<link href="https://csdnimg.cn/public/favicon.ico" rel="SHORTCUT ICON">
<title>Image similarity algorithm--SIFT Algorithm details - jiutianhe Column - CSDN Blog</title>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/detail-fa42e278b4.min.css">
<script type="application/ld+json">{"@context":"https:\/\/ziyuan.baidu.com\/contexts\/cambrian.jsonld","@id":"https:\/\/blog.csdn.net\/jiutianhe\/article\/details\/39896931","appid":"1563894916825412","title":"\u56fe\u50cf\u76f8\u4f3c\u5ea6\u7b97\u6cd5--SIFT\u7b97\u6cd5\u8be6\u89e3 - jiutianhe\u7684\u4e13\u680f","images":["https:\/\/img-my.csdn.net\/uploads\/201204\/28\/1335624456_4441.jpg","https:\/\/img-my.csdn.net\/uploads\/201204\/29\/1335629778_5099.jpg","https:\/\/img-my.csdn.net\/uploads\/201204\/29\/1335629778_5099.jpg"],"pubDate":"2019-09-10T20:38:23"}</script>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/themes/skin3-template/skin3-template-c9d2f651cc.min.css">
<script type="text/javascript">
var username = "jiutianhe";
var blog_address = "https://blog.csdn.net/jiutianhe";
var static_host = "https://csdnimg.cn/release/phoenix/";
var currentUserName = "qq_25736745";
var isShowAds = true;
var isOwner = false;
var loginUrl = "http://passport.csdn.net/account/login?from=https://blog.csdn.net/jiutianhe/article/details/39896931"
var blogUrl = "https://blog.csdn.net/";
var curSkin = "skin3-template";
// Collection of required data
var articleTitle = "Image similarity algorithm--SIFT Algorithm details";
var articleDesc = "Detailed Explanation of Scale-invariant Feature Transform Matching Algorithms Scale Invariant Feature Transform(SIFT)Just For Funzdd zddmail@gmail.com or(zddhub@gmail.com)For beginners, from David G.Lowe There are many gaps between the paper and its realization. This article helps you to bridge the gap. If you study SIFI The purpose is to search, maybe OpenSSE";
// Data required for the fourth paradigm
var articleTitles = "Image similarity algorithm--SIFT Algorithm details - jiutianhe Column";
var nickName = "jiutianhe";
var isCorporate = false;
var subDomainBlogUrl = "https://blog.csdn.net/"
var digg_base_url = "https://blog.csdn.net/jiutianhe/phoenix/comment";
var articleDetailUrl = "https://blog.csdn.net/jiutianhe/article/details/39896931";
</script>
<script src="https://csdnimg.cn/public/common/libs/jquery/jquery-1.9.1.min.js" type="text/javascript"></script>
<!--js Quote-->
<script src="//g.csdnimg.cn/??fixed-sidebar/1.1.6/fixed-sidebar.js,report/1.0.6/report.js" type="text/javascript"></script>
<link rel="stylesheet" href="https://csdnimg.cn/public/sandalstrap/1.4/css/sandalstrap.min.css">
<style>
.MathJax, .MathJax_Message, .MathJax_Preview{
display: none
}
</style>
Image Similarity Algorithms--Detailed Explanation of SIFT Algorithms
Detailed Explanation of Scale-invariant Feature Transform Matching Algorithms
Scale Invariant Feature Transform(SIFT)
Just For Fun
zdd zddmail@gmail.com or (zddhub@gmail.com)
For beginners, there are many gaps from David G.Lowe's paper to implementation, and this article helps you bridge them.
If you're learning SIFI for retrieval purposes, maybe OpenSSE More suitable for you, welcome to use.
1. Overview of SIFT
Scale-invariant feature transform ation (SIFT) is a computer vision algorithm for detecting and describing local features in images. It searches for extreme points in spatial scales and extracts their position, scale and rotation invariants. This algorithm was published by David Lowe in 1999 and improved in 2004. Knot.
Its applications include object recognition, robot map sensing and navigation, image stitching, 3D model building, gesture recognition, image tracking and motion comparison.
This algorithm has its own patent, which is owned by the University of British Columbia.
Description and detection of local image features can help to identify objects. SIFT features are based on some interest points of local appearance of objects and are independent of image size and rotation. Tolerance of light, noise and some micro-angle changes is also quite high. Based on these characteristics, they are highly significant and relatively easy to extract. In the feature database with a large number of matrices, they are easy to identify objects and rarely misrecognize. Using SIFT feature description, the detection rate of partial object occlusion is quite high, and even more than three SIFT object features are enough to calculate the position and orientation. In the current computer hardware speed and small feature database conditions, the identification speed can be close to real-time operation. SIFT features have a large amount of information and are suitable for fast and accurate matching in massive databases.
The characteristics of SIFT algorithm are as follows:
1. SIFT feature is a local feature of image. It keeps invariant to rotation, scale scaling, brightness change and stable to a certain extent to view angle change, affine transformation and noise.
2. Distinctiveness is good and abundant in information. It is suitable for fast and accurate matching in massive feature databases.
3. Multivariability, even a few objects can produce a large number of SIFT eigenvectors.
4. High speed, the optimized SIFT matching algorithm can even meet the real-time requirements.
5. Extensibility, which can be easily combined with other forms of eigenvectors.
SIFT algorithm can solve the following problems:
The performance of image registration/target recognition and tracking is affected by the state of the target, the environment of the scene and the imaging characteristics of the imaging equipment. To some extent, SIFT algorithm can solve the following problems:
1. Rotation, zooming and translation of the target (RST)
2. Image Affine/Projection Transform (viewpoint)
3. illumination
4. occlusion
5. clutter
6. noise
The essence of SIFT algorithm is to find key points (feature points) in different scale spaces and calculate the direction of key points. The key points found by SIFT are some very prominent points, such as corners, edges, bright spots in dark areas and dark spots in bright areas, which are not changed by illumination, affine transformation and noise.
Lowe decomposes the SIFT algorithm into the following four steps:
1. Scale Space Extremum Detection: Search for image positions on all scales. Gauss differential function is used to identify potential points of interest for scale and rotation invariance.
2. Key Point Location: At each candidate position, the position and scale are determined by a fine fitting model. The selection of key points depends on their stability.
3. Direction determination: Based on the local gradient direction of the image, one or more directions are assigned to each key point position. All subsequent operations on image data are transformed relative to the direction, scale and location of key points, thus providing invariance for these transformations.
4. Key Point Description: In the neighborhood around each key point, the local gradient of the image is measured on the selected scale. These gradients are transformed into a representation that allows for larger local shape deformations and light changes.
Following Lowe's steps, referring to Rob Hess and Andrea Vedaldi source code, this paper describes the implementation process of SIFT algorithm in detail.
2. Gauss ambiguity
SIFT algorithm searches for key points in different scale spaces, and the acquisition of scale space needs to be realized by using Gaussian ambiguity. Lindeberg et al. have proved that Gaussian convolution kernel is the only transform core and the only linear kernel to realize scale transformation. In this section, we first introduce the Gauss fuzzy algorithm.
2.1 Two-Dimensional Gauss Function
Gauss blurring is an image filter. It uses normal distribution (Gauss function) to calculate the fuzzy template, and uses the template to convolute with the original image to achieve the purpose of blurring the image.
The normal distribution equation in N-dimensional space is as follows:
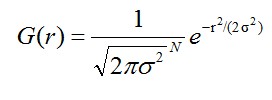 (1-1)
(1-1)
Among them,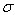 It is the standard deviation of the normal distribution.The bigger the value, the blurred (smooth) the image. r is a fuzzy radius, which refers to the distance from the template element to the center of the template. If the size of two-dimensional template is m*n, then the corresponding Gauss formula of elements (x,y) on the template is:
It is the standard deviation of the normal distribution.The bigger the value, the blurred (smooth) the image. r is a fuzzy radius, which refers to the distance from the template element to the center of the template. If the size of two-dimensional template is m*n, then the corresponding Gauss formula of elements (x,y) on the template is:
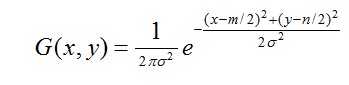 (1-2)
(1-2)
In two-dimensional space, the contour of the surface generated by this formula is a concentric circle with normal distribution from the center, as shown in Figure 2.1. The convolution matrix composed of non-zero-distributed pixels is transformed from the original image. The values of each pixel are the weighted average of the neighboring pixel values. The value of the original pixel has the largest Gauss distribution value, so it has the largest weight. As the adjacent pixels get farther and farther from the original pixel, their weight becomes smaller and smaller. In this way, the edge effect is preserved more effectively than other equalized fuzzy filters.
In theory, the distribution of each point in the image is not zero, which means that the calculation of each pixel needs to include the whole image. In practical applications, when calculating the discrete approximation of Gauss function, the pixels beyond the approximate 3_distance can be regarded as ineffective, and the calculation of these pixels can be ignored. Usually, the image processing program only needs calculation.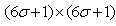 The matrix can guarantee the influence of the relevant pixels.
The matrix can guarantee the influence of the relevant pixels.
2.2 Two-Dimensional Gauss Blurring of Image
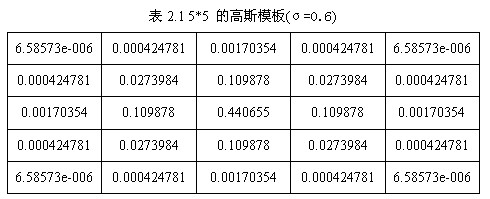
According to the value of_, the size of Gauss template matrix is calculated.(By using formula (1-2) to calculate the value of the Gauss template matrix and convoluting the original image, the smooth (Gauss blurred) image of the original image can be obtained. In order to ensure that the elements in the template matrix are between [0,1], it is necessary to normalize the template matrix. The 5*5 Gauss template is shown in Table 2.1.
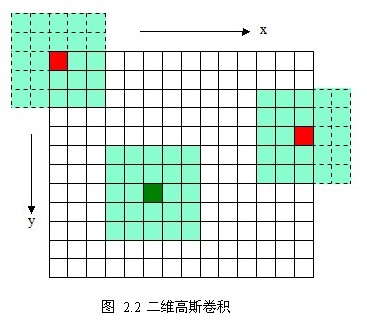
The following figure is a 5*5 Gauss template convolution calculation sketch. The Gauss template is centrally symmetric.

2.3 Separated Gauss Fuzzy
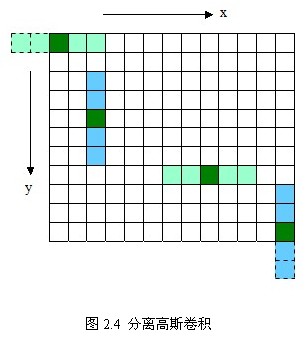
As shown in Figure 2.3, the blurred image is achieved by using two-dimensional Gauss template, but the edge image is missing due to the relationship between the template matrix (2.3b, c).The larger the size, the more missing pixels, the more black edges (2.3 d) will be caused by discarding the template. More importantly, when it becomes larger, the amount of operation of Gauss template (Gauss kernel) and convolution will be greatly increased. According to the separability of Gauss function, two-dimensional Gauss fuzzy function can be improved.
