modes are all legal modes of Git files (i.e. data objects) (of course, there are other modes, but they are used for directory items and sub modules).
- Now, you can write the contents of the staging area to a tree object through the GIT write tree command. There is no need to specify the - w option here. If a tree object does not exist before, when you call this command, it will automatically create a new tree object according to the current staging area status:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
- Use the GIT cat file command you've seen before to verify that it is indeed a tree object:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
- Next, create a new tree object, including the second version of test.txt file and a new file:
$ echo 'new file' > new.txt
$ git update-index --add --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txt
- The staging area now contains a new version of the test.txt file and a new file: new.txt. Record the directory tree (record the status of the current staging area as a tree object), and then observe its structure:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
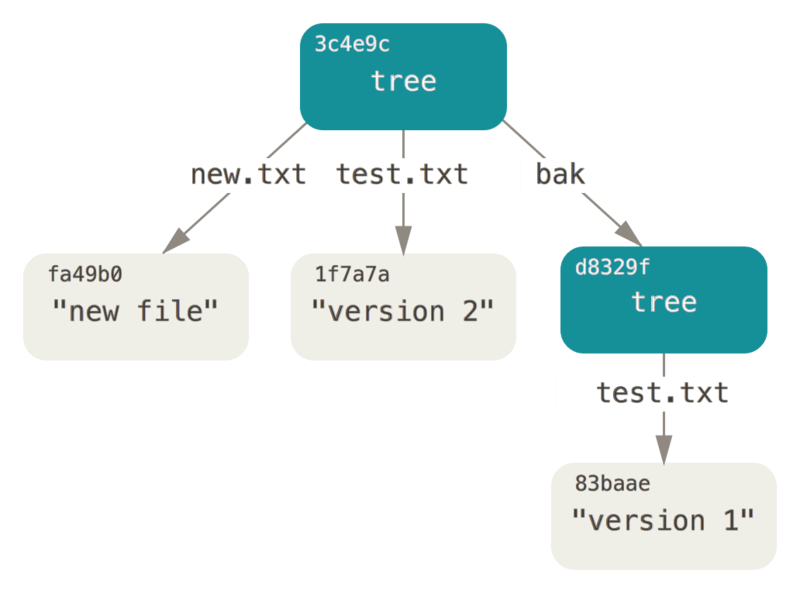
- Note that the new tree object contains two file records, and the SHA-1 value (1f7a7a) of test.txt is the "second version" of the previous value. You can add the first tree object to the second tree object to make it a subdirectory of the new tree object. You can read the tree object into the temporary storage area by calling git read tree command. In this example, you can read an existing tree object into the staging area as a subtree by specifying the -- prefix option on the command:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
- If you create a working directory based on this new tree object, you can find that the root directory of the working directory contains two files and a subdirectory named bak, which contains the first version of the test.txt file. It can be considered that the data used to represent the above structure stored in Git is as follows:
3, Submit object
- If all the above operations are completed, there are now three tree objects representing different project snapshots that we want to track. However, the problem remains: if you want to reuse these snapshots, you must remember all three SHA-1 hash values. And I don't know who saved these snapshots, at what time, and why. These are the basic information that a commit object can save.
- You can create a submission object by calling the commit tree command. To do this, you need to specify the SHA-1 value of a tree object and the submitted parent submission object (if any), starting from the first tree object created earlier:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
- Because the creation time is different from the author data, you will get a different hash value. Now you can view the new submission object through the GIT cat file command:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
- The format of submission object is very simple: it first specifies a top-level tree object to represent the snapshot of the current project; Then there is the possible parent submission (the submission object described above does not have any parent submission); Then the author / submitter information (set according to the user.name and user.email configuration, plus a timestamp); Leave a blank line and finally submit comments.
