We know that PyFlink is newly added in Apache Flink version 1.9, so can the speed of Python UDF function support in Apache Flink 1.10 meet the urgent needs of users?

The development trend of Python UDF
Intuitively, the function of PyFlink Python UDF can also be changed from a seedling to a tree as shown in the above figure. Why do you have this judgment? Please continue to look down
Flink on Beam
We all know that there is a scenario of Beam on Flink, that is, Beam supports multiple runners, that is, jobs written by the Beam SDK can run on Flink. As shown in the figure below:
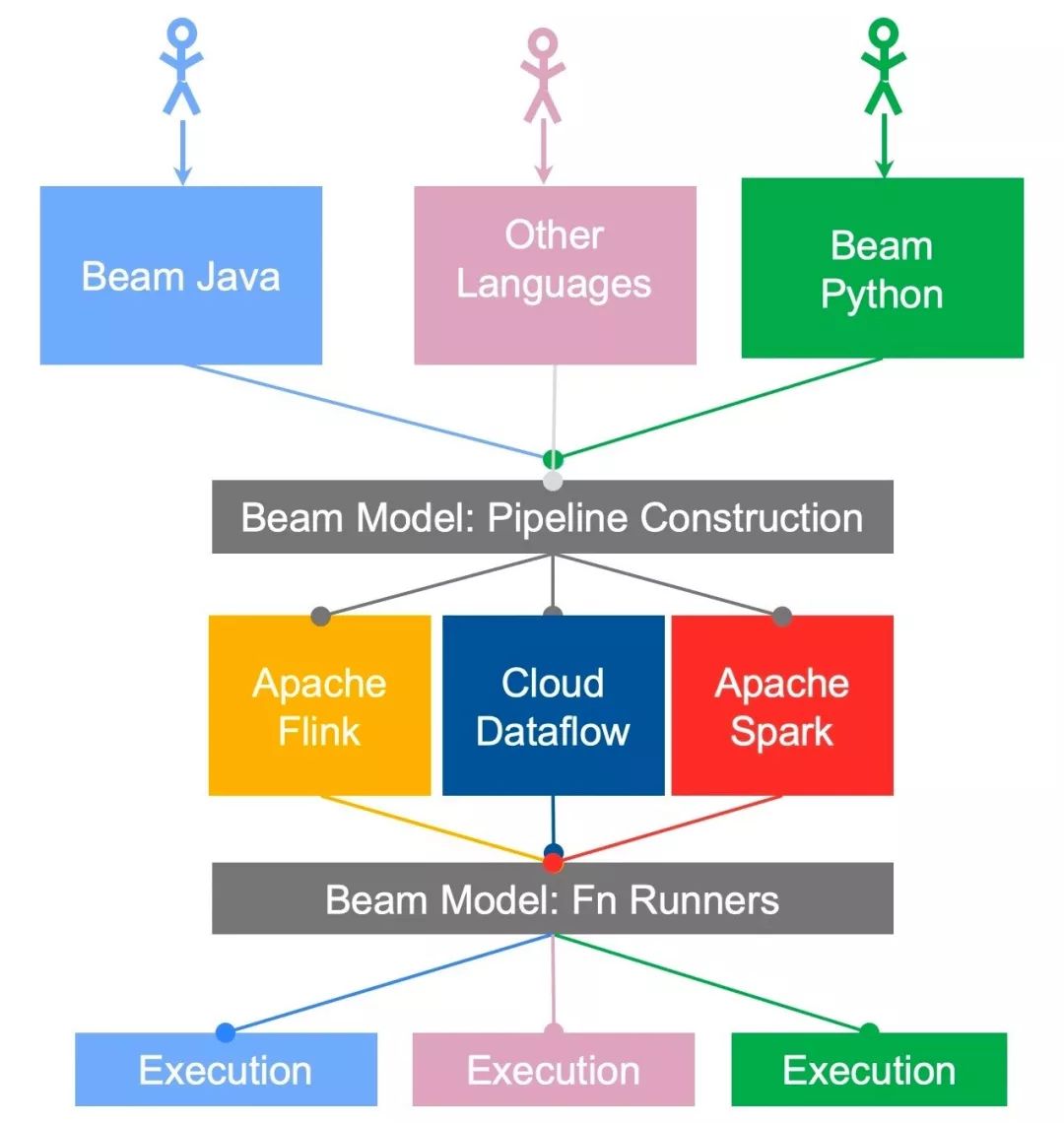
The above figure is the architecture diagram of the Beam Portability Framework. It describes how the Beam supports multiple languages and multiple runners. When we say Apache Flink alone, we can say that it is Beam on Flink. So how to explain Flink on Beam?