The separability of Gauss function means that the effect obtained by using two-dimensional matrix transformation can also be obtained by one-dimensional Gauss matrix transformation in horizontal direction and one-dimensional Gauss matrix transformation in vertical direction. From a computational point of view, this is a useful feature because it only requires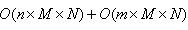 Subcomputations, and two-dimensional indivisible matrices are required
Subcomputations, and two-dimensional indivisible matrices are required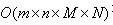 Secondly, m, n is the dimension of the Gauss matrix and M, N is the dimension of the two-dimensional image.
Secondly, m, n is the dimension of the Gauss matrix and M, N is the dimension of the two-dimensional image.
In addition, two one-dimensional Gauss convolutions will eliminate the edges generated by two-dimensional Gauss matrix. (Discussions on edge removal are shown in Figure 2.4 below. For dotted boxes, which are part of the template matrix beyond the boundary, convolution calculation will not be done. In Figure 2.4, the first template 1*5 in the x direction will degenerate into a template 1*3 and convolute only the part inside the image. )

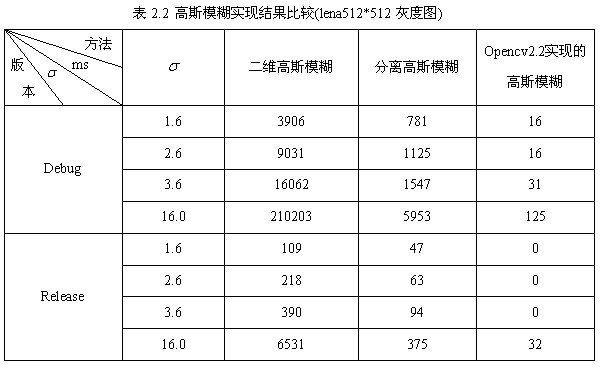
Appendix 1 is a two-dimensional Gaussian ambiguity and separated Gaussian ambiguity implemented by opencv2.2. Table 2.2 compares the two methods mentioned above with the Gauss ambiguity program implemented by opencv2.3 open source library.
3. Extremum Detection in Scale Space
Scale space is represented by a Gauss pyramid. Tony Lindeberg points out that the scale normalized Laplacion of Gaussian operator has real scale invariance. Lowe uses the Gauss difference pyramid to approximate the LoG operator to detect the key points of stability in the scale space.
3.1 Scale Space Theory
The idea of scale space was first put forward by Iijima in 1962. It has been widely used in computer vision neighborhoods since it was popularized by witkin and Koenderink.
The basic idea of scale space theory is to introduce a parameter which is regarded as scale in image information processing model, obtain multi-scale space representation sequence by continuously changing scale parameters, extract the principal contour of scale space from these sequences, and use the principal contour as a feature vector to realize the edge. Corner detection and feature extraction at different resolutions.
Scale space method incorporates the traditional single-scale image information processing technology into the dynamic analysis framework with changing scales, which makes it easier to acquire the essential features of images. In scale space, the blurring degree of each scale image gradually increases, which can simulate the formation process of the target on the retina from near to far distance.
Scale space satisfies visual invariance. The visual interpretation of the invariance is as follows: when we observe an object with our eyes, on the one hand, the brightness level and contrast of the retina perception image are different when the illumination conditions of the background of the object change. Therefore, it is required that the analysis of the image by the scale space operator is not affected by the changes of the gray level and contrast of the image. That is to say, it satisfies the invariance of gray scale and contrast. On the other hand, relative to a fixed coordinate system, when the relative position between the observer and the object changes, the position, size, angle and shape of the image perceived by the retina are different. Therefore, the scale space operator is required to analyze the image irrespective of its position, size, angle and affine transformation. Foot translation invariance, scale invariance, Euclidean invariance and affine invariance.
Representation of 3.2 Scale Space
A scale space of an image,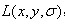 Gauss function defined as a scale of change
Gauss function defined as a scale of change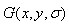 And original image
And original image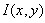 Convolution.
Convolution.
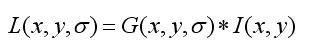 (3-1)
(3-1)
Where * denotes convolution operations,
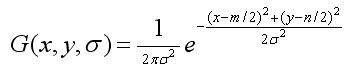 (3-2)
(3-2)
Similar to formula (1-2), m, n denotes the dimension of the Gauss template.Confirm). (x, y) represents the pixel position of the image.It is a scale space factor. The smaller the value, the less the image is smoothed, the smaller the corresponding scale. Large scale corresponds to the general features of the image, and small scale corresponds to the details of the image.
Construction of 3.3 Gauss Pyramid
Scale space is represented by a Gauss pyramid in its implementation. The construction of the Gauss pyramid is divided into two parts:
1. Gauss blurring on different scales of the image;
2. Sample the image downward (separated point sampling).
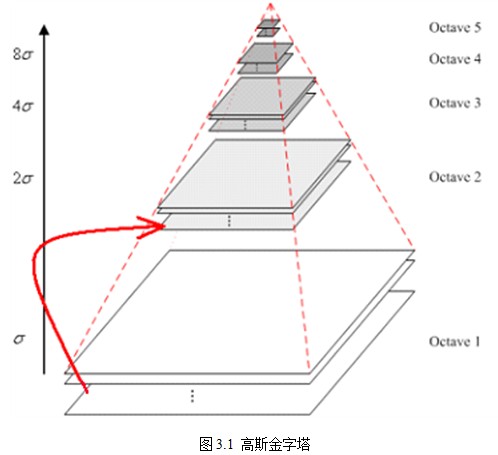
The pyramid model of an image refers to a pyramid model consisting of a series of images of different sizes, from large to small and from bottom to top. The original image is the first layer of the pyramid. The new image obtained by each downsampling is one layer of the pyramid (one image per layer). Each pyramid has n layers. The pyramid layers are determined by the original size of the image and the size of the image on the top of the pyramid. The calculation formulas are as follows:
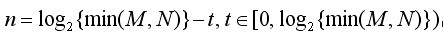 (3-3)
(3-3)
M, N are the size of the original image and t is the logarithmic value of the minimum dimension of the tower top image. For example, for images with size 512*512, the sizes of the images of the upper layers of the pyramid are shown in Table 3.1. When the image of the top of the pyramid is 4*4, n=7, and when the image of the top of the pyramid is 2*2, n=8.

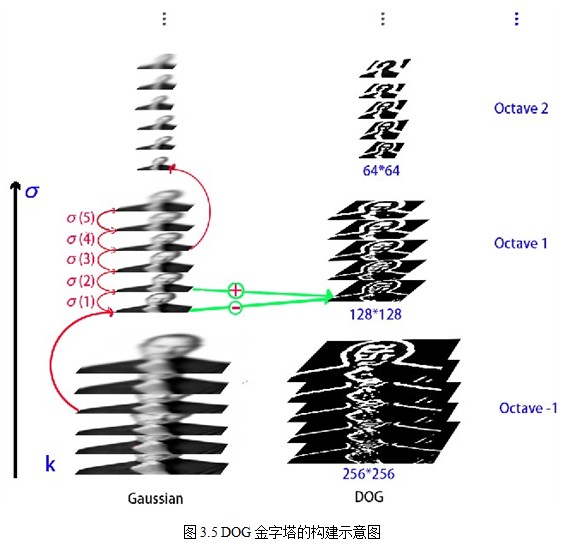
In order to make the scale reflect its continuity, the Gauss pyramid adds the Gauss filter on the basis of simple down-sampling. As shown in Figure 3.1, the image of each layer of the pyramid is blurred by using different parameters, so that each layer of the pyramid contains multiple Gauss blurred images. The pyramid is called an Octave. Each layer of the pyramid has only one set of images. The number of arrays is equal to the number of pyramid layers. The formula (3-3) is used to calculate the image. Each group contains multiple images (also known as Layer Interval). In addition, the initial image (bottom image) of a group of images on the Gauss pyramid is sampled from the reciprocal third image of the previous group.
Note: Because the images in the group are overlapped by layers, the images in the group are also called multi-layers. In order to avoid confusion with the concept of pyramid layer, in this paper, if the number of pyramid layers is not specified, the layers generally refer to the images in the group.
Note: As shown in Section 3.4, in order to detect the extremum points of S scales in each group, the DOG pyramid requires S+2-layer images for each group, while the DOG pyramid is subtracted from two adjacent layers of the Gauss pyramid, the Gauss pyramid needs S+3-layer images for each group, and the actual calculation time S is between 3 and 5. When S=3 is taken, it is assumed that the Gauss pyramid storage index is as follows:
Group 0 (i.e. Group-1): 0 1 2 3 4 5
Group 1: 67 8 9 10 11
Group 2:
Then the first picture in the second group is sampled from the image with index 9 in the first group, and the others are similar.
3.4 Gauss difference pyramid
In 2002, Mikolajczyk found Gaussian Laplace function with normalized scales in detailed experimental comparisons.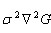 Compared with other feature extraction functions, such as gradient, Hessian or Harris angle features, the maximum and minimum of the proposed method can produce the most stable image features.
Compared with other feature extraction functions, such as gradient, Hessian or Harris angle features, the maximum and minimum of the proposed method can produce the most stable image features.
Lindeberg discovered Gauss Difference of Gaussian (DOG operator) and scale normalized Gauss Laplace function as early as 1994.Very similar. among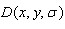 andThe relationship can be derived from the following formula:
andThe relationship can be derived from the following formula:
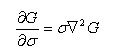
When differential approximation is used instead of differential approximation, there are:
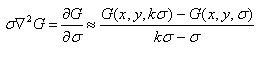
Therefore, there are
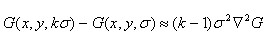
k-1 is a constant and does not affect the location of the extreme point.
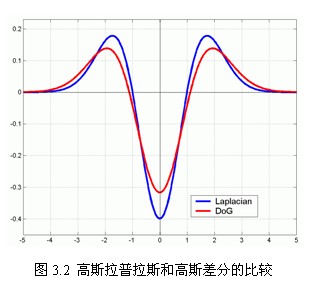
As shown in Figure 3.2, the red curve represents the Gauss difference operator, while the blue curve represents the Gauss Laplacian operator. Lowe uses a more efficient Gauss difference operator instead of Laplacian operator for extremum detection, as follows:
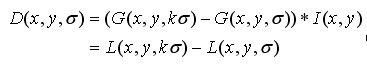 (3-4)
(3-4)
In practical calculation, the Gauss difference image is obtained by subtracting two adjacent layers of image in each group of the Gauss pyramid. As shown in Figure 3.3, the extremum detection is carried out.
