This article has more points of knowledge and a longer length of text, please be patient to learn
MySQL has become the backbone of relational database products nowadays, and is favored by Internet companies. Out-of-office interviews want BAT, high salary, no knowledge of MySQL optimization, and the success rate of offer ing will be greatly reduced.
Why Optimize
- System throughput bottlenecks often occur at database access speeds
- As the application runs, there will be more and more data in the database and processing time will be slower accordingly
- Data is stored on disk and cannot be read or written faster than memory
How to optimize
- When designing a database: design of database tables and fields, storage engine
- Take advantage of MySQL's own capabilities, such as indexing
- Horizontal Extension: MySQL Cluster, Load Balancing, Read-Write Separation
- SQL statement optimization (with little success)
Field Design
Selection of field types, design specifications, paradigms, common design cases
Principle: Use integers to represent strings whenever possible
Store IP
INET_ATON(str),address to number
INET_NTOA(number),number to address
Enumeration (radio) and collection (multi-select) types inside MySQL
However, it is not often used because of high maintenance costs, and the associated tables are used instead of enum
Principle: Selection of fixed-length and non-fixed-length data types
decimal does not lose precision, and storage space increases as data increases.A double takes up a fixed amount of space, and a larger number of storage can lose precision.Vachar, text are also non-variable lengths
Amount of money
There is a high accuracy requirement for data, and there is a problem with the precision of decimal operations and storage (all decimal numbers cannot be converted to binary)
Fixed-point decimal
price decimal(8,2) has two decimal fixed points, which support very large numbers (even numbers that exceed the storage range of int,bigint)
Small Units Large Amounts Avoid Decimals
Yuan->Minutes
String Storage
Fixed-length char, non-fixed-length varchar, text (upper limit 65535, where varchar also consumes 1-3 bytes of record length, while text uses extra space record length)
Principle: Choose as small a data type as possible and specify a short length
Principle: Use not null whenever possible
Non-null fields are handled more efficiently than null fields!There is no need to determine whether it is null.
Null is hard to handle in MySQL, requires extra space for storage, and requires special operators for operations.If select null = null and select null <> null (<> is not equal sign) have the same results, only is null and is not null can be used to determine whether a field is null.
How to store?Each record in MySQL requires additional storage space to indicate whether each field is null.So it's common to use special data for placeholders, such as int not null default 0, string not null default''
Principle: Complete field notes, see name
Principle: Don't have too many fields in a single form
Twenty or thirty is the limit
Principle: Fields can be reserved
Satisfy business needs before using these principles
Design of Associated Tables
foreign key can only map one-to-one or one-to-many
One-to-many
Use foreign keys
Many-to-many
Create a new table separately to split many-to-many into two one-to-many tables
One-on-one
For example, the basic information of a commodity (item) and the details of a commodity (item_intro), the same primary key is usually used or a foreign key field (item_id) is added.
Normal Format
Data table design specifications, an increasingly stringent set of specifications (if you need to satisfy the N-1 paradigm, you must first satisfy the N-1 paradigm).N
First Norm 1NF: Field Atomicity
Field atomicity, field can no longer be split.
Relational database, which satisfies the first paradigm by default
Note that it's easier to make mistakes by using commas to separate multiple foreign keys in a one-to-many design, which is convenient to store but not easy to maintain and index (for example, looking for tagged java articles)
Second paradigm: eliminating partial dependence on primary keys
That is, add a field to the table that is independent of business logic as the primary key
Primary key: A field or collection of fields that uniquely identifies a record.
| course_name | course_class | weekday (day of week) | course_teacher |
|---|---|---|---|
| MySQL | Educational Building 1525 | Monday | Zhang San |
| Java | Education Building 1521 | Wednesday | Li Si |
| MySQL | Education Building 1521 | Friday | Zhang San |
Dependency: A field determines B field, B field depends on A field.For example, if you know that the next lesson is math, you can determine who the teacher is.So the days of the week and the next lesson and can form a composite primary key, can determine which classroom to go to, who is the teacher, and so on.But we often add an id as the primary key, eliminating partial dependence on the primary key.
Partial dependency on a primary key: A field depends on a part of a composite primary key.
Solution: Add a separate field as the primary key.
Third paradigm: eliminating dependency on primary key delivery
Delivery Dependency: Field B depends on A and Field C on B.For example, in the example above, who the teacher is depends on what lesson is and what lesson depends on the primary key id.Therefore, this table needs to be split into two timetables and timetables (separate data tables):
| id | weekday | course_class | course_id |
|---|---|---|---|
| 1001 | Monday | Education Building 1521 | 3546 |
| course_id | course_name | course_teacher |
|---|---|---|
| 3546 | Java | Zhang San |
This reduces data redundancy (even if there are Java classes every day from Monday to Sunday, there are only seven occurrences of course_id:3546)
Storage Engine Selection
Early Question: How do I choose MyISAM and Innodb?
There is no longer a problem. Innodb continues to improve, overtaking MyISAM in all aspects, and is the default use of MySQL.
Storage engine: How data, indexes, and other objects in MySQL are stored is an implementation of a file system.
Functional differences
show engines
| Engine | Support | Comment |
|---|---|---|
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys |
| MyISAM | YES | MyISAM storage engine |
Storage differences
| MyISAM | Innodb | |
|---|---|---|
| file format | Data and indexes are stored separately, data. MYD, index. MYI | Data and indexes are centrally stored,.ibd |
| Can files be moved | Yes, a table corresponds to.frm, MYD, MYI files | No, because there are other files associated under data |
| Record storage order | Save in record insertion order | Insert orderly by primary key size |
| Spatial fragmentation (table file size unchanged after deleting records and flush table table name) | Generate.Timing: Implemented using the command optimize table table name | Do not produce |
| affair | I won't support it | Support |
| foreign key | I won't support it | Support |
| Lock support (Locks are a mechanism to avoid resource contention and MySQL locks are almost transparent to users) | Table level locking | Row-level locking, table-level locking, low locking force and high concurrency |
Lock extension
table-level lock: lock tables <table_name1>, <table_name2>... read/write, unlock tables <table_name1>, <table_name2>....Where read is a shared lock and once locked any client is unreadable; write is an exclusive/write lock, only the locked client is readable and writable, and no other client is readable or writable.One or more tables are locked.
row-level lock: Locks one or more rows of records.Shared locks: select * from <table_name> where <condition> LOCK IN SHARE MODE; add shared locks to the records of the query; select * from <table_name> where <condition> FOR UPDATE; and add exclusive locks to the records of the query.It is worth noting here that innodb's row lock is actually a sub-range lock, locking part of the range according to conditions, rather than mapping to specific rows, so there is also a school name: gap lock.For example, select * from stu where id < 20 LOCK IN SHARE MODE locks IDS in the range below 20 or so, and you may not be able to insert a new record with IDs of 18 or 22.