In Apache Flink 1.10, the Flink on Beam we mentioned is more precisely the PyFlink on Beam Portability Framework. Let's take a look at a simple architecture diagram, as follows:
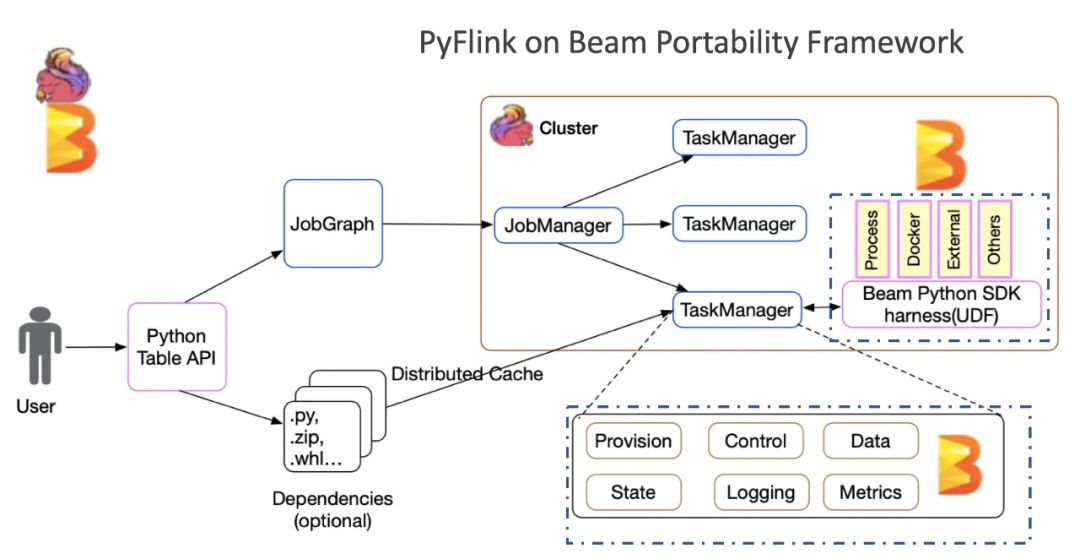
The Beam Portability Framework is a mature multi language support framework, which highly abstracts the communication protocol (gRPC) between languages, defines the data transfer format (Protobuf), and abstracts various services, such as DataService, StateService, MetricsService, etc., according to the components required by the general flow computing framework. In such a mature framework, PyFlink can quickly build its own Python operators, reuse the existing SDK harness components in the Apache Beam Portability Framework, and support a variety of Python running modes, such as: Process, Docker, etc., which makes PyFlink's support for Python UDF very easy, and its functions in Apache Flink 1.10 are also very good Stability and integrity. So why did Apache Flink and Apache Beam build it together? Because I found that there are many optimization spaces in the current Apache Beam Portability Framework framework framework, so I did it in the Beam community Optimization discussion And contributed to the Beam community 20 + optimized patch.
After a brief understanding of the architecture of Python UDF in Apache Flink 1.10, let's cut into the code part to see how to develop and use Python UDF.