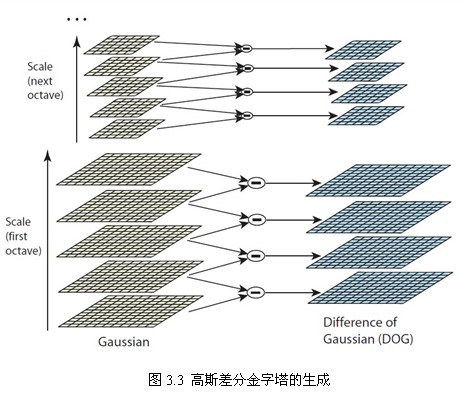
3.5 Spatial Extreme Point Detection (Preliminary Exploration of Key Points)
The key point is composed of local extremum points in DOG space. The preliminary exploration of key points is accomplished by comparing the two adjacent layers of DoG images in the same group. In order to find the extremum points of DoG function, each pixel point should be compared with all its adjacent points to see whether it is larger or smaller than its adjacent points in image domain and scale domain. As shown in Figure 3.4, the middle detection point is compared with 26 points corresponding to 8 adjacent points of the same scale and 9*2 points corresponding to the upper and lower adjacent scales to ensure that extreme points are detected in both scale space and two-dimensional image space.
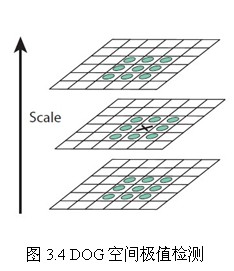
For the comparison of adjacent scales, as shown in Figure 3.3, each group of four-layer Gauss difference pyramids on the right side can only detect the extreme points of two scales in the middle two layers, while the other scales can only be detected in different groups. In order to detect the extremum points of S scales in each group, the DOG pyramids need S+2-layer images for each group, while the DOG pyramids are subtracted from the two adjacent layers of the Gauss pyramid, then the Gauss pyramids need S+3-layer images for each group. In actual calculation, S is between 3 and 5.
Of course, the extremum points generated by this method are not all stable feature points, because some extremum points have weak response, and DOG operators will produce strong edge response.
3.6 Parameters to be determined in constructing scale space
- Scale space coordinates
O-group (octave) number
S-group Inner Layer Number
In the above scale space, O and S,The relationship is as follows:
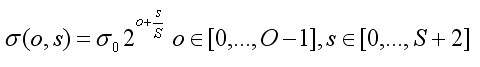 (3-5)
(3-5)
among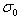 It is the base level scale, o is the index of group octave, s is the index of group inner layer. Scale coordinates of key pointsIt is calculated by formula (3-5) according to the group where the key points are located and the layer within the group.
It is the base level scale, o is the index of group octave, s is the index of group inner layer. Scale coordinates of key pointsIt is calculated by formula (3-5) according to the group where the key points are located and the layer within the group.
At the beginning of building the Gauss pyramid, the input image should be blurred in advance as the image of the 0th layer of the 0th group, which is equivalent to discarding the highest spatial sampling rate. Therefore, the usual method is to double the scale of the image to generate group - 1. We assume that the initial input image has been processed to combat confusion.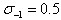 Gauss blur, if the size of the input image is doubled by bilinear interpolation, is equivalent to
Gauss blur, if the size of the input image is doubled by bilinear interpolation, is equivalent to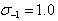 .
.
The k in formula (3-4) is the reciprocal of the total number of layers in the group, i.e.
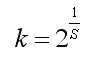 (3-6)
(3-6)
When constructing the Gauss pyramid, the scale coordinates of each layer in the group are calculated according to the following formula:
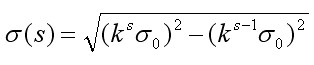 (3-7)
(3-7)
amongInitial scale, lowe st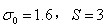 s is the intra-group index and the intra-group scale coordinates of the same layer in different groups
s is the intra-group index and the intra-group scale coordinates of the same layer in different groups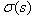 The same. The next image in the group is pressed by the previous image.Gauss ambiguity is obtained. Formula (3-7) is used to generate Gauss images of different scales in a group at one time, while in calculating the scales of a layer of images in a group, the following formulas are used directly to calculate the scales:
The same. The next image in the group is pressed by the previous image.Gauss ambiguity is obtained. Formula (3-7) is used to generate Gauss images of different scales in a group at one time, while in calculating the scales of a layer of images in a group, the following formulas are used directly to calculate the scales:
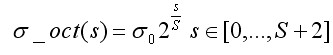 (3-8)
(3-8)
The size of the sampling window is determined by the inner scale in the direction assignment and feature description.
Formula (3-4) can be recorded as
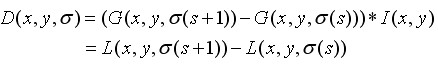 (3-9)
(3-9)
Figure 3.5 is a sketch of the DOG pyramid. The original image uses 128*128 jobs images to double the size of the pyramid.
4. Key Point Location
The extremum points detected by the above methods are the extremum points in discrete space. Fitting the three-dimensional quadratic function to determine the location and scale of the key points accurately, and removing the low contrast key points and unstable edge response points (because DoG operator will produce strong edge response), in order to enhance matching stability and improve anti-noise. Sound ability.
4.1 Precise Location of Key Points
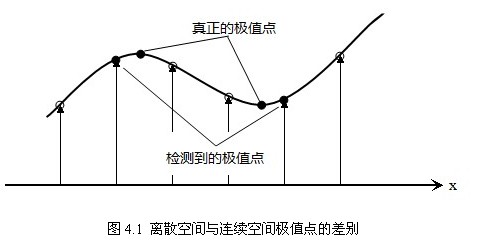
The extremum point in discrete space is not the real extremum point. Figure 4.1 shows the difference between the extremum point in discrete space of two-dimensional function and that in continuous space. The method of using known discrete space points to interpolate the continuous space extremum points is called Sub-pixel Interpolation.
In order to improve the stability of key points, it is necessary to fit the DoG function in scale space. The Taylor expansion (fitting function) of DoG function in scale space is as follows:
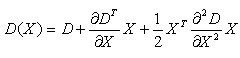 (4-1)
(4-1)
Among them,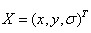 . By deriving and making the equation equal to zero, the offset of the extreme point can be obtained as follows:
. By deriving and making the equation equal to zero, the offset of the extreme point can be obtained as follows:
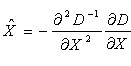 (4-2)
(4-2)
Corresponding to the extreme point, the value of the equation is:
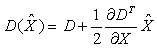 (4-3)
(4-3)
Among them,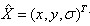 An offset representing the relative interpolation center when it is greater than 0.5 in any dimension (i.e., x or y orIt means that the interpolation center has shifted to its adjacent point, so the position of the current key point must be changed. At the same time, interpolation is repeated in the new position until convergence; it may exceed the set number of iterations or beyond the boundaries of the image. At this time, such points should be deleted and iterated five times in Lowe. In addition,
An offset representing the relative interpolation center when it is greater than 0.5 in any dimension (i.e., x or y orIt means that the interpolation center has shifted to its adjacent point, so the position of the current key point must be changed. At the same time, interpolation is repeated in the new position until convergence; it may exceed the set number of iterations or beyond the boundaries of the image. At this time, such points should be deleted and iterated five times in Lowe. In addition,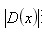 Too small points are vulnerable to noise interference and become unstable, so willExtremum deletion is less than an empirical value (Lowe paper uses 0.03, Rob Hess et al. uses 0.04/S for implementation). At the same time, the precise position of feature points (in-situ location plus fitting offset) and scale are obtained during the process.(
Too small points are vulnerable to noise interference and become unstable, so willExtremum deletion is less than an empirical value (Lowe paper uses 0.03, Rob Hess et al. uses 0.04/S for implementation). At the same time, the precise position of feature points (in-situ location plus fitting offset) and scale are obtained during the process.( ).
).
4.2 Eliminating Edge Response
The extremum of a poorly defined Gauss difference operator has a larger principal curvature across the edge and a smaller principal curvature in the direction of the vertical edge.
DOG operator will produce strong edge response, and unstable edge response points need to be eliminated. The H essian matrix at the feature points is obtained, and the principal curvature is obtained through a Hessian matrix H of 2x2:
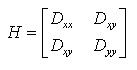 (4-4)
(4-4)
The eigenvalues alpha and beta of H represent the gradients in the x and y directions.
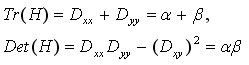 (4-5)
(4-5)
Represents the sum of the diagonal elements of matrix H and the determinant of matrix H. Suppose that the eigenvalue of alpha is larger, but that of beta is smaller.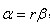 Then
Then
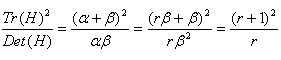 (4-6)
(4-6)
The derivative is estimated from the adjacent difference of the sampling point, which is explained in the next section.
The principal curvature of D is proportional to the eigenvalue of H. If the maximum eigenvalue of a and the minimum eigenvalue of beta are given, then the formula is given.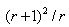 When the two eigenvalues are equal, the value is the smallest and increases with the increase of the eigenvalues. The larger the value, the larger the ratio of the two eigenvalues, that is, the greater the gradient value in one direction, and the smaller the gradient value in the other direction, which is exactly the case at the edge. Therefore, in order to eliminate the edge response points, it is necessary to make the ratio less than a certain threshold. Therefore, in order to detect whether the principal curvature is in a certain range r, only detection is needed.
When the two eigenvalues are equal, the value is the smallest and increases with the increase of the eigenvalues. The larger the value, the larger the ratio of the two eigenvalues, that is, the greater the gradient value in one direction, and the smaller the gradient value in the other direction, which is exactly the case at the edge. Therefore, in order to eliminate the edge response points, it is necessary to make the ratio less than a certain threshold. Therefore, in order to detect whether the principal curvature is in a certain range r, only detection is needed.
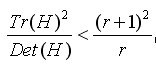 (4-7)
(4-7)
Formula (4-7) retains the key points and eliminates them.
In Lowe's article, take r = 10. Figure 4.2 shows the distribution of key points on the right after eliminating the edge response.

4.3 Finite Difference Method for Derivatives
The finite difference method approximates the continuous values of independent variables in differential equations by the function values corresponding to the discrete values of variables. In the finite difference method, we abandon the feature that independent variables can take continuous values in differential equations, and focus on the corresponding function values after discrete values of independent variables. However, in principle, this method can still achieve any satisfactory calculation accuracy. Because the continuous numerical solution of the equation can be approximated by reducing the interval between discrete values of independent variables or by interpolating functions at discrete points. This method has been developed with the birth and application of computers. Its calculation format and program design are intuitive and simple, so it is widely used in computational mathematics.
The operation of the finite difference method is divided into two parts:
1. The differential equation is replaced by the difference, and the continuous variable is discretized to obtain the mathematical form of the difference equation system.
2. Solving difference equations.
The first and second derivatives of a function at point x can be approximately expressed by the difference of the value of the function at two points adjacent to it. For example, for a single variable function f(x), x is a continuous variable defined on interval [a,b], with step size.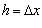 By discretizing the interval [a,b], we will get a series of nodes.
