html test paper (including latex) downloaded into word
The main objectives are:
- Share the html format test papers with latex downloaded in word format, and add some flexible typesetting style
- Receive reviews from the masses and get feedback
- Cheat for reward, or github star
Demand Background:
- html test paper with latex formula, downloaded into word format
- word test paper typesetting, paper size, font, sealing line, title, question type, reputation column, etc.
- html renders the same style as word renders (only roughly the same, some of which are not exactly the same)
Programme outline:
Major Scheme: Extract the content of the title in HTML > Convert it to word tag style > (Make test paper template) Fill it into the template > Build word (doc or docx)
- Make freemark Template: Edit the doc and docx sample papers, convert them into xml format, then transform them into ftl files, and write filling logic according to typesetting requirements
- Write freemark Download Program: Select doc or docx template to download according to incoming conditions
- Analyzing the content of html test questions: decomposing the content of the test questions with XPath, extracting the style, and structuring the information
- Translate the structured test content into word tag format: translate html style into the corresponding word tag format, so that it can be filled into the freemark template without violating the grammatical norms of word tag
- Combining the above steps, you can download the HTML test paper into word format, and the source code will be attached at the end of the paper.
Knowledge needed in advance:
- freemark-related grammar knowledge
- Basic knowledge of XPath
- html Tag style knowledge
- Knowledge of word Tag Styles
Detailed implementation steps:
freemark template making:
1. Make a full-style test paper template (doc, docx each one) [Example: A3 full-style template]
Description: Contains all styles of requirements (fonts, seals, titles, Title types, reputation columns, etc.), and can be flexibly controlled in the subsequent development of template display logic.

2. Convert the doc, docx format template to xml
The doc format saves the file as Word XML document (*. xml) format, and opens it with Notepad++ and other similar formats (installing XML Tools plug-in in NotePad++, which can format the XML file, which is very useful for subsequent work). [Example diagram, folded up, the general structure is as follows]
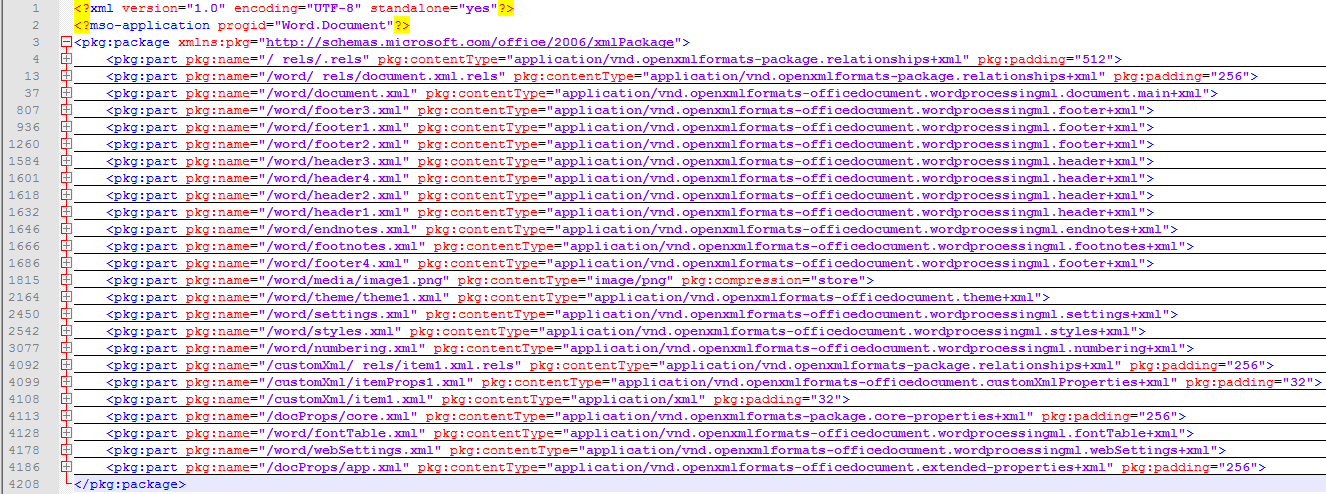
1. A brief introduction to the structure of word xml (purely personal guess, not official definition, if you want to know more about the structure and find formal information), the following is only the part we used.
· pkg:part:/word/_rels/document.xml.rels: Used to define references to pkg:part such as header, footer, styles, image, etc.