How to define Python UDF
In Apache Flink 1.10, we have a variety of ways to define UDF, such as:
- Extend ScalarFunction, e.g.:
class HashCodeMean(ScalarFunction): def eval(self, i, j): return (hash(i) + hash(j)) / 2
- Lambda Functio
lambda i, j: (hash(i) + hash(j)) / 2
- Named Function
def hash_code_mean(i, j): return (hash(i) + hash(j)) / 2
- Callable Function
class CallableHashCodeMean(object): def __call__(self, i, j): return (hash(i) + hash(j)) / 2
We found that the first way to extend ScalaFunction is unique to PyFlink, and other ways are supported by Python. That is to say, in Apache Flink 1.10, PyFlink allows UDF to be defined in any way supported by Python.
How to use Python UDF
So after defining UDF, how should we use it? Apache Flink 1.10 provides two kinds of Decorators, as follows:
- Decorators - udf(), e.g. :
udf(lambda i, j: (hash(i) + hash(j)) / 2, [for input types], [for result types])
- Decorators - @udf, e.g. :
@udf(input_types=..., result_type=...) def hash_code_mean(...): return ...
Then register before use, as follows:
st_env.register_function("hash_code", hash_code_mean)
Next, it can be used in Table API/SQL, as follows:
my_table.select("hash_code_mean(a, b)").insert_into("Results")
So far, we have finished the definition, declaration and registration of Python UDF. Let's take a complete example:)
Case description
- demand
Suppose Apple wants to count the distribution of sales volume and sales amount of its products in each city during the double 11 period.
- data format
Each order is a string with fields separated by commas, for example:
ItemName, OrderCount, Price, City ------------------------------------------- iPhone 11, 30, 5499, Beijing\n iPhone 11 Pro,20,8699,Guangzhou\n
case analysis
According to the case requirements and data structure analysis, we need to carry out structural analysis on the original string, so we need a UDF(split) separated by "," and a DUF(get) which can flatten the information of each column. At the same time, we need to group statistics according to cities.
Core realization
UDF definition
- Split UDF
@udf(input_types=[DataTypes.STRING()], result_type=DataTypes.ARRAY(DataTypes.STRING())) def split(line): return line.split(",")
- Get UDF
@udf(input_types=[DataTypes.ARRAY(DataTypes.STRING()), DataTypes.INT()], result_type=DataTypes.STRING()) def get(array, index): return array[index]
Registered UDF
- Register Split UDF
t_env.register_function("split", split)
- Register Get UDF
t_env.register_function("get", get)
Core implementation logic
In the following code, we find that the core implementation logic is very simple, and only need to analyze the data and calculate the data set:
t_env.from_table_source(SocketTableSource(port=9999))\ .alias("line")\ .select("split(line) as str_array")\ .select("get(str_array, 3) as city, " "get(str_array, 1).cast(LONG) as count, " "get(str_array, 2).cast(LONG) as unit_price")\ .select("city, count, count * unit_price as total_price")\ .group_by("city")\ .select("city, sum(count) as sales_volume, sum(total_price) as sales")\ .insert_into("sink") t_env.execute("Sales Statistic")
In the above code, we assume that it is a Socket Source and Sink is a Chart Sink. Then the final running effect is as follows:

I always think that a blog that is just a text description and can't let readers run on their own machine is not a good blog, so let's see if it can run on your machine according to our following operations? )
Environmental Science
Because currently PyFlink has not been deployed to PyPI, before Apache Flink 1.10 was released, we need to build the PyFlink version running our Python UDF by building the master Branch source code of Flink.
Source code compilation
Before compiling the code, we need you to have installed JDK8 and Maven3x.
- Download decompression
tar -xvf apache-maven-3.6.1-bin.tar.gz mv -rf apache-maven-3.6.1 /usr/local/
- Modify environment variable (~ /. bashrc)
MAVEN_HOME=/usr/local/apache-maven-3.6.1 export MAVEN_HOME export PATH=${PATH}:${MAVEN_HOME}/bin
In addition to JDK and MAVEN, the complete environment dependency is as follows:
- JDK 1.8+ (1.8.0_211)
- Maven 3.x (3.2.5)
- Scala 2.11+ (2.12.0)
- Python 3.6+ (3.7.3)
- Git 2.20+ (2.20.1)
- Pip3 19+ (19.1.1)
We see that the basic environment installation is relatively simple, and I don't post every one here. If you have any questions, welcome to email or blog.