By discretizing the interval [a,b], we will get a series of nodes.
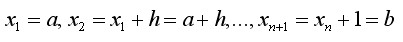
Then the approximate values of f(x) at these points are obtained. Obviously, the smaller the step h, the better the accuracy of the approximate solution. And node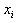 The adjacent nodes are
The adjacent nodes are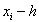 and
and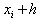 So at the nodeThe difference can be constructed as follows:
So at the nodeThe difference can be constructed as follows:
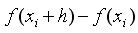 First-order forward difference of nodes
First-order forward difference of nodes
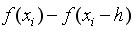 First-order backward difference of nodes
First-order backward difference of nodes
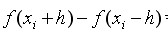 First order central difference of nodes
First order central difference of nodes
In this paper, the central difference method is used to solve the derivatives used in Section 4 by Taylor expansion, and the following derivations are made.
The function f(x) is inThe Taylor expansion of the region is:
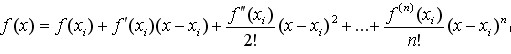 (4-8)
(4-8)
Then,
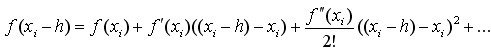 (4-9)
(4-9)
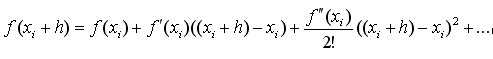 (4-10)
(4-10)
Ignoring the term after h-square, the simultaneous equation (4-9), (4-10) solves the system of equations.
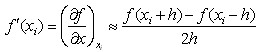 (4-11)
(4-11)
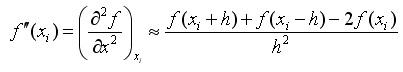 (4-12)
(4-12)
The Taylor expansion of binary functions is as follows:
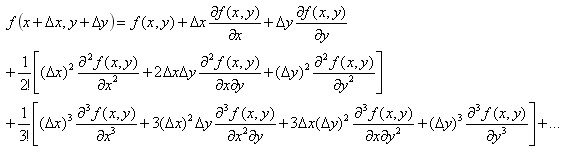
take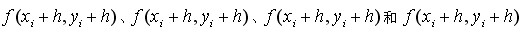 Two-dimensional mixed partial derivatives are obtained by neglecting the minor terms of the simultaneous solution equation after expansion as follows:
Two-dimensional mixed partial derivatives are obtained by neglecting the minor terms of the simultaneous solution equation after expansion as follows:
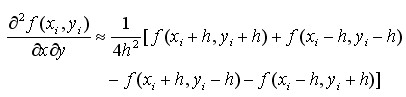 (4-13)
(4-13)
In summary, all derivatives encountered in 4.1 and 4.2 are derived. Similarly, the approximate difference representation of arbitrary partial derivatives can be obtained by using multivariate Taylor expansion.
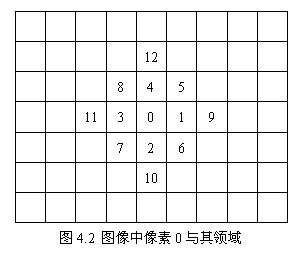
In image processing, Take h=1. In the image shown in Figure 4.2, the basic midpoint derivative formula of pixel 0 is arranged as follows:
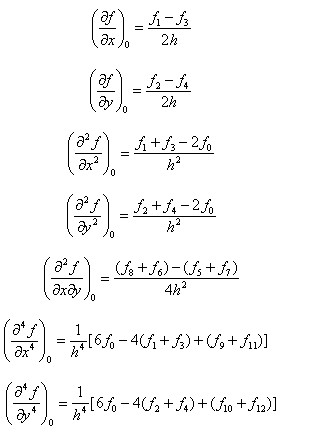
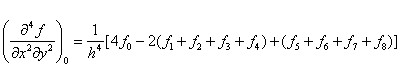
4.4 Inverse Formula of Third Order Matrix
The inversion algorithms of higher-order matrices mainly include normalization method and elimination method. Now, the inversion formulas of third-order matrices are summarized as follows:
If matrix
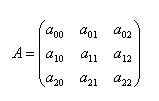
Reversible, that is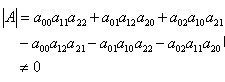 At that time,
At that time,
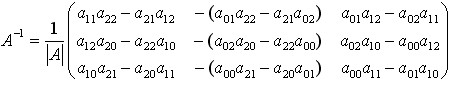 (4-14)
(4-14)
5. Direction allocation of key points
In order to make the descriptor rotation invariant, it is necessary to assign a reference direction to each key point by using the local features of the image. The method of image gradient is used to find the stable direction of local structure. For the key points detected in the DOG pyramid, the gradient and direction distribution characteristics of the pixels in the 3 neighborhood window of the Gauss pyramid image are collected. The modulus and direction of the gradient are as follows:
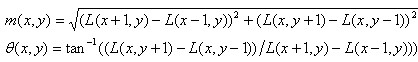 (5-1)
(5-1)
L is the scale space value of the key point. According to Lowe's suggestion, the modulus m(x,y) of the gradient is as follows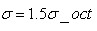 Gauss distribution addition, according to the 3_principle of scale sampling, the radius of neighborhood window is
Gauss distribution addition, according to the 3_principle of scale sampling, the radius of neighborhood window is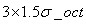 .
.
After calculating the gradient of the key points, the histogram is used to calculate the gradient and direction of the pixels in the neighborhood. The gradient histogram divides the direction range from 0 to 360 degrees into 36 columns (bins), of which each column is 10 degrees. As shown in Fig. 5.1, the peak direction of the histogram represents the main direction of the key points. (For simplification, only eight directions are drawn in the histogram.)
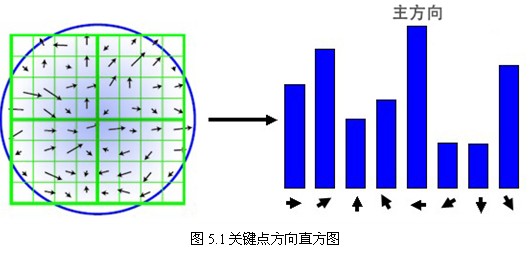
The peak value of the directional histogram represents the direction of the neighborhood gradient at the feature point, and the maximum value of the histogram is the main direction of the key point. In order to enhance the robustness of matching, only the direction where the peak value is greater than 80% of the peak value in the main direction is retained as the auxiliary direction of the key point. Therefore, for the key points of multiple peaks of the same gradient value, there will be multiple key points created at the same location and scale, but in different directions. Only 15% of the key points are given multiple directions, but the stability of key points matching can be significantly improved. In the actual programming implementation, the key points are copied into multiple key points, and the direction values are assigned to these key points respectively. Moreover, the discrete gradient direction histogram should be interpolated and fitted to obtain more accurate direction angle values. The test results are shown in Fig. 5.2.
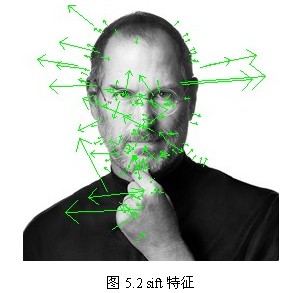
So far, SIFT feature points which contain position, scale and direction will be detected.
6. Key Point Characteristic Description
Through the above steps, for each key point, there are three information: location, scale and direction. The next step is to create a descriptor for each key point, and describe the key point with a set of vectors so that it does not change with various changes, such as changes in light, perspective and so on. This descriptor includes not only the key points, but also the pixels around the key points that contribute to it. Moreover, the descriptor should have a higher uniqueness in order to improve the probability of correct matching of feature points.
SIFT descriptor is a representation of the gradient statistical results of the key point neighborhood Gauss image. By partitioning the image area around the key points, the gradient histogram in the block is calculated to generate a unique vector, which is an abstract and unique image information in the region.
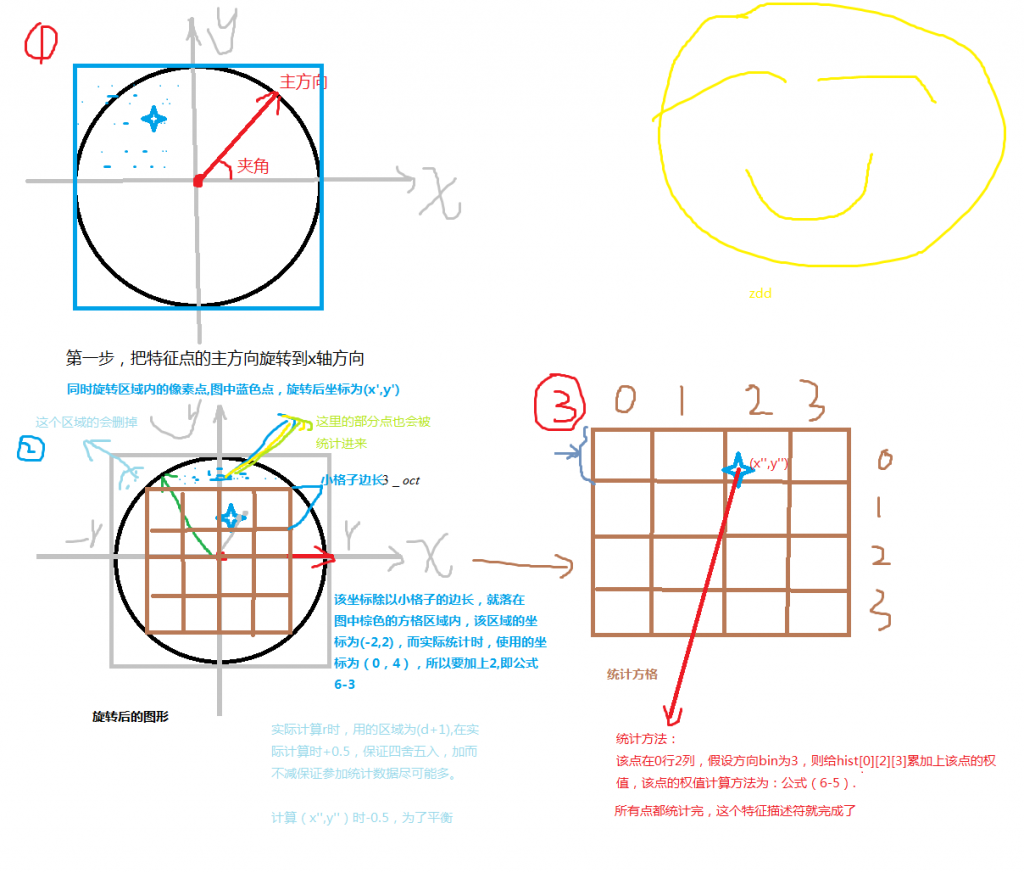
Lowe suggests that the descriptor be represented by a 4*4*8=128-dimensional vector, using the gradient information of eight directions calculated in the 4*4 window of the key point scale space. The steps are as follows:
1. Determine the image region needed to compute the descriptor
The feature descriptor is related to the scale of feature points, so the gradient should be calculated on the corresponding Gauss image of feature points. The neighborhood near the key point is divided into d*d(Lowe suggested d=4) sub-regions, each sub-region as a seed point, each seed point has eight directions. The size of each sub-region is the same as that of the key point direction allocation, i.e. each region has one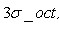 Subpixels, assigning edge lengths to each subareaSampling in rectangular area (actual edge length of each sub-pixel is
Subpixels, assigning edge lengths to each subareaSampling in rectangular area (actual edge length of each sub-pixel is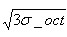 The rectangular region of the equation (3-8) can be included.
