@[toc]
Last week, brother song reprinted an article on batch data insertion. He talked with you about how to do batch data insertion quickly.
After reading the article, a little partner put forward different opinions:

Brother song had a serious chat with BUG and basically understood the meaning of this little partner, so I also wrote a test case and reorganized today's article. I hope to discuss this problem with my friends and welcome my friends to put forward better solutions.
1. Train of thought analysis
To solve the problem of batch insertion, we use JDBC operation, which is actually two ideas:
- Use a for loop to insert data one by one (this requires batch processing).
- Generate an insert sql, such as insert into user(username,address) values('aa','bb'),('cc','dd').
Which is fast?
We consider this issue from two aspects:
- The efficiency of inserting SQL itself.
- Network I/O.
Let's start with the first scheme, which is to insert with a for loop:
- The advantage of this scheme is that PreparedStatement in JDBC has pre compiled function, which will be buffered after precompilation, and the SQL execution will be faster and JDBC can open batch processing. This batch processing is awesome.
- The disadvantage is that many times our SQL server and application server may not be the same, so we must consider network io. If network IO takes more time, it may slow down the speed of SQL execution.
The second scheme is to generate an SQL insert:
- The advantage of this scheme is that there is only one network IO, and even if the partition processing is only several network IOS, so this scheme will not spend too much time on network io.
- Of course, this scheme has several disadvantages. First, SQL is too long and may even need to be processed in batches after fragmentation; Second, the precompiled advantages of PreparedStatement cannot be brought into full play. SQL needs to be re parsed and cannot be reused; Third, the final generated SQL is too long, and it takes time for the database manager to parse such a long SQL.
Therefore, we should finally consider whether the time we spend on network IO exceeds the time of SQL insertion? This is the core issue we should consider.
2. Data test
Next, let's do a simple test and insert 50000 pieces of data in batch.
First, prepare a simple test table:
CREATE TABLE `user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `address` varchar(255) DEFAULT NULL, `password` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Next, create a Spring Boot project, introduce MyBatis dependency and MySQL driver, and then configure the following database connection information in application.properties:
spring.datasource.username=root spring.datasource.password=123 spring.datasource.url=jdbc:mysql:///batch_insert?serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
You should note that there is an additional parameter rewritebackedstatements in the database connection URL address, which is the core.
By default, the MySQL JDBC driver ignores the executeBatch() statement and breaks up a group of SQL statements that we expect to execute in batches and sends them to the MySQL database one by one. In fact, batch insertion is a single insertion, which directly leads to low performance. Set the rewritebackedstatements parameter to true, and the database driver will help us execute SQL in batches.
OK, so the preparations are ready.
2.1 scheme I test
First, let's look at the test of scheme 1, that is, insert one by one (actually batch processing).
First create the corresponding mapper as follows:
@Mapper
public interface UserMapper {
Integer addUserOneByOne(User user);
}The corresponding XML files are as follows:
<insert id="addUserOneByOne">
insert into user (username,address,password) values (#{username},#{address},#{password})
</insert>The service is as follows:
@Service
public class UserService extends ServiceImpl<UserMapper, User> implements IUserService {
private static final Logger logger = LoggerFactory.getLogger(UserService.class);
@Autowired
UserMapper userMapper;
@Autowired
SqlSessionFactory sqlSessionFactory;
@Transactional(rollbackFor = Exception.class)
public void addUserOneByOne(List<User> users) {
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserMapper um = session.getMapper(UserMapper.class);
long startTime = System.currentTimeMillis();
for (User user : users) {
um.addUserOneByOne(user);
}
session.commit();
long endTime = System.currentTimeMillis();
logger.info("Insert one by one SQL Time consuming {}", (endTime - startTime));
}
}
Here I would like to say:
Although it is inserted one by one, we need to turn on the BATCH mode so that we can only use this SqlSession before and after. If the BATCH mode is not adopted, it will take a lot of time to repeatedly obtain and release connections, and the efficiency is extremely low. Brother song will not test this extremely inefficient method for you.