- Download Flink source code:
git clone https://github.com/apache/flink.git
- Compile
cd flink mvn clean install -DskipTests ... ... [INFO] flink-walkthrough-datastream-scala ................. SUCCESS [ 0.192 s] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 18:34 min [INFO] Finished at: 2019-12-04T23:03:25+08:00 [INFO] ------------------------------------------------------------------------
- Build the PyFlink release package
cd flink-python; python3 setup.py sdist bdist_wheel ... ... adding 'apache_flink-1.10.dev0.dist-info/WHEEL' adding 'apache_flink-1.10.dev0.dist-info/top_level.txt' adding 'apache_flink-1.10.dev0.dist-info/RECORD' removing build/bdist.macosx-10.14-x86_64/wheel
- Install PyFlink(PyFlink 1.10 requires Python 3.6 +)
pip3 install dist/*.tar.gz ... ... Successfully installed apache-beam-2.15.0 apache-flink-1.10.dev0 avro-python3-1.9.1 cloudpickle-1.2.2 crcmod-1.7 dill-0.2.9 docopt-0.6.2 fastavro-0.21.24 future-0.18.2 grpcio-1.25.0 hdfs-2.5.8 httplib2-0.12.0 mock-2.0.0 numpy-1.17.4 oauth2client-3.0.0 pbr-5.4.4 protobuf-3.11.1 pyarrow-0.14.1 pyasn1-0.4.8 pyasn1-modules-0.2.7 pydot-1.4.1 pymongo-3.9.0 pyyaml-3.13 rsa-4.0
You can also see that our core needs Apache beam and Apache Flink, as follows:
jincheng:flink-python jincheng.sunjc$ pip3 list Package Version ----------------------------- --------- alabaster 0.7.12 apache-beam 2.15.0 apache-flink 1.10.dev0 atomicwrites 1.3.0
The above information proves that the Python dependency we need is no problem. Next, we will look back at how to develop business requirements.
Job structure of PyFlinlk
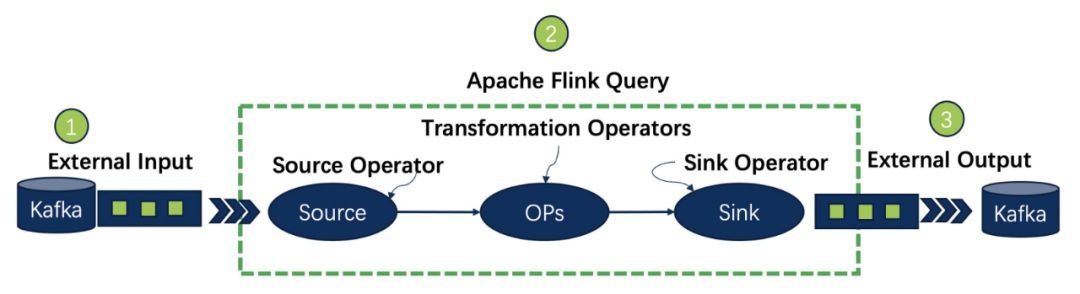
A completed Job of PyFlink needs to have the definition of external data source, the definition of business logic and the definition of final calculation result output. That is, Source connector, Transformations, Sink connector. Next, we will complete our requirements according to these three parts.
Source Connector
We need to implement a Socket Connector. First, we need to implement a StreamTableSource. The core code is to implement getDataStream. The code is as follows:
@Override public DataStream<Row> getDataStream(StreamExecutionEnvironment env) { return env.socketTextStream(hostname, port, lineDelimiter, MAX_RETRY) .flatMap(new Spliter(fieldNames.length, fieldDelimiter, appendProctime)) .returns(getReturnType()); }
The above code uses the existing socketTextStream method in StreamExecutionEnvironment to receive data, and then transmits the business order data to a flatmapfunction. Flatmapfunction mainly encapsulates the data type as Row, which can be consulted in detail Spliter.
