Editor of xl_echo, welcome to reprint, reprint please declare the source of the article. Welcome to add echo Wechat (micro signal: t2421499075) for communication and learning. Never lose a hundred battles, never claim to win, never fail, and always strive to move forward. —— This is the real strength!!
Read Suggestions: If the system has not done the relevant import and export, you need this magnitude to read the application of poi-ooxm at the bottom directly.
What is the maximum value that excel derives directly using poi? It is estimated that many people will not pay attention to this problem, because few businesses require Excel to export tens of thousands of data directly, or even may not have heard of Excel to export 100w data directly. Here we introduce a quotation scenario and the experience of blogger mining pit.
Requirement description
The company's requirement for the export of a bank's pipeline looks like a simple button, but there are several requirements for this requirement:
- The exported file format needs to be xlsx
- The minimum amount of each export is 5 w, and it is a table.
- When exporting, you need to download it in the browser in the form of file download.
Building Master Development Environment: jdk1.8, idea2018.1, spring boot 1.5x, dubbox
An attempt at poi-3.9
At the beginning, we did not pay too much attention to the number of 5w items. We used poi-3.9 directly. There are no problems in the whole development process. During the test, we encountered a problem that could not meet the requirements. When I downloaded 5w items directly, the program reported an error directly. After continuous testing, it is found that the maximum download value of 3.9 is 6000 + (the maximum value is related to the computer performance, but the discrepancy is not very large).
Test conclusion poi-3.9 ceiling 6000+
Obviously, the above attempt can not do the function related to the demand. After Baidu, we found that easyexcel is a good solution.
An attempt at easyexcel
The imported easyexcel is
<dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>1.1.1</version> </dependency>
When using this dependency, I refer to the code for the blogger. The code address is: https://blog.csdn.net/qq_35206261/article/details/88579151. When I moved his million-line solution to my project, it seemed that everything was okay. But when I started, I found that I had been reporting errors in java.lang.NoSuchMethodError. org.apache.poi.ss.usermodel.Font.setBold(Z)V. (The mistake here stems from the conflict of dependencies on project imports in the company's original project, which should not occur if the import and export related functions have not been done.) After investigation, it was found that the problem appeared in dependence. The company originally had import and export functions.
The dependencies introduced are as follows:
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.9</version> </dependency>
The conflict is shown in the following figure:
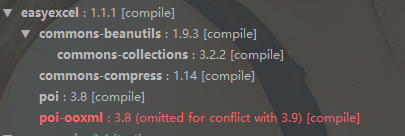
Point 1 poi-ooxml is not downward compatible
Click into the dependency discovery of easyexcel, which is based on the version of poi3.17 of the dependency. When I always thought that POI was downcompatible, the problems that eventually occurred during each boot and compilation pointed to the lack of downcompatibility.
The underlying poi-ooxml version is 3.17, as shown in the figure
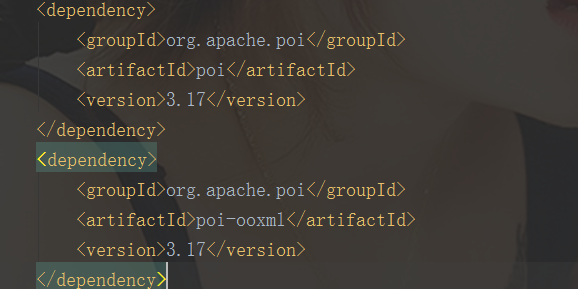
If we want to use easyexcel at this time, we need to change the version or solve the version compatibility problem of poi-ooxml.
After the incompatibility problem, looking at the company's original application of poi-ooxml, we decided to use the solution of poi-ooxml.
Application of poi-ooxml
After the above pits, I decided to use the compatible solution of poi-ooxml version 3.9. Baidu later found an application based on version 3.8. After the incompatibility above, I decided to give it a try. So I used a code in the blogger's article, the address of the article: https://blog.csdn.net/happyljw/article/details/52809244.
