I have always felt the shortcomings of the blog, but recently I found it difficult to find a blog I wrote before when it grew up. As a back-end developer, the owner felt he had enough clothes and clothes to eat, so he had the full-text search function of the blog, Elasticsearch, and thanks to a server sponsored by Phigo.
Selection of Full Text Retrieval Tool
As we all know, there are many tools to support full-text search, such as Lucene, solr, Elasticsearch, etc. Compared with other tools, it is clear that the Elasticsearch community is more active and has a better solution to problems. The restful interface provided by Elasticsearch is easy to operate, which is also an important reason why the building owners choose Elasticsearch, of course.Elasticsearch takes up a relatively large amount of memory, and the 2G cloud server is running out of capacity.
Data migration, from MySQL to Elasticsearch
This function is relatively simple, that is, update data from MySQL to Elasticsearch regularly. Originally, the landlord intended to write a tool for data migration by himself, but recalled that the DataX used by the landlord to do data migration before was very good, read and write official documents or support, but the landlord did not run because there were not enough cloud servers in the 2G memory of the landlord.Yes, DataX-ray is more than 1G of memory to run, so the landlord can only find another way.A little buddy interested in DataX can see another article by the landlord Ali Offline Data Synchronization Tool DataX Trench Record.
Speaking of languages that can save memory, your little buddy might think of golang, which is more popular recently. That's what the landlord thought.Finally, the landlord uses a tool called go-mysql-elasticsearch, which uses golang's implementation to migrate data from MySQL to Elasticsearch.The building owner is not here to elaborate on the specific construction process. Please move on if you are interested go-mysql-elasticsearch In addition, to build the Elasticsearch environment, it is important to note that the machine memory installed with Elasticsearch should be greater than or equal to 2G, otherwise the situation may not arise, the landlord is not here to repeat, it is relatively simple, please small partners to google themselves.
It is also important to note that the binlog function of MySQL should be turned on when using go-mysql-elasticsearch. The idea of go-mysql-elasticsearch to synchronize data is to mount itself on M ySQL as a slave of M ySQL, which makes it easy to synchronize data to Elasticsearch in real time. There should be at least one M on the machine that starts go-mysql-elasticsearchYSQL client tool, otherwise error will be started.The landlord's suggestion is that root MySQL be deployed on the same machine, since golang consumes very little memory and will not have much impact.The following is the configuration file for go-mysql-elasticsearch when the building master synchronizes data:
# MySQL address, user and password # user must have replication privilege in MySQL. my_addr = "127.0.0.1:3306" my_user = "root" my_pass = "******" my_charset = "utf8" # Set true when elasticsearch use https #es_https = false # Elasticsearch address es_addr = "127.0.0.1:9200" # Elasticsearch user and password, maybe set by shield, nginx, or x-pack es_user = "" es_pass = "" # Path to store data, like master.info, if not set or empty, # we must use this to support breakpoint resume syncing. # TODO: support other storage, like etcd. data_dir = "./var" # Inner Http status address stat_addr = "127.0.0.1:12800" # pseudo server id like a slave server_id = 1001 # mysql or mariadb flavor = "mysql" # mysqldump execution path # if not set or empty, ignore mysqldump. mysqldump = "mysqldump" # if we have no privilege to use mysqldump with --master-data, # we must skip it. #skip_master_data = false # minimal items to be inserted in one bulk bulk_size = 128 # force flush the pending requests if we don't have enough items >= bulk_size flush_bulk_time = "200ms" # Ignore table without primary key skip_no_pk_table = false # MySQL data source [[source]] schema = "billboard-blog" # Only below tables will be synced into Elasticsearch. tables = ["content"] # Below is for special rule mapping [[rule]] schema = "billboard-blog" table = "content" index = "contentindex" type = "content" [rule.field] title="title" blog_desc="blog_desc" content="content" # Filter rule [[rule]] schema = "billboard-blog" table = "content" index = "contentindex" type = "content" # Only sync following columns filter = ["title", "blog_desc", "content"] # id rule [[rule]] schema = "billboard-blog" table = "content" index = "contentindex" type = "content" id = ["id"]
Service for Full-Text Retrieval
To achieve full-text retrieval and provide services to the outside world, web services are essential. The landlord uses Spring Boot to set up Web services. Small partners interested in Spring Boot can also look at another article by the landlord. Implement Blog Statistics Service with Spring Boot .Okay, let's not talk more. See the code
Interface implementation code, the code is relatively simple is to receive parameters, call service code
@ApiOperation(value="Full Text Retrieval Interface", notes="")
@ApiImplicitParam(name = "searchParam", value = "Blog search criteria (author, description, content, title)", required = true, dataType = "String")
@RequestMapping(value = "/get_content_list_from_es", method = RequestMethod.GET)
public ResultCode<List<ContentsWithBLOBs>> getContentListFromEs(String searchParam) {
ResultCode<List<ContentsWithBLOBs>> resultCode = new ResultCode();
try {
LOGGER.info(">>>>>> method getContentListFromEs request params : {},{},{}",searchParam);
resultCode = contentService.getContentListFromEs(searchParam);
LOGGER.info(">>>>>> method getContentListFromEs return value : {}",JSON.toJSONString(resultCode));
} catch (Exception e) {
e.printStackTrace();
resultCode.setCode(Messages.API_ERROR_CODE);
resultCode.setMsg(Messages.API_ERROR_MSG);
}
return resultCode;
}
service code implementation, where the main function of the code is to call the es tool class, to retrieve the blog description, author, blog title, blog content in full text.