At the same time, we need to encapsulate a socketablesource in Python. For details, please refer to socket_table_source.py.
Sink Connector
One effect we expect to get is to be able to graphically display the result data. The simple idea is to write the data to a local file, and then write an HTML page, so that it can automatically update the result file and display the results. So we also need to customize a Sink to complete this function. Our demand calculation results will be constantly updated, that is, when it comes to Retraction (if you don't understand this concept, you can refer to my previous blog). Currently, there is no Sink that supports Retract by default in Flink, so we need to customize a RetractSink, such as our implementation Take a look at CsvRetractTableSink.
The core logic of CsvRetractTableSink is to buffer the calculation results and output the full amount of files (this is a pure demo and cannot be used in the production environment) once every update. Source code lookup CsvRetractTableSink.
At the same time, we need to use Python for encapsulation. For details, see chart_table_sink.py.
In chart_table_sink.py, we encapsulate an http server so that we can check our statistics in the browser.
Business logic
After completing the customized Source and Sink, we can finally develop the business logic. In fact, the whole process of customizing Source and Sink is the most troublesome, and the core computing logic seems to be much simpler.
- Set Python Version (important)
If the python command version of your local environment is 2.x, you need to set the python version as follows:
t_env.get_config().set_python_executable("python3")
Python 3.6 + is supported after PyFlink 1.10.
- Read data source
The PyFlink reading data source is very simple, as follows:
... ... t_env.from_table_source(SocketTableSource(port=9999)).alias("line")
The above line of code defines the data source listening to port 9999, and the structured Table has only one column named line.
- Parsing raw data
We need to analyze the above columns. In order to demonstrate Python UDF, we do not preprocess the data in socketablesource, so we use the UDF defined in the UDF definition section above to preprocess the original data.
... ... .select("split(line) as str_array") .select("get(str_array, 3) as city, " "get(str_array, 1).cast(LONG) as count, " "get(str_array, 2).cast(LONG) as unit_price") .select("city, count, count * unit_price as total_price")
- statistical analysis
The core statistical logic is to group by city, and then sum the sales quantity and sales amount, as follows:
... ... .group_by("city") .select("city, sum(count) as sales_volume, sum(total_price) as sales")\
- Calculation result output
The calculation results are written into our custom Sink as follows:
... ... .insert_into("sink")
- Complete code( blog_demo.py)
from pyflink.datastream import StreamExecutionEnvironment from pyflink.demo import ChartConnector, SocketTableSource from pyflink.table import StreamTableEnvironment, EnvironmentSettings, DataTypes from pyflink.table.descriptors import Schema from pyflink.table.udf import udf env = StreamExecutionEnvironment.get_execution_environment() t_env = StreamTableEnvironment.create( env, environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build()) t_env.connect(ChartConnector())\ .with_schema(Schema() .field("city", DataTypes.STRING()) .field("sales_volume", DataTypes.BIGINT()) .field("sales", DataTypes.BIGINT()))\ .register_table_sink("sink") @udf(input_types=[DataTypes.STRING()], result_type=DataTypes.ARRAY(DataTypes.STRING())) def split(line): return line.split(",") @udf(input_types=[DataTypes.ARRAY(DataTypes.STRING()), DataTypes.INT()], result_type=DataTypes.STRING()) def get(array, index): return array[index] t_env.get_config().set_python_executable("python3") t_env.register_function("split", split) t_env.register_function("get", get) t_env.from_table_source(SocketTableSource(port=6666))\ .alias("line")\ .select("split(line) as str_array")\ .select("get(str_array, 3) as city, " "get(str_array, 1).cast(LONG) as count, " "get(str_array, 2).cast(LONG) as unit_price")\ .select("city, count, count * unit_price as total_price")\ .group_by("city")\ .select("city, " "sum(count) as sales_volume, " "sum(total_price) as sales")\ .insert_into("sink") t_env.execute("Sales Statistic")
In the above code, you will find a strange part: from pyflink.demo import chartconnector, socketablesource. Where is pyflink.demo from? In fact, it includes the custom Source/Sink (Java & Python) introduced above. Let's show you how to add the pyflink.demo module.
