In version 2.3 of Kafka, the Kafka connector has been greatly improved. First, when adding and deleting connectors, the way Kafka connectors handle tasks is modified. Previously, this action brought the whole system to a standstill, which has been criticized by the development and maintenance personnel. In addition, other problems frequently mentioned in the community have also been solved.
Incremental Cooperative Rebalancing in Kafka Connectors
The Kafka Connector Cluster consists of one or more working node processes that distribute the load of the connector in the form of tasks. When adding or removing connectors or working nodes, Kafka connectors try to rebalance these tasks. Before Kafka version 2.3, the cluster stops all tasks, recalculates the execution location of all tasks, and then restarts all tasks. Each rebalancing pauses all data entry and exit, usually for a short time, but sometimes for a period of time.
Now through KIP-415 Kafka 2.3 is replaced by incremental collaborative rebalancing, which will only rebalance tasks that need to be started, stopped or moved. For more information, see Here.
The following is a simple test with some connectors, where only one distributed Kafka connector working node is used, while the source uses kafka-connect-datagen, which generates random data according to a given pattern at a fixed time interval. At a fixed interval, it is possible to roughly calculate the time when the task stops due to rebalancing, because the generated message, as part of the Kafka message, contains a timestamp. These messages are then streamed into Elastic search, which is used not only because it is an easy-to-use receiver, but also because any pauses in production can be viewed by observing the timestamp of the source message.
The source end can be created in the following way:
curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/connectors/source-datagen-01/config \ -d '{ "connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector", "kafka.topic": "orders", "quickstart":"orders", "max.interval":200, "iterations":10000000, "tasks.max": "1" }'
The receiver is created as follows:
curl -s -X PUT -H "Content-Type:application/json" \ http://localhost:8083/connectors/sink-elastic-orders-00/config \ -d '{ "connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector", "topics": "orders", "connection.url": "http://elasticsearch:9200", "type.name": "type.name=kafkaconnect", "key.ignore": "true", "schema.ignore": "false", "transforms": "addTS", "transforms.addTS.type": "org.apache.kafka.connect.transforms.InsertField$Value", "transforms.addTS.timestamp.field": "op_ts" }'
Single message transformation is used here to elevate the timestamp of the Kafka message to the field of the message itself so that it can be exposed in Elastic search. Kibana is then used to plot, so that a drop in the number of messages generated can be displayed, consistent with where rebalancing occurs:
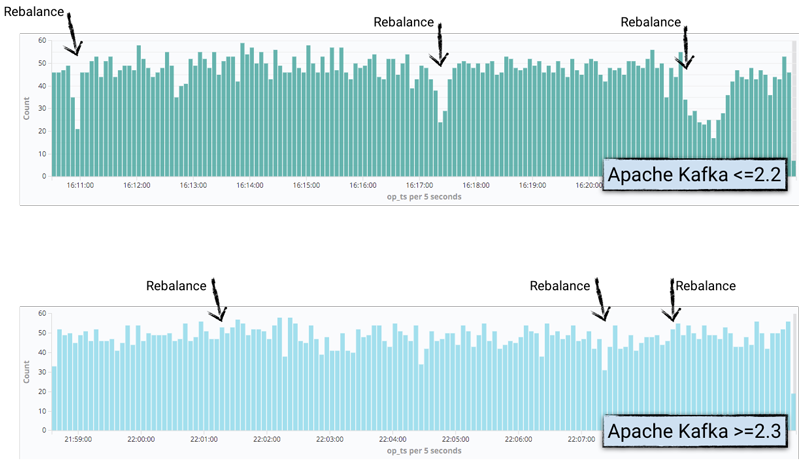
In the working node log of Kafka connector, activity and time can be viewed, and the behavior of Kafka version 2.2 and 2.3 can be compared:
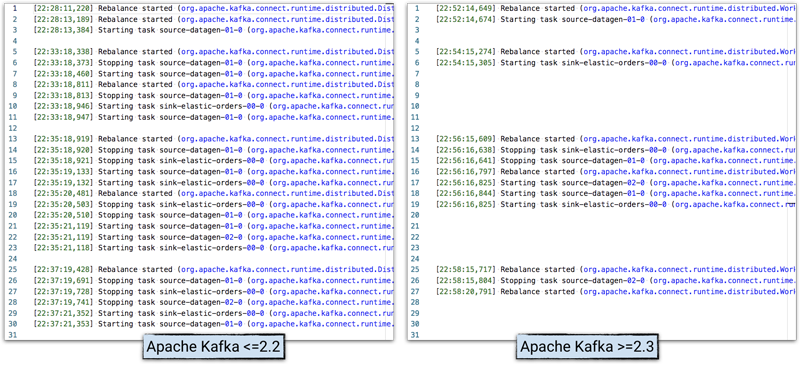
** Note: ** In order to clarify the problem, the log has been streamlined.
Improvement of Log
After the rebalancing problem (as mentioned above) has been greatly improved, the second major problem with Kafka connectors may be that it is difficult to determine which connector a message belongs to in the Kafka connector working node log.
Previously, messages in the log could be retrieved directly from the connector's tasks, such as:
INFO Using multi thread/connection supporting pooling connection manager (io.searchbox.client.JestClientFactory) INFO Using default GSON instance (io.searchbox.client.JestClientFactory) INFO Node Discovery disabled... (io.searchbox.client.JestClientFactory) INFO Idle connection reaping disabled... (io.searchbox.client.JestClientFactory)
What tasks do they belong to? Unclear. Maybe JestClient is related to Elastic search, maybe they come from Elastic search connectors, but now there are five different Elastic search connectors running, so which instance do they come from? Not to mention that connectors can have multiple tasks.
In Apache Kafka 2.3, the Mapping Diagnostic Context (MDC) log can be used to provide more context information in the log:
INFO [sink-elastic-orders-00|task-0] Using multi thread/connection supporting pooling connection manager (io.searchbox.client.JestClientFactory:223) INFO [sink-elastic-orders-00|task-0] Using default GSON instance (io.searchbox.client.JestClientFactory:69) INFO [sink-elastic-orders-00|task-0] Node Discovery disabled... (io.searchbox.client.JestClientFactory:86) INFO [sink-elastic-orders-00|task-0] Idle connection reaping disabled... (io.searchbox.client.JestClientFactory:98)
This log format change is disabled by default to maintain backward compatibility. To enable this improvement, you need to edit the etc/kafka/connect-log4j.properties file and modify log4j.appender.stdout.layout.ConversionPattern as follows:
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %X{connector.context}%m (%c:%L)%n
Through the environment variable CONNECT_LOG4J_APPENDER_STDOUT_LAYOUT_CONVERSION PATTERN, Docker image of Kafka connector This feature is also supported.
For more details, see KIP-449.
REST Improvement
KIP-465 Some convenient functions have been added to the / connectors REST endpoint. By passing other parameters, you can get more information about each connector without having to iterate over the results and make other REST calls.
For example, to query the status of all tasks before Kafka 2.3, the following operations must be performed, using xargs iteration output and calling status endpoints repeatedly:
$ curl -s "http://localhost:8083/connectors"| \ jq '.[]'| \ xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status"| \ jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| \ column -s : -t| sed 's/\"//g'| sort sink-elastic-orders-00 | RUNNING | RUNNING source-datagen-01 | RUNNING | RUNNING
Now with Kafka 2.3, you can make a single REST call using / connectors?expand=status plus some jq techniques to achieve the same effect as before:
$ curl -s "http://localhost:8083/connectors?expand=status" | \ jq 'to_entries[] | [.key, .value.status.connector.state,.value.status.tasks[].state]|join(":|:")' | \ column -s : -t| sed 's/\"//g'| sort sink-elastic-orders-00 | RUNNING | RUNNING source-datagen-01 | RUNNING | RUNNING
And / connectors?expand=status, which returns information about each connector, such as configuration, connector type, etc., or combines them:
$ curl -s "http://localhost:8083/connectors?expand=info&expand=status"|jq 'to_entries[] | [ .value.info.type, .key, .value.status.connector.state,.value.status.tasks[].state,.value.info.config."connector.class"]|join(":|:")' | \ column -s : -t| sed 's/\"//g'| sort sink | sink-elastic-orders-00 | RUNNING | RUNNING | io.confluent.connect.elasticsearch.ElasticsearchSinkConnector source | source-datagen-01 | RUNNING | RUNNING | io.confluent.kafka.connect.datagen.DatagenConnector
Kafka connector now supports client.id
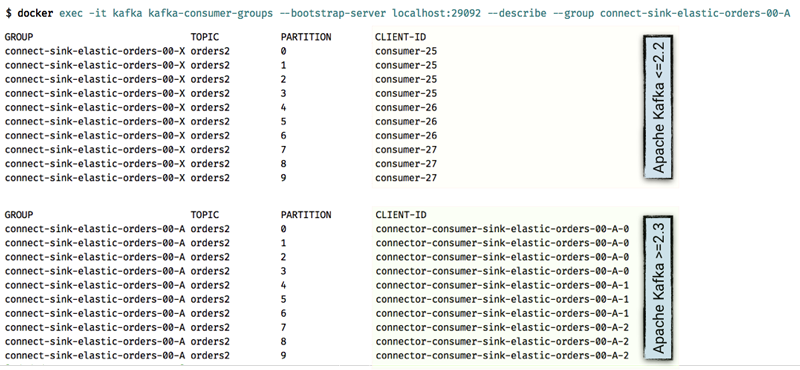
because KIP-411 Kafka connectors can now configure client.id for each task in a more useful way. Previously, you could only see consumer-25 consuming from a given partition as part of the consumer group of connectors, but now you can bind it directly back to a specific task, making troubleshooting and diagnosis easier.
Connector-level producer/consumer configuration override
A long-standing common requirement is the ability to override the use of Kafka connectors at both the receiving and source ends, respectively. Consumer Settings or Producer Settings . So far, they have adopted the values specified in the worker node configuration, and unless more worker nodes are generated, fine-grained control of content such as security subjects cannot be achieved.
In Kafka 2.3 KIP-458 Enables working nodes to allow overwriting of configurations. Conneor. client. config. override. policy is a new parameter with three options at the working node level:
| value | describe |
|---|---|
| None | Default policy, no overwriting of any configuration is allowed |
| Principal | Allow security.protocol, sasl.jaas.config, and sasl.mechanism to cover producers, consumers, and admin prefixes. |
| All | Allow coverage of all configurations of producer, consumer, and admin prefixes |
By setting the above parameters in the working node configuration, you can now override the configuration for each connector. Just provide the necessary parameters with a consumer.override (receiver) or producer.override (source) prefix, and you can also target Dead letter queue Use admin.override.
In the following example, when creating a connector, it will consume data from the current point of the topic, rather than reading all available data in the topic, by configuring consumer.override.auto.offset.reset to latest to override auto.offset.reset configuration.
curl -i -X PUT -H "Content-Type:application/json" \ http://localhost:8083/connectors/sink-elastic-orders-01-latest/config \ -d '{ "connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector", "topics": "orders", "consumer.override.auto.offset.reset": "latest", "tasks.max": 1, "connection.url": "http://elasticsearch:9200", "type.name": "type.name=kafkaconnect", "key.ignore": "true", "schema.ignore": "false", "transforms": "renameTopic", "transforms.renameTopic.type": "org.apache.kafka.connect.transforms.RegexRouter", "transforms.renameTopic.regex": "orders", "transforms.renameTopic.replacement": "orders-latest" }'
By checking the worker node log, you can see that the overwrite has taken effect:
[2019-07-17 13:57:27,532] INFO [sink-elastic-orders-01-latest|task-0] ConsumerConfig values: allow.auto.create.topics = true auto.commit.interval.ms = 5000 auto.offset.reset = latest [...]
You can see that this ConsumerConfig log entry is directly associated with the created connector, which proves the usefulness of the above MDC log record.
The second connector runs on the same topic but does not have consumer.override, thus inheriting the default value earliest:
[2019-07-17 13:57:27,487] INFO [sink-elastic-orders-01-earliest|task-0] ConsumerConfig values: allow.auto.create.topics = true auto.commit.interval.ms = 5000 auto.offset.reset = earliest [...]
By streaming data from the topic to Elastic search, you can check the impact of configuration differences.
$ curl -s "localhost:9200/_cat/indices?h=idx,docsCount" orders-latest 2369 orders-earliest 144932
There are two indexes: one injects fewer messages from the same topic, because the orders-latest index only injects messages to the topic after the connector is created; the other orders-earliest index, injected by a separate connector, uses the default configuration of the Kafka connector, that is, injects all new messages. Plus all the original news in the topic.