Yunqi information:[ Click to see more industry information]
Here you can find the first-hand cloud information of different industries. What are you waiting for? Come on!
Preface
There is a need for company project recently: report export. In the whole system, at least more than 100 reports need to be exported. At this time, how to implement report export gracefully and release productivity is very important. Next, I'd like to share with you how to use this tool class and how to implement it.
Function point realized
For each report with the same operation, we will naturally pull it out, which is very simple. The most important thing is: how to encapsulate the operations that are different from each report and improve the reusability as much as possible; for the above principles, the following key function points are mainly implemented:
- Export any type of data
- Free setting header
- Free format field export
Use case
As mentioned above, this tool class implements three function points, which can be set when using
- Set data list
- Set header
- Format field
The following export function can directly return an excel data to the client, where productInfoPos is the data list to be exported, and ExcelHeaderInfo is used to save header information, including header name, first column, last column, first row and last row of the header. Because the default exported data format is string type, a Map parameter is also needed to specify the format type of a field (such as number type, decimal type, date type). Here you can know how to use them. The following will explain these parameters in detail.
@Override public void export(HttpServletResponse response, String fileName) { // Data to be exported List<TtlProductInfoPo> productInfoPos = this.multiThreadListProduct(); ExcelUtils excelUtils = new ExcelUtils(productInfoPos, getHeaderInfo(), getFormatInfo()); excelUtils.sendHttpResponse(response, fileName, excelUtils.getWorkbook()); } // Get header information private List<ExcelHeaderInfo> getHeaderInfo() { return Arrays.asList( new ExcelHeaderInfo(1, 1, 0, 0, "id"), new ExcelHeaderInfo(1, 1, 1, 1, "Commodity name"), new ExcelHeaderInfo(0, 0, 2, 3, "classification"), new ExcelHeaderInfo(1, 1, 2, 2, "type ID"), new ExcelHeaderInfo(1, 1, 3, 3, "Classification name"), new ExcelHeaderInfo(0, 0, 4, 5, "brand"), new ExcelHeaderInfo(1, 1, 4, 4, "brand ID"), new ExcelHeaderInfo(1, 1, 5, 5, "Brand name"), new ExcelHeaderInfo(0, 0, 6, 7, "Shop"), new ExcelHeaderInfo(1, 1, 6, 6, "Shop ID"), new ExcelHeaderInfo(1, 1, 7, 7, "Store name"), new ExcelHeaderInfo(1, 1, 8, 8, "Price"), new ExcelHeaderInfo(1, 1, 9, 9, "Stock"), new ExcelHeaderInfo(1, 1, 10, 10, "Sales volume"), new ExcelHeaderInfo(1, 1, 11, 11, "Insert time"), new ExcelHeaderInfo(1, 1, 12, 12, "Update time"), new ExcelHeaderInfo(1, 1, 13, 13, "Whether the record has been deleted") ); } // Get formatting information private Map<String, ExcelFormat> getFormatInfo() { Map<String, ExcelFormat> format = new HashMap<>(); format.put("id", ExcelFormat.FORMAT_INTEGER); format.put("categoryId", ExcelFormat.FORMAT_INTEGER); format.put("branchId", ExcelFormat.FORMAT_INTEGER); format.put("shopId", ExcelFormat.FORMAT_INTEGER); format.put("price", ExcelFormat.FORMAT_DOUBLE); format.put("stock", ExcelFormat.FORMAT_INTEGER); format.put("salesNum", ExcelFormat.FORMAT_INTEGER); format.put("isDel", ExcelFormat.FORMAT_INTEGER); return format; }
Achieving results
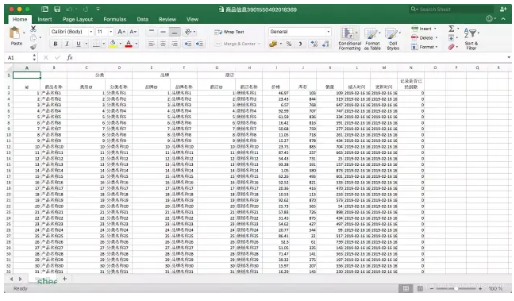
Source code analysis
Haha, it's interesting to analyze your own code. Because it's not convenient to post too much code, you can go to github first, and then come back to read the article. A kind of Source address A kind of This tool of POI version 4.0.1 used by LZ needs to use the SXSSFWorkbook component to export massive data. I won't say much about the specific usage of POI here, mainly to explain how to encapsulate and use poi.
Member variable
Let's focus on the ExcelUtils class, which is the core of the export implementation. First, let's look at three member variables.
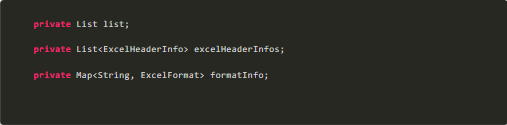
list
This member variable is used to save the data to be exported.