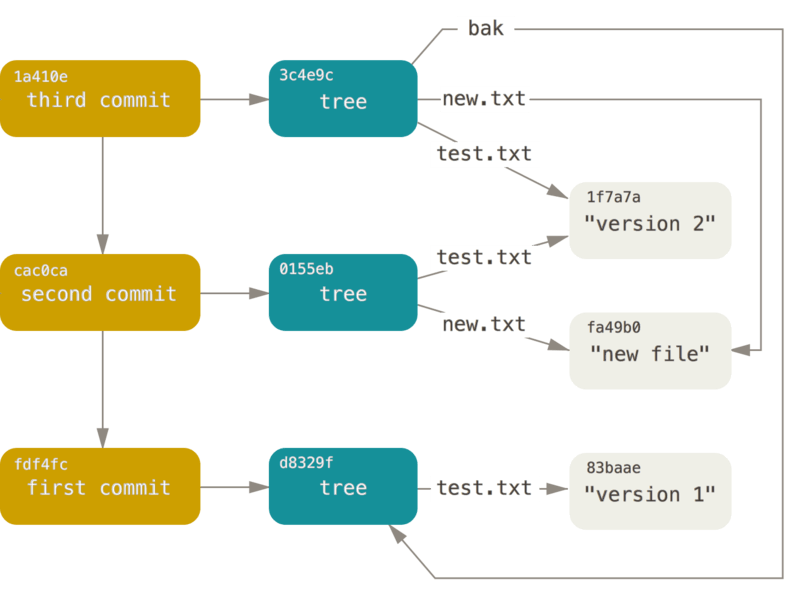
- Next, two other submission objects will be created, each referring to their previous submission (as its parent submission object):
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
- The three commit objects point to one of the three tree object snapshots created earlier. Now, if you run the git log command on the SHA-1 value of the last submission, you will be surprised to find that there is a real Git submission history that can be viewed by git log:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)
- It's amazing: just now, a git submission history was created without the help of any upper-level commands. This is what git does every time git add and git commit commands are run. The essence of GIT's work is to save the rewritten file as a data object, update the temporary storage area and record the tree object, Finally, create a submission object that indicates the top-level tree object and the parent submission. The three main git objects - data object, tree object and submission object are initially saved in the. git/objects directory in the form of separate files. All objects in the current example directory are listed below, supplemented by comments on their saved contents:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
- If you trace all internal pointers, you will get an object relationship diagram similar to the following:
4, Object storage
- As mentioned above, all objects submitted to the Git repository will have a header information saved together. Let's take a moment to see how Git stores its objects. Through an interactive demonstration in the Ruby scripting language, we will see a data object. In this example, the string "what is up, doc?" is stored?
- You can start the interaction mode of Ruby through the irb command:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
- Git will first construct a header information starting with the recognized object type. In this case, it is a "blob" string. Then git will add a space in the first part of the header, followed by the number of bytes of the data content, and finally a null byte:
>> header = "blob #{content.length}\0"
=> "blob 16\u0000"
- Git will splice the above header information with the original data and calculate the SHA-1 checksum of the new content. In Ruby, you can calculate the SHA-1 value in this way. First import the SHA-1 digest library through the require command, and then call Digest::SHA1.hexdigest() on the target string:
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
- Let's compare the output of GIT hash object. echo -n is used here to avoid adding line breaks to the output.
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37
- Git will compress this new content through zlib. You can do this in Ruby with the help of zlib library. First import the corresponding library, and then call Zlib::Deflate.deflate() on the target content:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"
- Finally, you need to write this zlib compressed content to an object on the disk. First determine the path of the object to be written (the first two characters of SHA-1 value are used as the subdirectory name, and the last 38 characters are used as the file name in the subdirectory). If the subdirectory does not exist, you can use fileutils.mkdir in Ruby_ P () function to create it; Then, open the file through File.open(); Finally, call the write() function on the file handle obtained in the previous step to write the previous zlib compressed content to the target file:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
- Use git cat file to view the contents of this object:
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---
- That's it. A valid Git data object has been created.
- All Git objects are stored in this way. The only difference is the type identification. The header information of the other two object types starts with the string "commit" or "tree", not "blob". In addition, although the contents of data objects can be almost anything, the contents of submission objects and tree objects have their own fixed formats.