Selection basis
If there is no special requirement, use the default Innodb.
MyISAM: Read-write insert-based applications such as blog systems, news portals.
Innodb: Update (delete) operations are also frequent, or data integrity needs to be guaranteed; high concurrency, transaction support and foreign keys are required to ensure data integrity.For example, OA automated office system.
Indexes
The mapping relationship between keywords and data is called an index (=== The address on disk that contains keywords and corresponding records==).Keyword is a specific content extracted from data to identify and retrieve data.
Why is index retrieval fast?
- Keyword relative to data itself, ==Small amount of data==
- Keyword is==ordered==Binary lookup to quickly locate
The library uses index numbers (category-floor-shelf) for each book, dictionaries to catalog word explanations in alphabetical order, and so on.
Index type in MySQL
Normal index, unique key, primary key, full-text index
The three indexes are indexed in the same way, but with different restrictions on the keywords of the index:
- Normal Index: No restrictions on keywords
- Unique index: Keyword provided by the record is required not to be duplicated
- Primary key index: Requires keywords to be unique and not null
Index Management Syntax
View Index
show create table table name:
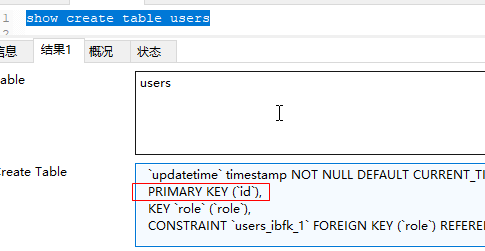
desc table name
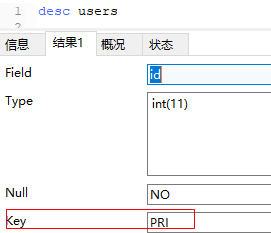
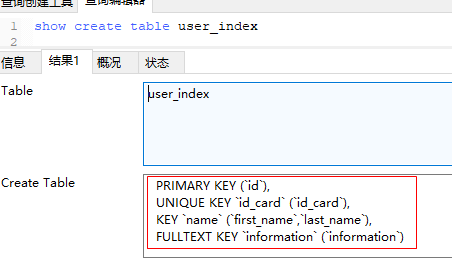
Create Index
Index tables after they are created
create TABLE user_index(
id int auto_increment primary key,
first_name varchar(16),
last_name VARCHAR(16),
id_card VARCHAR(18),
information text
);
-- Change table structure
alter table user_index
-- Create a first_name and last_name Composite index named name
add key name (first_name,last_name),
-- Create a id_card Unique index with field name as index name by default
add UNIQUE KEY (id_card),
-- Chicken ribs, full-text indexing does not support Chinese
add FULLTEXT KEY (information);show create table user_index:
Specify index when creating table
CREATE TABLE user_index2 (
id INT auto_increment PRIMARY KEY,
first_name VARCHAR (16),
last_name VARCHAR (16),
id_card VARCHAR (18),
information text,
KEY name (first_name, last_name),
FULLTEXT KEY (information),
UNIQUE KEY (id_card)
);Delete Index
Delete normal index, unique index, full-text index by index name: alter table table table name drop KEY index name
alter table user_index drop KEY name; alter table user_index drop KEY id_card; alter table user_index drop KEY information;
Delete primary key index: alter table table table name drop primary key (because there is only one primary key).It is worth noting here that this operation cannot be performed directly if the primary key grows itself (self-growth depends on the primary key index):
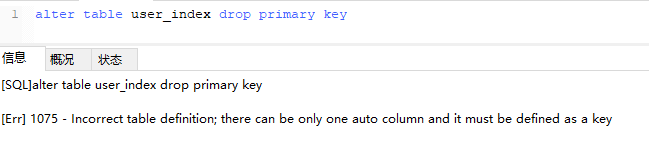
You need to cancel self-growth before deleting:
alter table user_index -- Redefine Field MODIFY id int, drop PRIMARY KEY
However, the primary key is not usually deleted because the design primary key must be independent of business logic.
Execution plan explain
CREATE TABLE innodb1 (
id INT auto_increment PRIMARY KEY,
first_name VARCHAR (16),
last_name VARCHAR (16),
id_card VARCHAR (18),
information text,
KEY name (first_name, last_name),
FULLTEXT KEY (information),
UNIQUE KEY (id_card)
);
insert into innodb1 (first_name,last_name,id_card,information) values ('Zhang','three','1001','Mount Hua Sect');We can analyze the execution plan before the execution of the SQL statement by explain selelct:
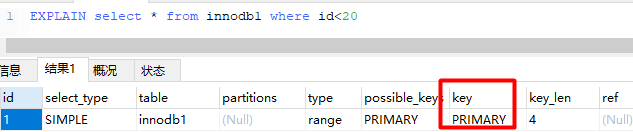
As you can see from the figure above, this SQL statement is retrieved by primary key index.
The execution plan is that when executing a SQL statement, it will first analyze and optimize to form an execution plan, which will be executed according to the execution plan.
Index usage scenarios (focus)
where
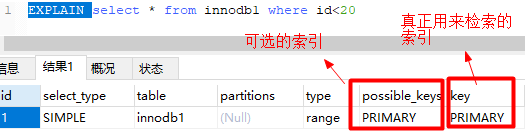
In the figure above, records are queried based on id because the id field only establishes a primary key index, so the only index that this SQL executes optionally is a primary key index, and if there are more than one, a better one will eventually be chosen as the basis for retrieval.
-- Add a field that is not indexed alter table innodb1 add sex char(1); -- Press sex The optional index to retrieve is null EXPLAIN SELECT * from innodb1 where sex='male';
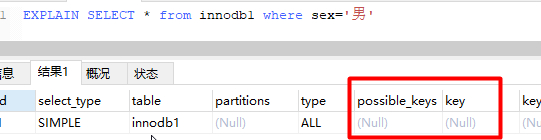
You can try indexing a field without indexing it based on its query efficiency and then indexing it (alter table name add index). With the same efficiency of SQL execution, you will see a significant improvement in query efficiency (the larger the amount of data).
order by
When we use orderWhen by sorts the results of a query by a field, if the field is not indexed, the execution plan uses an external sort for all the data it queries (batches of data from the hard disk to internal sort using memory, and finally merges the sort results), which can have a significant impact on performance because all the data involved in the query needs to be read from disk to memory(If a single piece of data is too large or there is too much data, it will reduce efficiency), not to mention sorting after reading into memory.