ExcelHeaderInfo
This member variable is mainly used to save header information. Because we need to define multiple header information, we need to use a list to save. The ExcelHeaderInfo constructor is as follows: ExcelHeaderInfo(int firstRow, int lastRow, int firstCol, int lastCol, String title)
- firstRow: the first row of the position occupied by the header
- lastRow: the last row of the position occupied by the header
- firstCol: the first column of the position occupied by this header
- lastCol: the last line of the position occupied by the header
- title: the name of the header
ExcelFormat
This parameter is mainly used to format fields. We need to specify the format to convert it in advance, which can't be determined by the user. So we define a variable of enumeration type, which has only one member variable of string type, to save the format to be converted. For example, format "integer" is to convert to integer. Because we need to accept the conversion format of multiple fields, we define a Map type to receive. This parameter can be omitted (the default format is string).
public enum ExcelFormat { FORMAT_INTEGER("INTEGER"), FORMAT_DOUBLE("DOUBLE"), FORMAT_PERCENT("PERCENT"), FORMAT_DATE("DATE"); private String value; ExcelFormat(String value) { this.value = value; } public String getValue() { return value; } }
Core approach
- Create header
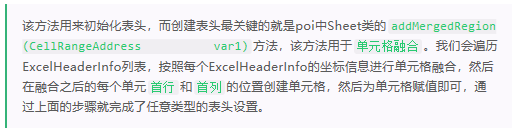
// Create header private void createHeader(Sheet sheet, CellStyle style) { for (ExcelHeaderInfo excelHeaderInfo : excelHeaderInfos) { Integer lastRow = excelHeaderInfo.getLastRow(); Integer firstRow = excelHeaderInfo.getFirstRow(); Integer lastCol = excelHeaderInfo.getLastCol(); Integer firstCol = excelHeaderInfo.getFirstCol(); // Cell fusion occurs when the row spacing or column spacing is greater than 0 if ((lastRow - firstRow) != 0 || (lastCol - firstCol) != 0) { sheet.addMergedRegion(new CellRangeAddress(firstRow, lastRow, firstCol, lastCol)); } // Get the first row position of the current header Row row = sheet.getRow(firstRow); // Create a new cell in the first row and column of the header Cell cell = row.createCell(firstCol); // Assigned cell cell.setCellValue(excelHeaderInfo.getTitle()); cell.setCellStyle(style); sheet.setColumnWidth(firstCol, sheet.getColumnWidth(firstCol) * 17 / 12); } }
- Convert data

// Convert raw data to 2D array private String[][] transformData() { int dataSize = this.list.size(); String[][] datas = new String[dataSize][]; // Get the number of columns in the report Field[] fields = list.get(0).getClass().getDeclaredFields(); // Get the field name array of entity class List<String> columnNames = this.getBeanProperty(fields); for (int i = 0; i < dataSize; i++) { datas[i] = new String[fields.length]; for (int j = 0; j < fields.length; j++) { try { // assignment datas[i][j] = BeanUtils.getProperty(list.get(i), columnNames.get(j)); } catch (Exception e) { LOGGER.error("Failed to get object property value"); e.printStackTrace(); } } } return datas; }
In this method, we use reflection technology to skillfully implement any type of data export (here, any type refers to any report type, different reports, the exported data must be different, so the entity class in the Java implementation must also be different). To convert a List into a corresponding 2D array, we need to know the following information:
- Number of columns in a two-dimensional array
- Number of rows in a two-dimensional array
- Values for each element of a 2D array
What if we get the above three information?
- Through the Field[] getDeclaredFields() method in the reflection, all fields of the entity class are obtained, so as to indirectly know how many columns there are in total
- The size of the List is just the number of rows of the two-dimensional array
- Although the field names of each entity class are different, can we really not get the value of a field of the entity class? No, you need to know that if you have reflection, you will have the whole world. What else can't be done. Instead of using reflection directly, we use a tool called BeanUtils, which can easily help us to assign field values and get field values for an entity class. Very simply, through the line of BeanUtils.getProperty(list.get(i), columnNames.get(j)), we get the value of the field named columnNames.get(j) in the entity list.get(i). list.get(i) is of course the entity class that we traverse the original data, while columnNames list is an array of all field names of entity class, which is also obtained by reflection method. For specific implementation, please refer to LZ source code.
- Assignment body

// Create body private void createContent(Row row, CellStyle style, String[][] content, int i, Field[] fields) { List<String> columnNames = getBeanProperty(fields); for (int j = 0; j < columnNames.size(); j++) { if (formatInfo == null) { row.createCell(j).setCellValue(content[i][j]); continue; } if (formatInfo.containsKey(columnNames.get(j))) { switch (formatInfo.get(columnNames.get(j)).getValue()) { case "DOUBLE": row.createCell(j).setCellValue(Double.parseDouble(content[i][j])); break; case "INTEGER": row.createCell(j).setCellValue(Integer.parseInt(content[i][j])); break; case "PERCENT": style.setDataFormat(HSSFDataFormat.getBuiltinFormat("0.00%")); Cell cell = row.createCell(j); cell.setCellStyle(style); cell.setCellValue(Double.parseDouble(content[i][j])); break; case "DATE": row.createCell(j).setCellValue(this.parseDate(content[i][j])); } } else { row.createCell(j).setCellValue(content[i][j]); } } }
The core method of exporting tool class is almost finished. Let's talk about multi-threaded query.