Description: Header and footer can define more than one image path and reference that need to be displayed in word.
· pkg:part:/word/document.xml: The main content presented in word except header and footer is in this part (the most important part, the format of which is introduced later).
· pkg:part:/word/footer.xml: footer section, set the pages of the test paper, a total of several pages
· pkg:part:/word/header.xml: Header section, set up test paper sealing line
· pkg:part:/word/styles.xml: style, default font, etc.
· pkg:part:/word/media/image.png: picture content (base64). Put the picture in the / word/media folder in docx
A template in docx format is decompressed with a decompression tool. (Don't be surprised. Written correctly, it is decompressed. Dox is a compressed file. It is a compressed file that decomposes every structure block of the original doc's xml into a separate file.) [Example: The structure of the sample file is as follows]

word Folder Files
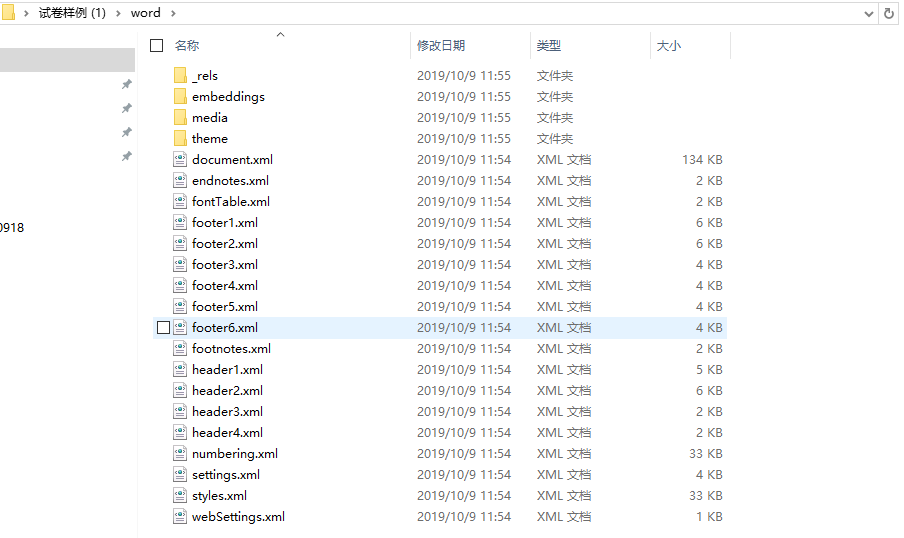
The structure of docx is roughly the same as that of each pkg: part in doc separately divided into files, placed in a folder of a certain structure, and finally compressed. Each block has the same function as the corresponding pkg: part in doc.
Dox has [Content_Types].xml files: Define image types, and other pkg:part
Text: A brief introduction to tags used in/word/document.xml:
1>Paragraphs: <w:p>: Paragraphs; <w:pPr>: Paragraph Style; <w:r>: Content Part; <w:rPr>: Content Style; <w:t>: Text Content
<w:p w:rsidR="004D42A0" w:rsidRDefault="005F1054"> <w:pPr> <w:jc w:val="center"/> <w:rPr> <w:rFonts w:eastAsia="Blackbody"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> </w:pPr> <w:r w:rsidRPr="00771D19"> <w:rPr> <w:rFonts w:eastAsia="Blackbody" w:hint="eastAsia"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> <w:t>school year</w:t> </w:r> </w:p>
2 > Pictures: <w:pict>: Picture Label; <v:shape>: Picture Style; <v:imagedata>: Introducing Pictures (Picture id defined by/word/_rels/document.xml.rels)
<w:r> <w:pict> <v:shape id="_x0000768de9d0ea6111e98c2a28843b052b2f" type="_x0000_t75" style="width:85pt;height:43pt"> <v:imagedata r:id="rId768de9d0ea6111e98c2a28843b052b2f" o:title="2"/> </v:shape> </w:pict> </w:r>
3 > Table:
<w:tbl> <w:tblPr> <w:tblW w:w="0" w:type="auto"/> <w:tblLook w:val="04A0" w:firstRow="1" w:lastRow="0" w:firstColumn="1" w:lastColumn="0" w:noHBand="0" w:noVBand="1"/> </w:tblPr> <w:tblGrid> <w:gridCol w:w="222"/> <w:gridCol w:w="1376"/> </w:tblGrid> <w:tr w:rsidR="00A93926" w:rsidTr="00682485"> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRDefault="00286E3F" w:rsidP="00A93926"/> </w:tc> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> <w:vAlign w:val="center"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRPr="00A93926" w:rsidRDefault="00BF47F0" w:rsidP="00A93926"> <w:pPr> <w:rPr> <w:b/> </w:rPr> </w:pPr> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>I.</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t xml:space="preserve"> </w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>Answer questions</w:t> </w:r> </w:p> </w:tc> </w:tr> </w:tbl>
4 > Latx converted word formula: omml:
<m:oMath> <m:f> <m:fPr> <m:ctrlPr> <w:rPr> <w:sz w:val="30"/> </w:rPr> </m:ctrlPr> </m:fPr> <m:num> <m:r> <w:rPr> <w:sz w:val="30"/> </w:rPr> <m:t>a</m:t> </m:r> </m:num> <m:den> <m:r> <w:rPr> <w:sz w:val="30"/> </w:rPr> <m:t>sinA</m:t> </m:r> </m:den> </m:f> </m:oMath>
5 > Paper size, single or double columns, header, footer display settings:
<w:header Reference>: Header Settings