But if we index this field with the alter table table name add index, then since the index itself is ordered, the data is taken out one by one directly in the order of the indexes and the mapping relationship.And if paging, only the data corresponding to the index within a range of the index table will be taken out, instead of sorting all the data and returning the data within a range as described above.(fetching data from disk is the most performance-impacting)
join
Indexing the fields involved in the join statement matching relationship (on) improves efficiency
Index Coverage
If the fields to be queried are indexed, the engine will query directly in the index table without accessing the original data (otherwise, a full table scan will be performed if only one field is not indexed), which is called index override.So we need to write only the necessary query fields after select=== to increase the chance of index coverage.
It is worth noting here that you don't want to index each field, because the advantage of preferring an index is its small size.
Grammatical details (main points)
In scenarios where the index is used (where/order by/join or index override), the index is not necessarily used
Fields need to appear independently
For example, the following two SQL statements are semantically identical, but the first one uses a primary key index and the second one does not.
select * from user where id = 20-1; select * from user where id+1 = 20;
like query, cannot start with a wildcard
For example, the search title contains articles from mysql:
select * from article where title like '%mysql%';
This SQL execution plan uses no indexes (like statement matching expressions start with wildcards), so it can only do full table scanning, which is extremely inefficient and rarely used in practice.In general, the full-text index provided by third parties to support Chinese is used.
However, the keyword query hotspot reminder function can still be done, such as reminding MySQL tutorial, MySQL download, MySQL installation steps after typing mysql, etc.The statements used are:
select * from article where title like 'mysql%';
This like s can be indexed (provided, of course, the title field has been indexed).
Composite index is valid only for the first field
Composite index:
alter table person add index(first_name,last_name);
The principle is to sort the index first by the keyword extracted from first_name, and then by the keyword extracted from last_name if it is not certain, that is, the index table is only ordered by the first_name field value of the record.
So select * from person where first_name =? Is an index available, and select * from person where last_name =? Is not.
So what is the scenario for this composite index?==Combinatorial Query==
For example, for select * person from first_name =? And last_name =?, a composite index is more efficient than indexing first_name and last_name separately.It's understandable that a composite index first looks for records matching first_name =? In two, and then in two, for records matching last_name, only one index table is involved.Indexing separately finds records matching first_name =? In the first_name index table by dichotomy, and then finds records matching last_name =? In the last_name index table by dichotomy, which is an intersection of the two.
or, both conditions have indexes available
A full table scan of the entire SQL statement can result if one side has no index available
Status value, not easy to use with indexes
Status value fields such as gender, payment status, and so on, tend to have very few possible values, which are often not available even when indexed.This is because a status value may match a large number of records, in which case MySQL will think that using an index is less efficient than full-table scanning, thereby discarding the index.Indexes access disks randomly, while full-table scans access disks sequentially, which is like having a 20-story office building with index boards downstairs stating the floors of a company that are not adjacent to each other. When you go to your company to find someone, you might as well find the top floor one by one instead of following the index boards and looking up again.
How to create an index
- Building a base index: Index on where, order by, join fields.
- Optimize, Composite Index: Based on Business Logic
- If conditions often occur together, consider upgrading a multifield index to ==composite index==
- If you increase the index of an individual field and you get ==index override==, you might consider indexing the field
- When querying, infrequently used indexes should be deleted
Prefix index
Syntax: index(field(10)), which uses the first 10 characters of a field value to index. By default, it uses the entire content of the field to index.
Prerequisite: The prefix is highly identifiable.For example, passwords are good for prefix indexing, because passwords are almost different.
==The difficulty of the operation==: is the length of the prefix intercept.
We can use select count(*)/count(distinct left(password,prefixLen)); by looking at an average match of different prefixLen lengths from adjusting the value of prefixLen (increasing from 1), close to 1 (the first prefixLen characters representing a password almost determine the only record)
Storage structure of index
BTree
btree (Multiplex Balanced Lookup Tree) is a data structure that is widely used to implement index function==on disk, and is also the implementation of most database index tables.
Take add index(first_name,last_name) for example:
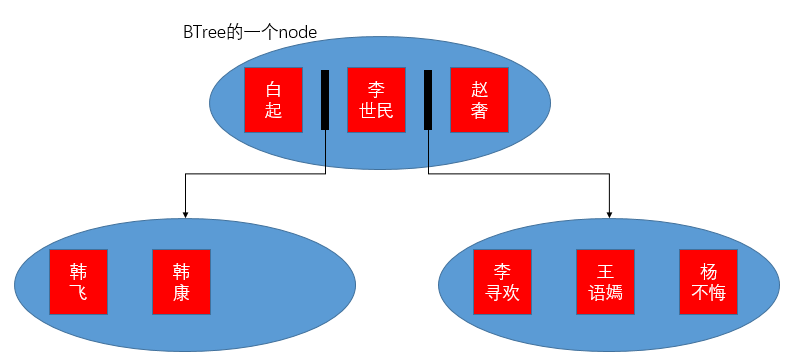
A node of BTree can store mu lt iple keywords, and the size of the node depends on the computer's file system, so we can make the node store more keywords by reducing the length of the index field.If the keywords in the node are full, the index table can be expanded by the sub-node pointer between each keyword, but the orderliness of the structure can not be destroyed, for example, according to the first_name first-order and last_name second-order rules, the newly added Korean fragrance can be inserted after Hankang.White rise <Hanfei<Hankang<Li Shimin<Zhaolu<Li Xunhuan<Wang Yuyan<Yang does not repent.This is the same idea as the binary search tree, except that the search efficiency of the binary search tree is log(2,N) (logarithm with base 2 N), while the search efficiency of BTree is log(x,N) (where x is the number of keywords for node, can reach more than 1000).
From the log(1000+,N), you can see that a small amount of disk reading can traverse a large amount of data, which is the design purpose of btree.
B+Tree Cluster Structure
Keyword and record are stored together in a clustered structure (also modified by BTree upgrade).
In MySQL, only Innodb's==primary key index is clustered==, while other indexes, including Innodb's non-primary key index, are typical BTree structures.
Hash indices
When the index is loaded into memory, it is stored using a hash structure.
Query Cache
Cache the query results of the select statement
Turn on cache in configuration file
my.ini on windows and my.cnf on linux
Configure query_cache_type in the [mysqld] section:
- 0: Do not turn on
- 1: On, default cache all, need to add select sql-no-cache prompt in SQL statement to discard cache
- 2: On, no cache by default, need to add select sql-cache to the SQL statement to actively cache (==Common==)
Configuration changes require a reboot for the configuration to take effect, which can be viewed by showing variables like'query_cache_type';
show variables like 'query_cache_type'; query_cache_type DEMAND
Set cache size on client side
Set by configuring the item query_cache_size:
show variables like 'query_cache_size'; query_cache_size 0 set global query_cache_size=64*1024*1024; show variables like 'query_cache_size'; query_cache_size 67108864
Cache query results
select sql_cache * from user;
Reset Cache
reset query cache;
Cache Failure Problem (Large Problem)
Any cache based on a data table is deleted when the table changes.(Surface management, not record management, has a higher failure rate)
Matters needing attention
- Applications should not be concerned about the use of query cache.You can try to use it, but you cannot let query cache determine business logic, because query cache is managed by the DBA.