The rectangular region of the equation (3-8) can be included.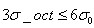 Not too big. In order to simplify the calculation, take the edge length asAnd the sampling points should be more or less. Considering that bilinear interpolation is needed in practical calculation, the required edge length of image window is
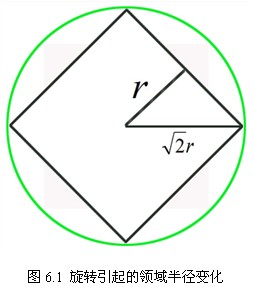
Not too big. In order to simplify the calculation, take the edge length asAnd the sampling points should be more or less. Considering that bilinear interpolation is needed in practical calculation, the required edge length of image window is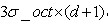 . Considering the rotation factor (to facilitate the next step to rotate the coordinate axis to the direction of the key point), as shown in Figure 6.1 below, the actual calculation of the required image area radius is as follows:
. Considering the rotation factor (to facilitate the next step to rotate the coordinate axis to the direction of the key point), as shown in Figure 6.1 below, the actual calculation of the required image area radius is as follows:
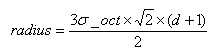 (6-1)
(6-1)
The results are rounded.
2. Rotate the coordinate axis in the direction of the key points to ensure rotation invariance, as shown in 6.2.
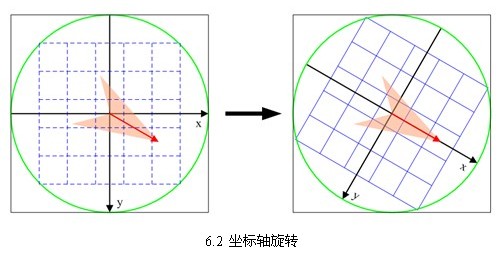
The new coordinates of the sampling points in the neighborhood after rotation are:
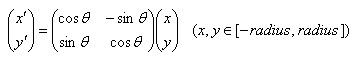 (6-2)
(6-2)
3. The sampling points in the neighborhood are allocated to the corresponding sub-region, and the gradient values in the sub-region are allocated to eight directions, and their weights are calculated.
The coordinates of the rotating sampling points are assigned to the radius circle. The gradient and direction of sampling points affecting the sub-region are calculated and assigned to eight directions.
The gradient and direction of sampling points affecting the sub-region are calculated and assigned to eight directions.
Sampling points after rotation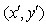 The subscript that falls on the subregion is
The subscript that falls on the subregion is
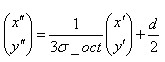 (6-3)
(6-3)
Lowe suggests that the gradient size of the pixels in the sub-region should be as follows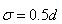 Gaussian weighting calculation, i.e.
Gaussian weighting calculation, i.e.
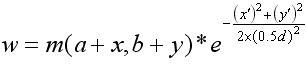 (6-4)
(6-4)
Among them, a and b are the position coordinates of the key points in the Gauss pyramid image.
4. Interpolation calculates gradients in eight directions for each seed point.
As shown in Figure 6.3, the subscripts of the sampling points obtained by equation (6-3) in the sub-region Linear interpolation is used to calculate its contribution to each seed point. The red dot in the figure falls between line 0 and line 1, contributing to both lines. The contribution factors to the seed points of row 0, row 3 and row 1 are dr, and to row 1, column 3 are 1-dr. Similarly, the contribution factors to the adjacent two columns are DC and 1-dc, and to the adjacent two directions are do and 1-do. Then the gradient in each direction is finally accumulated as follows:
Linear interpolation is used to calculate its contribution to each seed point. The red dot in the figure falls between line 0 and line 1, contributing to both lines. The contribution factors to the seed points of row 0, row 3 and row 1 are dr, and to row 1, column 3 are 1-dr. Similarly, the contribution factors to the adjacent two columns are DC and 1-dc, and to the adjacent two directions are do and 1-do. Then the gradient in each direction is finally accumulated as follows:
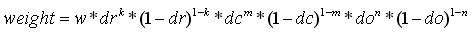 (6-5)
(6-5)
Where k, m, n are 0 or 1.
5. The 4*4*8=128 gradient information of the above statistics is the eigenvector of the key point. After the formation of feature vectors, in order to remove the influence of illumination changes, they need to be normalized. For the overall drift of image gray value, the gradient of each point in the image is obtained by subtracting the neighborhood pixels, so it can also be removed. The resulting descriptor subvector is The normalized eigenvector is
The normalized eigenvector is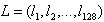 be
be
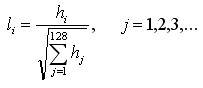 (6-7)
(6-7)
6. Describe subvector thresholds. Under non-linear illumination, the change of camera saturation causes the gradient value in some directions to be too large, but the influence on direction is weak. Therefore, the threshold value (0.2 after normalization of vectors) is set to truncate the larger gradient value. Then, a normalization process is carried out to improve the discriminability of features.
7. The feature description vectors are sorted according to the scale of feature points.
So far, SIFT feature description vectors are generated.
The description vector is not easy to understand. I drew a sketch for your reference.
7. Disadvantages of SIFT
SIFT has incomparable advantages in image invariant feature extraction, but it is not perfect and still exists:
1. Real-time is not high.
2. Sometimes there are fewer feature points.
3. It is impossible to extract feature points accurately for objects with smooth edges.
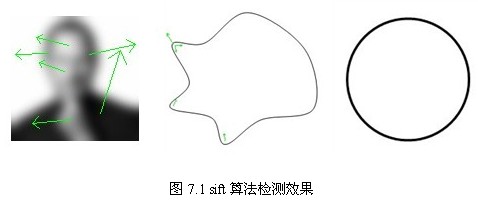
As shown in Figure 7.1 below, for blurred images and edge smoothing images, too few feature points are detected, and there is nothing to do with circles. Recent improvements have been made, most notably SURF and CSIF.
8, summary
I have been studying SIFT algorithm for more than a month. In view of the lack of relevant knowledge, scale space technology and differential approximation derivation have been difficult for me for a long time. In Lowe's paper, little or no details are mentioned, which makes it difficult to implement. After multi-reference, implementation, summed up in this article. I think I have the most detailed information about SIFT algorithm so far. I would like to share it with you and look forward to criticism and correction.
Also shared with you are the simultaneous implementation of Gauss fuzzy source code, sift algorithm source code, see Appendix 1, 2. The source code is implemented with vs2010+opencv2.2.
zdd
April 28, 2012, Beijing Normal University
First Amendment 15:33:23 May 17, 2012
Amendments: Part 3.3, Figure 3.1, Figure 3.5.
Correct the following code: http://download.csdn.net/detail/zddmail/4309418
Reference material
1,David G.Lowe Distinctive Image Features from Scale-Invariant Keypoints. January 5, 2004.
2,David G.Lowe Object Recognition from Local Scale-Invariant Features. 1999
3,Matthew Brown and David Lowe Invariant Features from Interest Point Groups. In British Machine Vision Conference, Cardiff, Wales, pp. 656-665.
4,PETER J. BURT, MEMBER, IEEE, AND EDWARD H. ADELSON, The Laplacian Pyramid as a Compact Image Code. IEEE TRANSACTIONS ON COMMUNICATIONS, VOL. COM-3l, NO. 4, APRIL 1983
5. Songdan 10905056 Scale Invariant Feature Transform (SIFT) (PPT)
6. RaySaint's blog SIFT algorithm research http://underthehood.blog.51cto.com/2531780/658350
7,Jason Clemons SIFT: SCALE INVARIANT FEATURE TRANSFORM BY DAVID LOWE(ppt)
8,Tony Lindeberg Scale-space theory: A basic tool for analysing structures at different scales.1994
9. Rob Hess of SIFT <hess@eecs.oregonstate.edu> SIFT source code
10. SIFT source code implemented by Opencv2.2 Andrea Vedaldi(UCLA VisionLab) http://www.vlfeat.org/~vedaldi/code/siftpp.html, opencv2.3 Change to Rob Hess Source Code
11. The Finite Difference Method of Partial Differential Equations in Scientific Computing Editor-in-Chief Yang Le
12. Wikipedia SIFT entry: http://zh.wikipedia.org/zh-cn/Scale-invariant_feature_transform
13. Baidu Encyclopedia SIFT entry: http://baike.baidu.com/view/2832304.htm
14. Other Internet Information
Appendix 1 Gauss Fuzzy Source Code
http://blog.csdn.net/zddmail/article/details/7450033
http://download.csdn.net/detail/zddmail/4217704
Appendix 2 SIFT algorithm source code
http://download.csdn.net/detail/zddmail/4309418
<div class="hide-article-box hide-article-pos text-center">
<a class="btn-readmore" data-report-view='{"mod":"popu_376","dest":"https://blog.csdn.net/jiutianhe/article/details/39896931","strategy":"readmore"}' data-report-click='{"mod":"popu_376","dest":"https://blog.csdn.net/jiutianhe/article/details/39896931","strategy":"readmore"}'>
Read the full text
<svg class="icon chevrondown" aria-hidden="true">
<use xlink:href="#csdnc-chevrondown"></use>
</svg>
</a>
</div>
<div class="recommend-box"><div class="recommend-item-box type_blog clearfix" data-report-click='{"mod":"popu_387","dest":"https://blog.csdn.net/chenghaoy/article/details/83308448","strategy":"BlogCommendFromMachineLearnPai2","index":"0"}'>
<div class="content">
<a href="https://Blog.csdn.net/chenghaoy/article/details/83308448 "target="_blank "rel=" noopener "title=" image similarity calculation-template matching ">
<h4 class="text-truncate oneline">
picture<em>Similarity degree</em>Calculation-template matching </h4>
<div class="info-box d-flex align-content-center">
<p class="date-and-readNum oneline">
<span class="date hover-show">10-23</span>
<span class="read-num hover-hide">
Reading number
1845</span>
</p>
</div>
</a>
<p class="content">
<a href="https://Blog.csdn.net/chenghaoy/article/details/83308448 "target="_blank "rel=" noopener "title=" image similarity calculation-template matching ">
<span class="desc oneline">What is template matching? The so-called template matching is to give a template image and a search image, in the search image to find the most similar part of the template image. How to achieve it? Simply put, it is to let the template image slide on the search image and calculate each position in pixels....</span>
</a>
<span class="blog_title_box oneline ">
<span class="type-show type-show-blog type-show-after">Bowen</span>
<a target="_blank" rel="noopener" href="https://Blog.csdn.net/chenghaoy "> from < span class=" blog_title "> chenghaoy's blog</span></a>
</span>
</p>
</div>
</div>
<div class="comment-edit-box d-flex">
<a id="commentsedit"></a>
<div class="user-img">
<a href="//me.csdn.net/qq_25736745" target="_blank" rel="noopener">
<img class="" src="https://avatar.csdn.net/1/0/C/3_qq_25736745.jpg">
</a>
</div>
<form id="commentform">
<input type="hidden" id="comment_replyId">
<textarea class="comment-content" name="comment_content" id="comment_content" placeholder="What would you like to say to the author?"></textarea>
<div class="opt-box"> <!-- d-flex -->
<div id="ubbtools" class="add_code">
<a href="#insertcode" code="code" target="_self"><i class="icon iconfont icon-daima"></i></a>