<w:footerReference>: Footer Settings
<w:pgSz>: Paper width and height settings, where you can adjust A3,A4,B4,B5 and other styles
<w:pgMar>: Page margins and other settings
<w:cols>: Single and Double Column Settings
<w:docGrid>: Column Settings
<w:p w:rsidR="005320E8" w:rsidRDefault="00286E3F" w:rsidP="00B33EF9"> <w:pPr> <w:sectPr w:rsidR="005320E8" w:rsidSect="007A55E5"> <w:headerReference w:type="even" r:id="rId9"/> <w:headerReference w:type="default" r:id="rId10"/> <w:footerReference w:type="even" r:id="rId11"/> <w:footerReference w:type="default" r:id="rId12"/> <w:pgSz w:w="23814" w:h="16840" w:orient="landscape" w:code="9"/> <w:pgMar w:top="1134" w:right="1000" w:bottom="1134" w:left="1000" w:header="851" w:footer="692" w:gutter="0"/> <w:cols w:num="2" w:sep="1" w:space="425"/> <w:docGrid w:type="lines" w:linePitch="312"/> </w:sectPr> </w:pPr> </w:p>
Above is a brief introduction of word test paper template and word structure and label, which is very important for word generation. It involves a lot of content, and I don't know much about it. It is a try-out one by one. If there are other requirements, you can check the document or control the variables, open word edit to change the style you want to xml and compare with the original xml to find out the different parts of the lock. Style settings
2. Converting xml template to ftl template of freemark
1. doc's xml file directly changes the suffix to. ftl, and deletes too much information in the template (each later filled picture, paragraph style keeps one), so that the simplest template can be put into the project.
2) docx XML file will take out the body part of / word/document.xml. If the header and footer style can be flexibly changed, it can also be taken out as a template and put into the project.

3. Writing data filling logic (with some basic freemark grammar)
doc template data filling logic writing description:
1>: Picture Reference Writing: In the / word/_rels/document.xml.rels section, the dynamic introduction of picture links, while the picture base64 should also be introduced into pkg:part
<pkg:part pkg:name="/word/_rels/document.xml.rels" pkg:contentType="application/vnd.openxmlformats-package.relationships+xml" pkg:padding="256"> <pkg:xmlData> <Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"> <Relationship Id="rId8" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/header" Target="header2.xml"/> .......... <#list relations.relationshipStr as rs> ${rs} </#list> </Relationships> </pkg:xmlData> </pkg:part>
2>: Fill in the title content: in the / word/document.xml section
<w:p w:rsidR="00C93DDE" w:rsidRPr="00771D19" w:rsidRDefault="00BF47F0" w:rsidP="00C93DDE"> <w:pPr> <w:jc w:val="center"/> <w:rPr> <w:rFonts w:eastAsia="Blackbody"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> </w:pPr> <w:r w:rsidRPr="00771D19"> <w:rPr> <w:rFonts w:eastAsia="Blackbody" w:hint="eastAsia"/> <w:b/> <w:sz w:val="30"/> <w:szCs w:val="30"/> </w:rPr> <w:t>${(mainTitle.mainTitleName)!'XXXX School year XX School XX Examination'}</w:t> </w:r> </w:p> <#list questionsList as qMap> <w:p w:rsidR="00A81065" w:rsidRDefault="00BF47F0" w:rsidP="00744A41"> <w:pPr> <w:pStyle w:val="a7"/> <w:ind w:firstLineChars="0"/> <w:textAlignment w:val="center"/> <w:spacing w:line="360" w:lineRule="auto"/> </w:pPr> ${(qMap.questionContent)!""} </w:p> </#list>
Basically, the operation of if, else, and circular list can satisfy the basic needs. No longer listing, as long as the correct style and style location can be found, it can be completed.
Download word program according to freemark template.
1. Introducing freemarker jar package
<dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.26-incubating</version> </dependency>
2. Template reading
public class PaperDownloadSeting { private static Configuration configuration = null; private static Map<String, Template> allTemplate = null; private static Logger logger= LoggerFactory.getLogger(PaperDownloadSeting.class.getName()); static{ configuration = new Configuration(Configuration.VERSION_2_3_0); configuration.setDefaultEncoding("UTF-8"); configuration.setClassForTemplateLoading(PaperDownloadSeting.class, "/freemarkmould/papermould/"); allTemplate = new HashMap<String,Template>(); try{ allTemplate.put("docmould", configuration.getTemplate("docmould.ftl")); allTemplate.put("docxDocumentMould", configuration.getTemplate("docxmould/document.ftl")); allTemplate.put("docxHeader1Mould", configuration.getTemplate("docxmould/header1.ftl")); allTemplate.put("docxHeader2Mould", configuration.getTemplate("docxmould/header2.ftl")); allTemplate.put("docxStylesMould", configuration.getTemplate("docxmould/styles.ftl")); }catch(IOException e){ e.printStackTrace(); throw new RuntimeException(e); } }
3. Data Filling, word Flow Generation
/** *@Desc: Get word file stream, paperMap: Paper information processed into word style, out: word output stream */ public static void getwordFileOutPutStream(Map<String, Object> paperMap,String docType, OutputStream out){ try{ Writer w = new OutputStreamWriter(out,"utf-8"); if(docType.equals("doc")) { Template t = allTemplate.get("docmould"); t.process(paperMap,w);//freemark fills the template with data w.close(); deleteTmpImages(paperMap.get("tempMediaPath").toString()); } if(docType.equals("docx")) { ZipOutputStream zipout = new ZipOutputStream(out); zipdocx(paperMap,zipout); } }catch(Exception e){ e.printStackTrace(); throw new RuntimeException(e); }finally { try { out.close(); deleteTmpImages(paperMap.get("tempMediaPath").toString()); } catch (Exception e2) { e2.printStackTrace(); } } } /** *@Desc: docx Download the test paper, decompress the static template, replace the text, header, footer, style and other template files with the filled template, and compress them. */ @SuppressWarnings("unchecked") public static void zipdocx(Map<String, Object> paperMap,ZipOutputStream zipout) throws IOException, TemplateException, URISyntaxException { Map<String, Object> relationsMap= JsonUtil.fromJson(JsonUtil.toJson(paperMap.get("relations")), Map.class); List<String> relationshipStr=JsonUtil.fromJson(JsonUtil.toJson(relationsMap.get("relationshipStr")), List.class); Template doct = allTemplate.get("docxDocumentMould");//Text Template Template hea1t = allTemplate.get("docxHeader1Mould");//Header Style Template hea2t = allTemplate.get("docxHeader2Mould");//Another header style Template stylt = allTemplate.get("docxStylesMould");//Global Style Template Writer w = new OutputStreamWriter(zipout,"utf-8"); File file=makeDirs(); ZipFile zipFile = new ZipFile(file); Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries(); int len = -1; byte[] buffer = new byte[1024]; while (zipEntrys.hasMoreElements()) { ZipEntry next = zipEntrys.nextElement(); zipout.putNextEntry(new ZipEntry(next.toString())); if ("word/document.xml".equals(next.toString())) { doct.process(paperMap,w);//Fill in the text of the test paper to the template } else if ("word/header1.xml".equals(next.toString())) { hea1t.process(paperMap,w);//Fill the header style into the template } else if ("word/header2.xml".equals(next.toString())) { hea2t.process(paperMap,w);//Fill the header style into the template } else if ("word/styles.xml".equals(next.toString())) { stylt.process(paperMap,w);//Filling global styles into templates } else { //Copy other files in InputStream is = zipFile.getInputStream(next); while ((len = is.read(buffer)) != -1) { zipout.write(buffer, 0, len); } //towards Relationships Write picture links if ("word/_rels/document.xml.rels".equals(next.toString())) { for(String str:relationshipStr) { zipout.write(str.getBytes()); } String endStr="</Relationships>"; zipout.write(endStr.getBytes()); } is.close(); } } //to word/media/Add pictures below String tempMediaPath=paperMap.get("tempMediaPath").toString(); File imagesFile=new File(tempMediaPath); if(tempMediaPath!=null&&tempMediaPath!=""&&imagesFile.exists()) { File[] imagesList = imagesFile.listFiles(); if(imagesList.length>0) { for(File tmpFile:imagesList) { if (tmpFile.isFile()) { zipout.putNextEntry(new ZipEntry("word/media/"+tmpFile.getName())); InputStream input=new FileInputStream(tmpFile); while ((len = input.read(buffer)) != -1) { zipout.write(buffer, 0, len); } input.close(); } tmpFile.delete(); } } } imagesFile.delete(); w.close(); zipout.close(); zipFile.close(); } /** *@Desc: Create temporary folder of word picture and return docx static template file. Place static template file in temporary directory (static template can be placed in other places separately, this project is placed under resources for convenience) */ public static File makeDirs() { String filePath=PaperDownloadSeting.class.getClassLoader().getResource("").getPath().replace("classes", "tempfile"); String fileName="docxmould.docx"; File file=new File(filePath, fileName); if(file.exists()) { if(file.length()>0) { return file; } file.delete(); } file.getParentFile().mkdirs(); try { file.createNewFile(); OutputStream out=new FileOutputStream(file); File modulFile = ResourceUtils.getFile("classpath:freemarkmould/staticmould/docxmould.docx"); InputStream in= new FileInputStream(modulFile); byte[] buffer = new byte[1024]; int bytesToRead = -1; while ((bytesToRead = in.read(buffer)) != -1) { out.write(buffer, 0, bytesToRead); } in.close(); out.flush(); out.close(); } catch (Exception e) { e.printStackTrace(); } return file; } /** *@Desc: Delete temporary pictures */ public static void deleteTmpImages(String floderPath) { File imagesFloder=new File(floderPath); if(floderPath==null||floderPath.equals("")||!imagesFloder.exists()) {return;} File[] imagesList = imagesFloder.listFiles(); if(imagesList.length<1) {imagesFloder.delete();return;} for(File tmpFile:imagesList) { if (tmpFile.isFile()) {tmpFile.delete();} } imagesFloder.delete(); }
So we can fill the template with the simple data of the text and download it to word. Next, what we need to do is to convert the test questions in html format into the corresponding word format and fill it in the template.
Analyse the content of html test questions and structure them:
1. Introducing XPath jar packages
<dependency> <groupId>cn.wanghaomiao</groupId> <artifactId>JsoupXpath</artifactId> <version>2.2</version> </dependency>
2. Analyzing HTML Test Content
/** * @Desc: Label Node **/ public class Node { private String nodeName; private Integer nodeType;//1:Label nodes; 2:Text Node private Map<String,String> attrMap; private String nodeText; private String nodeStr; private String childStr; private String nodeParent; private List<Node> childNodeList; public String getNodeName() { return nodeName; } public void setNodeName(String nodeName) { this.nodeName = nodeName; } public Integer getNodeType() { return nodeType; } public void setNodeType(Integer nodeType) { this.nodeType = nodeType; } public Map<String, String> getAttrMap() { return attrMap; } public void setAttrMap(Map<String, String> attrMap) { this.attrMap = attrMap; } public String getNodeText() { return nodeText; } public void setNodeText(String nodeText) { // nodeText=nodeText.replaceAll("[\n\r\t]",""); nodeText=nodeText.trim(); if(nodeText==null||nodeText.equals("")) {nodeText=null;} this.nodeText = nodeText; } public String getNodeStr() { return nodeStr; } public void setNodeStr(String nodeStr) { nodeStr=nodeStr.replaceAll("[\n\r\t]",""); this.nodeStr = nodeStr; } public String getChildStr() { return childStr; } public void setChildStr(String childStr) { this.childStr = childStr; } public String getNodeParent() { return nodeParent; } public void setNodeParent(String nodeParent) { this.nodeParent = nodeParent; } public List<Node> getChildNodeList() { return childNodeList; } public void setChildNodeList(List<Node> childNodeList) { this.childNodeList = childNodeList; } }
Parsing html
/** *@Author: maoyuwei *@Date: 2019/9/7 15:29 *@Desc: Extracting First-level Label Nodes */ public static List<Node> htmlStrToNodes(String htmlStr){ htmlStr.replace("##","");//## In order to extract the separator of text, it cannot appear in the title. JXDocument jxDocument=JXDocument.create(htmlStr); String bodyPath = "/body"; JXNode bodyNode=jxDocument.selNOne(bodyPath); Node node = new Node(); node.setNodeType(1); node.setNodeName(bodyNode.asElement().nodeName()); node.setChildStr(bodyNode.asElement().html()); List<Node> nodes=childStrToNodes(node,bodyNode); if(nodes==null||nodes.size()<1) { nodes=new ArrayList<Node>(); nodes.add(node); } return nodes; } /** *@Author: maoyuwei *@Date: 2019/9/7 15:29 *@Desc: Extract sublabel nodes under the current label */ public static List<Node> childStrToNodes(Node node,JXNode jxNode){ String childPath = "/child::*"; List<JXNode> childJXNodeList=jxNode.sel(childPath); if(childJXNodeList==null||childJXNodeList.size()<1){ if(node.getChildStr()!=null||!node.getChildStr().equals("")){ node.setNodeText(node.getChildStr().replaceAll("[\n\r\t]","")); } return null; } List<Node> tempChildNodes=new ArrayList<Node>(); String currentHtmlStr=node.getChildStr(); int index=0; for(JXNode childJXNode:childJXNodeList) { String childNodeStr=childJXNode.toString(); //Markup native text int beginIndex=currentHtmlStr.indexOf(childNodeStr); if(beginIndex<0) {continue;} currentHtmlStr=currentHtmlStr.substring(0,beginIndex)+"##<"+index+">"+currentHtmlStr.substring(beginIndex+childNodeStr.length()); index++; Node childNode=new Node(); Element element=childJXNode.asElement(); childNode.setNodeName(element.nodeName()); childNode.setNodeStr(childJXNode.toString()); childNode.setNodeParent(node.getNodeName()); childNode.setChildStr(element.html()); childNode.setNodeType(1); //Attributes sink step by step, and each child tag has a parent attribute Map<String,String> attrMap= JsonUtil.fromJson(JsonUtil.toJson(node.getAttrMap()), Map.class); if (attrMap==null) {attrMap=new HashMap<String,String>();}
if (childNode.getNodeName()!=null&&childNode.getNodeName().equals("tr")) {attrMap=new HashMap<>();}//Do not write parent attributes in table tag tr if(element.attributes()!=null) { for(Attribute attribute: element.attributes().asList()) { if(attribute.getKey().equals("style")){ String style=attrMap.get(attribute.getKey())==null?"":attrMap.get(attribute.getKey()); attrMap.put(attribute.getKey(),style+" "+attribute.getValue()); }else { attrMap.put(attribute.getKey(),attribute.getValue()); } } } //Attribute Writing with Label if(childNode.getNodeName()!=null&&"b i u B I U".contains(childNode.getNodeName())){ String style=attrMap.get("style")==null?"":attrMap.get("style"); attrMap.put("style",style+" _"+childNode.getNodeName().toLowerCase()); } childNode.setAttrMap(attrMap); childStrToNodes(childNode,childJXNode); tempChildNodes.add(childNode); } //Extract the text of this level and store it in sequence with the label nodes of this level String[] textList=currentHtmlStr.split("##"); List<Node> childNodes=new ArrayList<Node>(); for(int i=0;i<textList.length;i++){ String textStr=textList[i]; if(textStr==null||textStr.equals("")) {continue;} String regex="(?<=<)[0-9]+(?=>)"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(textStr); Integer position=null; if(matcher.find()) { String positionStr=matcher.group(); position=Integer.parseInt(positionStr.toString()); } if(position!=null&&position<tempChildNodes.size()){ childNodes.add(tempChildNodes.get(position)); } textStr=textStr.replaceAll("<[0-9]+>",""); textStr=textStr.replaceAll("[\n\r\t]",""); if(textStr==null||textStr.equals("")) {continue;} Node textNode=new Node(); textNode.setNodeType(2); textNode.setNodeText(textStr); Map<String,String> attrMap= JsonUtil.fromJson(JsonUtil.toJson(node.getAttrMap()), Map.class); textNode.setAttrMap(attrMap); textNode.setNodeParent(node.getNodeName()); childNodes.add(textNode); } node.setChildNodeList(childNodes); return childNodes; }
The above code can structure the title of html. Next, we translate the structured title into word format.
Translate structured text into word format:
This block has a lot of code, and it's not good enough to stick. You can see my source code (see the following classes: com pdl paperdownload wordpapermake htmltowordhandle). Here's a brief introduction of this block:
1. To parse each node in a structured essay into word format, we have to summarize the corresponding relationship between HTML style and word style.
Following is a brief list of the corresponding styles:
· The green section below sets the position for the word paragraph style; the yellow section sets the position for the content style.
<w:p w:rsidR="00A81065" w:rsidRDefault="00BF47F0"> <w:pPr> <w:ind w:leftChars="130" w:left="273"/> <w:textAlignment w:val="center"/> <w:spacing w:line="360" w:lineRule="auto"/> </w:pPr> <w:r w:rsidRPr="00043B54"> <w:t xml:space="preserve"> [Analysis]</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>item analysis</w:t> </w:r> </w:p>
· Center: word paragraph style
<w:jc w:val="center"/>
· First line indentation: word paragraph style
<w:ind w:firstLineChars="200" w:firstLine="480"/>
· Right alignment: word paragraph style
<w:jc w:val="right"/>
· Coarsening: Content Style
<w:b/>
· italics: content style
<w:i/>
· Underline: Content Style
<w:u w:val="single"/>
· Allow space display settings in content (green part is settings part)
<w:r> <w:t xml:space="preserve"> hello pretty girl!</w:t> </w:r>
· Subsup: Content Style
<w:vertAlign w:val="superscript"/> <w:vertAlign w:val="subscript"/>
Other formats:
· The omml formula is placed in the label of the <w:p> paragraph. (For the method of converting latex to word formula omml, see my other article to share: https://www.cnblogs.com/maoyuwei/p/10874773.html)
· The picture part is placed in the label of <w:p> paragraph.
textAlignment w:val="center" is in the middle of the picture line
style="width:85pt;height:43pt" sets the width and height of the picture
<v:imagedata r:id="rId768de9d0ea6111e98c2a28843b052b2f" Sets the Picture Reference Address
Note: The image of doc has to fill its base64 code and reference definition into the template; the image of docx is placed in the word media folder, and the reference definition is filled into the template.
<w:p w:rsidR="00A81065" w:rsidRDefault="00BF47F0" w:rsidP="00744A41"> <w:pPr> <w:textAlignment w:val="center"/> <w:rPr> <w:rFonts w:hint="eastAsia"/> </w:rPr> </w:pPr> <w:r> <w:pict> <v:shape id="_x0000768de9d0ea6111e98c2a28843b052b2f" type="_x0000_t75" style="width:85pt;height:43pt"> <v:imagedata r:id="rId768de9d0ea6111e98c2a28843b052b2f" o:title="2"/> </v:shape> </w:pict> </w:r> </w:p>
· The table is placed at the same level as <w:p>.
w:gridCol w:w="222" column width setting
< w: tr > is equivalent to < tr > in html table
< w: TC > is equivalent to < td > in html table
Note: word merges cells in a different way than HTML. It's not easy to describe. Try it more and you'll find the rules.
<w:tbl> <w:tblPr> <w:tblW w:w="0" w:type="auto"/> <w:tblLook w:val="04A0" w:firstRow="1" w:lastRow="0" w:firstColumn="1" w:lastColumn="0" w:noHBand="0" w:noVBand="1"/> </w:tblPr> <w:tblGrid> <w:gridCol w:w="222"/> <w:gridCol w:w="1376"/> </w:tblGrid> <w:tr w:rsidR="00A93926" w:rsidTr="00682485"> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRDefault="00286E3F" w:rsidP="00A93926"/> </w:tc> <w:tc> <w:tcPr> <w:tcW w:w="0" w:type="auto"/> <w:vAlign w:val="center"/> </w:tcPr> <w:p w:rsidR="00A93926" w:rsidRPr="00A93926" w:rsidRDefault="00BF47F0" w:rsidP="00A93926"> <w:pPr> <w:rPr> <w:b/> </w:rPr> </w:pPr> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>I.</w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t xml:space="preserve"> </w:t> </w:r> <w:r> <w:rPr> <w:rFonts w:hint="eastAsia"/> <w:b/> </w:rPr> <w:t>Answer questions</w:t> </w:r> </w:p> </w:tc> </w:tr> </w:tbl>
Also note that html has some special characters that need to be escaped in advance, otherwise word will not open.
=>   < => < > => > & => & " => " ' => ' ¢ => ¢ £ => £ ¥ => ¥ € => € § => § © => © ® => ® ™ => ™ × => × ÷ => ÷   =>     =>   Α => Α Γ => Γ Ε => Ε Η => Η Ι => Ι Λ => Λ Ν => Ν Ο => Ο Ρ => Ρ Τ => Τ Φ => Φ Ψ => Ψ α => α γ => γ ε => ε η => η ι => ι λ => λ ν => ν ο => ο ρ => ρ σ => σ υ => υ χ => χ ω => ω ϒ => ϒ • => • ′ => ′ ‾ => ‾ ℘ => ℘ ℜ => ℜ ℵ => ℵ ↑ => ↑ ↓ => ↓ ↵ => ↵ ⇑ => ⇑ ⇓ => ⇓ ∀ => ∀ ∃ => ∃ ∇ => ∇ ∉ => ∉ ∏ => ∏ − => − √ => √ ∞ => ∞ ∧ => ⊥ ∩ => ∩ ∫ => ∫ ∼ => ∼ ≈ => ≅ ≡ => ≡ ≥ => ≥ ⊃ => ⊃ ⊆ => ⊆ ⊕ => ⊕ ⊥ => ⊥ ⌈ => ⌈ ⌊ => ⌊ ◊ => ◊ ♣ => ♣ ♦ => ♦ ¡ => ¡ £ => £ ¥ => ¥ § => § © => © « => « ­ => ­ ¯ => ¯ ± => ± ³ => ³ µ => µ Β => Β Δ => Δ Ζ => Ζ Θ => Θ Κ => Κ Μ => Μ Ξ => Ξ Π => Π Σ => Σ Υ => Υ Χ => Χ Ω => Ω β => β δ => δ ζ => ζ θ => θ κ => κ μ => μ ξ => ξ π => π ς => ς τ => τ φ => φ ψ => ψ ϑ => ϑ ϖ => ϖ … => … ″ => ″ ⁄ => ⁄ ℑ => ℑ ™ => ™ ← => ← → => → ↔ => ↔ ⇐ => ⇐ ⇒ => ⇒ ⇔ => ⇔ ∂ => ∂ ∅ => ∅ ∈ => ∈ ∋ => ∋ ∑ => − ∗ => ∗ ∝ => ∝ ∠ => ∠ ∨ => ⊦ ∪ => ∪ ∴ => ∴ ≅ => ≅ ≠ => ≠ ≤ => ≤ ⊂ => ⊂ ⊄ => ⊄ ⊇ => ⊇ ⊗ => ⊗ ⋅ => ⋅ ⌉ => ⌉ ⌋ => ⌋ ♠ => ♠ ♥ => ♥ =>   ¢ => ¢ ¤ => ¤ ¦ => ¦ ¨ => ¨ ª => ª ¬ => ¬ ® => ® ° => ° ² => ² ´ => ´ · => · ø => ø á => á
According to the above rules, combined with other requirements of the rules, do the translation of html structured topic, specific translation code too much is not shown here.
Source code: https://github.com/mao-yuwei/paper_download
Note: For the spring boot project, visit localhost:8080 to download the sample page after launching:
Choose test paper, download format, paper size, size, answer style.
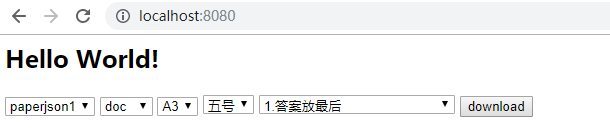
Paper json data in: resources paperdata
Request method location: com pdl paperdownload main. Java
Summary:
The whole process is a process of understanding HTML structure, understanding word structure, then translating, stitching up a complete word.
Problem: There are often format errors or special characters that make word hard to open, which is a big pain point, but after continuous optimization, such situations are becoming fewer and fewer.
Another share of Latx to word formula omml that will be used: https://www.cnblogs.com/maoyuwei/p/10874773.html
If the above content is still useful to you or can be used in the future, please go here, don't be too interesting.

Sisters without Blue Friends, Men ( Manual Dog Head) or Problem Apes, please come here: mao_yuwei@163.com