@Override
public ResultCode<List<ContentsWithBLOBs>> getContentListFromEs(String searchParam) {
ResultCode resultCode = new ResultCode();
// Check parameter, parameter cannot be empty
if (StringUtils.isBlank(searchParam)) {
LOGGER.info(">>>>>> params not be null");
resultCode.setMsg(Messages.INPUT_ERROR_MSG);
resultCode.setCode(Messages.INPUT_ERROR_CODE);
return resultCode;
}
String matchStr = "blog_desc=" + searchParam;
List<Map<String, Object>> result = ElasticsearchUtils.searchListData(BillboardContants.ES_CONTENT_INDEX,BillboardContants.ES_CONTENT_TYPE,BillboardContants.ES_CONTENT_FIELD,true,matchStr);
matchStr = "author=" + searchParam;
result.addAll(ElasticsearchUtils.searchListData(BillboardContants.ES_CONTENT_INDEX,BillboardContants.ES_CONTENT_TYPE,BillboardContants.ES_CONTENT_FIELD,true,matchStr));
matchStr = "title=" + searchParam;
result.addAll(ElasticsearchUtils.searchListData(BillboardContants.ES_CONTENT_INDEX,BillboardContants.ES_CONTENT_TYPE,BillboardContants.ES_CONTENT_FIELD,true,matchStr));
matchStr = "content=" + searchParam;
result.addAll(ElasticsearchUtils.searchListData(BillboardContants.ES_CONTENT_INDEX,BillboardContants.ES_CONTENT_TYPE,BillboardContants.ES_CONTENT_FIELD,true,matchStr));
List<ContentsWithBLOBs> data = JSON.parseArray(JSON.toJSONString(result),ContentsWithBLOBs.class);
LOGGER.info("es return data : {}",JSON.toJSONString(result));
resultCode.setData(data);
return resultCode;
}
The tool class code implementation of ES used by the building owner is to use the java client of ES to retrieve es.
/**
* Use word breaking queries
*
* @param index Index Name
* @param type type name, which can be passed in multiple types separated by commas
* @param fields Fields to display separated by commas (default is all fields)
* @param matchPhrase true Use, phrase matching
* @param matchStr Filter condition (xxx=111,aaa=222)
* @return
*/
public static List<Map<String, Object>> searchListData(String index, String type, String fields, boolean matchPhrase, String matchStr) {
return searchListData(index, type, 0, 0, null, fields, null, matchPhrase, null, matchStr);
}
/**
* Use word breaking queries
*
* @param index Index Name
* @param type type name, which can be passed in multiple types separated by commas
* @param startTime start time
* @param endTime End time
* @param size Document size limit
* @param fields Fields to display separated by commas (default is all fields)
* @param sortField sort field
* @param matchPhrase true Use, phrase matching
* @param highlightField Highlight Fields
* @param matchStr Filter condition (xxx=111,aaa=222)
* @return
*/
public static List<Map<String, Object>> searchListData(String index, String type, long startTime, long endTime, Integer size, String fields, String sortField, boolean matchPhrase, String highlightField, String matchStr) {
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index);
if (StringUtils.isNotEmpty(type)) {
searchRequestBuilder.setTypes(type.split(","));
}
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
if (startTime > 0 && endTime > 0) {
boolQuery.must(QueryBuilders.rangeQuery("processTime")
.format("epoch_millis")
.from(startTime)
.to(endTime)
.includeLower(true)
.includeUpper(true));
}
//Searched Fields
if (StringUtils.isNotEmpty(matchStr)) {
for (String s : matchStr.split(",")) {
String[] ss = s.split("=");
if (ss.length > 1) {
if (matchPhrase == Boolean.TRUE) {
boolQuery.must(QueryBuilders.matchPhraseQuery(s.split("=")[0], s.split("=")[1]));
} else {
boolQuery.must(QueryBuilders.matchQuery(s.split("=")[0], s.split("=")[1]));