Next, write a simple test interface to see:
@RestController
public class HelloController {
private static final Logger logger = getLogger(HelloController.class);
@Autowired
UserService userService;
/**
* Insert one by one
*/
@GetMapping("/user2")
public void user2() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 50000; i++) {
User u = new User();
u.setAddress("Guangzhou:" + i);
u.setUsername("Zhang San:" + i);
u.setPassword("123: " + i);
users.add(u);
}
userService.addUserOneByOne(users);
}
}Write a simple unit test:
/**
*
* The purpose of unit test plus transaction is to automatically roll back after insertion to avoid affecting the next test result
* Insert one by one
*/
@Test
@Transactional
void addUserOneByOne() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 50000; i++) {
User u = new User();
u.setAddress("Guangzhou:" + i);
u.setUsername("Zhang San:" + i);
u.setPassword("123: " + i);
users.add(u);
}
userService.addUserOneByOne(users);
}
It can be seen that it takes 901 milliseconds and 5w pieces of data are inserted in less than 1 second.
2.2 scheme II test
The second scheme is to generate an SQL and insert it.
mapper is as follows:
@Mapper
public interface UserMapper {
void addByOneSQL(@Param("users") List<User> users);
}The corresponding SQL is as follows:
<insert id="addByOneSQL">
insert into user (username,address,password) values
<foreach collection="users" item="user" separator=",">
(#{user.username},#{user.address},#{user.password})
</foreach>
</insert>The service is as follows:
@Service
public class UserService extends ServiceImpl<UserMapper, User> implements IUserService {
private static final Logger logger = LoggerFactory.getLogger(UserService.class);
@Autowired
UserMapper userMapper;
@Autowired
SqlSessionFactory sqlSessionFactory;
@Transactional(rollbackFor = Exception.class)
public void addByOneSQL(List<User> users) {
long startTime = System.currentTimeMillis();
userMapper.addByOneSQL(users);
long endTime = System.currentTimeMillis();
logger.info("Merge into one SQL Insertion takes time {}", (endTime - startTime));
}
}Then adjust this method in unit test.
/**
* Merge into one SQL insert
*/
@Test
@Transactional
void addByOneSQL() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 50000; i++) {
User u = new User();
u.setAddress("Guangzhou:" + i);
u.setUsername("Zhang San:" + i);
u.setPassword("123: " + i);
users.add(u);
}
userService.addByOneSQL(users);
}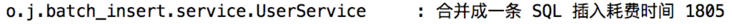
You can see that it takes 1805 milliseconds to insert 50000 pieces of data.
It can be seen that the execution efficiency of generating an SQL is still a little poor.
In addition, it should be noted that the second scheme also has a problem, that is, when the amount of data is large, the generated SQL will be particularly long. MySQL may not be able to process such a large amount of SQL at one time. At this time, it is necessary to modify the MySQL configuration or slice the data to be inserted, which will lead to a longer insertion time.
2.3 comparative analysis
Obviously, scheme 1 has more advantages. When 100000 or 200000 data are inserted in batches, the advantages of scheme 1 will be more obvious (scheme 2 requires modifying the MySQL configuration or slicing the data to be inserted).
3. What does MP do?
As you know, there is also a batch insertion method saveBatch in MyBatis Plus. Let's take a look at its implementation source code:
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);
return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}You can see that the sqlStatement obtained here is an INSERT_ONE, i.e. insert one by one.
Let's look at the executeBatch method, as follows:
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {
int size = list.size();
int i = 1;
for (E element : list) {
consumer.accept(sqlSession, element);
if ((i % batchSize == 0) || i == size) {
sqlSession.flushStatements();
}
i++;
}
});
}Note here that the third parameter in return is a lambda expression, which is also the core logic of batch insertion in MP. You can see that MP splits the data first (the default partition size is 1000). After the partition is completed, it is also inserted one by one. Continue to check the executeBatch method, and you will find that the sqlSession here is actually a batch sqlSession, not an ordinary sqlSession.
To sum up, the batch insertion scheme in MP is actually the same as that in Section 2.1.
4. Summary
Well, after the above analysis, now the partners know what to do with batch insertion, right?
Song brother has provided a test case. The official account is back to the bulk insert test to get the case address. There are three unit test methods in the case. The difference in the time of batch insertion can be seen directly in the database (the database script is in the resources directory).
Interested partners might as well try~
Finally, thank BUG children's shoes again for their comments~