Simulate a story, randomly find a few beautiful pictures from Baidu pictures, download them, save them locally, and download them in order first
1 sequential synchronous Download
import random
import time
import requests
urls = [
"https://t7.baidu.com/it/u=3676218341,3686214618&fm=193&f=GIF",
"https://t7.baidu.com/it/u=3930750564,2979238085&fm=193&f=GIF",
"https://pics7.baidu.com/feed/c8ea15ce36d3d5398b62865e47680d55372ab0c1.jpeg?token=43cb8aff8adfd6c74ec99218af7a3aad&s=FD36AD570CBC56949920F8E803003021",
"https://pics4.baidu.com/feed/00e93901213fb80ea99ee55b212dcb28bb3894f6.jpeg?token=910769ca2750ca2900cb28542616f7c2",
"https://gimg2.baidu.com/image_search/src=http%3A%2F%2Finews.gtimg.com%2Fnewsapp_match%2F0%2F11158692545%2F0.jpg&refer=http%3A%2F%2Finews.gtimg.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1638945903&t=ab53b7ec3f91652eacf7499b1a4ff529"
]
def use_time(func):
def inner(*args, **kwargs):
s = time.time()
func(*args, **kwargs)
print(f"Total consumption{time.time()-s}s")
return inner
def download(url):
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
resp = requests.get(url, headers=headers)
return resp.content
def sava(content):
with open(f'{random.randint(0,100)}.jpg','wb') as f:
f.write(content)
@use_time
def main():
for url in urls:
resp = download(url)
sava(resp)
if __name__ == '__main__':
main()
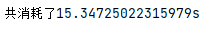
The sequential download took about 15s
2 concurrent.futures concurrent Download
map function
from concurrent.futures import ThreadPoolExecutor
from test4 import download, sava, urls, use_time
MAX_WORKER = 10
@use_time
def cmain():
resp = ThreadPoolExecutor(max_workers=min(len(urls), MAX_WORKER)).map(
download, urls
)
for _ in resp:
sava(_)
if __name__ == '__main__':
cmain()
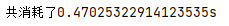
It's about 30 times faster. This is only the concurrency of small tasks. If the task is large enough, the efficiency can be imagined.
The map method is similar to the built-in map method. The return value is a generator that contains the return values of all parameter lists.
The return value of map is an iterator containing the Future object__ next__ Method calls the result method of each Future object, so we get the results of each Future, not the Future itself.
submit function
import random
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
urls = [
"https://t7.baidu.com/it/u=3676218341,3686214618&fm=193&f=GIF",
"https://t7.baidu.com/it/u=3930750564,2979238085&fm=193&f=GIF",
"https://pics7.baidu.com/feed/c8ea15ce36d3d5398b62865e47680d55372ab0c1.jpeg?token=43cb8aff8adfd6c74ec99218af7a3aad&s=FD36AD570CBC56949920F8E803003021",
"https://pics4.baidu.com/feed/00e93901213fb80ea99ee55b212dcb28bb3894f6.jpeg?token=910769ca2750ca2900cb28542616f7c2",
"https://gimg2.baidu.com/image_search/src=http%3A%2F%2Finews.gtimg.com%2Fnewsapp_match%2F0%2F11158692545%2F0.jpg&refer=http%3A%2F%2Finews.gtimg.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1638945903&t=ab53b7ec3f91652eacf7499b1a4ff529"
]
def use_time(func):
def inner(*args, **kwargs):
s = time.time()
func(*args, **kwargs)
print(f"Total consumption{time.time()-s}s")
return inner
def download(url):
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
resp = requests.get(url, headers=headers)
return resp.content
def sava(content):
with open(f'{random.randint(0,100)}.jpg','wb') as f:
f.write(content)
@use_time
def main():
fu_list = []
with ThreadPoolExecutor(3) as the:
for url in urls:
fu = the.submit(download, url)
print(f"url-{url}->fu-{fu}")
fu_list.append(fu)
for fu in as_completed(fu_list):
print(f"state:{fu}")
resp = fu.result()
sava(resp)
if __name__ == '__main__':
main()
url-https://t7.baidu.com/it/u=3676218341,368621461 ->fu-<Future at 0x21a64dc6550 state=running> url-https://t7.baidu.com/it/u=3930750564,2979238085->fu-<Future at 0x21a64dd6d00 state=running> url-https://pics7.baidu.com/feed/c8ea15ce36d3d5398b->fu-<Future at 0x21a64de0910 state=running> url-https://pics4.baidu.com/feed/00e93901213fb80ea9->fu-<Future at 0x21a64ded310 state=pending> url-https://gimg2.baidu.com/image_search/src=http%3->fu-<Future at 0x21a64dedac0 state=pending> state:<Future at 0x21a64dc6550 state=finished returned bytes> state:<Future at 0x21a64dd6d00 state=finished returned bytes> state:<Future at 0x21a64de0910 state=finished returned bytes> state:<Future at 0x21a64dedac0 state=finished returned bytes> state:<Future at 0x21a64ded310 state=finished returned bytes> 0 consumed in total.7982451915740967s
The result of using two for loops is actually the same as that of the map. The only difference is that the map result and parameters cannot be one-to-one corresponding. They can be one-to-one corresponding through the submit function and the Future object.
executor.submit and futures.as_ The combination of completed is more flexible than executor.map, because the submit method can handle different callable objects and parameters, while executor.map can only handle the same callable object with different parameters. In addition, pass it to futures.as_ The Future collection of the completed function can come from multiple executor instances, such as some created by ThreadPoolExecutor instances and others created by ProcessPoolExecutor instances.
3 GIL, multi-core CPU and process pool
All blocking I/O functions in the Python standard library release the GIL and allow other threads to run. The time.sleep() function also frees the GIL. Therefore, despite GIL, Python threads can play a role in I/O-Intensive applications.
If you want to use multi-core, please move to multi-process. concurrent.futures also provides process pool to support multi-process
The concurrent.futures module implements true parallel computing because it uses the ProcessPoolExecutor class to distribute work to multiple Python processes. Therefore, if CPU intensive processing is required, using this module can bypass GIL and use all available CPU cores.
import os
from concurrent.futures import ProcessPoolExecutor
from test4 import download, sava, urls, use_time
@use_time
def cmain():
# resp = ThreadPoolExecutor(max_workers=min(len(urls), MAX_WORKER)).map(
# download, urls
# )
with ProcessPoolExecutor() as ppe:
resp = ppe.map(download, urls)
for _ in resp:
sava(_)
if __name__ == '__main__':
cmain()
ThreadPoolExecutor and ProcessPoolExecutor classes inherit from the same interface. The difference is that the max of ProcessPoolExecutor_ Worker is optional, and the default value is os.cpu_count(), which is the maximum number of CPUs in the computer.
Using process pool instead of thread pool to download network resources is slow. I guess it may take longer to create processes and allocate resources.
From this perspective, the process pool is suitable for computing intensive tasks, but not for IO intensive computing.