I/O Operation of Hadoop: Serialization (I)
1. serialization
(1) Basic definitions
Serialization refers to the conversion of structured objects into byte streams for transmission over the network or permanent storage on disk; deserialization refers to the conversion of byte streams back to structured objects.
(2) Applications
Serialization is mainly used in two areas of distributed data processing: interprocess communication and permanent storage (i.e., data persistence).
(3) Characteristics of RPC serialization mechanism
Hadoop uses RPC to achieve inter-process communication. The serialization mechanism of RPC has the following characteristics:
1) compact
Compact format can make full use of network bandwidth (the scarcest resource in data center) to speed up transmission.
2) fast
It can reduce the cost of serialization and deserialization.
3) Extensibility
New parameters for method calls can be added at any time.
4) Supporting interoperability
Client and server can be implemented in different languages.
2. Writable interface
2.1 Interface Introduction
The org.apache.hadoop.io.Writable interface is the core of the Hadoop serialization mechanism, which defines two methods:
package org.apache.hadoop.io; import java.io.DataOutput; //Binary Output Stream import java.io.DataInput; //Binary input stream import java.io.IOException; public interface Writable { //Serializing objects to binary output streams void write(DataOutput out) throws IOException; //Deserializing objects from binary input streams void readFields(DataInput in) throws IOException; }
There are many classes in Hadoop that implement the Writable interface, such as the IntWritable class, which is a wrapper class for the Java data type int. The method of instantiating an IntWritable object is as follows:
//Law 1: IntWritable writable = new IntWritable(); writable.set(1); //Law two: IntWritable writable = new IntWritable(1);
2.2 example 1
Achieving goals:
Implement a method serialize to display the serialization format of an IntWritable.
Implementation process:
(1) Write MyWritable.java:
import java.io.*; import org.apache.hadoop.util.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.*; public class MyWritable { public static byte[] serialize(Writable writable) throws IOException { /* In this method, the flow of data is from writable.write to DataOutputStream to ByteArray OutputStream. */ ByteArrayOutputStream out = new ByteArrayOutputStream(); DataOutputStream dataout = new DataOutputStream(out); writable.write(dataout); dataout.close(); return out.toByteArray(); } public static void main(String[] args) throws Exception{ IntWritable w1 = new IntWritable(5); byte[] b1 = serialize(w1); System.out.println(StringUtils.byteToHexString(b1)); } }
(2) After compilation, use hadoop command to run this class:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop MyWritable
00000005
2.3 example 2
Achieving goals:
Implement a method deserialize to show the result of an IntWritable reverse sequence.
Implementation process:
(1) Write MyWritable.java:
import java.io.*; import org.apache.hadoop.util.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.*; public class MyWritable { public static byte[] serialize(Writable writable) throws IOException { ByteArrayOutputStream out = new ByteArrayOutputStream(); DataOutputStream dataout = new DataOutputStream(out); writable.write(dataout); dataout.close(); return out.toByteArray(); } public static void deserialize(byte[] bytes, Writable writable) throws IOException { /* The data flow in this method is from byte [] to Byte Array InputStream to DataInputStream to writable.readFields to writable. */ ByteArrayInputStream in = new ByteArrayInputStream(bytes); DataInputStream datain = new DataInputStream(in); writable.readFields(datain); /*writable Deserialize the byte stream of data input into a writable object*/ datain.close(); in.close(); } public static void main(String[] args) throws Exception{ IntWritable w1 = new IntWritable(5); byte[] b1 = serialize(w1); System.out.println(StringUtils.byteToHexString(b1)); IntWritable w2 = new IntWritable(); /*At this point there is no value in w2*/ deserialize(b1, w2); System.out.println(w2.get()); /*Get the object value after the deserialization*/ } }
(2) After compilation, use hadoop command to run this class:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop MyWritable
00000005
5
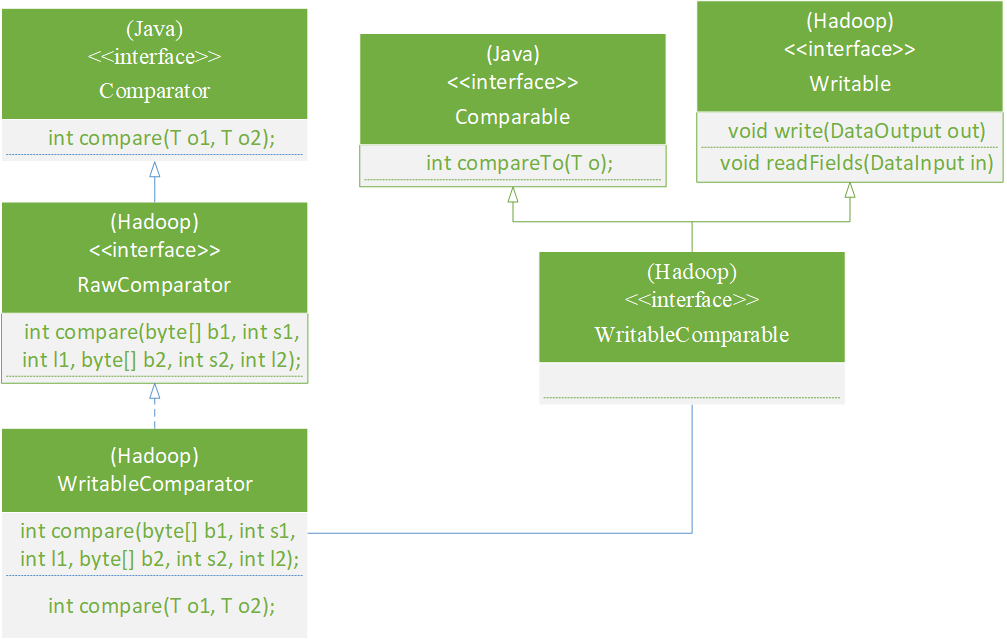
3. Writable Comparable and Writable Comparator
For MapReduce, type comparison is important because there is a key-based sorting stage in the middle. Java provides two interfaces, Comparable and Compparator. Hadoop also provides the corresponding interfaces and classes, which are inherited from the interface provided by Java. Here we will introduce them separately.
