introduce
In recent years, with the increasing demand for reliable systems and infrastructure, the term "high availability" has become more and more popular. In distributed systems, high availability usually involves maximizing uptime and making the system fault-tolerant.
In high availability, a common practice is to use redundancy to minimize a single point of failure. Preparing redundancy for systems and services can be as simple as deploying more redundant copies behind the load balancer. Although such a configuration may be applicable to many applications, some use cases need to be carefully coordinated across replicas for the system to work properly.
Kubernetes controller deployment as multiple instances is a good example. In order to prevent any unexpected behavior, the leader election process must ensure that the leader is elected in the replica and is the only leader actively coordinating the cluster. Other instances should remain inactive, but be ready to take over when the leader instance fails.
Kubernetes' leader election
Kubernetes' leader election process is simple. It starts with the creation of the lock object, and the leader periodically updates the current timestamp to inform other copies about its leader. The lock object can be a Lease, ConfigMap, or Endpoint, or hold the identity of the current leader. If the leader fails to update the timestamp within a given time interval, it is considered to have crashed. At this time, the inactive copy competes to obtain the leader by updating the lock with its own identity. The pod that successfully obtains the lock will become a new leader.
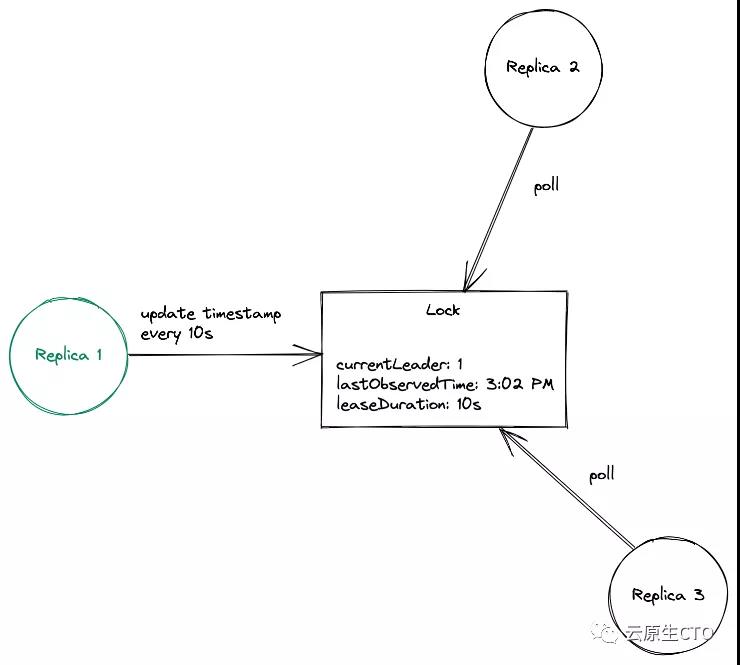
Before dealing with any code, look at how this process works! The first step is to establish a local Kubernetes cluster. I will use KinD, but you can also use your own k8s cluster.
$ kind create cluster Creating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.21.1) 🖼 ✓ Preparing nodes 📦 ✓ Writing configuration 📜 ✓ Starting control-plane 🕹️ ✓ Installing CNI 🔌 ✓ Installing StorageClass 💾 Set kubectl context to "kind-kind" You can now use your cluster with: kubectl cluster-info --context kind-kind Not sure what to do next? 😅 Check out https://kind.sigs.k8s.io/docs/user/quick-start/
The sample application used can be found here. It uses kubernetes / client go for leadership elections. Let's install the application on the cluster:
Example: https://github.com/mayankshah1607/k8s-leader-election
client-go: https://github.com/kubernetes/client-go
# Setup required permissions for creating/getting Lease objects $ kubectl apply -f rbac.yaml serviceaccount/leaderelection-sa created role.rbac.authorization.k8s.io/leaderelection-role created rolebinding.rbac.authorization.k8s.io/leaderelection-rolebinding created # Create deployment $ kubectl apply -f deploy.yaml deployment.apps/leaderelection created
This creates a deployment with three pods (replicas). If you wait a few seconds, you should see that they are Running.