This article describes a way of thinking, but also gives a section of the implementation code provided by the blogger. Relatively speaking, if it is not a big problem as a test, it finally adjusts the steps of partial implementation according to the requirements, and adds some new implementation and limitations. The code is as follows:
@ResponseBody @RequestMapping(value = "/exportDataMoreThan1000") public void readMoreThan1000RowBySheet(@RequestParam(value = "start") Integer start, @RequestParam(value = "limit") Integer limit, HttpServletResponse response) throws Exception { //Only 100 objects are created in memory and temporary files are written. When more than 100 objects are created, unused objects in memory are released. Workbook wb = new SXSSFWorkbook(100); //Worksheet object final Sheet[] sheet = {null}; //Row object final Row[] nRow = {null}; //Column object final Cell[] nCell = {null}; //Head office number final int[] rowNo = {0}; //Page line number final int[] pageRowNo = {0}; List<BankDto> list = new ArrayList<>(50000); //data source list = BankServer.getList(); list.forEach(it -> { if (rowNo[0] % 10001 == 0) { sheet[0] = wb.createSheet("My first" + (rowNo[0] / 10001 + 1) + "A Workbook"); sheet[0] = wb.getSheetAt(rowNo[0] / 10001); //Reset the row number of the current worksheet to 0 whenever a new worksheet is created pageRowNo[0] = 0; } rowNo[0]++; nRow[0] = sheet[0].createRow(pageRowNo[0]++); //This is the key step. If not, there will be no watch. if (pageRowNo[0] == 1) { for (int j = 0; j < 9; j++) { nCell[0] = nRow[0].createCell(j); if (j == 0) nCell[0].setCellValue("number"); if (j == 1) nCell[0].setCellValue("number"); if (j == 2) nCell[0].setCellValue("number"); if (j == 3) nCell[0].setCellValue("number"); if (j == 4) nCell[0].setCellValue("number"); if (j == 5) nCell[0].setCellValue("number"); if (j == 6) nCell[0].setCellValue("number"); if (j == 7) nCell[0].setCellValue("number"); if (j == 8) nCell[0].setCellValue("Remarks"); } rowNo[0]++; nRow[0] = sheet[0].createRow(pageRowNo[0]++); } // Output each row with nine columns of data per row for (int j = 0; j < 9; j++) { nCell[0] = nRow[0].createCell(j); if (j == 0) nCell[0].setCellValue(it.getPaycode()); if (j == 1) nCell[0].setCellValue(it.getPaycode()); if (j == 2) nCell[0].setCellValue(it.getPaycode()); if (j == 3) nCell[0].setCellValue(it.getPaycode()); if (j == 4) nCell[0].setCellValue(it.getPaycode()); if (j == 5) nCell[0].setCellValue(it.getPaycode()); if (j == 6) nCell[0].setCellValue(it.getPaycode()); if (j == 7) nCell[0].setCellValue(it.getPaycode()); if (j == 8) nCell[0].setCellValue(it.getRemark()); } }); String fileName = "Bank Flow Meter.xlsx"; //Setting the request header response.setHeader("content-Type", "application/vnd.ms-excel"); response.setContentType("application/vnd.ms-excel;charset=utf-8"); response.setHeader("Content-Disposition", "attachment; filename=" + fileName + ".xlsx"); ServletOutputStream outputStream = response.getOutputStream(); wb.write(outputStream); outputStream.flush(); outputStream.close(); }
This simplifies the operation of the data source. If you need to modify it according to your own business, I review the operation of the data source relatively in my actual implementation. Not only do I make slicing requests (to avoid dubbox timeout), but also do a lot of data processing. One of the highlights of this operation is the segmentation of multiple shelets.
Note: The development environment here is jdk1.8
After completing the above coding, using tool testing, I found that I have achieved the functions I need. At present, there is no big problem with a download of less than 10 weeks. The measured data of 10 weeks is 20s. If the business logic is simpler, it will double the speed.
Summary:
- There are two universal solutions
-
- poi-ooxml
-
- easyexc
- It may be incompatible if one of them is used and attention should be paid to whether the other is introduced.
- Po-ooxml 3.9 and poi-ooxml 3.17 are not perfectly downward compatible
- poi3.17 Max download peak 6000+