- The cache is stored with the SQL statement as the key, so even if the SQL statement functions the same, an extra space or a difference in case results in a mismatch in the cache.
partition
Typically, the tables we create correspond to a set of storage files, which are.MYI and.MYD files when using the MyISAM storage engine and.ibd and.frm (table structure) files when using the Innodb storage engine.
When there is a large amount of data (generally more than 10 million records), MySQL performance begins to degrade, and then we need to spread the data across groups of storage files, == to ensure the efficiency of its individual files==.
The most common partitioning scheme is partitioning by id, as follows, modelling the hash value of ID over 10 to evenly distribute the data to 10.ibd storage files:
create table article(
id int auto_increment PRIMARY KEY,
title varchar(64),
content text
)PARTITION by HASH(id) PARTITIONS 10View the data directory:
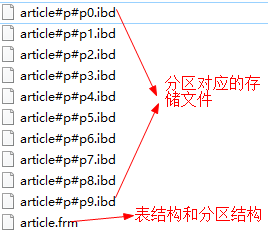
==The server side's table partition is transparent to the client==, the client inserts the data as usual, but the server side stores the data separately according to the partitioning algorithm.
Partition algorithm provided by MySQL
==The field on which the partition is based must be part of the primary key==, partitioning is for fast positioning of the data, so the field should be searched more frequently as a strong retrieval field, otherwise partitioning by that field is meaningless
hash(field)
The same input yields the same output.The output results are independent of whether the input is regular or not.==Applicable only to integer fields==
key(field)
Just like hash(field), except that key==handles string==and calculates an integer from the string one step more than hash() in the modeling operation.
create table article_key(
id int auto_increment,
title varchar(64),
content text,
PRIMARY KEY (id,title) -- Require partition by field to be part of primary key
)PARTITION by KEY(title) PARTITIONS 10range algorithm
Is a==conditional partition==algorithm that partitions data by size range (scatters data into different partitions using some condition).
As follows, the data will be stored in August, September, and October 2018 zones by the time the article was published:
create table article_range(
id int auto_increment,
title varchar(64),
content text,
created_time int, -- Published until 1970-1-1 milliseconds
PRIMARY KEY (id,created_time) -- Require partition by field to be part of primary key
)charset=utf8
PARTITION BY RANGE(created_time)(
PARTITION p201808 VALUES less than (1535731199), -- select UNIX_TIMESTAMP('2018-8-31 23:59:59')
PARTITION p201809 VALUES less than (1538323199), -- 2018-9-30 23:59:59
PARTITION p201810 VALUES less than (1541001599) -- 2018-10-31 23:59:59
);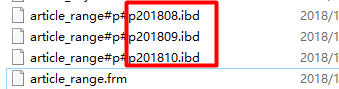
Note: Conditional operators can only use ==less than==, which means that smaller ranges, such as p201808, p201819, and p201810 partitions, are defined in a sequence from small to large in the created_time value range and cannot be reversed.
insert into article_range values(null,'MySQL optimization','Content examples',1535731180); flush tables; -- Refresh operation to disk file immediately
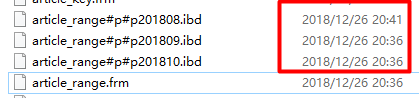
Since the published time of the inserted article is less than 1535731199 (2018-8-31 23:59:59), it is stored in the p201808 partition, which partition the algorithm is stored in depends on the data condition.
list algorithm
It is also a conditional partition, partitioned by list values (in (list of values).
create table article_list(
id int auto_increment,
title varchar(64),
content text,
status TINYINT(1), -- Article Status: 0-Draft, 1-Completed but not published,2-Published
PRIMARY KEY (id,status) -- Require partition by field to be part of primary key
)charset=utf8
PARTITION BY list(status)(
PARTITION writing values in(0,1), -- Put unpublished in one partition
PARTITION published values in (2) -- Published in one partition
);insert into article_list values(null,'mysql optimization','Content examples',0); flush tables;

Partition Management Syntax
range/list
Add partitions
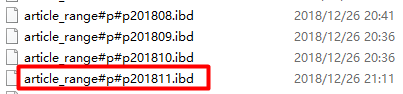
In the previous section, we tried to use range to archive articles by month. As time goes on, we need to add a month:
alter table article_range add partition(
partition p201811 values less than (1543593599) -- select UNIX_TIMESTAMP('2018-11-30 23:59:59')
-- more
);
delete a partition
alter table article_range drop PARTITION p201808
Note: ==Delete the partition, and the original data in the partition will also be deleted!==
key/hash
New partition
alter table article_key add partition partitions 4
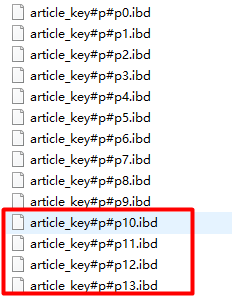
Destroy partition
alter table article_key coalesce partition 6
The management of key/hash partitions does not delete data, but each adjustment (adding or destroying partitions) assigns all data overrides to the new partition.=== Very inefficient==, partitioning strategy is best considered at design time.
Use of partitions
When there is a large amount of data in a data table, the efficiency gains from partitioning will become apparent.
Partitioning improves efficiency only when the retrieval field is a partition field.Therefore, it is important to select the == partition field ==, and ===Business logic should adjust it accordingly to the partition field as much as possible == (try using the partition field as a query condition).
Horizontal and vertical divisions
Horizontal Split: Store data separately by creating several tables with the same structure
Vertical Split: Place frequently used fields in a separate table, and there is a one-to-one correspondence between the split table records.