❯ kubectl get pods NAME READY STATUS RESTARTS AGE leaderelection-6d5b456c9d-cfd2l 1/1 Running 0 19s leaderelection-6d5b456c9d-n2kx2 1/1 Running 0 19s leaderelection-6d5b456c9d-ph8nj 1/1 Running 0 19s
After running the pod, try to view the Lease lock objects they created as part of the leader election process.
$ kubectl describe lease my-lease Name: my-lease Namespace: default Labels: <none> Annotations: <none> API Version: coordination.k8s.io/v1 Kind: Lease Metadata: ... Spec: Acquire Time: 2021-10-23T06:51:50.605570Z Holder Identity: leaderelection-56457b6c5c-fn725 Lease Duration Seconds: 15 Lease Transitions: 0 Renew Time: 2021-10-23T06:52:45.309478Z
According to this, our current leader pod is leader election-56457bc5c-fn725. Verify this by viewing the pod log.
# leader pod $ kubectl logs leaderelection-56457b6c5c-fn725 I1023 06:51:50.605439 1 leaderelection.go:248] attempting to acquire leader lease default/my-lease... I1023 06:51:50.630111 1 leaderelection.go:258] successfully acquired lease default/my-lease I1023 06:51:50.630141 1 main.go:57] still the leader! I1023 06:51:50.630245 1 main.go:36] doing stuff... # inactive pods $ kubectl logs leaderelection-56457b6c5c-n857k I1023 06:51:55.400797 1 leaderelection.go:248] attempting to acquire leader lease default/my-lease... I1023 06:51:55.412780 1 main.go:60] new leader is %sleaderelection-56457b6c5c-fn725 # inactive pod $ kubectl logs leaderelection-56457b6c5c-s48kx I1023 06:51:52.905451 1 leaderelection.go:248] attempting to acquire leader lease default/my-lease... I1023 06:51:52.915618 1 main.go:60] new leader is %sleaderelection-56457b6c5c-fn725
Try to delete the leader pod to simulate a crash. If a new leader is selected, check the lead object
Code deep dive
See the following link for the code of the project
https://github.com/mayankshah1607/k8s-leader-election
The basic idea here is to use the distributed locking mechanism to determine which process becomes the leader. The process that obtains the lock will perform the required task. The main function is the entry of the application. Here, we create a reference to the lock object and start the leader election loop.
func main() {
var (
leaseLockName string
leaseLockNamespace string
podName = os.Getenv("POD_NAME")
)
flag.StringVar(&leaseLockName, "lease-name", "", "Name of lease lock")
flag.StringVar(&leaseLockNamespace, "lease-namespace", "default", "Name of lease lock namespace")
flag.Parse()
if leaseLockName == "" {
klog.Fatal("missing lease-name flag")
}
if leaseLockNamespace == "" {
klog.Fatal("missing lease-namespace flag")
}
config, err := rest.InClusterConfig()
client = clientset.NewForConfigOrDie(config)
if err != nil {
klog.Fatalf("failed to get kubeconfig")
}
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
lock := getNewLock(leaseLockName, podName, leaseLockNamespace)
runLeaderElection(lock, ctx, podName)
}
We first resolve the Lease name and Lease namespace flags to obtain the name and namespace of the lock object that the copy must use. POD_ The value of the name environment variable (in deploy.yaml manifest) will be used to identify the leader in the lead object. Finally, we use these parameters to create a lock object to start the leader election process.
deploy.yaml: https://github.com/mayankshah1607/k8s-leader-election/blob/master/deploy.yaml#L26
The runLeaderElection function is where we start the leader election cycle by calling RunOrDie. We pass a LeaderElectionConfig to it:
func runLeaderElection(lock *resourcelock.LeaseLock, ctx context.Context, id string) {
leaderelection.RunOrDie(ctx, leaderelection.LeaderElectionConfig{
Lock: lock,
ReleaseOnCancel: true,
LeaseDuration: 15 * time.Second,
RenewDeadline: 10 * time.Second,
RetryPeriod: 2 * time.Second,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(c context.Context) {
doStuff()
},
OnStoppedLeading: func() {
klog.Info("no longer the leader, staying inactive.")
