characteristic:
one Simultaneous operation of multiple machines
two When the client submits a large file, the server should judge the size of the file, then divide the file and execute some scheduling logic. Suppose it is divided into four parts, the scheduling logic should schedule the four subsets of the file, which specific data server should be placed on, and return the IP addresses of the four data servers to the client
three The server records the correspondence between this file and the four dataserver s, which are called metadata. For example, a structured form like this:
id,filename,storage_path,total_size,splits,data_servers (there can be multiple), each data_ The specific location and each data stored on the server_ The offset position of the file fragment stored by the server
In other words, the metadata server process should calculate according to a file write request submitted by the client. What should be calculated?
- How big is this file
- It is divided into several parts, each of which calculates the offset according to bytes, startoffset~ endoffset, for example, is divided into four parts, which are 1-1000, 1001-2000, 2001-3000 and 3001-3555 bytes respectively. These four files are stored on four data servers
- Find out four data servers, for example, according to whether the data server is online, the remaining disk capacity of the data server, etc
- Return the ip addresses of the four data servers to the client
- The client connects four data servers at the same time, sends data to the four data servers respectively, writes the four subsets of files to the data server disk, and also remembers the specific storage locations on the four data servers, such as / data/companyname/projectname/abc/myfile001
four When the client starts to query the meta server for a file, the meta server should find out which data servers the file is stored on according to the previous metadata information, and then let the client establish a tcp connection with the four data servers and download the data at the same time. Finally, the client splices the file itself
five The whole cluster system should support the backup of copies of files. After the large files submitted by the above client are divided into four copies, they should be automatically backed up in the cluster, and they should be backed up across the data server. These backup information should be stored in the meta server database, and the meta server database must also be highly available
six Meta server must also be HA deployed
seven You should be able to expand the capacity of the meta server at any time
eight To expand the data server at any time, the meta server must know the details of each data server (health status, disk remaining space, cpu utilization, memory utilization, network card traffic, etc.), and there is a heartbeat packet between the data server and the meta server
Cluster deployment of MinIO
You can't start a process like a stand-alone test. You must deploy in a cluster. If docker compose is used, you can start multiple minIO docker containers on a stand-alone machine, but you can't deploy minIO across physical hosts. If docker swarm or K8s is used, you can deploy minIO across physical hosts. The following composition.yaml file explains everything.
version: '3.7'
# Settings and configurations that are common for all containers
x-minio-common: &minio-common
image: quay.io/minio/minio:RELEASE.2021-09-09T21-37-07Z
command: server --console-address ":9001" http://minio{1...4}/data{1...2}
expose:
- "9000"
- "9001"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
# starts 4 docker containers running minio server instances.
# using nginx reverse proxy, load balancing, you can access
# it through port 9000.
services:
minio1:
<<: *minio-common
hostname: minio1
volumes:
- data1-1:/data1
- data1-2:/data2
minio2:
<<: *minio-common
hostname: minio2
volumes:
- data2-1:/data1
- data2-2:/data2
minio3:
<<: *minio-common
hostname: minio3
volumes:
- data3-1:/data1
- data3-2:/data2
minio4:
<<: *minio-common
hostname: minio4
volumes:
- data4-1:/data1
- data4-2:/data2
nginx:
image: nginx:1.19.2-alpine
hostname: nginx
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
ports:
- "9000:9000"
- "9001:9001"
depends_on:
- minio1
- minio2
- minio3
- minio4
## By default this config uses default local driver,
## For custom volumes replace with volume driver configuration.
volumes:
data1-1:
data1-2:
data2-1:
data2-2:
data3-1:
data3-2:
data4-1:
data4-2:Start the distributed Minio instance with 8 nodes and 1 disk for each node. You need to run the following commands on all 8 nodes
export MINIO_ACCESS_KEY=<ACCESS_KEY>
export MINIO_SECRET_KEY=<SECRET_KEY>
minio server http://192.168.1.11/export1 http://192.168.1.12/export2 \
http://192.168.1.13/export3 http://192.168.1.14/export4 \
http://192.168.1.15/export5 http://192.168.1.16/export6 \
http://192.168.1.17/export7 http://192.168.1.18/export8However, it is strange to see that minio does not have the role of meta server. Are all nodes peer-to-peer? It seems that the core is that it uses a so-called erasure code mechanism
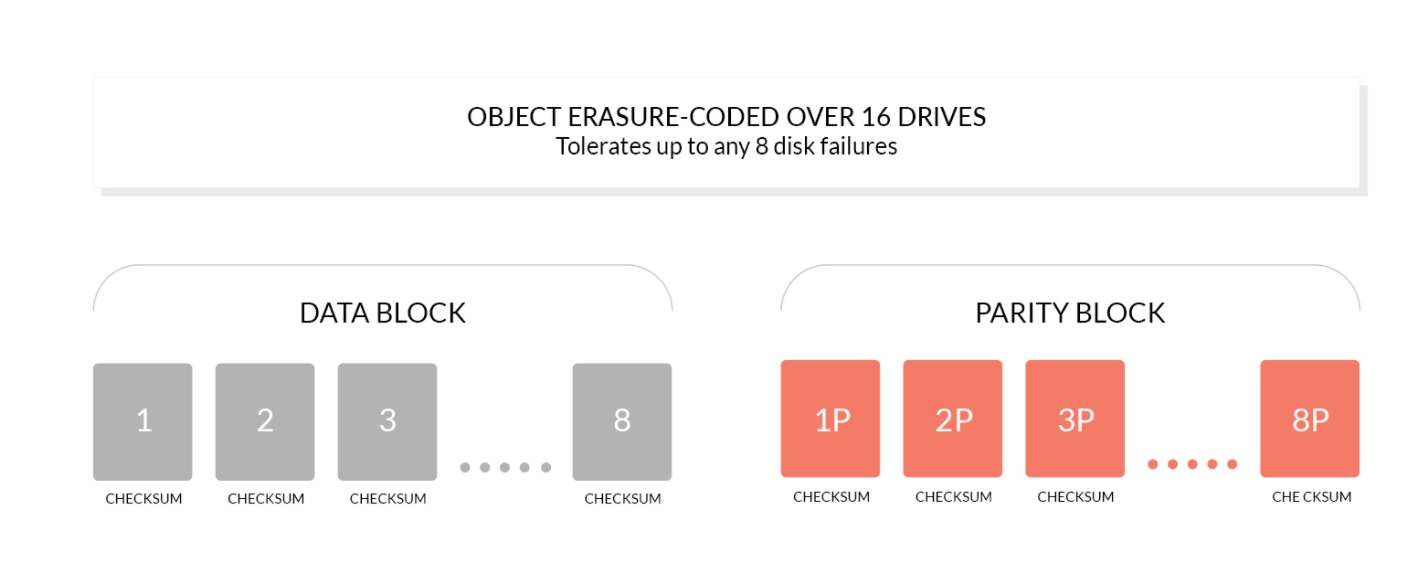
Erasure code is a mathematical algorithm to recover lost and damaged data. Minio uses Reed Solomon code to split the object into N/2 data and N/2 parity blocks. This means that if there are 12 disks, an object will be divided into 6 data blocks and 6 parity blocks. You can lose any 6 disks (whether they are stored data blocks or parity blocks), and you can still recover the data from the remaining disks
The working principle of erasure code is different from RAID or replication. For example, RAID6 can not lose data when two disks are lost, while Minio erasure code can still ensure data security when half of the disks are lost. Moreover, the Minio erasure code is used at the object level to recover one object at a time, while RAID is used at the volume level, and the data recovery time is very long. Minio encodes each object separately. Once the storage service is deployed, it usually does not need to replace the hard disk or repair. The design goal of Minio erasure code is to improve performance and use hardware acceleration as much as possible.
Bit attenuation, also known as Data Rot and Silent Data Corruption, is a serious data loss problem of hard disk data. The data on the hard disk may be damaged unknowingly, and there is no error log. As the saying goes, open guns are easy to hide and hidden arrows are difficult to prevent. This kind of secret mistake is more dangerous than the direct click of the hard disk. But don't be afraid, Minio erasure code adopts high speed HighwayHash Hash based checksum to prevent bit attenuation.