[I. project objectives]
adopt How to use Python to grab QQ music data (the first play) We have realized to obtain the song name, album name and play link of the songs with the specified page number in the single ranking of the specified singer of QQ music.
adopt How to use Python to grab QQ music data We have realized to obtain the lyrics of the specified songs of QQ music and the hot reviews of the front page of the specified songs.
This time, we will get more comments on the basis of the project (2) and generate a cloud map of words, forming a manual to teach you to use Python to grab QQ music data (the third play).
[II. Required library]
The main libraries involved are: requests, json, wordcloud, jieba
If you need to change the background picture of cloud picture, you need numpy library and PIL Library (pipingstall pilot)
3. Project realization
1. First of all, the following is the project (2) to obtain the code of the hot review of the designated song homepage;
def get_comment(i):
url_3 = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
#Mark the device and browser from which the request is sent
}
params = {'g_tk_new_20200303': '5381', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'GB2312', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0', 'cid': '205360772', 'reqtype': '2', 'biztype': '1', 'topid': id, 'cmd': '8', 'needmusiccrit': '0', 'pagenum': '0', 'pagesize': '25', 'lasthotcommentid': '', 'domain': 'qq.com', 'ct': '24', 'cv': '10101010'}
res_music = requests.get(url_3,headers=headers,params=params)
#Initiate a request
js_2 = res_music.json()
comments = js_2['hot_comment']['commentlist']
f2 = open(i+'comment.txt','a',encoding='utf-8') #Store in txt for i in comments:
comment = i['rootcommentcontent'] + '\n-----------------\n'
f2.writelines(comment)
# print(comment)f2.close()2. Next, consider how to get the following comments. The figure below is the parms parameter of the item (2) comment page;
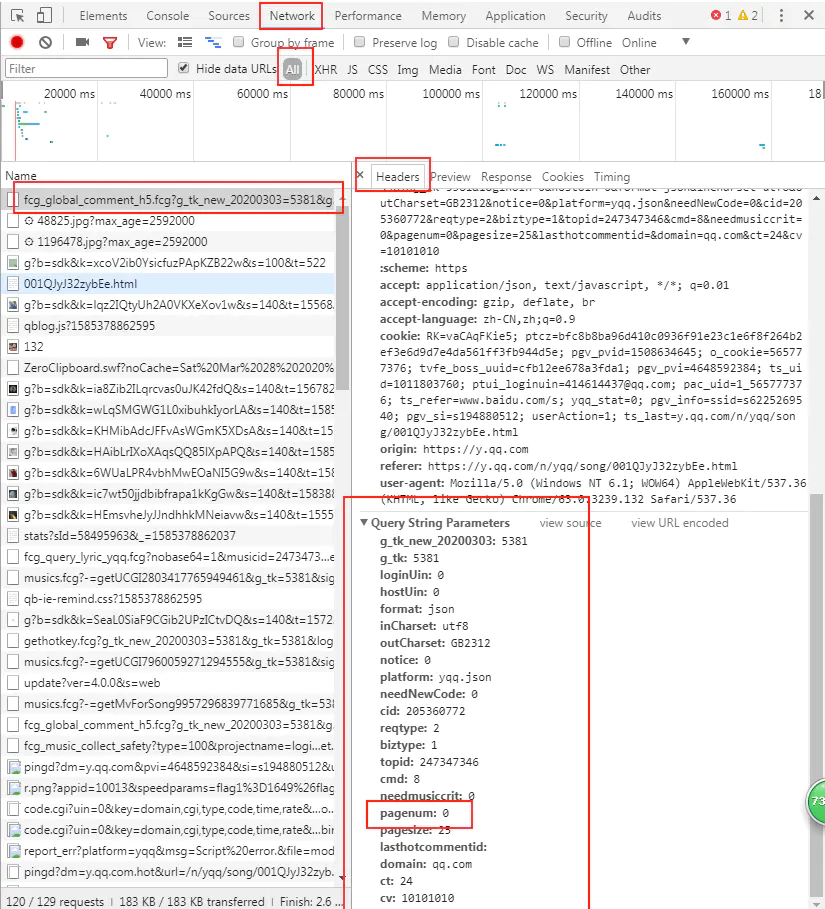
image
3. The page can't select the page number of the comment. To see the following comments, click "click to load more" one time. We can click to see what's the change of parms.
image
4. Here's a trick. First click the clear button as shown in the figure below, clear the network interface, and then click "click to load more", you can find the data on the second page directly.
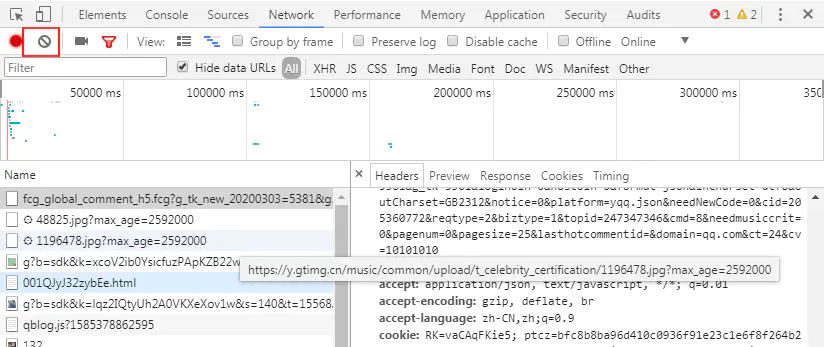
image
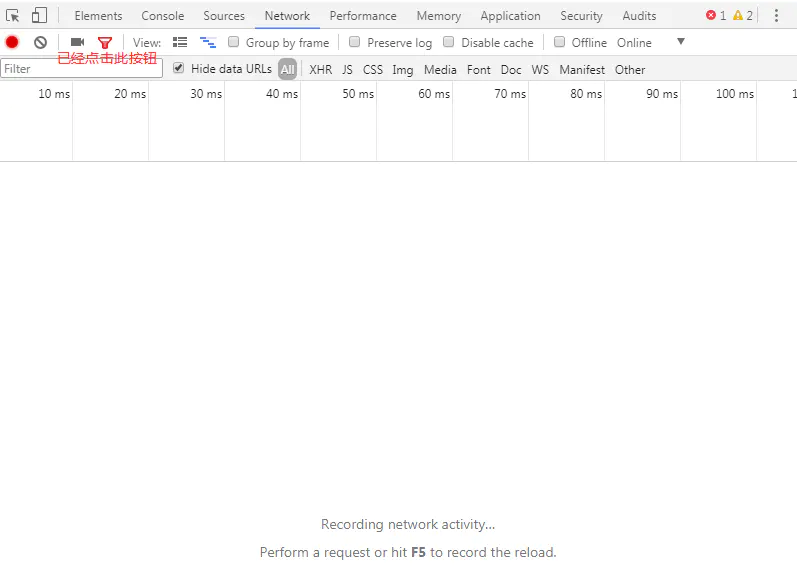
image
5. Click load more and the following figure will appear.
image
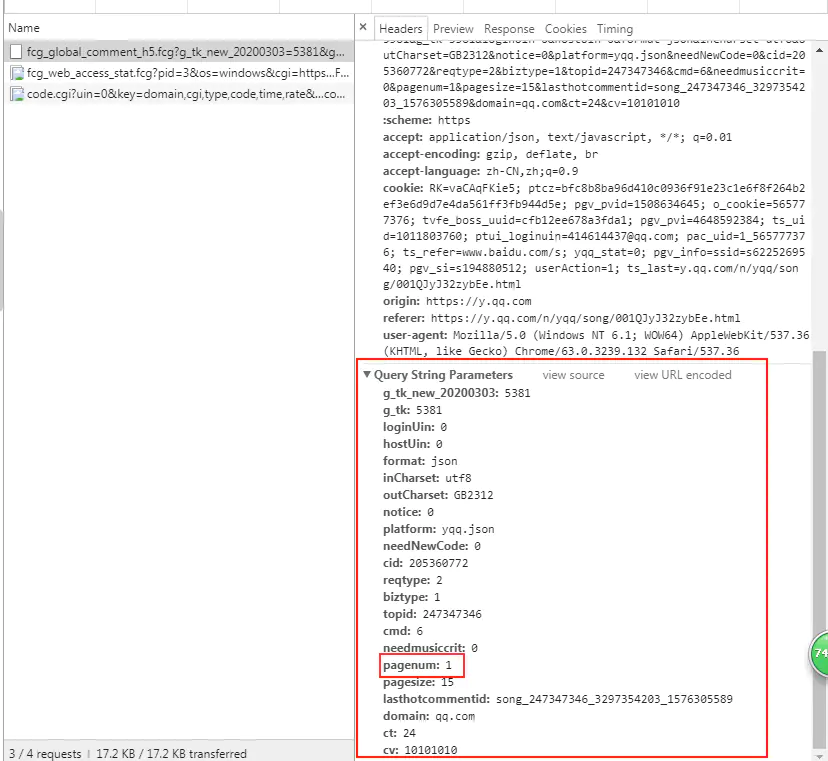
image
6. It is found that not only pagenum has changed, but also cmd and pagesize. Let's look at the third page for the problem of that parameter;
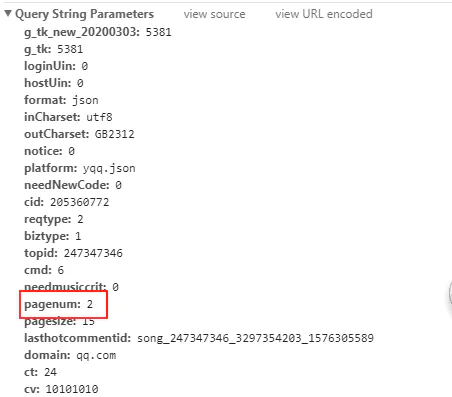
image
7. Only pagenum has changed. Let's try to change pagenum to "0". Other things remain unchanged. Can the data on the first page be displayed normally?
image
First page first comment

image
Last comment on the first page

image
8. If it can be displayed normally, then the idea is determined: write a for loop assignment to pagenum with parms on the second page, and grab the comments to txt with reference to item (2).
9. Code implementation: in order not to cause too much pressure on the server, we only crawl 20 pages of data this time.
import requests,json
def get_id(i):
global id
url_1 = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
#This is the url to request song Reviews
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
params = {'ct': '24', 'qqmusic_ver': '1298', 'new_json': '1', 'remoteplace': 'txt.yqq.song', 'searchid': '71600317520820180', 't': '0', 'aggr': '1', 'cr': '1', 'catZhida': '1', 'lossless': '0', 'flag_qc': '0', 'p': '1', 'n': '10', 'w': i, 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'utf-8', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0'}
res_music = requests.get(url_1,headers=headers,params=params)
json_music = res_music.json()
id = json_music['data']['song']['list'][0]['id']
return id # print(id)def get_comment(i):
url_3 = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
f2 = open(i+'comment.txt','a',encoding='utf-8') #Store in txt for n in range(20):
params = {'g_tk_new_20200303': '5381', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'GB2312', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0', 'cid': '205360772', 'reqtype': '2', 'biztype': '1', 'topid': '247347346', 'cmd': '6', 'needmusiccrit': '0', 'pagenum':n, 'pagesize': '15', 'lasthotcommentid': 'song_247347346_3297354203_1576305589', 'domain': 'qq.com', 'ct': '24', 'cv': '10101010'}
res_music = requests.get(url_3,headers=headers,params=params)
js_2 = res_music.json()
comments = js_2['comment']['commentlist']
for i in comments:
comment = i['rootcommentcontent'] + '\n-----------------\n'
f2.writelines(comment)
# print(comment)
f2.close()
input('Download succeeded, press enter to exit!')def main(i):
get_id(i)
get_comment(i)main(i = input('Please enter the song name to query lyrics:'))10. Cloud code
from wordcloud import WordCloudimport jiebaimport numpyimport PIL.Image as Image #The above two libraries are for changing the background pictures of cloud pictures
def cut(text):
wordlist_jieba=jieba.cut(text)
space_wordlist=" ".join(wordlist_jieba)
return space_wordlistwith open("Full stop comment.txt" ,encoding="utf-8")as file:
text=file.read()
text=cut(text)
mask_pic=numpy.array(Image.open("heart.png"))
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",
collocations=False,
max_words= 100,
min_font_size=10,
max_font_size=500,
mask=mask_pic).generate(text)
image=wordcloud.to_image()
# image.show()
wordcloud.to_file('Cloud word map.png') #Save the word cloud11. Achievement display
image

image
[IV. summary]
1. Project three has more functions than project two: one is to crawl more comments by finding the relationship between the comment pages of each page in parms parameters; the other is to learn to generate a cloud map of words; (pay attention to the path of reading files)
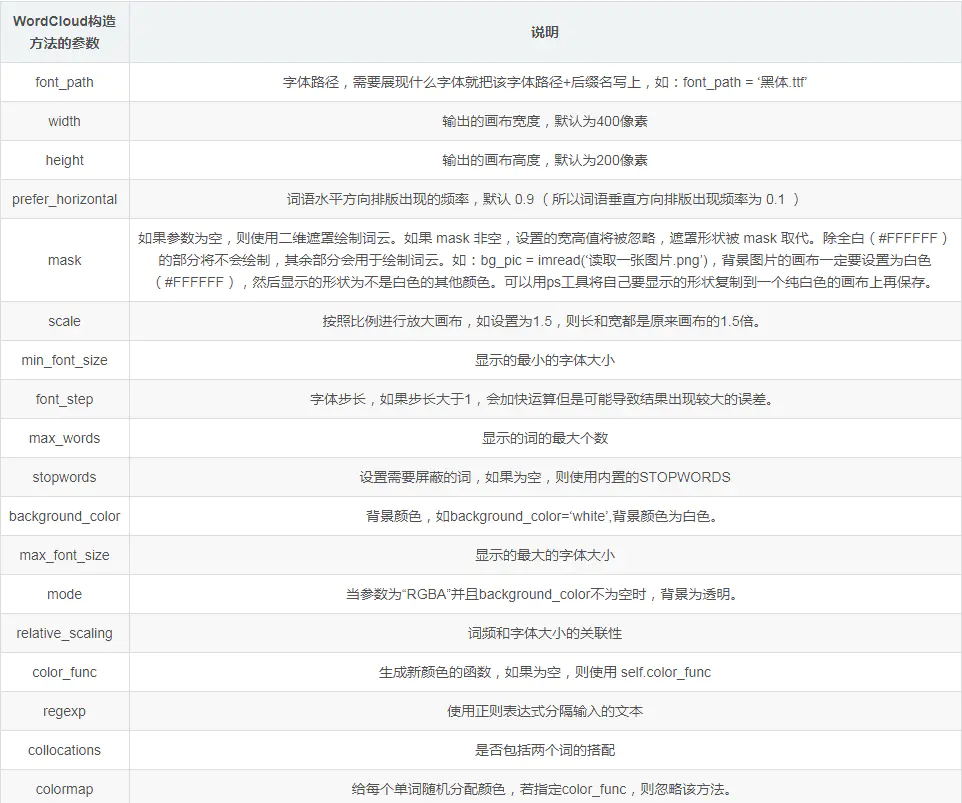
2. More parameters of WordCloud are shown in the figure below, and more playing methods can be developed;
image
3. Not only. txt can be used as the data source of cloud chart, but also csv and Excel can:
import xlrd
#Introduction of excel reading module
datafile_path = 'Your Excel file.xlsx'data = xlrd.open_workbook(datafile_path)#File name and path table = data.sheet_by_name('sheet')##Get by name Sheet1 form nrows = table.nrows#Get the number of valid rows in the Sheet1 list = [] for i in range(nrows):
value = str(table.row_values(i)[1])
# print(value)
list.append(value)# print(pingjia_list)text = str(list).replace("'", '').replace(',', '').rstrip(']').lstrip('[')# print(text)4. This is the end of the QQ music project. If you need more information, lyrics and comments, you can use the Scrapy framework. However, as a hand training project, it is not how much data to climb, but how to climb the specified data.
5. The fourth one will encapsulate the first three items together and crawl different data through menu control. Please wait.
6, if you need the source code, please reply to the word "QQ music" in the background of the official account to get four words.
IT sharing home
Please reply to [join] in wechat background