},
OnNewLeader: func(current_id string) {
if current_id == id {
klog.Info("still the leader!")
return
}
klog.Info("new leader is %s", current_id)
},
},
})
}
Now, let's look at the implementation of RunOrDie in client go.
// RunOrDie starts a client with the provided config or panics if the config
// fails to validate. RunOrDie blocks until leader election loop is
// stopped by ctx or it has stopped holding the leader lease
func RunOrDie(ctx context.Context, lec LeaderElectionConfig) {
le, err := NewLeaderElector(lec)
if err != nil {
panic(err)
}
if lec.WatchDog != nil {
lec.WatchDog.SetLeaderElection(le)
}
le.Run(ctx)
}
It uses the leadelectorconfig we passed to it to create a * leadelector and call its Run method:
// Run starts the leader election loop. Run will not return
// before leader election loop is stopped by ctx or it has
// stopped holding the leader lease
func (le *LeaderElector) Run(ctx context.Context) {
defer runtime.HandleCrash()
defer func() {
le.config.Callbacks.OnStoppedLeading()
}()
if !le.acquire(ctx) {
return // ctx signalled done
}
ctx, cancel := context.WithCancel(ctx)
defer cancel()
go le.config.Callbacks.OnStartedLeading(ctx)
le.renew(ctx)
}
This method is responsible for running the leader election cycle. It first attempts to acquire the lock (using le.acquire). Once successful, it will run our previously configured OnStartedLeading callback and update the lead periodically. When the lock acquisition fails, it just runs the OnStoppedLeading callback and returns.
The most important part of the implementation of the get and update method is the call to tryAcquireOrRenew, which holds the core logic of the locking mechanism.
acquire: https://github.com/kubernetes/client-go/blob/56656ba0e04ff501549162385908f5b7d14f5dc8/tools/leaderelection/leaderelection.go#L243
renew: https://github.com/kubernetes/client-go/blob/56656ba0e04ff501549162385908f5b7d14f5dc8/tools/leaderelection/leaderelection.go#L265
tryAcquireOrRenew: https://github.com/kubernetes/client-go/blob/56656ba0e04ff501549162385908f5b7d14f5dc8/tools/leaderelection/leaderelection.go#L317
Optimistic locking (concurrency control)
The leader election process uses the atomic nature of the Kubernetes operation to ensure that no two copies can obtain a Lease at the same time (otherwise it may lead to competitive conditions and other unexpected behaviors!). Whenever a Lease is updated (updated or obtained), Kubernetes will also update the resourceVersion field on it. When another process tries to update Lease at the same time, Kubernetes checks whether the resourceVersion field of the updated object matches the current object -- if not, the update fails, so as to prevent concurrency problems!
summary
In this blog post, we discussed the idea of leader election and why it is important for high availability of distributed systems. This paper studies how to use Lease lock in Kubernetes to achieve this, and tries to use Kubernetes / client go library to achieve this. In addition, we try to understand how Kubernetes uses atomic operations and optimistic locking methods to prevent problems caused by concurrency.
Please also note that the code used in this article is not a production available solution, but is simply used to demonstrate the leader election in a simple way.
reference material
[1]
reference resources: https://kubernetes.io/blog/2016/01/simple-leader-election-with-kubernetes//
[2]
reference resources: https://carlosbecker.com/posts/k8s-leader-election//
[3]
reference resources: https://taesunny.github.io/kubernetes/kubernetes-controllers-leader-election-with-go-library/