Two more points
- Multi thread query data

Now let's talk about the specific idea: because multiple threads execute at the same time, you can't guarantee which thread finishes executing first, but we have to ensure the consistency of data order. Here we use the Callable interface. The thread that implements the Callable interface can have the return value. We get the query results of all the sub threads, and then merge them into a result set. How to ensure the order of merging? First, we create a List of FutureTask type, which is the returned result set.
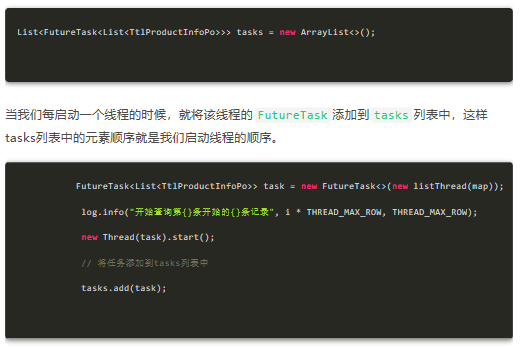
Next, it's the sequence plug value. We take FutureTask out of the tasks list in order, and then execute FutureTask's get() method, which will block the calling thread until we get the returned result. In this way, all data can be stored in order.
for (FutureTask<List<TtlProductInfoPo>> task : tasks) { try { productInfoPos.addAll(task.get()); } catch (Exception e) { e.printStackTrace(); } }
- How to solve interface timeout
If you need to export massive data, there may be a problem: interface timeout, the main reason is that the whole export process takes too long. In fact, it's a good solution. The response time of the interface is too long. We can shorten the response time. We use asynchronous programming solutions. There are many ways to implement asynchronous programming. Here we use the simplest Async annotation in spring. With this annotation, we can immediately return the response results. As for the usage of annotations, you can refer to them for yourself. Here are the key implementation steps:
- Write the asynchronous interface, which is responsible for receiving the export request from the client, and then start the export (Note: the export here is not directly returned to the client, but downloaded to the local server). As long as the export instruction is issued, you can immediately return a unique mark of the excel file to the client (used to find the file later), and the interface ends.
- Write the excel status interface. After the client gets the unique mark of the excel file, it starts to poll and call the interface every second to check the export status of the excel file
- Write the excel file interface returned from the local server. If the client checks that excel has been successfully downloaded to the local server, it can request the interface to download the file directly.
This can solve the problem of interface timeout.
Source address
https://github.com/dearKundy/excel-utils
Source taking posture
1. Create table (insert data by yourself)
CREATE TABLE `ttl_product_info` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Record unique identification', `product_name` varchar(50) NOT NULL COMMENT 'Commodity name', `category_id` bigint(20) NOT NULL DEFAULT '0' COMMENT 'type ID', `category_name` varchar(50) NOT NULL COMMENT 'Redundant classification name-Avoid cross table join', `branch_id` bigint(20) NOT NULL COMMENT 'brand ID', `branch_name` varchar(50) NOT NULL COMMENT 'Redundant brand name-Avoid cross table join', `shop_id` bigint(20) NOT NULL COMMENT 'commodity ID', `shop_name` varchar(50) NOT NULL COMMENT 'Redundant store name-Avoid cross table join', `price` decimal(10,2) NOT NULL COMMENT 'Current price of goods-It belongs to hot spot data, and price changes need to be recorded, and price detail table is needed', `stock` int(11) NOT NULL COMMENT 'Stock-Hot data', `sales_num` int(11) NOT NULL COMMENT 'Sales volume', `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Insert time', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Update time', `is_del` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT 'Whether the record has been deleted', PRIMARY KEY (`id`), KEY `idx_shop_category_salesnum` (`shop_id`,`category_id`,`sales_num`), KEY `idx_category_branch_price` (`category_id`,`branch_id`,`price`), KEY `idx_productname` (`product_name`) ) ENGINE=InnoDB AUTO_INCREMENT=15000001 DEFAULT CHARSET=utf8 COMMENT='Commodity information table';
Run program
In the address bar of the browser, enter: http://localhost:8080/api/excelUtils/export Download complete
[yunqi online class] product technology experts share every day!
Course address: https://yqh.aliyun.com/zhibo
Join the community immediately, face to face with experts, and keep abreast of the latest news of the course!
[yunqi online classroom community] https://c.tb.cn/F3.Z8gvnK
Original release time: May 9, 2020
Author: you are at my door
This article comes from:“ Internet architect WeChat official account ”, you can pay attention to“ Internet architect"