The purpose of this paper is to generate the inverse document frequency of each word for a specific corpus. Then key words are extracted according to TF-IDF algorithm.
For reprinting, please indicate the source: Gaussic (Natural Language Processing) .
GitHub code: https://github.com/gaussic/tf-idf-keyword
participle
For the extraction of keywords in Chinese text, we need to perform word segmentation first. This paper uses a full-mode stuttering participler for word segmentation. One advantage of using full mode is that it can gain raw data. If you don't need to, you can change cut_all to the default False.
Remove some of the English and numbers, and retain only Chinese:
import jieba import re def segment(sentence, cut_all=True): sentence = re.sub('[a-zA-Z0-9]', '', sentence.replace('\n', '')) # filter return jieba.cut(sentence, cut_all=cut_all) # participle
Inverse Document Frequency Statistics in Corpus
Efficient File Reading
Read all text files in the specified directory and use a stuttering segmenter for word segmentation. IDF extracts about 800,000 texts based on THUCNews (Tsinghua News Corpus).
Based on the implementation of python generator, the following code can efficiently read text and segment words:
class MyDocuments(object): # memory efficient data streaming def __init__(self, dirname): self.dirname = dirname if not os.path.isdir(dirname): print(dirname, '- not a directory!') sys.exit() def __iter__(self): for dirfile in os.walk(self.dirname): for fname in dirfile[2]: text = open(os.path.join(dirfile[0], fname), 'r', encoding='utf-8').read() yield segment(text)
Inverse Document Frequency Statistics of Words
Statistics of how many documents each word appears in:
documents = MyDocuments(inputdir) # Exclusion of Chinese Punctuation Symbols ignored = {'', ' ', '', '. ', ': ', ',', ')', '(', '!', '?', '"', '"'} id_freq = {} # frequency i = 0 # Total number of documents for doc in documents: doc = (x for x in doc if x not in ignored) for x in doc: id_freq[x] = id_freq.get(x, 0) + 1 if i % 1000 == 0: # Output status every 1000 articles print('Documents processed: ', i, ', time: ', datetime.datetime.now()) i += 1
Calculate the inverse document frequency and store it
with open(outputfile, 'w', encoding='utf-8') as f: for key, value in id_freq.items(): f.write(key + ' ' + str(math.log(i / value, 2)) + '\n')
Inverse Document Frequency (IDF) Formula
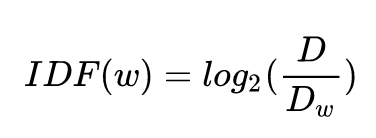
Among them, D denotes the total number of documents, and D w denotes how many documents w appears.
Running example:
Building prefix dict from the default dictionary ... Loading model from cache /var/folders/65/1sj9q72d15gg80vt9c70v9d80000gn/T/jieba.cache Loading model cost 0.943 seconds. Prefix dict has been built succesfully. Documents processed: 0 , time: 2017-08-08 17:11:15.906739 Documents processed: 1000 , time: 2017-08-08 17:11:18.857246 Documents processed: 2000 , time: 2017-08-08 17:11:21.762615 Documents processed: 3000 , time: 2017-08-08 17:11:24.534753 Documents processed: 4000 , time: 2017-08-08 17:11:27.235600 Documents processed: 5000 , time: 2017-08-08 17:11:29.974688 Documents processed: 6000 , time: 2017-08-08 17:11:32.818768 Documents processed: 7000 , time: 2017-08-08 17:11:35.797916 Documents processed: 8000 , time: 2017-08-08 17:11:39.232018
It takes about 3 seconds to process 1,000 documents and 40 minutes to process 800,000 documents.
TF-IDF keyword extraction
Drawing on the processing idea of stuttering participle, IDF file is loaded with IDFLoader:
class IDFLoader(object): def __init__(self, idf_path): self.idf_path = idf_path self.idf_freq = {} # idf self.mean_idf = 0.0 # mean value self.load_idf() def load_idf(self): # Load idf from a file cnt = 0 with open(self.idf_path, 'r', encoding='utf-8') as f: for line in f: try: word, freq = line.strip().split(' ') cnt += 1 except Exception as e: pass self.idf_freq[word] = float(freq) print('Vocabularies loaded: %d' % cnt) self.mean_idf = sum(self.idf_freq.values()) / cnt
Use TF-IDF to extract keywords:
TF-IDF formula:
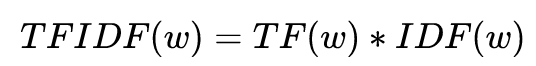
class TFIDF(object): def __init__(self, idf_path): self.idf_loader = IDFLoader(idf_path) self.idf_freq = self.idf_loader.idf_freq self.mean_idf = self.idf_loader.mean_idf def extract_keywords(self, sentence, topK=20): # Extraction of keywords # participle seg_list = segment(sentence) freq = {} for w in seg_list: freq[w] = freq.get(w, 0.0) + 1.0 # Statistical word frequency if '' in freq: del freq[''] total = sum(freq.values()) # Total number of words for k in freq: # Computing TF-IDF freq[k] *= self.idf_freq.get(k, self.mean_idf) / total tags = sorted(freq, key=freq.__getitem__, reverse=True) # sort if topK: # Return topK return tags[:topK] else: return tags
Use:
# idffile is the idf file path, document is the text path to be processed tdidf = TFIDF(idffile) sentence = open(document, 'r', encoding='utf-8').read() tags = tdidf.extract_keywords(sentence, topK)
Example output:
traffic Wing Traffic China Telecom telecom Guodian service day Wuhan information A citizen Trip Convenient people Wuhan Hotline access Traffic Radio real time see Branch Office Mobile phone