Table breakdown reasons
- Decompressing the database
- Partition algorithm limitations
- Imperfect database support (mysql supports partitioning operations after 5.1)
Solution with duplicate id
- id booster borrowing from third-party applications such as memcache, redis
- Create a separate table with only one field of id, each time adding the field as the ID of the data record
colony
Horizontal expansion: Fundamentally (limited hardware processing power on a single machine) improves database performance.Relevant technologies resulting from this: ==read-write separation, load balancing==
Install and configure master-slave replication
Environmental Science
- Red Hat Enterprise Linux Server release 7.0 (Maipo) (Virtual Machine)
- mysql5.7(Download Address)
install and configure
Unzip to the directory of services offered to the outside world (I created a / export/server to store it myself)
tar xzvf mysql-5.7.23-linux-glibc2.12-x86_64.tar.gz -C /export/server cd /export/server mv mysql-5.7.23-linux-glibc2.12-x86_64 mysql
Add the group and owner of the mysql directory:
groupadd mysql useradd -r -g mysql mysql cd /export/server chown -R mysql:mysql mysql/ chmod -R 755 mysql/
Create a mysql data store directory (where/export/data is the directory I created specifically for various services)
mkdir /export/data/mysql
Initialize mysql service
cd /export/server/mysql ./bin/mysqld --basedir=/export/server/mysql --datadir=/export/data/mysql --user=mysql --pid-file=/export/data/mysql/mysql.pid --initialize
If the initial password for mysql's root account is displayed successfully, write it down for subsequent logins.If errors lack a dependency, install them in turn using yum instally
Configure my.cnf
vim /etc/my.cnf [mysqld] basedir=/export/server/mysql datadir=/export/data/mysql socket=/tmp/mysql.sock user=mysql server-id=10 # Service id, must be unique when clustering, recommended set to the fourth segment of IP port=3306 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in http://fedoraproject.org/wiki/Systemd [mysqld_safe] log-error=/export/data/mysql/error.log pid-file=/export/data/mysql/mysql.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
Add services to boot-up autostart
cp /export/server/mysql/support-files/mysql.server /etc/init.d/mysqld
Start Services
service mysqld start
Configure environment variables to add the following in/etc/profile
# mysql env MYSQL_HOME=/export/server/mysql MYSQL_PATH=$MYSQL_HOME/bin PATH=$PATH:$MYSQL_PATH export PATH
Make the configuration take effect
source /etc/profile
Log on using root
mysql -uroot -p # Fill in the password you provided to initialize the service before
After you log in, change the root account password (I changed it to root for convenience), otherwise the operation database will fail
set password=password('root');
flush privileges;Setup services are accessible by all remote clients
use mysql; update user set host='%' where user='root'; flush privileges;
This allows you to remotely connect mysql on the virtual machine linux using navicat on the host machine
Configure master-slave nodes
Configure master
Configure master-slave replication with mysql on linux (192.168.10.10) and mysql on host (192.168.10.1).
Modify master's my.cnf as follows
[mysqld] basedir=/export/server/mysql datadir=/export/data/mysql socket=/tmp/mysql.sock user=mysql server-id=10 port=3306 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in http://fedoraproject.org/wiki/Systemd log-bin=mysql-bin # Open Binary Log expire-logs-days=7 # Set log expiration time to avoid full disk binlog-ignore-db=mysql # Databases that do not use master-slave replication binlog-ignore-db=information_schema binlog-ignore-db=performation_schema binlog-ignore-db=sys binlog-do-db=test #Use master-slave replicated databases [mysqld_safe] log-error=/export/data/mysql/error.log pid-file=/export/data/mysql/mysql.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
Restart master
service mysqld restart
Log in to master to see if the configuration works (ON is on, OFF by default):
mysql> show variables like 'log_bin'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_bin | ON | +---------------+-------+
Create a backup account in master's database: backup is the user name,%indicates any remote address, user backup can use password 1234 to connect master through any remote client
grant replication slave on *.* to 'backup'@'%' identified by '1234'
Looking at the user table, you can see the user we just created:
mysql> use mysql mysql> select user,authentication_string,host from user; +---------------+-------------------------------------------+-----------+ | user | authentication_string | host | +---------------+-------------------------------------------+-----------+ | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | % | | mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | localhost | | mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | localhost | | backup | *A4B6157319038724E3560894F7F932C8886EBFCF | % | +---------------+-------------------------------------------+-----------+
Create a new test database, create an article table for subsequent testing
CREATE TABLE `article` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(64) DEFAULT NULL, `content` text, PRIMARY KEY (`id`) ) CHARSET=utf8;
Restart the service and refresh the database state to a storage file (with read lock means that clients can only read data during this process to get a consistent snapshot)
[root@zhenganwen ~]# service mysqld restart Shutting down MySQL.... SUCCESS! Starting MySQL. SUCCESS! [root@zhenganwen mysql]# mysql -uroot -proot mysql> flush tables with read lock; Query OK, 0 rows affected (0.00 sec)
View the current binary logs and offsets on the master (take note of the File and osition)
mysql> show master status \G
*************************** 1. row ***************************
File: mysql-bin.000002
Position: 154
Binlog_Do_DB: test
Binlog_Ignore_DB: mysql,information_schema,performation_schema,sys
Executed_Gtid_Set:
1 row in set (0.00 sec)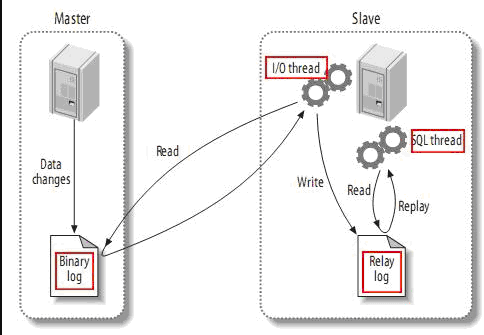
File represents the log for replication, which is the Binary log in the figure above; Position indicates that the offset of the Binary log file is synchronized to the slave, so we need to import it manually before the offset.
Any modifications made on the primary server are saved in the Binary log, an I/O thread (essentially a client process on the primary server) is started from the server, a connection is made to the primary server and a request is made to read the Binary log, which is then written to a local Really log.Open a SQL thread ed timer from the server to check the Realy log and execute the changes locally once if any changes are found.
If there is a master slave, then the master library is responsible for both writing and providing binary logs to several slave libraries.You can adjust this to give the binary log only to a slave, which then opens the binary log and sends its own binary log to another slave.Or simply this never-logger is responsible only for forwarding binary logs to other slaves, which may result in much better architecture performance and slightly better latency between data
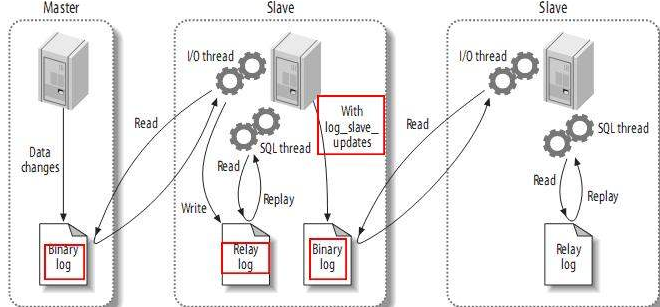
Manual import, export data from master
mysqldump -uroot -proot -hlocalhost test > /export/data/test.sql
Execute the contents of test.sql on the slave once.