}
}
}
}
// Highlight (xxx=111,aaa=222)
if (StringUtils.isNotEmpty(highlightField)) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
//HighlightBuilder.preTags ('<span style='color:red'>');//Set prefix
//HighlightBuilder.postTags ('</span>'); //Set suffix
// Set Highlight Fields
highlightBuilder.field(highlightField);
searchRequestBuilder.highlighter(highlightBuilder);
}
searchRequestBuilder.setQuery(boolQuery);
if (StringUtils.isNotEmpty(fields)) {
searchRequestBuilder.setFetchSource(fields.split(","), null);
}
searchRequestBuilder.setFetchSource(true);
if (StringUtils.isNotEmpty(sortField)) {
searchRequestBuilder.addSort(sortField, SortOrder.DESC);
}
if (size != null && size > 0) {
searchRequestBuilder.setSize(size);
}
//Printed content can be queried on Elasticsearch head er and Kibana
LOGGER.info("\n{}", searchRequestBuilder);
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
long totalHits = searchResponse.getHits().totalHits;
long length = searchResponse.getHits().getHits().length;
LOGGER.info("Total queries to[{}]Bar data,Number of processing data bars[{}]", totalHits, length);
if (searchResponse.status().getStatus() == 200) {
// Resolve Object
return setSearchResponse(searchResponse, highlightField);
}
return null;
}
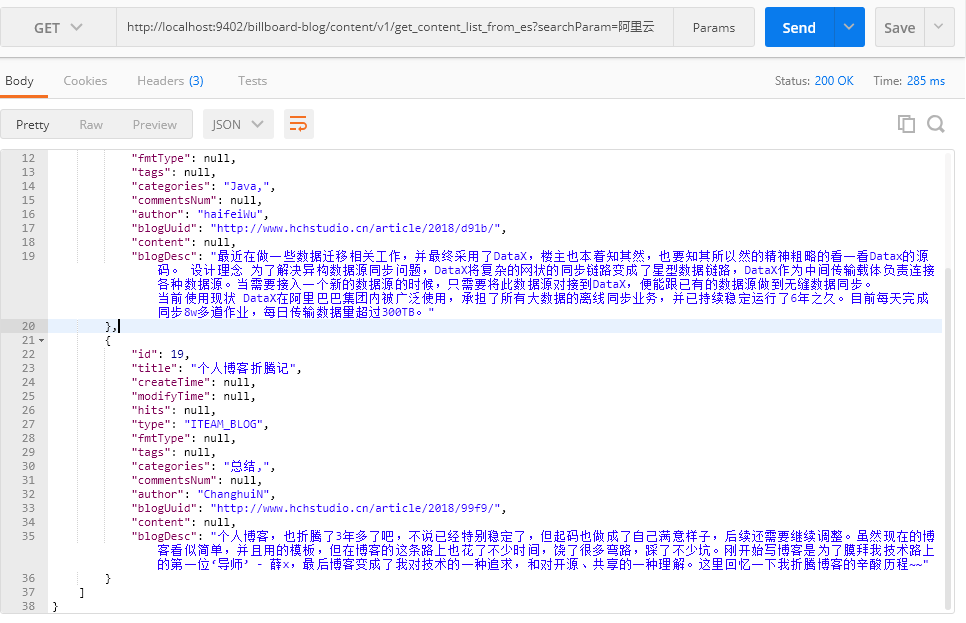
Finally, the owner uses postman to test the web service, as shown in the following figure:
Pits encountered in the process
Setup of IK word breaker
It is important to note here that the version of Elasticsearch must correspond to the version of the ik word breaker, otherwise Elasticsearch will fail.
$ ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip
Then, restart Elastic and the newly installed plug-in will automatically load.
Then, create a new Index specifying the fields that need to be partitioned.This step varies according to the data structure, and the following commands are for this article only.Basically, any Chinese text segments that need to be searched need to be set up separately.
$ curl -X PUT 'localhost:9200/contentindex' -H 'Content-Type: application/json' -d '
{
"mappings": {
"content": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"blog_desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"author": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}'In the code above, you first create a new Index named contentindex with a Type named contentinside.Content has several fields, only four of which are given a participle, content, title, blog_desc, author.
These four fields are all Chinese and of type text, so you need to specify a Chinese word breaker instead of using the default English word breaker.
Settings for MySQL binlog
Because the client side of MySQL used by the building master when running go-mysql-elasticsearch is not consistent with the version of MySQL server side of the data to be exported, resulting in errors, and ultimately solved with the help of the original author of go-mysql-elasticsearch, it is necessary to use the same version of MySQL server and client, because different versions of MySQL have different characteristics, which also results in go-mysql-elasticsearchExporting data is slightly different.
Summary
The whole process is relatively simple, of course, the landlord through the implementation of this function, also has a relatively understanding of es, learned a new skill, there may be small partners interested in the landlord's entire project code, temporarily can not disclose, and so on, the landlord improved and contributed.