3.1 Comparable
(1) java.lang.Comparable interface
In Java, any type that needs to be compared must implement the java.lang.Comparable interface:
package java.lang; public interface Comparable<T> { public int compareTo(T o); }
For example, class Hellow implements the Comparable interface and rewrites the compareTo function:
package come.test.one; public class Hellow implements Comparable{ int i; public Hellow(int j) { i = j; } @Override public int compareTo(Object o) { // TODO Auto-generated method stub Hellow temp = (Hellow)o; if(i == temp.i) { return 0; } else if(i > temp.i) { return 1; } else { return -1; } } }
Test with main function in class hehe:
package come.test.one; public class hehe { public static void main(String[] args) { Hellow h1 = new Hellow(1); Hellow h2 = new Hellow(-6); int k = h1.compareTo(h2); System.out.print(k); //The output k is 1 } }
(2)org.apache.hadoop.io Writable Comparable interface
In Hadoop, org.apache.hadoop.io The Writable Comparable interface is an important interface. It inherits from org.apache.hadoop.io Writable interface and java.lang.Comparable interface:
package org.apache.hadoop.io; public Interface WritableComparable<T> extends Writable,Comparable<T> { }
3.2 Comparator
(1) java.lang.Comparator interface
The java.util.Comparator interface is defined in Java, which is a comparator interface for comparing two objects:
package java.util; public interface Comparator<T> { int compare(T o1, T o2); }
For example, class Hellow implements the Comparator interface and rewrites the compare function:
package come.test.one; import java.util.Comparator; public class Hellow implements Comparator{ int i; public Hellow(int j) { i = j; } @Override public int compare(Object arg0, Object arg1) { // TODO Auto-generated method stub Hellow h1 = (Hellow)arg0; Hellow h2 = (Hellow)arg1; if(h1.i == h2.i) { return 0; } else if(h1.i > h2.i) { return 1; } else { return -1; } } }
The class hehe tests it:
package come.test.one; public class hehe { public static void main(String[] args) { Hellow h1 = new Hellow(1); Hellow h2 = new Hellow(-6); Hellow h3 = new Hellow(2); int i = h3.compare(h1, h2); System.out.println(i); //Output is 1. } }
(2)org.apache.hadoop.io RawComparator interface
Hadoop provides an org.apache.hadoop.io RawComparator interface, which inherits from java.lang.Comparator interface, and adds a new interface method on the basis of Comparator interface:
package org.apache.hadoop.io; import java.util.Comparator; public Interface RawComparator<T> extends Comparator<T> { //New added interface method public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) }
The comparison method defined by the RawComparator interface can be compare d directly at the byte stream level without requiring the byte stream to be deserialized into objects for comparison, so it is much more efficient.
(3)org.apache.hadoop.io WritableComparator class
The WritableComparator class implements the RawComparator interface, which can be used to compare WritableComparable objects. Here is an example.
A. Write MyWritable_1.java:
import java.io.*; import org.apache.hadoop.util.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.*; public class MyWritable_1 { public static byte[] serialize(Writable writable) throws IOException { ByteArrayOutputStream out = new ByteArrayOutputStream(); DataOutputStream dataout = new DataOutputStream(out); writable.write(dataout); dataout.close(); return out.toByteArray(); } public static void main(String[] args) throws Exception{ WritableComparator comparator = WritableComparator.get(IntWritable.class); IntWritable w1 = new IntWritable(5); IntWritable w2 = new IntWritable(10); /*What is called here is the comparator interface method of the Java API, which is compared at the object level.*/ int i = comparator.compare(w1, w2); System.out.println("i is " + i); //ouput is -1 byte[] bytes_1 = serialize(w1); byte[] bytes_2 = serialize(w2); /*What is called here is the comparator interface method of HadoopD RawComparator, which is compared at the byte stream level.*/ int j = comparator.compare(bytes_1, 0, bytes_1.length, bytes_2, 0, bytes_2.length); System.out.println("j is " + j); } }
B. Run this class with the hadoop command:
root@6b08ff31fc7f:/hadoop/hadoop-2.9.1/test/hadoop-io# hadoop MyWritable_1
i is -1
j is -1
As you can see, the results of the two comparisons are the same.
3.3 summary
These interfaces and classes can be illustrated by UML diagrams: