Most of the Linux kernel is C language. It is recommended to first look at the Linux kernel development, Robert Love, that is, LKD.
Linux is a dynamic system, which can adapt to the changing computing needs. The performance of Linux computing requirements is centered on the general abstraction of processes. Processes can be short-term (a command executed from the command line) or long-term (a network service). Therefore, the general management of processes and their scheduling is very important.
In user space, a process is represented by a process identifier (PID). From the user's point of view, a PID is a numeric value that uniquely identifies a process. A PID does not change throughout the life of a process, but PIDs can be reused after the process is destroyed, so caching them is not always ideal. There are several ways to create a process in user space. You can execute a program (which will lead to the creation of a new process), or you can call a fork or Exec System call within the program. The fork call will result in the creation of a child process, while the exec call will replace the current process context with a new program. These methods are discussed here so that you can understand how they work.
Here we will introduce processes in the following order. First, we will show the kernel representation of processes and how they are managed in the kernel, then look at various ways of process creation and scheduling (on one or more processors), and finally introduce process destruction. The kernel version is 2.6.32.45.
1, Process descriptor
In the linux kernel, the process consists of a fairly large one called task_struct structure representation. This structure contains all the data necessary to represent this process. In addition, it also contains a large amount of other data for accounting and maintaining the relationship with other processes (such as parent and child). task_struct is located in. / linux/include/linux/sched.h (note. / linux / points to the kernel source tree).
Here is the task_struct structure:
struct task_struct {
volatilelong state; /* -1 Not runnable, 0 runnable, > 0 stopped */
void *stack; /* stack */
atomic_t usage;
unsignedint flags; /* A set of signs */
unsignedint ptrace;
/* ... */
int prio, static_prio, normal_prio; /* priority */
/* ... */
struct list_head tasks;/* Threads of execution (there can be many) */
struct plist_node pushable_tasks;
struct mm_struct *mm, *active_mm;/* Memory page (process address space) */
/* Progress status */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal to send when the parent process dies */<span style="font-family: Arial, Helvetica, sans-serif;">/* ... */ </span>
pid_t pid; /* Process number */
pid_t tgid;
/* ... */
struct task_struct *real_parent; /* Actual parent process */
struct task_struct *parent; /* SIGCHLD Recipients of, reported by wait4() */
struct list_head children; /* Child process list */
struct list_head sibling; /* Sibling process list */
struct task_struct *group_leader; /* leader of thread group */
/* ... */
char comm[TASK_COMM_LEN]; /* Name of executable program (excluding path) */
/* file system information */
int link_count, total_link_count;
/* ... */
/* Status of a specific CPU architecture */
struct thread_struct thread;
/* Description of the directory where the process is currently located */
struct fs_struct *fs;
/* Open file description */
struct files_struct *files;
/* ... */
};In task_ In the struct structure, you can see several expected items, such as execution status, stack, a set of flags, parent process, execution threads (there can be many) and open files. The state variable is bits that indicate the status of the task. The most common status is: TASK_RUNNING indicates that the process is running or is in the running queue and is about to run; TASK_ Intermittent indicates that the process is sleeping and TASK_UNINTERRUPTIBLE indicates that the process is sleeping but cannot wake up; TASK_STOPPED means that the process is stopped, etc. A complete list of these flags can be found in. / linux/include/linux/sched.h.
flags defines a number of indicators to indicate whether the process is being created (PF_STARTING) or exited (PF_EXITING), or whether the process is currently allocating memory (PF_MEMALLOC). The name of the executable program (excluding the path) occupies the comm (command) field. Each process is given priority (called static_prio), but the actual priority of the process is dynamically determined based on loading and several other factors. The lower the priority value, the higher the actual priority. The tasks field provides the ability to link lists. It contains a prev pointer (to the previous task) and a next pointer (to the next task).
The address space of the process consists of mm and active_ The MM field indicates. Mm represents the memory descriptor of the process, while active_mm is the memory descriptor of the previous process (an optimization to improve context switching time). thread_ The struct thread structure is used to identify the storage state of the process. This element depends on the specific architecture on which Linux runs. For example, for x86 architecture, the thread in. / linux/arch/x86/include/asm/processor.h_ The storage (hardware registry, program counter, etc.) of the process after context switching can be found in the struct structure.
The code is as follows:
struct thread_struct {
/* Cached TLS descriptors: */
struct desc_struct tls_array[GDT_ENTRY_TLS_ENTRIES];
unsigned long sp0;
unsigned long sp;
#ifdef CONFIG_X86_32
unsigned long sysenter_cs;
#else
unsigned long usersp; /* Copy from PDA */
unsigned short es;
unsigned short ds;
unsigned short fsindex;
unsigned short gsindex;
#endif
#ifdef CONFIG_X86_32
unsigned long ip;
#endif
/* ... */
#ifdef CONFIG_X86_32
/* Virtual 86 mode info */
struct vm86_struct __user *vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags;
unsigned long v86mask;
unsigned long saved_sp0;
unsigned int saved_fs;
unsigned int saved_gs;
#endif
/* IO permissions: */
unsigned long *io_bitmap_ptr;
unsigned long iopl;
/* Max allowed port in the bitmap, in bytes: */
unsigned io_bitmap_max;
/* MSR_IA32_DEBUGCTLMSR value to switch in if TIF_DEBUGCTLMSR is set. */
unsigned long debugctlmsr;
/* Debug Store context; see asm/ds.h */
struct ds_context *ds_ctx;
};2, Process management
In many cases, processes are dynamically created and dynamically assigned by a task_struct representation. One exception is the init process itself, which always exists and consists of a statically assigned task_struct, see. / linux/arch/x86/kernel/init_task.c.
The code is as follows:
static struct signal_struct init_signals = INIT_SIGNALS(init_signals);
static struct sighand_struct init_sighand = INIT_SIGHAND(init_sighand);
/*
* Initialize thread structure
*/
union thread_union init_thread_union __init_task_data =
{ INIT_THREAD_INFO(init_task) };
/*
* Initializes the structure of the init process. The structure of all other processes will be allocated by slabs in fork.c
*/
struct task_struct init_task = INIT_TASK(init_task);
EXPORT_SYMBOL(init_task);
/*
* per-CPU TSS segments.
*/
DEFINE_PER_CPU_SHARED_ALIGNED(struct tss_struct, init_tss) = INIT_TSS;Note that although processes are dynamically allocated, the maximum number of processes still needs to be considered. The maximum number of processes in the kernel is determined by a called max_threads, which can be found in. / linux/kernel/fork.c. You can change this value from user space through the proc file system of / proc / sys / kernel / threads max.
There are two ways to allocate all processes in Linux. The first method is to hash the pid value through a hash table; The second way is through the double chain circular table. Circular tables are ideal for iterating over task lists. Because the list is circular, there is no head or tail; But because of init_task always exists, so you can use it as an anchor to continue iterating forward. Let's look at an example of traversing the current task set. The task list cannot be accessed from user space, but the problem is easy to solve by inserting code into the kernel in the form of modules. Here is a simple program that iterates through the task list and provides a small amount of information about each task (name, pid, and parent name). Note that here, this module uses printk to issue results. To see the specific results, you can view the / var/log/messages file through the cat utility (or real-time tail -f/var/log/messages). next_ The task function is a macro in sched.h, which simplifies the iteration of the task list (returns the task_struct reference of the next task).
As follows:
#define next_task(p) \ list_entry_rcu((p)->tasks.next, struct task_struct, tasks)
Simple kernel module for querying task list information:
<pre name="code" class="cpp">#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sched.h>
int init_module(void)
{
/* Set up the anchor point */
struct task_struct *task=&init_task;
/* Walk through the task list, until we hit the init_task again */
do {
printk(KERN_INFO "=== %s [%d] parent %s\n",
task->comm,task->pid,task->parent->comm);
} while((task=next_task(task))!=&init_task);
printk(KERN_INFO "Current task is %s [%d]\n", current->comm,current->pid);
return 0;
}
void cleanup_module(void)
{
return;
}The Makefile file for compiling this module is as follows:
obj-m += procsview.o KDIR := /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) default: $(MAKE) -C $(KDIR) SUBDIRS=$(PWD) modules
After compilation, you can insert the module object with insmod procsview.ko or delete it with rmmod procsview. After insertion, / var/log/messages displays the output, as shown below. As you can see, there is an idle task (called swap) and an init task (pid 1).
Dec 28 23:18:16 ubuntu kernel: [12128.910863]=== swapper [0] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910934]=== init [1] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910945]=== kthreadd [2] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910953]=== migration/0 [3] parent kthreadd ...... Dec 28 23:24:12 ubuntu kernel: [12485.295015]Current task is insmod [6051]
Linux maintains a macro called current that identifies the currently running process (type task_struct). The line print at the end of the module is used to output the running command and process number of the current process. Note that the current task is insmod because of init_ The module function runs in the context of insmod command execution. The current symbol actually refers to a function (get_current), which can be found in an arch related header. For example. / linux/arch/x86/include/asm/current.h, as follows:
#include <linux/compiler.h>
#include <asm/percpu.h>
#ifndef __ASSEMBLY__
struct task_struct;
DECLARE_PER_CPU(struct task_struct *, current_task);
static __always_inline struct task_struct *get_current(void)
{
return percpu_read_stable(current_task);
}
#define current get_current()
#endif /* __ASSEMBLY__ */
#endif /* _ASM_X86_CURRENT_H */[article welfare] Xiaobian recommends his own Linux kernel technology exchange group:[ 1143996416 ]I sorted out some good learning books and video materials that I think are shared in the group files. If necessary, I can add them myself!!! (including video tutorials, e-books, practical projects and codes)
3, Process creation
In user space, a process can be created by executing a program or calling fork (or exec) system call in the program. Fork call will lead to the creation of a child process, while exec call will replace the current process context with a new program. The birth of a new process can also be realized through vfork() and clone() respectively The three user state functions fork,vfork, and clone are provided by the libc library. They will call the system calls fork,vfork, and clone with the same name provided by the Linux kernel. The following takes fork system call as an example.
The traditional way to create a new process is that the child process copies all the resources of the parent process, which undoubtedly makes the process creation inefficient, because the child process needs to copy the entire address space of the parent process. What's worse, if the child process immediately executes exec family functions after it is created, the address space just copied from the parent process will be cleared to load new processes In order to solve this problem, the kernel provides the above three different system calls.
-
The kernel uses write time replication technology to optimize the traditional fork function, that is, after the child process is created, the parent and son share the resources of the parent process in a read-only manner (excluding the page table entries of the parent process) . when a child process needs to modify a page in the process address space, the page is copied for the child process. This technology can avoid unnecessary copying of some data in the parent process.
-
The child process created by vfork function will fully share the address space of the parent process, even the page table entries of the parent process. Any modification of any data by either parent and child process makes the other party aware. In order to prevent both parties from being affected by this, after the child process is created by vfork function, the parent process will be blocked until the child process calls exec() or exit() Because the fork function introduces the copy on write technology, the vfork function will hardly be used without considering copying the page table entries of the parent process.
-
The clone function is more flexible when creating a child process, because it can selectively copy the resources of the parent process by passing different clone flag parameters.
The routines corresponding to most system calls are named sys_ * and provide some initial functions to implement the call (such as error checking or user space behavior). The actual work is often delegated to another function named do_ *.
All system call numbers and names are recorded in. / Linux / include / ASM generic / unistd. H. note that the implementation of fork is related to the architecture. For 32-bit x86 systems, the definition in. / linux/arch/x86/include/asm/unistd_32.h will be used, and the fork system call number is 2.
The macro Association of fork system call in unistd.h is as follows:
#define __NR_fork 1079 #ifdef CONFIG_MMU __SYSCALL(__NR_fork, sys_fork) #else __SYSCALL(__NR_fork, sys_ni_syscall) #endif
The call number Association in unistd_32.h is: #define _nr_fork 2
In many cases, the underlying mechanisms of user space tasks and kernel tasks are the same. The corresponding service routines of system call fork, VFORK and clone in the kernel are sys_fork(), sys_vfork() and sys_clone() . they will eventually rely on a function called do_fork to create new processes. For example, when creating a kernel thread, the kernel will call a function called kernel_thread (for 32-bit systems) See. / linux/arch/x86/kernel/process_32.c. note that process.c contains code applicable to both 32 and 64 bits, process_32.c is specific to 32-bit architecture, and process_64.c is specific to 64 bit architecture). This function will call do after some initialization_ fork. Creating a user space process is similar. In user space, a program will call fork. Through soft interrupts such as int $0x80, it will cause a call to sys_ The system call of the kernel function of fork (see. / linux/arch/x86/kernel/process_32.c), as follows:
int sys_fork(struct pt_regs *regs)
{
return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL);
}In the end, do is called directly_ fork. The function hierarchy created by the process is shown in the following figure:
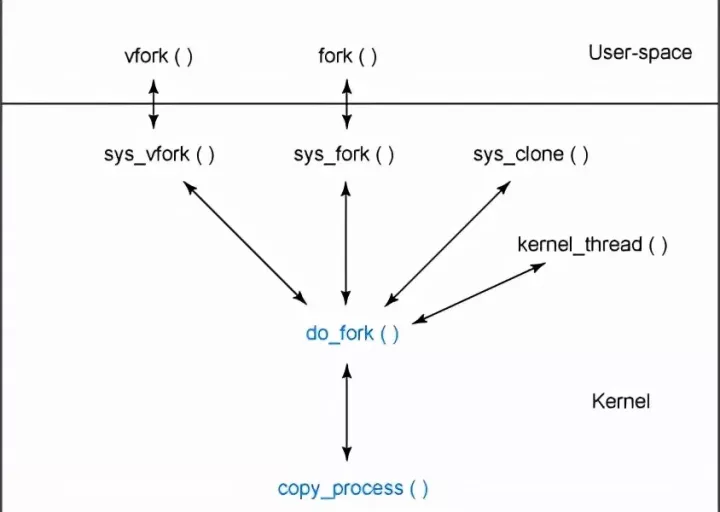
You can see do from the figure_ Fork is the foundation of process creation. You can find do in. / linux/kernel/fork.c_ Fork function (and the cooperation function copy_process).
When a user state process calls a system call, the CPU switches to the kernel state and starts executing a kernel function. In the X86 system, you can enter the system call in two different ways: execute int $0 × 80 assembly command and execute sysenter assembly command. The latter is an instruction introduced by Intel in Pentium II. The kernel supports this command from version 2.6. This will focus on int $0 × 80 mode to enter the process of system call.
Pass int $0 × 80 mode calling system call is actually an interrupt generated by the user process, and the vector number is 0 × 80 soft interrupt. When a user state fork() call occurs, the user state process will save the call number and parameters, and then issue int $0 × 80 command, falling into 0x80 interrupt. The CPU will switch from user mode to kernel mode and start executing system_call(). This function is implemented by assembly command. It is 0 × Interrupt handler corresponding to soft interrupt No. 80. For all system calls, they must first enter the system_call(), the so-called system call handler. Then jump to the specific system call service routine through the system call number. The system call handler of 32-bit x86 system is in. / Linux / arch / x86 / kernel / entry_ In 32. S, the code is as follows:
.macro SAVE_ALL cld PUSH_GS pushl %fs CFI_ADJUST_CFA_OFFSET 4 /*CFI_REL_OFFSET fs, 0;*/ pushl %es CFI_ADJUST_CFA_OFFSET 4 /*CFI_REL_OFFSET es, 0;*/ pushl %ds CFI_ADJUST_CFA_OFFSET 4 /*CFI_REL_OFFSET ds, 0;*/ pushl %eax CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET eax, 0 pushl %ebp CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET ebp, 0 pushl %edi CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET edi, 0 pushl %esi CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET esi, 0 pushl %edx CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET edx, 0 pushl %ecx CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET ecx, 0 pushl %ebx CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET ebx, 0 movl $(__USER_DS), %edx movl %edx, %ds movl %edx, %es movl $(__KERNEL_PERCPU), %edx movl %edx, %fs SET_KERNEL_GS %edx .endm /* ... */ ENTRY(system_call) RING0_INT_FRAME # In any case, you cannot enter user space pushl %eax # Push the saved system call number onto the stack CFI_ADJUST_CFA_OFFSET 4 SAVE_ALL GET_THREAD_INFO(%ebp) # Detect whether the process is tracked testl $_TIF_WORK_SYSCALL_ENTRY,TI_flags(%ebp) jnz syscall_trace_entry cmpl $(nr_syscalls), %eax jae syscall_badsys syscall_call: call *sys_call_table(,%eax,4) # Jump into the corresponding service routine movl %eax,PT_EAX(%esp) # Save the return value of the process syscall_exit: LOCKDEP_SYS_EXIT DISABLE_INTERRUPTS(CLBR_ANY) # Don't forget to turn off the interrupt before it returns TRACE_IRQS_OFF movl TI_flags(%ebp), %ecx testl $_TIF_ALLWORK_MASK, %ecx # current->work jne syscall_exit_work restore_all: TRACE_IRQS_IRET restore_all_notrace: movl PT_EFLAGS(%esp), %eax # mix EFLAGS, SS and CS # Warning: PT_OLDSS(%esp) contains the wrong/random values if we # are returning to the kernel. # See comments in process.c:copy_thread() for details. movb PT_OLDSS(%esp), %ah movb PT_CS(%esp), %al andl $(X86_EFLAGS_VM | (SEGMENT_TI_MASK << 8) | SEGMENT_RPL_MASK), %eax cmpl $((SEGMENT_LDT << 8) | USER_RPL), %eax CFI_REMEMBER_STATE je ldt_ss # returning to user-space with LDT SS restore_nocheck: RESTORE_REGS 4 # skip orig_eax/error_code CFI_ADJUST_CFA_OFFSET -4 irq_return: INTERRUPT_RETURN .section .fixup,"ax"
analysis:
(1) In system_ Before the call function is executed, the CPU control unit has automatically saved the values of eflags, cs, eip, ss and esp registers to the kernel stack corresponding to the process. Then, in the system_call first pushes the system call number stored in the eax register into the stack. Then execute SAVE_ALL macro. This macro saves all CPU registers that may be used by the next system call in the stack.
(2) By GET_THREAD_INFO macro gets the thread of the current process_ Address of inof structure; Then check whether the current process is tracked by other processes (for example, when debugging a program, the debugged program is in the tracked state), that is, thread_ flag field in info structure_ TIF_ALLWORK_MASK is set to 1. If tracked, turn to syscall_ trace_ At the processing command of the entry tag.
(3) Check the validity of the system call number passed by the user status process. If not, jump to syscall_badsys tag.
(4) If the system call is legal, find. / Linux / arch / x86 / kernel / syscall according to the system call number_ table_ System call table sys in 32. S_ call_ Table, find the corresponding function entry point and jump into sys_fork this service routine. Due to sys_ call_ The table entry of table occupies 4 bytes, so the specific method to obtain the service routine pointer is to multiply the system call number saved by eax by 4 and then compare it with sys_ call_ Add the base addresses of the table.
syscall_ table_ The code in 32. S is as follows:
ENTRY(sys_call_table) .long sys_restart_syscall /* 0 - old "setup()" system call, used for restarting */ .long sys_exit .long ptregs_fork .long sys_read .long sys_write .long sys_open /* 5 */ .long sys_close /* ... */
sys_call_table is a system call demultiplexing table. The index provided in eax is used to determine which system call in the table to call.
(5) When the system call service routine ends, the return value of the current process is obtained from the eax register, and the return value is stored in the stack unit where the user state eax register value was saved. In this way, the user state process can find the return code of the system call in the eax register.
The call chain passed is fork() --- > int $0 × 80 soft interrupt -- > entry (system_call) -- > entry (sys_call_table) -- > sys_ fork()--->do_fork(). In fact, the three system calls fork, vfork, and clone eventually call do_fork(). However, the parameters passed during the call are different, and the different parameters just lead to the different degree of resource sharing between the child process and the parent process. Therefore, do is analyzed_ Fork () has become our top priority. Before entering do_ Before analyzing the fork function, it is necessary to understand its parameters.
clone_flags: the four bytes of this flag bit are divided into two parts. The lowest byte is the signal code sent to the parent process at the end of the child process, usually SIGCHLD; The remaining three bytes are the combination of various clone flags (see the following table for the meaning of the flags involved in this paper), that is, the or operation between several flags. Through the clone flag, you can selectively copy the resources of the parent process.
The clone marks involved in this article are shown in the following table:
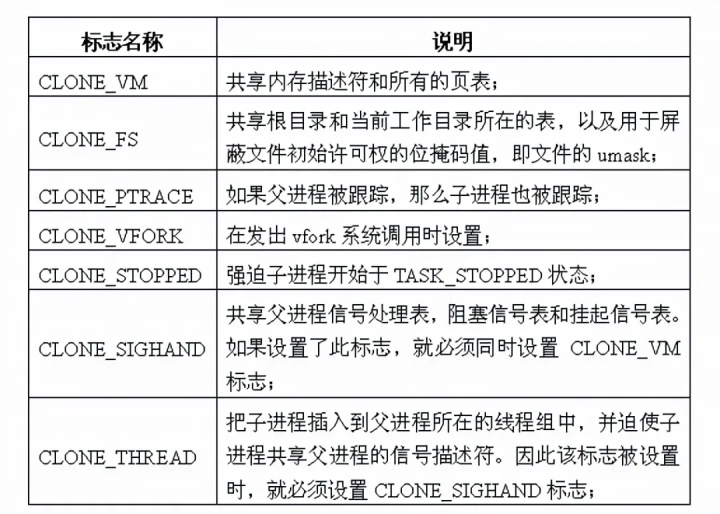
-
stack_start: the address of the child process user state stack.
-
Regs: point to Pt_ Pointer to the regs structure. When a system call occurs in the system, that is, when the user process switches from user state to kernel state, the structure saves the value in the general register and is stored in the stack of kernel state.
-
stack_size: not used, usually assigned to 0.
-
parent_tidptr: the pid address of the parent process in user status. This parameter is in clone_ PARENT_ The settid flag is meaningful when set.
-
child_tidptr: the pid address of the child process in user status. This parameter is in clone_ CHILD_ The settid flag is meaningful when set.
-
do_ The fork function is in. / linux/kernel/fork.c. its main work is to copy the original process into another new process. It completes most of the work in the creation of the whole process.
The code is as follows:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Do some pre parameter and permission checks
*/
if (clone_flags & CLONE_NEWUSER) {
if (clone_flags & CLONE_THREAD)
return -EINVAL;
/* It is hoped that the check here can be removed when the user name is supported
*/
if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) ||
!capable(CAP_SETGID))
return -EPERM;
}
/*
* It is hoped that after 2.6.26, these signs can realize circulation
*/
if (unlikely(clone_flags & CLONE_STOPPED)) {
static int __read_mostly count = 100;
if (count > 0 && printk_ratelimit()) {
char comm[TASK_COMM_LEN];
count--;
printk(KERN_INFO "fork(): process `%s' used deprecated "
"clone flags 0x%lx\n",
get_task_comm(comm, current),
clone_flags & CLONE_STOPPED);
}
}
/*
* When from the kernel_thread calls this do_ When forking, no trace is used
*/
if (likely(user_mode(regs))) /* If you enter this call from the user state, trace is used */
trace = tracehook_prepare_clone(clone_flags);
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
/*
* Do the following work before waking up a new thread, because the pointer of this thread will become invalid after the new thread wakes up (if it exits quickly)
*/
if (!IS_ERR(p)) {
struct completion vfork;
trace_sched_process_fork(current, p);
nr = task_pid_vnr(p);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
}
audit_finish_fork(p);
tracehook_report_clone(regs, clone_flags, nr, p);
/*
* We set pf at creation time_ Starting to prevent the tracking process from using this flag to distinguish a completely alive process
* And a trackhook that hasn't been obtained yet_ report_ Clone() process. Now let's clear it and set up the child process to run
*/
p->flags &= ~PF_STARTING;
if (unlikely(clone_flags & CLONE_STOPPED)) {
/*
* We will launch an instant SIGSTOP immediately
*/
sigaddset(&p->pending.signal, SIGSTOP);
set_tsk_thread_flag(p, TIF_SIGPENDING);
__set_task_state(p, TASK_STOPPED);
} else {
wake_up_new_task(p, clone_flags);
}
tracehook_report_clone_complete(trace, regs,
clone_flags, nr, p);
if (clone_flags & CLONE_VFORK) {
freezer_do_not_count();
wait_for_completion(&vfork);
freezer_count();
tracehook_report_vfork_done(p, nr);
}
} else {
nr = PTR_ERR(p);
}
return nr;
}(1) At the beginning, the function defines a task_ The pointer p of struct type is used to receive the process descriptor to be allocated for the new process (child process). trace represents the tracking status and nr represents the pid of the new process. Then do some pre parameter and permission checks.
(2) Next, check clone_flags whether clone is set_ Stopped flag. If it is set, it will be processed accordingly, and a message will be printed to indicate that the process is out of date. Usually, this rarely happens, so the unlikely modifier is used in judgment. The execution result of the judgment statement using this modifier is the same as that of the ordinary judgment statement, but it is different in execution efficiency. As the meaning of the word indicates, the current process is rarely stopped. Therefore, the compiler tries not to compile the statements in the if together with the code before the current statement, so as to increase the cache hit rate. In contrast, the like modifier indicates that the modified code is likely to occur. tracehook_prepare_clone is used to set whether child processes are tracked. The most common example of so-called tracing is that a process in the debugging state is tracked by the debugger process. The ptrace field of the process is not 0, indicating that the debugger program is tracking it. If the call comes in from the user state (not from the kernel_thread), and the current process (parent process) is tracked by another process, the child process should also be set to be tracked, and the tracking flag CLONE_PTRACE adds flag variable clone_flags. If the parent process is not tracked, the child process will not be tracked. After setting, return to trace.
(3) The next statement is to do the core work in the whole creation process: copy_process() creates the descriptor of the child process, allocates the pid, and creates other data structures required for the execution of the child process. Finally, the created process descriptor p will be returned. The meaning of the parameters in this function is the same as do_ The fork function is the same. Note that the original job of allocating pid to child processes in the kernel is to do_fork, and now the new kernel has been moved to copy_ In process.
(4) If copy_ If the process function is executed successfully, the if(!IS_ERR(p)) section will continue to be executed. First, A completion quantity vfork is defined, and task is used_ pid_ VNR (p) gets the PID of the new process from p. If clone_flags contains CLONE_VFORK flag, vfork in the process descriptor_ The done field points to the completed quantity, and then initializes the vfork completed quantity. The function of completion quantity is that task B will not start to execute until task A sends A signal informing Task B that A specific event has occurred. Otherwise, Task B will wait all the time. We know that if you use vfork system call to create A child process, the child process must execute first. The reason is the role of vfork completion here. When the child process calls the exec function or exits, it sends A signal to the parent process. At this time, the parent process will be awakened, otherwise it will wait all the time. The code here only initializes the completion quantity, and the specific blocking statement is reflected in the following code.
(5) If the child process is tracked or clone is set_ With the stopped flag, the suspend signal is added to the child process through the sigaddset function, and the state of the child process is set to TASK_STOPPED. Signal corresponds to an unsigned long variable, and each bit of the variable corresponds to a signal. The specific operation is to set the position 1 corresponding to the SIGSTOP signal. If the child process does not have clone set_ Stopped flag, then pass wake_up_new_task puts the process on the run queue so that the scheduler can schedule it. wake_up_new_task() in. / linux/kernel/sched.c is used to wake up the newly created process for the first time. It will do some initial necessary scheduler statistics for the new process, and then put the process into the run queue. Once the time slice of the running process runs out (controlled by clock tick interrupt), schedule() will be called to schedule the process.
The code is as follows:
void wake_up_new_task(struct task_struct *p, unsigned long clone_flags)
{
unsigned long flags;
struct rq *rq;
int cpu = get_cpu();
#ifdef CONFIG_SMP
rq = task_rq_lock(p, &flags);
p->state = TASK_WAKING;
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected cpu might disappear through hotplug
*
* We set TASK_WAKING so that select_task_rq() can drop rq->lock
* without people poking at ->cpus_allowed.
*/
cpu = select_task_rq(rq, p, SD_BALANCE_FORK, 0);
set_task_cpu(p, cpu);
p->state = TASK_RUNNING;
task_rq_unlock(rq, &flags);
#endif
rq = task_rq_lock(p, &flags);
update_rq_clock(rq);
activate_task(rq, p, 0);
trace_sched_wakeup_new(rq, p, 1);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken)
p->sched_class->task_woken(rq, p);
#endif
task_rq_unlock(rq, &flags);
put_cpu();
}Use get here first_ CPU () gets the CPU. If it is a symmetric multiprocessing system (SMP), set me as task first_ In the waiting state, since there are multiple CPUs (there is a running queue on each CPU), load balancing needs to be carried out. Select the best CPU and set me to use this CPU, and then set me to TASK_RUNNING status. This operation is mutually exclusive, so it needs to be locked. Pay attention to TASK_RUNNING does not mean that the process must be running. No matter whether the process is occupying CPU or not, it is in this state as long as the running conditions are met. Linux organizes all PCB s in this state into a runnable queue run_queue, from which the scheduler selects the process to run. In fact, Linux combines ready state and running state into one state. Then use. / linux/kernel/sched.c:activate_task() inserts the current process into the runqueue of the corresponding CPU, and the final function to complete the queue is active_ task()--->enqueue_ Task (), where the core code behavior is: P - > sched_ class->enqueue_ task(rq, p,wakeup, head); sched_ Class in. / linux/include/linux/sched.h, it is an object-oriented abstraction of a series of operations of the scheduler. This class includes interfaces such as process queue in, queue out, process operation and process switching, which are used to complete the scheduling and operation of processes.
(6)tracehook_ report_ clone_ The complete function is used to report the trace when the process replication is about to complete. If the parent process is tracked, the pid of the child process is assigned to pstrace of the process descriptor of the parent process_ Message field and send SIGCHLD signal to the parent process of the parent process.
(7) If clone_ If the VFORK flag is set, the parent process will be blocked through the wait operation until the child process calls the exec function or exits.
(8) If copy_ If an error occurs during the execution of process (), the allocated pid will be released first, and then according to the PTR_ The return value of err() is to the error code and saved in nr.
4, copy_process: process descriptor processing
copy_ The process function is also in. / linux/kernel/fork.c. It creates a new process with a copy of the current process and assigns a pid, but does not actually start the new process. It copies the value in the register, all parts related to the process environment, and each clone flag. The actual start of the new process is done by the caller.
For each process, the kernel allocates a separate memory area, which stores the kernel stack and a small process descriptor thread corresponding to the process_ Info structure. In. / linux/arch/x86/include/asm/thread_info.h, as follows:
struct thread_info {
struct task_struct *task; /* Main process descriptor */
struct exec_domain *exec_domain; /* Execution domain */
__u32 flags; /* Low level flag */
__u32 status; /* Thread synchronization flag */
__u32 cpu; /* Current CPU */
int preempt_count; /* 0 => Preemptive, < 0 = > bug */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* ESP of previous stack to prevent embedded (IRQ) stack */
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};
/* ... */
/* How to get the current stack pointer from C */
register unsigned long current_stack_pointer asm("esp") __used;
/* How to get the current thread information structure from C */
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}The reason why the thread information structure is called a small process descriptor is that it does not directly contain process related fields, but points to a specific process descriptor through the task field. Usually, the size of this memory area is 8KB, that is, the size of two pages (sometimes one page is used for storage, that is, 4KB).
Kernel stack and thread of a process_ The logical relationship between info structures is shown in the following figure:
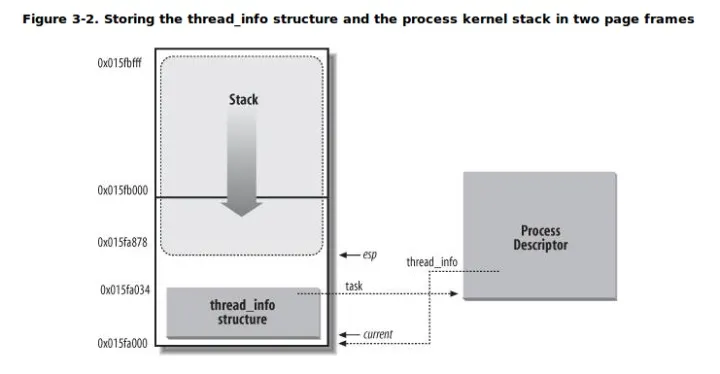
As can be seen from the above figure, the kernel stack grows downward (from high address to low address) from the top of the memory area, and the thread_ The info structure grows upward (from low address to high address) from the beginning of the region. The top address of the kernel stack is stored in the esp register. Therefore, when the process switches from user mode to kernel mode, the esp register points to the end of this area. From a code perspective, the kernel stack and thread_info structure is defined in a consortium in. / linux/include/linux/sched.h:
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};Among them, thread_ When the value of size is 8192, the size of stack array is 2048; THREAD_ When the value of size is 4096, the size of the stack array is 1024.
Now we should think about why the kernel stack and thread_ Info (in fact, it's equivalent to task_struct, but using thread_info structure saves more space) are closely put together? The main reason is that the kernel can easily obtain the thread of the currently running process through the value of the esp register_ Info structure, and then obtain the address of the current process descriptor. Current above_ thread_ In the info function, define current_ stack_ The pointer's Inline Assembly statement will obtain the top address of the kernel stack from the esp register, and the ~ (THREAD_SIZE - 1) do and operation will mask the lower 13 bits (or 12 bits, when the THREAD_SIZE is 4096). At this time, the address referred to is the starting address of the memory area, which is just thread_ The address of the info structure. However, thread_ The address of info structure will not be directly useful to us. We can usually easily get the task of the current process through the current macro_ Struct structure, which has been listed above_ Code for the current() function. The current macro returns thread_ Info structure task field, and task just points to and thread_ The process descriptor associated with the info structure. After getting current, we can get any field in the descriptor of the currently running process, such as current - > PID.
Let's look at copy_ Implementation of process:
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
p->signal->rlim[RLIMIT_NPROC].rlim_cur) {
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) &&
p->real_cred->user != INIT_USER)
goto bad_fork_free;
}
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p);
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = cputime_zero;
p->stime = cputime_zero;
p->gtime = cputime_zero;
p->utimescaled = cputime_zero;
p->stimescaled = cputime_zero;
p->prev_utime = cputime_zero;
p->prev_stime = cputime_zero;
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
p->lock_depth = -1; /* -1 = no lock */
do_posix_clock_monotonic_gettime(&p->start_time);
p->real_start_time = p->start_time;
monotonic_to_bootbased(&p->real_start_time);
p->io_context = NULL;
p->audit_context = NULL;
cgroup_fork(p);
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_cgroup;
}
mpol_fix_fork_child_flag(p);
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
#ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW
p->hardirqs_enabled = 1;
#else
p->hardirqs_enabled = 0;
#endif
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet */
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
p->bts = NULL;
/* Perform scheduler related setup. Assign this task to a CPU. */
sched_fork(p, clone_flags);
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
if ((retval = audit_alloc(p)))
goto bad_fork_cleanup_policy;
/* copy all the process information */
if ((retval = copy_semundo(clone_flags, p)))
goto bad_fork_cleanup_audit;
if ((retval = copy_files(clone_flags, p)))
goto bad_fork_cleanup_semundo;
if ((retval = copy_fs(clone_flags, p)))
goto bad_fork_cleanup_files;
if ((retval = copy_sighand(clone_flags, p)))
goto bad_fork_cleanup_fs;
if ((retval = copy_signal(clone_flags, p)))
goto bad_fork_cleanup_sighand;
if ((retval = copy_mm(clone_flags, p)))
goto bad_fork_cleanup_signal;
if ((retval = copy_namespaces(clone_flags, p)))
goto bad_fork_cleanup_mm;
if ((retval = copy_io(clone_flags, p)))
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
if (clone_flags & CLONE_NEWPID) {
retval = pid_ns_prepare_proc(p->nsproxy->pid_ns);
if (retval < 0)
goto bad_fork_free_pid;
}
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
if (current->nsproxy != p->nsproxy) {
retval = ns_cgroup_clone(p, pid);
if (retval)
goto bad_fork_free_pid;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr: NULL;
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing should be turned off in the child regardless
* of CLONE_PTRACE.
*/
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
/*
* Ok, make it visible to the rest of the system.
* We dont wake it up yet.
*/
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
/* Now that the task is set up, run cgroup callbacks if
* necessary. We need to run them before the task is visible
* on the tasklist. */
cgroup_fork_callbacks(p);
cgroup_callbacks_done = 1;
/* Need tasklist lock for parent etc handling! */
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
if (clone_flags & CLONE_THREAD) {
atomic_inc(¤t->signal->count);
atomic_inc(¤t->signal->live);
p->group_leader = current->group_leader;
list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
}
if (likely(p->pid)) {
list_add_tail(&p->sibling, &p->real_parent->children);
tracehook_finish_clone(p, clone_flags, trace);
if (thread_group_leader(p)) {
if (clone_flags & CLONE_NEWPID)
p->nsproxy->pid_ns->child_reaper = p;
p->signal->leader_pid = pid;
tty_kref_put(p->signal->tty);
p->signal->tty = tty_kref_get(current->signal->tty);
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__get_cpu_var(process_counts)++;
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
perf_event_fork(p);
return p;
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
put_io_context(p->io_context);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
__cleanup_signal(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_cgroup:
#endif
cgroup_exit(p, cgroup_callbacks_done);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
}-
(1) The defined return value is also retval and the new process descriptor task_struct structure p.
-
(2) Sign validity check. Yes, clone_ Check the legitimacy of the flag combination passed by flags. When the following three conditions occur, the error code is returned:
1)CLONE_NEWNS and CLONE_FS is set at the same time. The former flag indicates that the child process needs its own namespace, while the latter flag indicates that the child process shares the root directory and current working directory of the parent process, which are incompatible. In the traditional Unix system, the whole system has only one installed file system tree. Each process starts from the root file system of the system and can access any file through a legal path. In the kernel in version 2.6, each process can have its own installed file system tree, also known as namespace. Usually, most processes share the installed file system tree used by the init process, only in the clone_ Clone is set in flags_ A new namespace will be opened for this new process only when the newns flag is.
2)CLONE_ Thread is set, but clone_ Sighand is not set. If the child process and the parent process belong to the same thread group (CLONE_THREAD is set), the child process must share the signal of the parent process (CLONE_SIGHAND is set).
3)CLONE_SIGHAND is set, but clone_ VM is not set. If the child process shares the signal of the parent process, the memory descriptor and all page tables of the parent process must be shared at the same time (CLONE_VM is set).
-
(3) Security check. By calling security_task_create() and the following security_task_alloc() performs all additional security checks. Ask the Linux Security Module (LSM) to see if the current task can create a new task. LSM is the core of SELinux.
-
(4) Copy process descriptor. Through dup_task_struct() allocates a kernel stack and thread for the child process_ Info structure and task_struct structure. Note that the current process descriptor pointer is passed as a parameter to this function.
The function code is as follows:
int __attribute__((weak)) arch_dup_task_struct(struct task_struct *dst,
struct task_struct *src)
{
*dst = *src;
return 0;
}
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int err;
prepare_to_copy(orig);
tsk = alloc_task_struct();
if (!tsk)
return NULL;
ti = alloc_thread_info(tsk);
if (!ti) {
free_task_struct(tsk);
return NULL;
}
err = arch_dup_task_struct(tsk, orig);
if (err)
goto out;
tsk->stack = ti;
err = prop_local_init_single(&tsk->dirties);
if (err)
goto out;
setup_thread_stack(tsk, orig);
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* For overflow detection */
#ifdef CONFIG_CC_STACKPROTECTOR
tsk->stack_canary = get_random_int();
#endif
/* One for us, one for whoever does the "release_task()" (usually parent) */
atomic_set(&tsk->usage,2);
atomic_set(&tsk->fs_excl, 0);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
account_kernel_stack(ti, 1);
return tsk;
out:
free_thread_info(ti);
free_task_struct(tsk);
return NULL;
}First, the function defines the point to task_struct and thread_ Pointer to the info structure. Next, prepare_to_copy does some preparatory work for the formal allocation of process descriptors. It mainly saves the values of some necessary registers to the thread of the parent process_ Info structure. These values are later copied to the thread of the child process_ Info structure. Execute alloc_task_struct macro, which is responsible for allocating space for the process descriptor of the child process, assigning the first address of the memory to tsk, and then checking whether the memory is allocated correctly. Execute alloc_thread_info macro, which obtains a free memory area for the child process to store the kernel stack and thread of the child process_ Info structure, assign the first address of the memory area to the ti variable, and then check whether the allocation is correct.
As explained above, orig is the current macro passed in and a pointer to the current process descriptor. arch_dup_task_struct directly copies the contents of the current process descriptor pointed to by orig to the current mileage descriptor tsk. Then, use atomic_set sets the usage counter of the child process descriptor to 2, indicating that the process descriptor is being used and active. Finally, a pointer to the memory area of the child process descriptor just created is returned.
Through dup_task_struct can see that when the function operates successfully, the contents of the descriptors of the child process and the parent process are exactly the same. Copy later_ In the process code, we will see that the child process is gradually distinguished from the parent process.
-
(5) Some initialization. Through such as ftrace_graph_init_task,rt_mutex_init_task completes the initialization of some data structures. Call copy_creds() copies the certificate (which should be the copy permission and identity information).
-
(6) Check whether the total number of processes in the system exceeds max_ The maximum number of processes specified by threads.
-
(7) Copy flag. By copy_flags, from do_ Clone passed from fork()_ Flags and pid are assigned to the corresponding fields in the child process descriptor respectively.
-
(8) Initializes the child process descriptor. Initialize each field to gradually distinguish the child process from the parent process. This part of the work includes the queue headers such as children and sibling in the initialization sub process, initialization spin lock and signal processing, initialization process statistics, initialization POSIX clock, statistics related to initialization scheduling, and initialization audit information. It's in copy_ The process function takes up a long piece of code, but considering the task_ The complexity of struct structure itself is not surprising.
-
(9) Scheduler settings. Call sched_ The fork function executes the settings related to the scheduler, allocates the CPU for the new process, and makes the process state of the child process TASK_RUNNING. Kernel preemption is prohibited. Moreover, in order not to affect the scheduling of other processes, the child processes share the time slice of the parent process.
-
(10) Copy all information about the process. According to clone_ The specific value of flags is to copy or share some data structures of the parent process for the child process. Like copy_semundo(), copy_files, copy symbol information (copy_sighand and copy_signal), copy process memory (copy_mm), and copy_thread.
-
(11) Copy thread. By copy_ The threads () function updates the values in the kernel stack and registers of the child process. In previous dup_task_struct() only creates a kernel stack for the child process, so far it is really given a meaningful value.
When the parent process makes a clone system call, the kernel will save the value of the register in the CPU at that time in the kernel stack of the parent process. Here is to use the value in the parent process kernel stack to update the value in the child process register. In particular, the kernel forces the value in the subprocess eax register to 0, which is why the subprocess returns 0 when fork() is used. And in do_ The fork function returns the pid of the child process, which we have analyzed in the above content. In addition, the corresponding thread of the child process_ The esp field in the info structure is initialized to the base address of the child process kernel stack.
-
(12) Assign pid. Alloc_ The pid function assigns a pid to the new process. The pid in the Linux system is recycled and managed by bitmap. Simply put, each bit is used to indicate whether the pid corresponding to this bit is used. After allocation, judge whether pid allocation is successful. Success is assigned to p - > pid.
-
(13) Update properties and number of processes. According to clone_ The value of flags continues to update some properties of the child process. Will nr_threads plus one indicates that the new process has been added to the process set. total_forks plus one to record the number of processes created.
-
(14) If an error occurs in one step of the above process, skip to the corresponding error code through goto statement; If the execution is completed successfully, the descriptor p of the child process is returned.
So far, copy_ The approximate execution process analysis of process () is completed.
copy_process() returns do after execution_ fork(),do_ After fork () is executed, although the child process is in a runnable state, it does not run immediately. As for when the subprocess executes, it all depends on the scheduler, that is, schedule().
[article welfare] Xiaobian recommends his own Linux kernel technology exchange group:[ 1143996416 ]I sorted out some good learning books and video materials that I think are shared in the group files. If necessary, I can add them myself!!! (including video tutorials, e-books, practical projects and codes)
5, Process scheduling
The created process is finally inserted into the run queue, and it will be scheduled through the Linux scheduler. The Linux scheduler maintains a set of lists for each priority level, in which the task_struct reference is saved. When the running process runs out of time slices, the clock tick is interrupted and the kernel/sched.c:scheduler_tick() is called The interrupt processing of the process scheduler. After the interrupt returns, it will call schedule(). The tasks in the running queue are called through the schedule function (in. / linux/kernel/sched.c), which determines the best process according to the loading and process execution history. The analysis of this function is not involved here.
6, Process destruction
Process destruction can be driven by several events, terminated by a normal process (startuproutine calls exit when a C program returns from the main function), by a signal, or by an explicit call to the exit function. No matter how the process exits, the end of the process depends on the call to the kernel function do_exit (in. / linux/kernel/exit.c).
The function hierarchy is shown in the following figure:
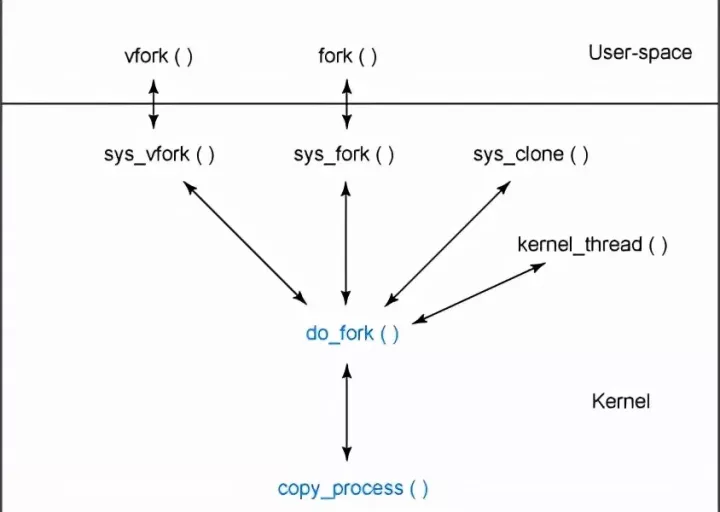
Function hierarchy of process destruction
The exit() call jumps to the sys_exit kernel routine through the 0x80 interrupt. The routine name can be found in. / linux/include/linux/syscalls.h (all platform independent system call names are exported in syscalls.h), which is defined as asmlinkage long sys_exit(int error_code); it will directly call do_exit.
The code is as follows:
NORET_TYPE void do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
profile_task_exit(tsk);
WARN_ON(atomic_read(&tsk->fs_excl));
if (unlikely(in_interrupt()))
panic("Aiee, killing interrupt handler!");
if (unlikely(!tsk->pid))
panic("Attempted to kill the idle task!");
/*
* If do_exit is called because this processes oopsed, it's possible
* that get_fs() was left as KERNEL_DS, so reset it to USER_DS before
* continuing. Amongst other possible reasons, this is to prevent
* mm_release()->clear_child_tid() from writing to a user-controlled
* kernel address.
*/
set_fs(USER_DS);
tracehook_report_exit(&code);
validate_creds_for_do_exit(tsk);
/*
* We're taking recursive faults here in do_exit. Safest is to just
* leave this task alone and wait for reboot.
*/
if (unlikely(tsk->flags & PF_EXITING)) {
printk(KERN_ALERT
"Fixing recursive fault but reboot is needed!\n");
/*
* We can do this unlocked here. The futex code uses
* this flag just to verify whether the pi state
* cleanup has been done or not. In the worst case it
* loops once more. We pretend that the cleanup was
* done as there is no way to return. Either the
* OWNER_DIED bit is set by now or we push the blocked
* task into the wait for ever nirwana as well.
*/
tsk->flags |= PF_EXITPIDONE;
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
exit_irq_thread();
exit_signals(tsk); /* sets PF_EXITING */
/*
* tsk->flags are checked in the futex code to protect against
* an exiting task cleaning up the robust pi futexes.
*/
smp_mb();
spin_unlock_wait(&tsk->pi_lock);
if (unlikely(in_atomic()))
printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n",
current->comm, task_pid_nr(current),
preempt_count());
acct_update_integrals(tsk);
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) {
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm);
}
acct_collect(code, group_dead);
if (group_dead)
tty_audit_exit();
if (unlikely(tsk->audit_context))
audit_free(tsk);
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
exit_mm(tsk);
if (group_dead)
acct_process();
trace_sched_process_exit(tsk);
exit_sem(tsk);
exit_files(tsk);
exit_fs(tsk);
check_stack_usage();
exit_thread();
cgroup_exit(tsk, 1);
if (group_dead && tsk->signal->leader)
disassociate_ctty(1);
module_put(task_thread_info(tsk)->exec_domain->module);
proc_exit_connector(tsk);
/*
* Flush inherited counters to the parent - before the parent
* gets woken up by child-exit notifications.
*/
perf_event_exit_task(tsk);
exit_notify(tsk, group_dead);
#ifdef CONFIG_NUMA
mpol_put(tsk->mempolicy);
tsk->mempolicy = NULL;
#endif
#ifdef CONFIG_FUTEX
if (unlikely(current->pi_state_cache))
kfree(current->pi_state_cache);
#endif
/*
* Make sure we are holding no locks:
*/
debug_check_no_locks_held(tsk);
/*
* We can do this unlocked here. The futex code uses this flag
* just to verify whether the pi state cleanup has been done
* or not. In the worst case it loops once more.
*/
tsk->flags |= PF_EXITPIDONE;
if (tsk->io_context)
exit_io_context();
if (tsk->splice_pipe)
__free_pipe_info(tsk->splice_pipe);
validate_creds_for_do_exit(tsk);
preempt_disable();
exit_rcu();
/* causes final put_task_struct in finish_task_switch(). */
tsk->state = TASK_DEAD;
schedule();
BUG();
/* Avoid "noreturn function does return". */
for (;;)
cpu_relax(); /* For when BUG is null */
}
EXPORT_SYMBOL_GPL(do_exit);
-
(1) Make a series of preparations for process destruction. Use set_fs to set USER_DS. Note that if do_exit is called because of an unpredictable error in the current process, get_fs() may still get the KERNEL_DS state, so we need to reset it to USER_DS state. Another possible reason is that this can prevent mm_release() - > clear_child_tid() Write a kernel address controlled by the user.
-
(2) Clear all signal processing functions. The exit_signals function sets the PF_EXITING flag to indicate that the process is exiting and clears all information processing functions. Other aspects of the kernel use PF_EXITING to prevent attempts to process the process when it is deleted.
-
(3) Clear a series of process resources. For example, exit_mm deletes memory pages, exit_files closes all open file descriptors, which will clean up the I/O cache. If there is data in the cache, they will be written to the corresponding files to prevent the loss of file data. exit_fs clears the inode associated with the current directory, exit_thread clears thread information, and so on.
-
(4) Issue exit notification. Call exit_notify to perform a series of notifications. For example, notify the parent process that I am exiting.
As follows:
static void exit_notify(struct task_struct *tsk, int group_dead)
{
int signal;
void *cookie;
/*
* This does two things:
*
* A. Make init inherit all the child processes
* B. Check to see if any process groups have become orphaned
* as a result of our exiting, and if they have any stopped
* jobs, send them a SIGHUP and then a SIGCONT. (POSIX 3.2.2.2)
*/
forget_original_parent(tsk);
exit_task_namespaces(tsk);
write_lock_irq(&tasklist_lock);
if (group_dead)
kill_orphaned_pgrp(tsk->group_leader, NULL);
/* Let father know we died
*
* Thread signals are configurable, but you aren't going to use
* that to send signals to arbitary processes.
* That stops right now.
*
* If the parent exec id doesn't match the exec id we saved
* when we started then we know the parent has changed security
* domain.
*
* If our self_exec id doesn't match our parent_exec_id then
* we have changed execution domain as these two values started
* the same after a fork.
*/
if (tsk->exit_signal != SIGCHLD && !task_detached(tsk) &&
(tsk->parent_exec_id != tsk->real_parent->self_exec_id ||
tsk->self_exec_id != tsk->parent_exec_id))
tsk->exit_signal = SIGCHLD;
signal = tracehook_notify_death(tsk, &cookie, group_dead);
if (signal >= 0)
signal = do_notify_parent(tsk, signal);
tsk->exit_state = signal == DEATH_REAP ? EXIT_DEAD : EXIT_ZOMBIE;
/* mt-exec, de_thread() is waiting for us */
if (thread_group_leader(tsk) &&
tsk->signal->group_exit_task &&
tsk->signal->notify_count < 0)
wake_up_process(tsk->signal->group_exit_task);
write_unlock_irq(&tasklist_lock);
tracehook_report_death(tsk, signal, cookie, group_dead);
/* If the process is dead, release it - nobody will wait for it */
if (signal == DEATH_REAP)
release_task(tsk);
}
exit_notify sets the parent process ID of all child processes of the current process to 1(init) and lets init take over all these child processes. If the current process is the leader of a process group, its destruction will cause the process group to become "leaderless" "Send the pending signal SIGHUP to each process within the group, then send SIGCONT. This is to follow the POSIX3.2.2.2 standard. Then send the SIGCHLD signal to the parent process, then call do_notify_parent to notify the parent process. If DEATH_REAP is returned, this means that no matter whether there are other processes concerned with the exit information of the process, automatic process exit and PCB destruction. , it directly enters the EXIT_DEAD state. If not, it needs to change to the EXIT_ZOMBIE state.
Note that when the parent process initially creates a child process, if it calls waitpid() to wait for the child process to end (indicating that it cares about the state of the child process), the parent process will process the SIGCHILD signal sent by it when the child process ends. If it does not call wait (indicating that it does not care about the dead or alive state of the child process) , the SIGCHILD signal of the child process will not be processed. See. / linux/kernel/signal.c:do_notify_parent(), and the code is as follows:
int do_notify_parent(struct task_struct *tsk, int sig)
{
struct siginfo info;
unsigned long flags;
struct sighand_struct *psig;
int ret = sig;
BUG_ON(sig == -1);
/* do_notify_parent_cldstop should have been called instead. */
BUG_ON(task_is_stopped_or_traced(tsk));
BUG_ON(!task_ptrace(tsk) &&
(tsk->group_leader != tsk || !thread_group_empty(tsk)));
info.si_signo = sig;
info.si_errno = 0;
/*
* we are under tasklist_lock here so our parent is tied to
* us and cannot exit and release its namespace.
*
* the only it can is to switch its nsproxy with sys_unshare,
* bu uncharing pid namespaces is not allowed, so we'll always
* see relevant namespace
*
* write_lock() currently calls preempt_disable() which is the
* same as rcu_read_lock(), but according to Oleg, this is not
* correct to rely on this
*/
rcu_read_lock();
info.si_pid = task_pid_nr_ns(tsk, tsk->parent->nsproxy->pid_ns);
info.si_uid = __task_cred(tsk)->uid;
rcu_read_unlock();
info.si_utime = cputime_to_clock_t(cputime_add(tsk->utime,
tsk->signal->utime));
info.si_stime = cputime_to_clock_t(cputime_add(tsk->stime,
tsk->signal->stime));
info.si_status = tsk->exit_code & 0x7f;
if (tsk->exit_code & 0x80)
info.si_code = CLD_DUMPED;
else if (tsk->exit_code & 0x7f)
info.si_code = CLD_KILLED;
else {
info.si_code = CLD_EXITED;
info.si_status = tsk->exit_code >> 8;
}
psig = tsk->parent->sighand;
spin_lock_irqsave(&psig->siglock, flags);
if (!task_ptrace(tsk) && sig == SIGCHLD &&
(psig->action[SIGCHLD-1].sa.sa_handler == SIG_IGN ||
(psig->action[SIGCHLD-1].sa.sa_flags & SA_NOCLDWAIT))) {
/*
* We are exiting and our parent doesn't care. POSIX.1
* defines special semantics for setting SIGCHLD to SIG_IGN
* or setting the SA_NOCLDWAIT flag: we should be reaped
* automatically and not left for our parent's wait4 call.
* Rather than having the parent do it as a magic kind of
* signal handler, we just set this to tell do_exit that we
* can be cleaned up without becoming a zombie. Note that
* we still call __wake_up_parent in this case, because a
* blocked sys_wait4 might now return -ECHILD.
*
* Whether we send SIGCHLD or not for SA_NOCLDWAIT
* is implementation-defined: we do (if you don't want
* it, just use SIG_IGN instead).
*/
ret = tsk->exit_signal = -1;
if (psig->action[SIGCHLD-1].sa.sa_handler == SIG_IGN)
sig = -1;
}
if (valid_signal(sig) && sig > 0)
__group_send_sig_info(sig, &info, tsk->parent);
__wake_up_parent(tsk, tsk->parent);
spin_unlock_irqrestore(&psig->siglock, flags);
return ret;
}
We can see that if the parent process displays the sigcld signal processing specified for the child process as SIG_IGN, or marked SA_NOCLDWAIT, ret=-1 is returned, that is, depth_ Reap (this macro is defined as - 1 in. / linux/include/tracehook.h), and it is in exit at this time_ The notify subprocess immediately becomes EXIT_DEAD indicates that I have quit and died, and was finally released later_ Task recycling, there will be no more processes waiting for me. Otherwise, the return value is the same as the incoming signal value, and the child process becomes EXIT_ZOMBIE, indicating that he has quit but is not dead. Whether or not SIGCHLD is processed, do_ notify_ The parent will use it in the end__ wake_up_parent to wake up the waiting parent process.
It can be seen that child processes do not necessarily need to go through an exit before they end_ Zombie process. If the parent process calls waitpid to wait for the child process, the SIGCHILD signal sent by it will be displayed and processed, and the child process will clean itself at the end (it will be cleaned up with release_task in do_exit); If the parent process does not call waitpid to wait for the child process, the SIGCHLD signal will not be processed, and the child process will not be cleaned up immediately, but will become EXIT_ZOMBIE state, becoming a famous zombie process. In another special case, if the parent process happens to be sleep ing when the child process exits, resulting in no urgent handling of sigcld, the child process will also become a zombie. As long as the parent process can call waitpid after waking up, it can also clean up the zombie child process, because the wait system call has code to clean up the zombie child process. Therefore, if the parent process has not called waitpid, the zombie child process can only be taken over by init when the parent process exits. The init process will be responsible for cleaning up these zombie processes (init will definitely call wait).
We can write a simple program to verify that the parent process creates 10 child processes, and the child process sleeps for a period of time and exits. In the first case, the parent process only calls waitpid() to the child processes 1 ~ 9, and the child processes 1 ~ 9 end normally. Before the parent process ends, pids[0] is EXIT_ZOMBIE. In the second case, after the parent process creates 10 child processes, sleep () takes a period of time. During this period of time_ All child processes of exit() become EXIT_ZOMBIE. After the parent process sleep() ends, call waitpid() in turn, and the child process immediately becomes EXIT_DEAD is cleared.