Configure slave
Modify the [mysqld] section of slave's my.ini file
log-bin=mysql server-id=1 #192.168.10.1
Restart slave after saving changes, WIN+R->services.msc->MySQL5.7->Restart
Log in to slave to check if log_bin is turned on:
show VARIABLES like 'log_bin';
Configure synchronous replication with master:
stop slave;
change master to
master_host='192.168.10.10', -- master Of IP
master_user='backup', -- Before master Users created on
master_password='1234',
master_log_file='mysql-bin.000002', -- master upper show master status \G Information provided
master_log_pos=154;Enable slave nodes and view status
mysql> start slave;
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.10
Master_User: backup
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 154
Relay_Log_File: DESKTOP-KUBSPE0-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 154
Relay_Log_Space: 537
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 10
Master_UUID: f68774b7-0b28-11e9-a925-000c290abe05
Master_Info_File: C:\ProgramData\MySQL\MySQL Server 5.7\Data\master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Note that looking at lines 4, 14, and 15, if consistent with me, indicates that slave was successfully configured
test
Turn off master's read lock
mysql> unlock tables; Query OK, 0 rows affected (0.00 sec)
Insert a piece of data into the master
mysql> use test
mysql> insert into article (title,content) values ('mysql master and slave','record the cluster building succeed!:)');
Query OK, 1 row affected (0.00 sec)See if slave automatically synchronizes data
mysql> insert into article (title,content) values ('mysql master and slave','record the cluster building succeed!:)');
Query OK, 1 row affected (0.00 sec)At this point, the master-slave replication configuration is successful!:)
Quickly set up Mysql master-slave replication using the mysqlreplicate command
Read-Write Separation
Read-write separation relies on master-slave replication, which serves read-write separation.Because master-slave replication requires that slaves cannot be written and read-only (if you write to a slave, show slave status will render Slave_SQL_Running=NO, at which point you need to synchronize the slave manually as mentioned earlier).
Scenario 1. Define two connections
Like the DataBase we defined when learning JDBC, we can extract ReadDataBase, WriteDataBase implementations DataBase, but this method can't help us manage connections using good thread pool technologies such as DruidDataSource, or make connections transparent to the DAO layer using Spring AOP.
Scenario 2. Using Spring AOP
If you can use Spring AOP to solve the problem of data source switching, you can integrate it with Mybatis and Druid.
When we integrate Spring1 and Mybatis, we only need to write DAO interfaces and corresponding SQL statements, so who created the DAO instance?In fact, Spring created it for us to get a database connection from the data source we injected, execute SQL statements using the connection, and finally return the connection to the data source.
If we can dynamically select a data source (read data source corresponds to connection master and write data source to connection slave) according to the interface method naming specification (add XXX/createXXX, delete XX/removeXXX, change updateXXXX X, check selectXX/findXXX/getXX/queryXXX) when invoking DAO interface, we can achieve read-write separation.
Project structure
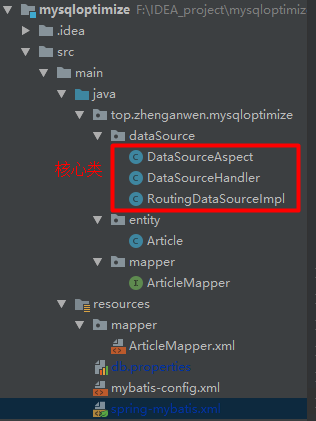
Introducing dependencies
Among them, mybatis and druid are introduced to facilitate access to the database, and dynamic switching of data sources mainly depends on spring-aop and spring-aspects
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>6.0.2</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.22</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>Data Class
package top.zhenganwen.mysqloptimize.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Article {
private int id;
private String title;
private String content;
}spring Profile
RoutingDataSourceImpl is the core class for dynamic switching, which is described later.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="db.properties"></context:property-placeholder>
<context:component-scan base-package="top.zhenganwen.mysqloptimize"/>
<bean id="slaveDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${db.driverClass}"/>
<property name="url" value="${master.db.url}"></property>
<property name="username" value="${master.db.username}"></property>
<property name="password" value="${master.db.password}"></property>
</bean>
<bean id="masterDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${db.driverClass}"/>
<property name="url" value="${slave.db.url}"></property>
<property name="username" value="${slave.db.username}"></property>
<property name="password" value="${slave.db.password}"></property>
</bean>
<bean id="dataSourceRouting" class="top.zhenganwen.mysqloptimize.dataSource.RoutingDataSourceImpl">
<property name="defaultTargetDataSource" ref="masterDataSource"></property>
<property name="targetDataSources">
<map key-type="java.lang.String" value-type="javax.sql.DataSource">
<entry key="read" value-ref="slaveDataSource"/>
<entry key="write" value-ref="masterDataSource"/>
</map>
</property>
<property name="methodType">
<map key-type="java.lang.String" value-type="java.lang.String">
<entry key="read" value="query,find,select,get,load,"></entry>
<entry key="write" value="update,add,create,delete,remove,modify"/>
</map>
</property>
</bean>
<!-- Mybatis file -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="configLocation" value="classpath:mybatis-config.xml" />
<property name="dataSource" ref="dataSourceRouting" />
<property name="mapperLocations" value="mapper/*.xml"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="top.zhenganwen.mysqloptimize.mapper" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" />
</bean>
</beans>dp.properties
master.db.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC master.db.username=root master.db.password=root slave.db.url=jdbc:mysql://192.168.10.10:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC slave.db.username=root slave.db.password=root db.driverClass=com.mysql.jdbc.Driver
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<typeAlias type="top.zhenganwen.mysqloptimize.entity.Article" alias="Article"/>
</typeAliases>
</configuration>mapper interface and configuration file
ArticleMapper.java
package top.zhenganwen.mysqloptimize.mapper;
import org.springframework.stereotype.Repository;
import top.zhenganwen.mysqloptimize.entity.Article;
import java.util.List;
@Repository
public interface ArticleMapper {
List<Article> findAll();
void add(Article article);
void delete(int id);
}ArticleMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="top.zhenganwen.mysqloptimize.mapper.ArticleMapper">
<select id="findAll" resultType="Article">
select * from article
</select>
<insert id="add" parameterType="Article">
insert into article (title,content) values (#{title},#{content})
</insert>
<delete id="delete" parameterType="int">
delete from article where id=#{id}
</delete>
</mapper>Core Classes
RoutingDataSourceImpl
package top.zhenganwen.mysqloptimize.dataSource;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import java.util.*;
/**
* RoutingDataSourceImpl class
* Data Source Routing
*
* @author zhenganwen, blog:zhenganwen.top
* @date 2018/12/29
*/
public class RoutingDataSourceImpl extends AbstractRoutingDataSource {
/**
* key For read or write
* value Prefix for DAO methods
* What prefix method starts with a reader and what starts with a write data source
*/
public static final Map<String, List<String>> METHOD_TYPE_MAP = new HashMap<String, List<String>>();
/**
* We specify the id of the data source, and Spring switches the data source
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
System.out.println("The data source is:"+DataSourceHandler.getDataSource());
return DataSourceHandler.getDataSource();
}
public void setMethodType(Map<String, String> map) {
for (String type : map.keySet()) {
String methodPrefixList = map.get(type);
if (methodPrefixList != null) {
METHOD_TYPE_MAP.put(type, Arrays.asList(methodPrefixList.split(",")));
}
}
}
}Its main function is that we only configure one data source, so Spring dynamic proxy DAO interface uses this data source directly. Now that we have two data sources to read and write, we need to add some logic to tell which interface to call which data source to use (slave for the interface to read data, master for the interface to write data).This tells Spring which data source class to use is AbstractRoutingDataSource, and the method determineCurrentLookupKey, which must be overridden, returns the identity of the data source in conjunction with the spring configuration file (lines 5, 6 of the next code)
<bean id="dataSourceRouting" class="top.zhenganwen.mysqloptimize.dataSource.RoutingDataSourceImpl">
<property name="defaultTargetDataSource" ref="masterDataSource"></property>
<property name="targetDataSources">
<map key-type="java.lang.String" value-type="javax.sql.DataSource">
<entry key="read" value-ref="slaveDataSource"/>
<entry key="write" value-ref="masterDataSource"/>
</map>
</property>
<property name="methodType">
<map key-type="java.lang.String" value-type="java.lang.String">
<entry key="read" value="query,find,select,get,load,"></entry>
<entry key="write" value="update,add,create,delete,remove,modify"/>
</map>
</property>
</bean>If determineCurrentLookupKey returns read, use slaveDataSource, and master DataSource if it returns write.