</div>
<input type="hidden" id="comment_replyId" name="comment_replyId">
<input type="hidden" id="article_id" name="article_id" value="39896931">
<input type="hidden" id="comment_userId" name="comment_userId" value="">
<input type="hidden" id="commentId" name="commentId" value="">
<div style="display: none;" class="csdn-tracking-statistics tracking-click" data-report-click='{"mod":"popu_384","dest":""}'><a href="#"Target="_blank"class=" comment_area_btn"rel=" noopener"> comment </a> </div>
<div class="dropdown" id="myDrap">
<a class="dropdown-face d-flex align-items-center" data-toggle="dropdown" role="button" aria-haspopup="true" aria-expanded="false">
<div class="txt-selected text-truncate">Add code slices</div>
<svg class="icon d-block" aria-hidden="true">
<use xlink:href="#csdnc-triangledown"></use>
</svg>
</a>
<ul class="dropdown-menu" id="commentCode" aria-labelledby="drop4">
<li><a data-code="html">HTML/XML</a></li>
<li><a data-code="objc">objective-c</a></li>
<li><a data-code="ruby">Ruby</a></li>
<li><a data-code="php">PHP</a></li>
<li><a data-code="csharp">C</a></li>
<li><a data-code="cpp">C++</a></li>
<li><a data-code="javascript">JavaScript</a></li>
<li><a data-code="python">Python</a></li>
<li><a data-code="java">Java</a></li>
<li><a data-code="css">CSS</a></li>
<li><a data-code="sql">SQL</a></li>
<li><a data-code="plain">Other</a></li>
</ul>
</div>
<div class="right-box">
<span id="tip_comment" class="tip">Can also input<em>1000</em>Character</span>
<input type="button" class="btn btn-sm btn-cancel d-none" value="Cancel reply">
<input type="submit" class="btn btn-sm btn-red btn-comment" value="Comment">
</div>
</div>
</form>
</div>
<div class="comment-list-container">
<a id="comments"></a>
<div class="comment-list-box">
</div>
<div id="commentPage" class="pagination-box d-none"></div>
<div class="opt-box text-center">
<div class="btn btn-sm btn-link-blue" id="btnMoreComment"></div>
</div>
</div>
Several methods of image similarity comparison
08-23 Reading number 5486
Reprinted from 1. Histogram method description: there are two images patch (of course, the whole image), calculate the histogram of the two images, normalize the histogram, and then measure the similarity according to some distance measurement standard. The idea of the method is based on simple vector similarity. Bowen From: github_39105958 blog
Several Solutions for Computing Image Similarity
09-13 Reading number 6655
Histogram distance is used to calculate the image similarity formula: G and S are the image color distribution histograms of two pictures, N is the color space sample points. In this paper, block method is used to calculate similarity in order to improve the characteristics of each part and prevent the similarity of image color from leading to high similarity of calculation. Average Ha Ha Ha Ha Ha Ha Ha Ha Ha. Bowen From: A cup of Java without sugar
Starting from scratch, Similar Image Matching SIFT (3), Closed Edition
03-27 Reading number 8457
After half a month, I can finally write this blog about learning sift algorithm from scratch! This article is suitable for children's shoes with a certain understanding of the theory, helping you to work out the java code implementation. If you don't know the theory, you can read http://blog.csdn.n together with this blog. Bowen Column from: abcd_d_
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_59" data-pid="59" data-report-view='{"mod":"kp_popu_59-78","keyword":""}' data-report-click='{"mod":"kp_popu_59-78","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u3491668",
container: s
});
})();
Image Similarity Computation Based on Depth
09-20 Reading number 885
Given the (x,y,z) coordinate values of each pixel on each image in the world coordinate system, a fast method to obtain the similarity of two images is found. Method 1: Calculate the Euclidean distance of any point (x1,y1,z1) on picture A and any point (x2,y2,z2) on picture B. If the distance... Bowen From: Libing 101007's blog
Analysis of Several Similarity Algorithms in Machine Learning
06-19 Reading number 10 thousand +
Recently, the recommendation system has been studied. The common similarity algorithms are as follows: 1. Euclidean distance metric (also known as Euclidean distance) is a commonly used definition of distance, which refers to the real distance between two points in m-dimensional space, or to the direction of ___________. Bowen From: weixin_39050022
Application Case Analysis of Recommendation System
04-13 Reading number 460
The application case analysis of recommendation system was published in 2016-01-0417:34 | 1007 reads | Source Alibaba Senior Engineer | 0 Comments | Author Jia Shuangcheng System Google Mathematics Principles Application Case Summary: This chapter will continue to describe the application case of recommendation system. To illustrate the recommendation system... Bowen From: Ling Feng's Column on Exploring Plum
Introduction of SIFT Feature Matching Algorithms-Principle of Finding Image Feature Points
06-26 Reading number 50 thousand +
The principle of SIFT feature matching algorithm of opencv is introduced in detail, with graph and text analysis, hoping to help friends who are just beginning to image processing (*^ *) laugh (* ^ ^ *)... ... Bowen From: Suray_Fu's blog
sift
09-30 Reading number 607
Https://blog.csdn.net/zddmail/article/details/7521424 sift Bowen From: qq_28031193 blog
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_60" data-pid="60" data-report-view='{"mod":"kp_popu_60-43","keyword":""}' data-report-click='{"mod":"kp_popu_60-43","keyword":""}'><div id="three_ad8" class="mediav_ad" ></div>
On the image similarity matching scheme, ask God for a way of thinking
The scene is similar to the license plate as shown in the figure. For example, I want to detect `6AX58LT'. This is the template. The rest of the cases such as `6AX78LT'and `6A58LT' should be excluded. How does this function work in the way of image similarity matching? forum
Feature matching opencv image similarity recognition
11-19 Reading number 3883
It is considered as one of the most effective image search methods. Many features are extracted from the image to ensure that the same features can be recognized again even when rotated/scaled/tilted. The features extracted in this way can be matched with other image feature sets. Another image with high proportionality in the first image is likely to depict ___________. Bowen From: column of Tony 2278
<div class="recommend-item-box blog-expert-recommend-box"> <div class="d-flex"> <div class="blog-expert-recommend"> <div class="blog-expert"> <div class="blog-expert-flexbox"></div> </div> </div> </div> </div>
Summary of Computing the Similarity of Two Images
09-17 Reading number 20 thousand +
1.SSIM (Structural Similarity Measurement) is a full-reference image quality evaluation index, which measures image similarity from three aspects: brightness, contrast and structure. The larger the value range of SSIM [0,1], the smaller the image distortion. In practical applications, sliding windows can be used to render images. Bowen From: Newbie Station
C Implementation and Evaluation of Image Similarity Algorithms
11-07 Reading number 168
C Implementation and Evaluation of Image Similarity Algorithms Bowen From: ffghggf's blog
java image similarity algorithm, large set
05-02 Reading number 3103
Use the histogram principle to achieve image content similarity comparison, mean hash to achieve image content similarity comparison, Hamming distance algorithm to achieve image content similarity comparison. For details, please refer to the personal blog copyright belongs to: technical guest original address: https://www.sunjs.com/ar... Bowen From: kevon_sun column
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_61" data-pid="61" data-report-view='{"mod":"kp_popu_61-622","keyword":""}' data-report-click='{"mod":"kp_popu_61-622","keyword":""}'><script type="text/javascript" src="//rabc1.iteye.com/common/web/production/79m9.js?f=aszggcwz"></script><img class="pre-img-lasy" data-src="https://kunyu.csdn.net/1.png?p=61&a=622&c=0&k=&d=1&t=3"></div></div>
A Summary of SIFT (Scale Invariant Feature Transform) Algorithms
06-29 Reading number 3919
This is the first time to write a blog, I feel that writing a summary will be conducive to my understanding of the algorithm. Firstly, the blog referenced in this paper is as follows: 1. https://blog.csdn.net/hit2015spring/article/details/528953. Bowen From: jancis blog
SIFT feature point extraction
01-15 Reading number 40 thousand +
There are many feature extraction algorithms in computer vision, but SIFT is a bright pearl in feature extraction algorithm because of its advantages in other aspects besides time-consuming calculation. There are many good blogs and articles on the introduction of SIFT algorithm. I also refer to this algorithm in the process of learning. Bowen From: PineTree's blog
matlab implementation of sift algorithm
Is there any research on the implementation of sift algorithm using matlab, add QQ: 316457055. The implementation code from the Internet and offline can not run. forum
Comparing the similarity of two images
12-29 Reading number 30 thousand +
Now the function of graph search is very hot. I'm curious about its principle. Simple search learning shows that the key technology to achieve similar image search is "perceptual hashing algorithm", which generates a corresponding fingerprint string for each picture according to certain rules. Comparing the fingerprint strings between different pictures, the more the result is... Bowen From: Junzzy's blog
Image Similarity Computation
10-08 Reading number 5963
This paper transfers from http://blog.sina.com.cn/s/blog_4a540be60100vjae.html image similarity calculation is mainly used for scoring the similarity between two images, and judging the image according to the score. Bowen From: The column of sarah_tang
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_62" data-pid="62" data-report-view='{"mod":"kp_popu_62-623","keyword":""}' data-report-click='{"mod":"kp_popu_62-623","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u3600849",
container: s
});
})();
Basis of Recommendation Algorithms--Summary of Similarity Computing Methods
09-04 Reading number 20 thousand +
Similarity calculation in recommendation system can be said to be the foundation, because almost all recommendation algorithms are in the calculation of similarity, user similarity or item similarity, here lists a variety of similarity calculation methods and applicable point cosine similarity = cos (theta) = A_B.. Bowen From: In the process of God's cultivation...