To better understand how to clean up zombie processes, let's briefly analyze wait system calls. The system calls of the wait family, such as waitpid and wait4, will eventually enter. / linux/kernel/exit.c:do_wait() kernel routine, and then the function chain is do_ wait()--->do_ wait_ thread()--->wait_ consider_ Task (), here, if the child process is in exit_ TSK - > Exit set in notify_ State is EXIT_DEAD returns 0, that is, the wait system call returns, indicating that the child process is not a zombie process and will use release itself_ Task to recycle. If its exit_state is EXIT_ZOMBIE, enter wait_task_zombie(). Use xchg here to try to put its exit_state is set to EXIT_DEAD, it can be seen that the wait4 call of the parent process will transfer the child process from EXIT_ZOMBIE is set to EXIT_DEAD. Last wait_task_zombie() calls release at the end_ Task () cleans up the zombie process.
(5) Set the destroy flag and schedule a new process. In do_ At the end of exit, use exit_io_context clear IO context, preempt_disable disables preemption and sets the process status to TASK_DEAD, then call./linux/kernel/sched.c:schedule() to select a new process to be executed. Note that after the process exits and recycles, the process descriptor (PCB) in the process list of the scheduler is not released immediately. You must set task_ The state of struct is task_ After dead, finish in schedule()_ task_ switch()--->put_ task_struct () puts its PCB back into the freelist (available list), then the PCB is released, and then switches to a new process.
7, exit and_ exit differences
In order to understand the difference between the two system calls, let's first discuss the problem of file memory cache. In linux, standard input / output (I/O) functions are processed as files. Corresponding to each open file, there is a corresponding cache in memory. Each time the file is read, more will be read and recorded in the cache, so that it will be read in the cache the next time the file is read; Similarly, when writing a file, it is also written in the cache corresponding to the file, not directly written to the file on the hard disk. Only when certain conditions are met (such as reaching a certain number, encountering newline character \ n or end of file flag EOF) can the data be really written to the file. The advantage of this is to speed up the reading and writing of files. But this also brings some problems. For example, we think that some data has been written to the file, but it still resides in the memory cache without meeting certain conditions. In this way, if we directly use_ The exit() function directly terminates the process, resulting in data loss. If it is changed to exit, there will be no data loss problem, which is the difference between them. To explain this problem, it is necessary to involve their work steps.
-
exit(): according to the previous source code analysis, when executing this function, the process will check the file opening and clean up the I/O cache. If there is data in the cache, it will write them to the corresponding file, so as to prevent the loss of file data, and then terminate the process.
-
_ exit(): when this function is executed, it does not clear the standard I / O cache, but directly clears the memory space. Of course, it destroys the data in the file cache that has not been written to the file. Thus, it is safer to use the exit () function.
In addition, there are differences in their header files. exit() in stdlib.h_ exit() is in unistd.h. Generally, exit(0) means normal exit, exit(1), exit(-1) means abnormal exit, and 0, 1, - 1 are return values. The specific meaning can be customized. Also note that return is a return function call. If the return is a main function, it means to exit the program. Exit is to forcibly exit the program at the call, and run the program once.
The following is the complete Linux process running process:
arch/x86/include/asm/unistd_32.h:fork() Called in user space (e.g C (program) --->int $0×80 Generate 0 x80 Soft interrupt --->arch/x86/kernel/entry_32.S:ENTRY(system_call) Interrupt handler system_call() --->implement SAVE_ALL macro Save all CPU Register value --->arch/x86/kernel/syscall_table_32.S:ENTRY(sys_call_table) System call demultiplexing table --->arch/x86/kernel/process_32.c:sys_fork() --->kernel/fork.c:do_fork() Copy the original process to become another new process --->kernel/fork.c:copy_process() --->struct task_struct *p; Define a new process descriptor( PCB) --->clone_flags Legitimacy check of signs --->security_task_create() Safety inspection(SELinux mechanism) --->kernel/fork.c:dup_task_struct() Copy process descriptor --->struct thread_info *ti; Define thread information structure --->alloc_task_struct() For new PCB Allocate memory --->kernel/fork.c:arch_dup_task_struct() Copy parent process PCB --->atomic_set(&tsk->usage,2) take PCB The usage counter is set to 2 to indicate the active state --->copy_creds() Copy permission and identity information --->Detect whether the total number of processes exceeds max_threads --->initialization PCB Fields in --->sched_fork() Scheduler related settings --->Copy all process information copy_semundo(), copy_files(), --->copy_signal(), copy_mm() --->copy_thread() Copy thread --->alloc_pid() distribution pid --->Update attribute and process count --->kernel/sched.c:wake_up_new_task() Put the process on the run queue and let the scheduler schedule it --->kernel/sched.c:select_task_rq() Choose the best CPU(SMP Multiple in CPU) --->p->state = TASK_RUNNING Set as TASK_RUNNING state --->activate_task() --->enqueue_task() Insert the current process into the corresponding CPU of runqueue upper --->have CLONE_VFORK Sign: wait_for_completion() Let the parent process block and wait for the child process to end --->Returns the assigned pid kernel/sched.c:schedule() Schedule newly created processes Process running exit() Called in user space (e.g C (program) --->0x80 Interrupt jump to include/linux/syscalls.h:sys_exit() --->kernel/exit.c:do_exit() Responsible for the exit of the process --->struct task_struct *tsk = current; Get my PCB --->set_fs(USER_DS) Sets the file system mode used --->exit_signals() Clear signal processing function and set PF_EXITING sign --->The purge process a list of resources exit_mm(), exit_files() --->exit_fs(), exit_thread() --->kernel/exit.c:exit_notify() Exit notification --->forget_original_parent() Pass on all my child processes to init process --->kill_orphaned_pgrp() Send a suspend signal to each process in the process group SIGHUP and SIGCONT --->tsk->exit_signal = SIGCHLD; Send to my parent process SIGCHLD signal --->kernel/exit.c:do_notify_parent() Notify parent process --->If the parent process handles SIGCHLD Signal, return DEATH_REAP --->If the parent process does not process SIGCHLD Signal, which returns the signal value at the time of incoming --->__wake_up_parent() Wake up parent process --->Notification return DEATH_REAP,set up exit_state by EXIT_DEAD I quit and died --->Otherwise, set me to EXIT_ZOMBIE I quit but didn't die and became a zombie process --->If yes DEATH_REAP: release_task() I clean up relevant resources myself --->If it is a zombie, I will inherit it when my parent process exits init Process, by init Responsible for cleaning --->exit_io_context() clear IO context --->preempt_disable() Disable preemption --->tsk->state = TASK_DEAD; Set me to process death state --->kernel/sched.c:schedule() Release my PCB,Schedule another new process Clean up zombie process: wait system call Wait for the child process to end --->0x80 Interrupt last arrival kernel/exit.c:do_wait() --->do_wait_thread() --->wait_consider_task() --->If the child process is EXIT_DEAD,Return 0, wait The call returns, and the child process cleans itself up --->If the child process is EXIT_ZOMBIE: wait_task_zombie() --->xchg() Set zombie child process to EXIT_DEAD --->release_task() Clean up zombie child processes
The following is the basic execution flow chart:
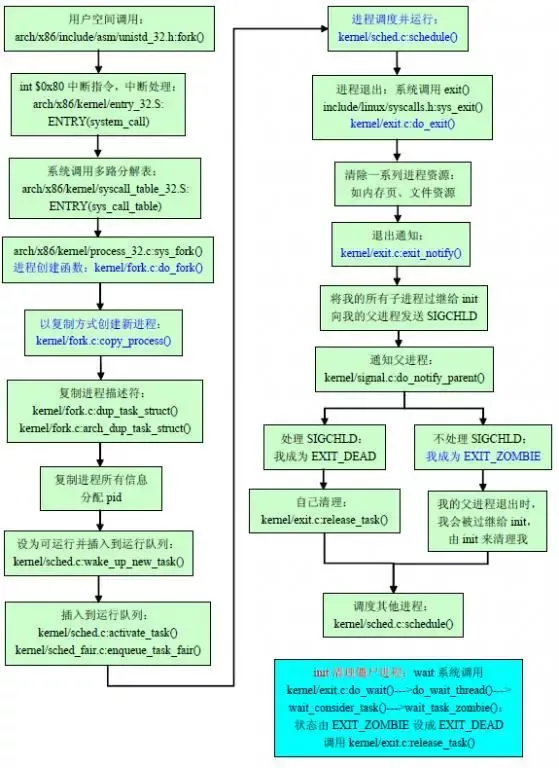
Original link; https://mp.weixin.qq.com/s?__biz=MzUxMjEyNDgyNw==&mid=2247499684&idx=1&sn=3aa314e7079793a8c59991724ae6daf2&chksm=f96b8d50ce1c0446546188411dd4be9b6bbd01f831ebeee0c85a2c335facac880b59ce4e77ab#rd