DataSourceHandler
package top.zhenganwen.mysqloptimize.dataSource;
/**
* DataSourceHandler class
* <p>
* Bind the data source to the thread and get it as needed
*
* @author zhenganwen, blog:zhenganwen.top
* @date 2018/12/29
*/
public class DataSourceHandler {
/**
* Binding is read or write, meaning to use a read or write data source
*/
private static final ThreadLocal<String> holder = new ThreadLocal<String>();
public static void setDataSource(String dataSource) {
System.out.println(Thread.currentThread().getName()+"Data Source Type Set");
holder.set(dataSource);
}
public static String getDataSource() {
System.out.println(Thread.currentThread().getName()+"Get the data source type");
return holder.get();
}
}DataSourceAspect
package top.zhenganwen.mysqloptimize.dataSource;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Set;
import static top.zhenganwen.mysqloptimize.dataSource.RoutingDataSourceImpl.METHOD_TYPE_MAP;
/**
* DataSourceAspect class
*
* Configure facets to set read and write data sources based on method prefix
* The bean is loaded when the project starts and the dynamic proxy logic is determined by the aspects of the configuration (which entry points, how to enhance)
* @author zhenganwen,blog:zhenganwen.top
* @date 2018/12/29
*/
@Component
//Declare that this is a facet so that Spring will configure it accordingly, otherwise it will only act as a simple bean injection
@Aspect
@EnableAspectJAutoProxy
public class DataSourceAspect {
/**
* Configure entry points: all methods for all classes under the DAO package
*/
@Pointcut("execution(* top.zhenganwen.mysqloptimize.mapper.*.*(..))")
public void aspect() {
}
/**
* Configuration Pre-Enhancement, Object is the starting point for configuration on the aspect() method
*/
@Before("aspect()")
public void before(JoinPoint point) {
String className = point.getTarget().getClass().getName();
String invokedMethod = point.getSignature().getName();
System.out.println("Yes "+className+"$"+invokedMethod+" Pre-enhancements were made to determine the type of data source to use");
Set<String> dataSourceType = METHOD_TYPE_MAP.keySet();
for (String type : dataSourceType) {
List<String> prefixList = METHOD_TYPE_MAP.get(type);
for (String prefix : prefixList) {
if (invokedMethod.startsWith(prefix)) {
DataSourceHandler.setDataSource(type);
System.out.println("The data source is:"+type);
return;
}
}
}
}
}Test Read-Write Separation
How do I test reading from slave?You can make changes to the data that you copy to the slave after writing, and then read the data to know it was read from the slave.==Note==, but if you do write to a slave, you need to manually synchronize the slave with the master, otherwise master-slave replication will fail.
package top.zhenganwen.mysqloptimize.dataSource;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import top.zhenganwen.mysqloptimize.entity.Article;
import top.zhenganwen.mysqloptimize.mapper.ArticleMapper;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:spring-mybatis.xml")
public class RoutingDataSourceTest {
@Autowired
ArticleMapper articleMapper;
@Test
public void testRead() {
System.out.println(articleMapper.findAll());
}
@Test
public void testAdd() {
Article article = new Article(0, "I am a newly inserted article", "Test if you can write to master And copy to slave in");
articleMapper.add(article);
}
@Test
public void testDelete() {
articleMapper.delete(2);
}
}load balancing
Load Balancing Algorithms
- polling
- Weighted polling: weighted by processing power
- Load Distribution: Based on the current idle state (but it is too inefficient to test each node's memory usage, CPU utilization, and so on, and then compare to select the most idle one)
High Availability
In the server architecture, to ensure that servers 7x24 are not down online, redundant machines are required for each single-point server (servers served by one server, such as write servers, database middleware).
For a write server, you need to provide the same write-redundancy server. When the write server is healthy (write-redundancy is detected by heartbeat), the write-redundancy replicates the contents of the write server as a slave role to synchronize with it; when the write server is down, the write-redundancy server will continue to serve as the write server on top.This process is transparent to the outside world, that is, the outside world only accesses services through one IP.
Typical SQL
Online DDL
DDL(Database Definition Language) refers to the language used to define (create table) and maintain (alter table) the structure of a database table.Executing DDL online will result in exclusive locking of the entire table below MySQL version 5.6, when the table is maintained and not operational, which will result in unresponsiveness to all access to the table during this period.However, after MySQL 5.6, Online DDL is supported, which greatly reduces the locking time.
The optimization technique is to use a DDL that maintains the table structure (such as adding a column or an index), which is ==copy==policy.Idea: Create a new table that satisfies the new structure and import (copy) the old table data==item by item==into the new table to ensure that==less content is locked at once== (the data being imported is locked), while other tasks can be performed on the old table.During the import process, all operations on the old tables are logged, and after the import is complete, the update log is executed on the new tables again (to ensure consistency).Finally, the new table replaces the old table (done in the application, or rename of the database, done in the view).
But with the upgrade of MySQL, the problem has almost faded.
Database Import Statement
When restoring data, a large amount of data may be imported.In order to import quickly at this time, you need to master some skills:
- When importing==Disable indexes and constraints first=:
alter table table-name disable keys
After data import is complete, open indexes and constraints to create indexes at once
alter table table-name enable keys
- If the engine used by the database is Innodb, it==defaults to adding transaction== to each write instruction (which can also take a while), so it is recommended that you start the transaction manually, perform a certain amount of bulk import, and then commit the transaction manually.