Starting from scratch, SIFT algorithm for similar image matching (I)
03-09 Reading number 6785
It's been half a month since I started learning SIFT algorithm. At last, I understand what it is. 1. This project is to do similar image search, after the project needs are roughly determined; in Baidu random search, search image matching or image recognition keywords, you can find a lot of things, what google.. Bowen Column from: abcd_d_
sift algorithm for image matching
04-13 Reading number 3287
Yesterday, I checked the data for a day, but I didn't understand what SIFT is. This morning, I finally found a blog with more detailed explanations. I reprinted and collected the SIFT algorithm proposed by D.G. Lowe in 1999, and improved it in 2004. The paper was published in IJCV in 2004. Bowen From: Amiee 521's blog
Image similarity comparison algorithm
11-26 Reading number 441
https://blog.csdn.net/Print_lin/article/details/81052497 Bowen From: blog l641208111
Delphi image Hash algorithm, on image similarity
12-14 Reading number 130
Image Hash algorithm, there are PHash, DHash, AHash, the following record average hash AHash Delphi algorithm code varbmp:TBitmap=nil;//gb:TBitmap; //algorithm principle: image scaling into 8x.. Bowen From: cmd9x column
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_63" data-pid="63" data-report-view='{"mod":"kp_popu_63-624","keyword":""}' data-report-click='{"mod":"kp_popu_63-624","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u4221910",
container: s
});
})();
SIFT feature point detection, feature point description, feature point matching understanding
03-19 Reading number 4892
Harris corner detection is mentioned earlier. One obvious disadvantage of this method is that it can't solve the invariance of scale change, because whether a point in Harris is corner detection depends on the patch where the point is located and whether there are obvious changes in all directions around the patch, but after the scale change, this method can't solve the problem of scale invariance. Bowen From: ds0529 blog
Two pairs of pictures have been matched with SIFT feature points using opencv. Where are the two pairs of feature points stored and the code found on the Internet?
- Questions and answers
Personal opinion on image similarity algorithm (python & opencv)
12-14 Reading number 20 thousand +
This paper briefly describes a blog hash algorithm to achieve image similarity comparison (Python & OpenCV), and uses simple hash algorithm to judge image similarity. But in practice, the algorithm can not achieve the desired results: image zooming 8*8 size, image information content seriously lost 64 bits. Bowen From: Hao Fan's blog
Similarity Algorithms--Cosine Similarity
08-01 Reading number 8566
Reprint: http://blog.csdn.net/u012160689/article/details/15341303 cosine distance, also known as cosine similarity, is used to measure the cosine value of the angle between two vectors in vector space. Bowen From: qw311113qin's blog
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_64" data-pid="64" data-report-view='{"mod":"kp_popu_64-626","keyword":""}' data-report-click='{"mod":"kp_popu_64-626","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u3600856",
container: s
});
})();
SIFT feature extraction and analysis
06-06 Reading number 530 thousand +
SIFT (Scale-invariant tfeaturetransform) is an algorithm for detecting local features. This algorithm finds the features (interestpoints,orcornerpoints) in a graph and their related s. Bowen From: Rachel Zhang's column
SIFT algorithm in detail
08-03 Reading number 2636
Scale Invariant Feature Transform(SIFT) for beginners, from David G.Lowe's paper to implementation, there are many gaps, this article helps you to bridge. 1. Overview of SIFT. Bowen From: wanglp094 column
javascript algorithm for judging image similarity
09-14 Reading number 2532
functiongetHistogram(imageData){vararr=[];for(vari=0;i Bowen From: Benyoulai 5 column
The Principle of Image Similarity Search
04-29 Reading number 9430
This article is from: http://www.hackerfactor.com/blog/index.php?/archives/432-Looks-Like-It.html http://www.ruanyifen... Bowen From: a column on Jiandan Jinxin
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_65" data-pid="65" data-report-view='{"mod":"kp_popu_65-1378","keyword":""}' data-report-click='{"mod":"kp_popu_65-1378","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u4221803",
container: s
});
})();
Computing Image Similarity: One of Python's OK
11-21 Reading number 364
Thank you to the author: https://blog.csdn.net/gzlaiyonghao/article/details/2325027 abstract: Computing image similarity - Python can also be one of the statements: this article was originally published by Lai. Bowen From: gqixf's blog
OpenCV-python image similarity algorithm (dHash, variance)
12-03 Reading number 1943
Catalogue 1, SIFT review 2, perceptual hash halgorithm 2.1 similarity image detection steps: 2.2 code implementation 3, using difference detection image similarity 3.1 implementation steps: 1, SIFT review scale invariant feature transformation. Bowen From: wsp_1138886114 blog
Principle and Realization of Common Similarity Calculating Method
04-11 Reading number 60 thousand +
In data analysis, data mining and search engine, we often need to know the difference between individuals, and then evaluate the similarity and category of individuals. Common such as data analysis, such as correlation analysis, K-Means algorithm in data mining, and search engine recommendation. Bowen From: yixianfeng 41 column
Image similarity comparison
05-21 Reading number 123
Recent projects need to analyze image similarity. Image similarity calculation is mainly used to score the similarity of content between two images, and to judge the similarity of image content according to the score. Another application is image retrieval based on image content, which is commonly referred to as image checking. Xiang... Bowen From: blog u010881576
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_66" data-pid="66" data-report-view='{"mod":"kp_popu_66-87","keyword":""}' data-report-click='{"mod":"kp_popu_66-87","keyword":""}'><div id="three_ad38" class="mediav_ad" ></div>
When running SIFT algorithm in matlab, there are always undefined function variables?
- Questions and answers
Image similarity comparison algorithm
07-15 Reading number 10 thousand +
One of the keys of Ocr character recognition is to judge whether two pictures are similar or not, so we hope to find one or more algorithms to calculate the similarity of pictures. This paper will introduce the comparison algorithm used in the project, and use it in combination for preliminary text recognition. Algorithm is clear. Bowen From: Print_lin's blog
Image similarity
08-29 Reading number 2211
Recently (2015-2017), the idea of calculating image similarity using in-depth learning (also known as image matching) is very similar, which is derived from Siamese Networks. Bowen From: blog u013247002
OpenCV Implementation of Hash Value Method for Image Similarity Computing
11-11 Reading number 722
OpenCV Implementation of Hash Value Method for Image Similarity Computing Bowen From: hddryjv's blog
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_67" data-pid="67" data-report-view='{"mod":"kp_popu_67-658","keyword":""}' data-report-click='{"mod":"kp_popu_67-658","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u4623113",
container: s
});
})();
Cosine Similarity of Similarity Algorithms
07-16 Reading number 50 thousand +
From: http://blog.csdn.net/u012160689/article/details/15341303 cosine distance, also known as cosine similarity, is used to measure the difference between two individuals by the cosine value of the angle between two vectors in vector space. Bowen From: The Song of the Wilderness
How to calculate the similarity between two images after feature matching of opencv sift?
How to calculate the similarity between two images after feature matching of opencv sift? Online are all about how to match features, not how to get the conclusion of similarity, please teach Daniel, I Xiaobai forum
Why SIFT feature is scale invariant
SIFT feature is a scale invariant feature. It is not clear why it is scale invariant. forum
<div class="recommend-item-box recommend-download-box clearfix" data-report-click='{"mod":"popu_387","dest":"https://download.csdn.net/download/u011745380/9967334","strategy":"BlogCommendFromBaidu2","index":"48"}'>
<a href="https://download.csdn.net/download/u011745380/9967334"rel="noopener" target="_blank" rel="noopener">
<div class="content clearfix">
<div class="">
<h4 class="text-truncate oneline clearfix">
<em>SIFT</em><em>algorithm</em><em>Detailed explanation</em>And Application(It's very good and detailed.) </h4>
<span class="data float-right">09-06</span>
</div>
<div class="desc oneline">
SIFT Algorithm characteristics • SIFT Feature is the local feature of image. It keeps invariant to rotation, scale scaling, brightness change, and stability to a certain extent to view angle change, affine transformation and noise. • Uniqueness(Distinctiveness)Okay, information. </div>
<span class="type-show type-show-download">download</span>
</div>
</a>
</div>
<div class="recommend-item-box recommend-recommend-box"><div id="kp_box_68" data-pid="68" data-report-view='{"mod":"kp_popu_68-625","keyword":""}' data-report-click='{"mod":"kp_popu_68-625","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u4623747",
container: s
});
})();
<div class="recommend-item-box type_hot_word">
<div class="content clearfix">
<div class="float-left">
<span>
<a href="https://www.csdn.net/gather_1b/NtjaMgxsLWRvd25sb2Fk.html" target="_blank">
c# linq principle</a>
</span>
<span>
<a href="https://www.csdn.net/gather_1a/NtjaMgysLWRvd25sb2Fk.html" target="_blank">
c# What's the use of packing?</a>
</span>
<span>
<a href="https://www.csdn.net/gather_12/NtjaMgzsLWRvd25sb2Fk.html" target="_blank">
c#Collection replication</a>
</span>
<span>
<a href="https://www.csdn.net/gather_16/NtjaMg0sLWRvd25sb2Fk.html" target="_blank">
c# A string grouping</a>
</span>
<span>
<a href="https://www.csdn.net/gather_26/NtjaMg1sLWJsb2cO0O0O.html" target="_blank">
c++and c#Which is the highest employment rate?</a>
</span>
<span>
<a href="https://www.csdn.net/gather_1c/NtjaMg2sLWRvd25sb2Fk.html" target="_blank">
c# Batch Dynamic Creation Control</a>
</span>
<span>
<a href="https://www.csdn.net/gather_1a/NtjaMg3sLWRvd25sb2Fk.html" target="_blank">
c# The difference between modules and assemblies</a>
</span>
<span>
<a href="https://www.csdn.net/gather_14/NtjaMg4sLWRvd25sb2Fk.html" target="_blank">
c# gmap screenshot</a>
</span>
<span>
<a href="https://www.csdn.net/gather_14/NtjaQgwsLWRvd25sb2Fk.html" target="_blank">
c# Verification Code Picture Generation Class</a>
</span>
<span>
<a href="https://www.csdn.net/gather_16/NtjaQgxsLWRvd25sb2Fk.html" target="_blank">
c# Failed to attempt connection again</a>
</span>
</div>
</div>
</div>
<div class="recommend-loading-box">
<img src='https://csdnimg.cn/release/phoenix/images/feedLoading.gif'>
</div>
<div class="recommend-end-box">
<p class="text-center">No more recommendations.<a href="https://Blog.csdn.net/"class=" c-blue c-blue-hover c-blue-focus">Return to Home Page</a></p>
</div>
</div>
</main>
<aside>
<div id="asideProfile" class="aside-box">
<!-- <h3 class="aside-title">personal data</h3> -->
<div class="profile-intro d-flex">
<div class="avatar-box d-flex justify-content-center flex-column">
<a href="https://blog.csdn.net/jiutianhe">
<img src="https://avatar.csdn.net/8/4/8/3_jiutianhe.jpg" class="avatar_pic">
<img src="https://g.csdnimg.cn/static/user-reg-year/1x/11.png" class="user-years">
</a>
</div>
<div class="user-info d-flex flex-column">
<p class="name csdn-tracking-statistics tracking-click" data-report-click='{"mod":"popu_379"}'>
<a href="https://blog.csdn.net/jiutianhe" class="" id="uid" title='jiutianhe'>jiutianhe</a>
</p>
<p class="personal-home-page" style = 'right:-96px;'><a target="_blank" href="https://Me.csdn.net/jiutianhe "> TA's personal home page>"</a></p>
</div>
<div class = 'profile-personal-letter'>
<a id = 'profile-personal-alink' href="" target="_blank" rel="noopener">Private letter</a>
</div>
<div class="opt-box d-flex flex-column">
<span class="csdn-tracking-statistics tracking-click" data-report-click='{"mod":"popu_379"}'>
<a class="btn btn-sm btn-red-hollow attention" id="btnAttent" style = 'line-height:24px;padding:0;'>follow</a>
</span>
</div>
</div>
<div class="data-info d-flex item-tiling">
<dl class="text-center" title="93">
<dt><a href="https://Blog. csdn. net / jiutianhe? T = 1 "> original </a> </dt>"
<dd><a href="https://blog.csdn.net/jiutianhe?t=1"><span class="count">93</span></a></dd>
</dl>
<dl class="text-center" id="fanBox" title="172">
<dt>Fans</dt>
<dd><span class="count" id="fan">172</span></dd>
</dl>
<dl class="text-center" title="28">
<dt>like</dt>
<dd><span class="count">28</span></dd>
</dl>
<dl class="text-center" title="57">
<dt>comment</dt>
<dd><span class="count">57</span></dd>
</dl>
</div>
<div class="grade-box clearfix">
<dl>
<dt>Grade:</dt>
<dd>
<a href="https://Blog.csdn.net/home/help.html# level "title=" level 6, click on "target="_blank"to see the level description.