- If the batch imported SQL instructions have the same format but different data, you should prepare==precompiled==once, which also saves a lot of time from repeating compilation.
limit offset,rows
Make sure you don't have large offsets, such as limit 10000,10, which is equivalent to 10 rows after discarding the first 10,000 rows of the queried rows. You can filter (complete the filter) with some conditions, and you shouldn't use limit to skip the queried data.This is a question of ==offset doing useless==In corresponding practical projects, to avoid the situation of large page numbers, try to guide users to do conditional filtering.
select * Use less
That is, try to select the field you want, but this effect is not very big, because the network transfer is tens of thousands of bytes and there is not much delay, and the popular ORM framework is now using select*, but when designing tables, we should pay attention to separating a large amount of data fields, such as commodity details can be separated from a commodity details table, so that we can view the commoditiesLoading speed is not affected when the page is simple.
order by rand() do not use
Its logic is to sort randomly (one random number is generated for each data, then sorted according to the size of the random number).For example, select * from student order by rand() limit 5 is inefficient because it generates random numbers and sorts each data in the table, whereas we only need the first five.
Solution ideas: In the application, the random primary key will be generated, to use the primary key in the database to retrieve.
Single and Multiple Table Queries
Multi-table query: join, sub-query are queries involving multiple tables.If you use explain lain to analyze the execution plan, you will find that a multi-table query is also a table-to-table process and merges the results.So it can be said that single-table queries put computing pressure on the application, while multitable queries put computing pressure on the database.
There is now an ORM framework to help us solve the object mapping problems caused by form queries (when querying a form, if a foreign key is found to automatically query the associated table, it is a table-by-table look-up).
count(*)
In the MyISAM storage engine, the number of rows in a table is automatically recorded, so count(*) can be used to quickly return.Innodb does not have such a counter, we need to manually count the number of records, the solution is to use a single table:
| id | table | count |
|---|---|---|
| 1 | student | 100 |
limit 1
If you can be sure that only one item is retrieved, it is recommended to add limit 1, which the ORM framework actually helps us do (querying individual items automatically adds limit 1).
Slow Query Log
Used to record SQL logs whose execution time exceeds a certain threshold, to locate slow queries quickly, and to provide reference for our optimization.
Open Slow Query Log
Configuration item: slow_query_log
You can use show variables like'slov_query_log'to see if it is turned on or if the status value is OFF, you can use set GLOBAL slow_query_log = on to turn it on, which will produce an xxx-slow.log file under datadir.
Set critical time
Configuration item: long_query_time
View: show VARIABLES like'long_query_time', in seconds
Setting: set long_query_time=0.5
Practice should be set from a long time to a short time, i.e. to optimize the slowest SQL
view log
Once the SQL exceeds the critical time we set, it will be logged in xxx-slow.log
profile information
Configuration item: profiling
Open profile
set profiling=on
When turned on, all details of SQL execution are automatically recorded
mysql> show variables like 'profiling'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | profiling | OFF | +---------------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> set profiling=on; Query OK, 0 rows affected, 1 warning (0.00 sec)
View profile information
show profiles
mysql> show variables like 'profiling'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | profiling | ON | +---------------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> insert into article values (null,'test profile',':)'); Query OK, 1 row affected (0.15 sec) mysql> show profiles; +----------+------------+-------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------------------------------+ | 1 | 0.00086150 | show variables like 'profiling' | | 2 | 0.15027550 | insert into article values (null,'test profile',':)') | +----------+------------+-------------------------------------------------------+
View the time of all the detailed steps of a SQL through Query_ID
show profile for query Query_ID
In the results of the show profiles above, each SQL has a Query_ID that allows you to see what steps have been taken to execute the SQL, each consuming multiple times
Typical server configuration
The following configurations all depend on the actual operating environment
-
max_connections, maximum number of client connections
mysql> show variables like 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+
-
table_open_cache, table file handle cache (table data is stored on disk, handle to cache disk file is easy to open file to read data)
mysql> show variables like 'table_open_cache'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | table_open_cache | 2000 | +------------------+-------+
-
key_buffer_size, index cache size (caches indexes read from disk into memory, which can be set larger to facilitate fast retrieval)
mysql> show variables like 'key_buffer_size'; +-----------------+---------+ | Variable_name | Value | +-----------------+---------+ | key_buffer_size | 8388608 | +-----------------+---------+
-
innodb_buffer_pool_size, Innodb storage engine cache pool size (the most important configuration for Innodb, if all tables use Innodb, it is even recommended to set this value to 80% of physical memory, on which Innodb relies for many performance improvements, such as indexing)
mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+---------+ | Variable_name | Value | +-------------------------+---------+ | innodb_buffer_pool_size | 8388608 | +-------------------------+---------+
-
innodb_file_per_table (in innodb, table data is stored in the.ibd file, if the configuration item is set to ON, then one table corresponds to an ibd file, otherwise all InnoDB tablespaces are shared)
Manometric tool mysqlslap
MySQL is installed with a stress test tool, mysqlslap (in the bin directory)
Automatically generate sql tests
C:\Users\zaw>mysqlslap --auto-generate-sql -uroot -proot
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Average number of seconds to run all queries: 1.219 seconds
Minimum number of seconds to run all queries: 1.219 seconds
Maximum number of seconds to run all queries: 1.219 seconds
Number of clients running queries: 1
Average number of queries per client: 0Concurrent Testing
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=100 -uroot -proot
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Average number of seconds to run all queries: 3.578 seconds
Minimum number of seconds to run all queries: 3.578 seconds
Maximum number of seconds to run all queries: 3.578 seconds
Number of clients running queries: 100
Average number of queries per client: 0
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 -uroot -proot
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Average number of seconds to run all queries: 5.718 seconds
Minimum number of seconds to run all queries: 5.718 seconds
Maximum number of seconds to run all queries: 5.718 seconds
Number of clients running queries: 150
Average number of queries per client: 0Multi-Round Testing
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=10 -uroot -proot
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Average number of seconds to run all queries: 5.398 seconds
Minimum number of seconds to run all queries: 4.313 seconds
Maximum number of seconds to run all queries: 6.265 seconds
Number of clients running queries: 150
Average number of queries per client: 0Storage Engine Test
C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=3 --engine=innodb -uroot -proot
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine innodb
Average number of seconds to run all queries: 5.911 seconds
Minimum number of seconds to run all queries: 5.485 seconds
Maximum number of seconds to run all queries: 6.703 seconds
Number of clients running queries: 150
Average number of queries per client: 0C:\Users\zaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=3 --engine=myisam -uroot -proot
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine myisam
Average number of seconds to run all queries: 53.104 seconds
Minimum number of seconds to run all queries: 46.843 seconds
Maximum number of seconds to run all queries: 60.781 seconds
Number of clients running queries: 150
Average number of queries per client: 0