<svg class="icon icon-level" aria-hidden="true">
<use xlink:href="#csdnc-bloglevel-6"></use>
</svg>
</a>
</dd>
</dl>
<dl>
<dt>Visit:</dt>
<dd title="781157">
78 ten thousand+ </dd>
</dl>
<dl>
<dt>Integral:</dt>
<dd title="6585">
6585 </dd>
</dl>
<dl title="6737">
<dt>Rank:</dt>
<dd>6737</dd>
</dl>
</div>
<div class="badge-box d-flex">
<span>Medal:</span>
<div class="badge d-flex">
<div class="icon-badge" title="Persevere">
<div class="mouse-box">
<img src="https://g.csdnimg.cn/static/user-medal/chizhiyiheng.svg" alt="">
<div class="icon-arrow"></div>
</div>
<div class="grade-detail-box">
<div class="pos-box">
<div class="left-box d-flex justify-content-center align-items-center flex-column">
<img src="https://g.csdnimg.cn/static/user-medal/chizhiyiheng.svg" alt="">
<p>Persevere</p>
</div>
<div class="right-box">
//Authorize users who publish 4 or more original or translated IT blogs every natural month. There is no such thing as a thousand miles or a small stream. The splendor of procedural life needs to be accumulated unremittingly. </div>
</div>
</div>
</div>
</div>
<script>
(function ($) {
setTimeout(function(){
$('div.icon-badge.show-moment').removeClass('show-moment');
}, 5000);
})(window.jQuery)
</script>
</div>
Latest articles
Classification column
-
 operating system
4 articles
operating system
4 articles
-
network
1 articles
-
data structure
33 articles
-
C Language Foundation
2 articles
-
Java
48 articles
-
Basic knowledge of Java
23 articles
-
Linux system
8 articles
-
machine learning
23 articles
-
Software knowledge
34 articles
-
data base
25 articles
-
Personal hobbies
6 articles
-
hapoop
16 articles
-
Python
3 articles
-
Apache
14 articles
-
image processing
7 articles
-
java plug-in
3 articles
-
algorithm
1 articles
File
- August 2015
- June 2015
- May 2015
- April 2015
- March 2015
- February 2015
- Jan. 9, 2015
- December 16, 2014
- 19 Nov. 2014
- October 2014 37
- 19 September 2014
- 11 August 2014
- July 2014
- 22 articles in June 2014
- 5 articles in May 2014
- 8 articles in April 2014
- March 2014
- Four articles in February 2014
- 6 articles in January 2014
- Dec. 10, 2013
- November 2013
- October 10, 2013
- 3 articles in September 2013
- August 2013
- Four articles in July 2013
- May 2013
- 8 articles in April 2013
- December 2012
- November 2012
- October 2012 21
- 12 September 2012
Hot articles
-
<a href="https://blog.csdn.net/jiutianhe/article/details/39896931" > Image similarity algorithm--SIFT Algorithm details </a> <p class="read">Reading number <span>106465</span></p> </li> <li> <a href="https://blog.csdn.net/jiutianhe/article/details/42455455" > eclipse Function Maven The Times wrongly summarized </a> <p class="read">Reading number <span>38371</span></p> </li> <li> <a href="https://blog.csdn.net/jiutianhe/article/details/18606295" > java Queue implementation (sequential queue, chain queue, circular queue) </a> <p class="read">Reading number <span>36819</span></p> </li> <li> <a href="https://blog.csdn.net/jiutianhe/article/details/39670817" > Java Use commons-dbcp2.0 </a> <p class="read">Reading number <span>31572</span></p> </li> <li> <a href="https://blog.csdn.net/jiutianhe/article/details/19199573" > apache.commons.collections4 usage </a> <p class="read">Reading number <span>25599</span></p> </li> </ul> </div>
Latest comments
-
Installation of mahout-0.9 under win7
Jialins_blog: Hello, step 4 of the implementation process, ERROR (HTML entity error and element not closed) how to do I am under the official website is mahout-0.14.0.zip
-
Learning Experience of Surf Algorithms (1) - Algorithms.
yushanly: See pictures together
-
Image Similarity Algorithms--Detailed Explanation of SIFT Algorithms
liaoyongraul: Hello, landlord. I'm looking at this blog material now. No matter which browser you use to open it, the formulas and pictures can't be displayed. Do you have the original full display? Now I'm studying this piece of information that really needs a little more detail. Please reply.
-
Apache Commons Co...
nkshuangyuan2012: Very good. It just solved my problem.
-
eclipse runs Maven Times...
qq_36361194: How to solve the first problem of the landlord? I made the same mistake as you. My linux system, I can't solve it. Can you give me some advice?
<div class="aside-box">
<div id="kp_box_57" data-pid="57" data-report-view='{"mod":"kp_popu_57-77","keyword":""}' data-report-click='{"mod":"kp_popu_57-77","keyword":""}'><script type="text/javascript">
(function() {
var s = "_" + Math.random().toString(36).slice(2);
document.write('<div style="" id="' + s + '"></div>');
(window.slotbydup = window.slotbydup || []).push({
id: "u3163270",
container: s
});
})();
-
Give the thumbs-up
Cancel points
27
-
poster
Share poster notes
</li> <li class="to-commentBox"> <a class="btn-comments long-height hover-box" title="Write comments" href="#commentBox"> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-comments"></use> </svg> <span class="hover-show text">comment</span> <p class=""> 4 </p> </a> </li> <li class="toc-container-box" id="liTocBox"> <a class="btn-toc low-height hover-box btn-comments" title="Catalog"> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-contents"></use> </svg> <span class="hover-show text">Catalog</span> </a> <div class="toc-container"> <div class="pos-box"> <div class="icon-arrow"></div> <div class="scroll-box"> <div class="toc-box"></div> </div> </div> <div class="opt-box"> <button class="btn-opt prev nomore" title="Upward"> <svg class="icon" aria-hidden="true"> <use xlink:href="#csdnc-chevronup"></use> </svg> </button> <button class="btn-opt next"> <svg class="icon" aria-hidden="true"> <use xlink:href="#csdnc-chevrondown"></use> </svg> </button> </div> </div> </li> <li> <a class="btn-bookmark low-height hover-box btn-comments" title="Collection"> <svg class="icon active hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-bookmark-ok"></use> </svg> <svg class="icon no-active hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-bookmark"></use> </svg> <span class="hover-show text">Collection</span> <!-- <span class="hover-show text-box text"> <span class="no-active">Collection</span> <span class="active">Cancel collection</span> </span> --> </a> </li> <li class="bdsharebuttonbox"> <div class="weixin-qr btn-comments low-height hover-box" > <a href="#"Class=" bds_weixin clear-share-style "data-cmd=" Weixin "title=" mobile phone watch ">"</a> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-usephone"></use> </svg> <span class="hover-show text text3"> Mobile phone look </span> </div> </li> <li class="widescreen-hide"> <a class="prev btn-comments low-height hover-box" href="https://Blog.csdn.net/jiutianhe/article/details/39892609 "title=" System class in Java "> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-chevronleft"></use> </svg> <span class="hover-show text text3">Last article</span> </a> </li> <li class="widescreen-hide"> <a class="next btn-comments hover-box low-height" href="https://Blog.csdn.net/jiutianhe/article/details/39928317 "title=" Surf algorithm learning experience (1) - algorithm principle "> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-chevronright"></use> </svg> <span class="hover-show text text3">Next article</span> </a> </li> <!-- Wide screen more buttons --> <li class="widescreen-more"> <a class="btn-comments chat-ask-button low-height hover-box" title="Ask quickly" href="#chatqa"> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-more"></use> </svg> <span class="hover-show text">More</span> </a> <ul class="widescreen-more-box"> <li class="widescreen-more"> <a class="btn-comments low-height hover-box" href="https://Blog.csdn.net/jiutianhe/article/details/39892609 "title=" System class in Java "> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-chevronleft"></use> </svg> <span class="hover-show text text3">Last article</span> </a> </li> <li class="widescreen-more"> <a class="btn-comments hover-box low-height" href="https://Blog.csdn.net/jiutianhe/article/details/39928317 "title=" Surf algorithm learning experience (1) - algorithm principle "> <svg class="icon hover-hide" aria-hidden="true"> <use xlink:href="#csdnc-chevronright"></use> </svg> <span class="hover-show text text3">Next article</span> </a> </li> </ul> </li> </ul>

<link rel="stylesheet" href="https://csdnimg.cn/release/blog_editor_html/release1.4.6/ckeditor/plugins/chart/chart.css" /> <script type="text/javascript" src="https://csdnimg.cn/release/blog_editor_html/release1.4.6/ckeditor/plugins/chart/lib/chart.min.js"></script> <script type="text/javascript" src="https://csdnimg.cn/release/blog_editor_html/release1.4.6/ckeditor/plugins/chart/widget2chart.js"></script> <link rel="stylesheet" href="https://csdnimg.cn/release/blog_editor_html/release1.4.6/ckeditor/plugins/codesnippet/lib/highlight/styles/atom-one-light.css"> <script type="text/javascript" src="https://csdnimg.cn/release/phoenix/production/pc_wap_common-f868939e52.js" /></script>
<script src="https://csdnimg.cn/release/phoenix/themes/skin3-template/skin3-template-fc7383b956.min.js"></script>
<script src="//g.csdnimg.cn/baidu-search/1.0.2/baidu-search.js" type="text/javascript"></script>