Install pyflink.demo
For your convenience, I put the source code of custom Source/Sink (Java & Python) here. You can do the following:
- Download source code
git clone https://github.com/sunjincheng121/enjoyment.code.git
- Compile source code
cd enjoyment.code/PyUDFDemoConnector/; mvn clean install
- Build release package
python3 setup.py sdist bdist_wheel ... ... adding 'pyflink_demo_connector-0.1.dist-info/WHEEL' adding 'pyflink_demo_connector-0.1.dist-info/top_level.txt' adding 'pyflink_demo_connector-0.1.dist-info/RECORD' removing build/bdist.macosx-10.14-x86_64/wheel
- Install Pyflink.demo
pip3 install dist/pyflink-demo-connector-0.1.tar.gz ... ... Successfully built pyflink-demo-connector Installing collected packages: pyflink-demo-connector Successfully installed pyflink-demo-connector-0.1
The above information appears to prove that the PyFlink.demo module has been successfully installed. Next we can run our example:)
Operation example
The sample code has been included in the source code downloaded above. For simplicity, we use PyCharm to open enjoyment.code/myPyFlink. Start a port at Terminal at the same time:
nc -l 6666
If everything goes well, the console will output a web address as follows:
We open this page and start with a blank page, as follows:
We try to send the following data, one by one, to the Source Connector:
iPhone 11,30,5499,Beijing iPhone 11 Pro,20,8699,Guangzhou MacBook Pro,10,9999,Beijing AirPods Pro,50,1999,Beijing MacBook Pro,10,11499,Shanghai iPhone 11,30,5999,Shanghai iPhone 11 Pro,20,9999,Shenzhen MacBook Pro,10,13899,Hangzhou iPhone 11,10,6799,Beijing MacBook Pro,10,18999,Beijing iPhone 11 Pro,10,11799,Shenzhen MacBook Pro,10,22199,Shanghai AirPods Pro,40,1999,Shanghai
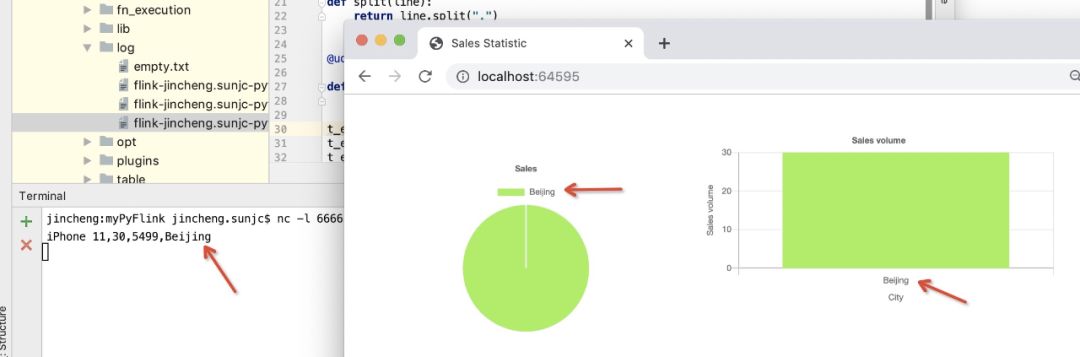
After entering the first order iPhone 11, 305499, Beijing, the page changes as follows:
With the continuous input of order data, the statistical chart is constantly changing. A complete GIF demonstration is as follows:
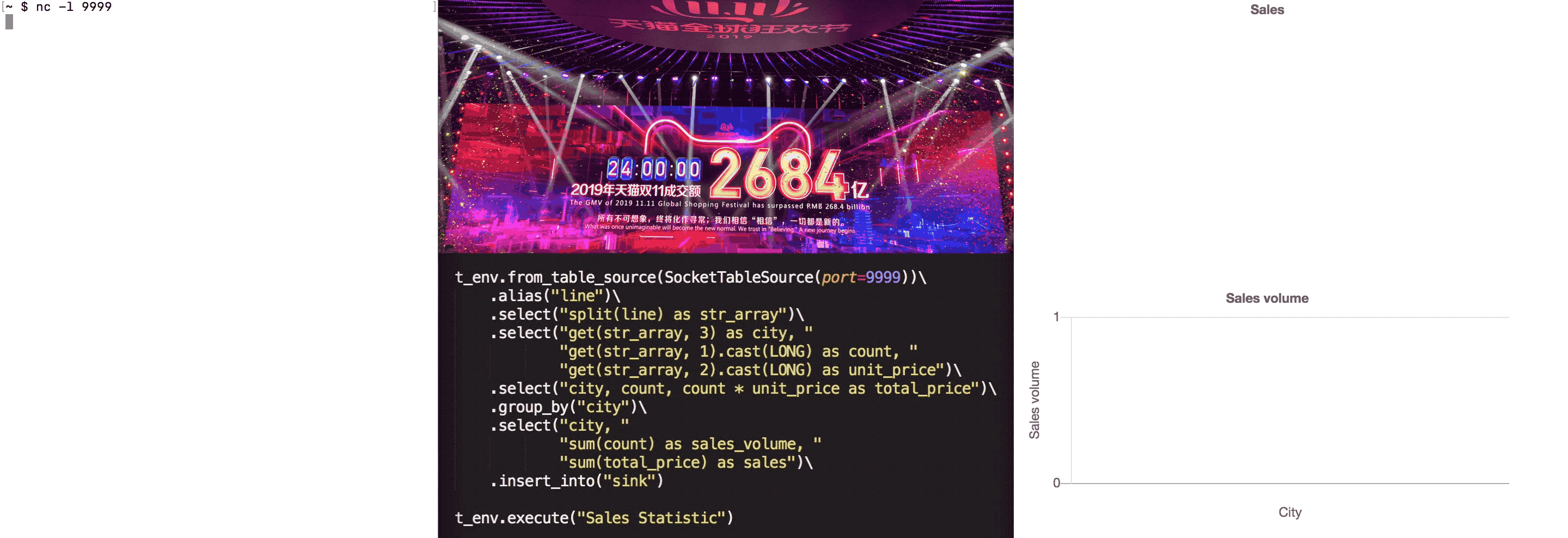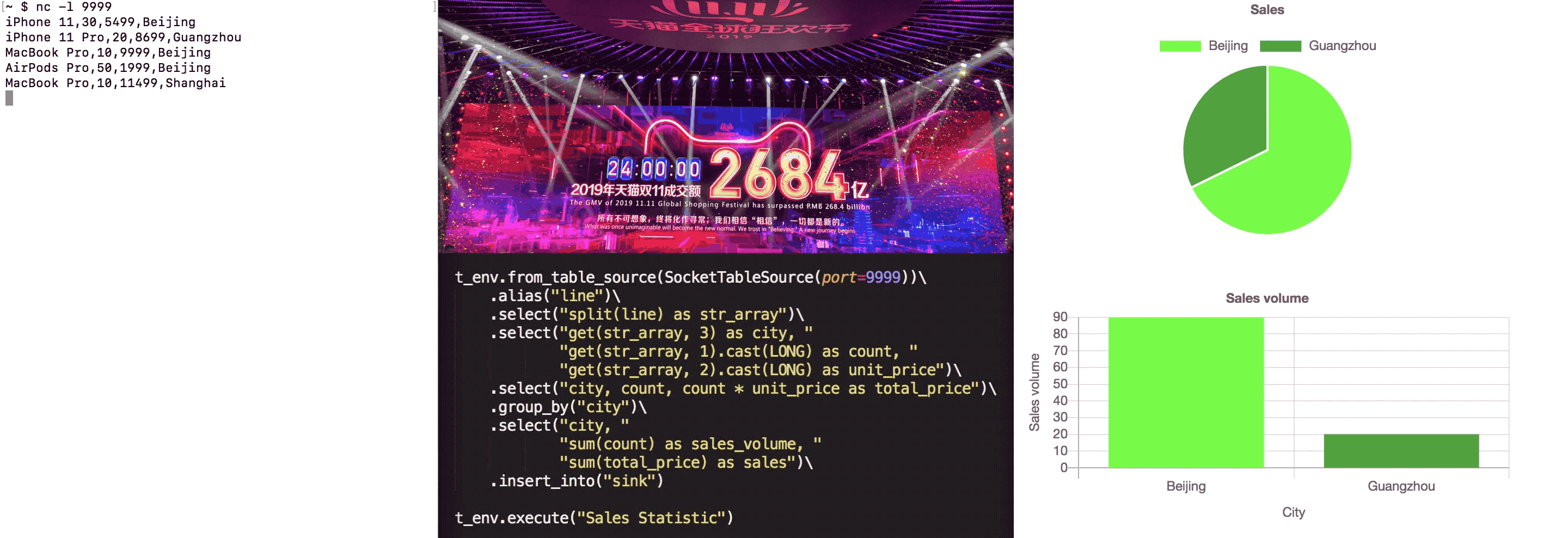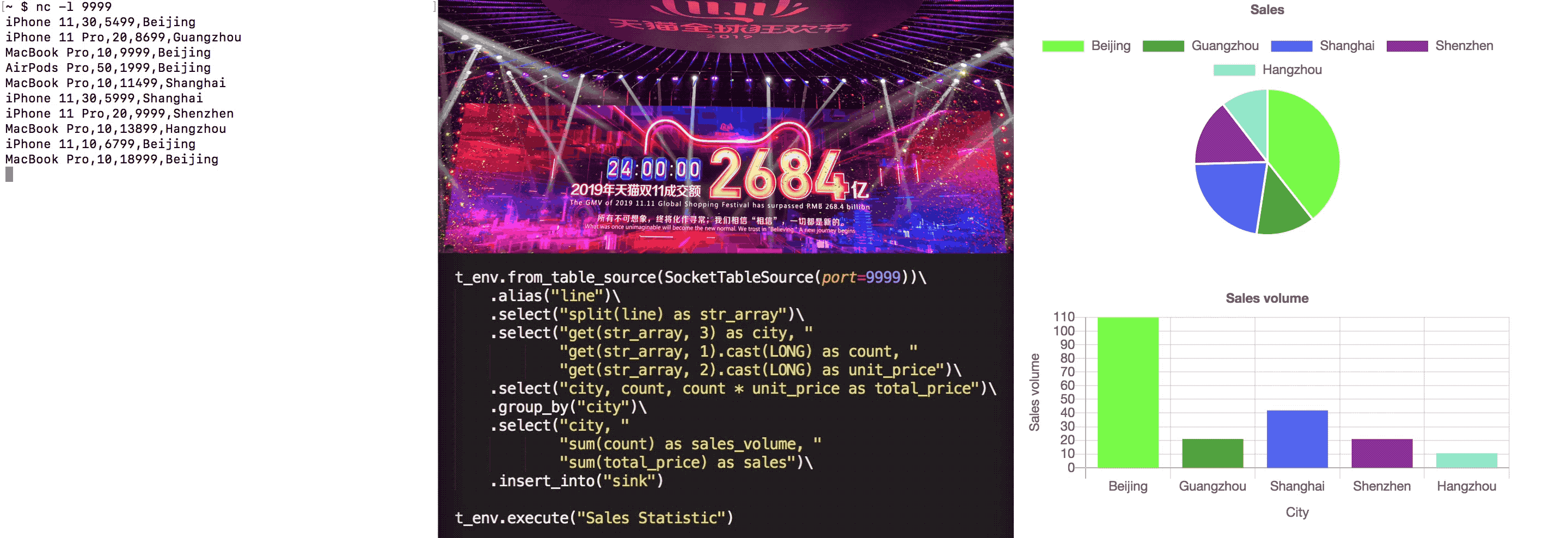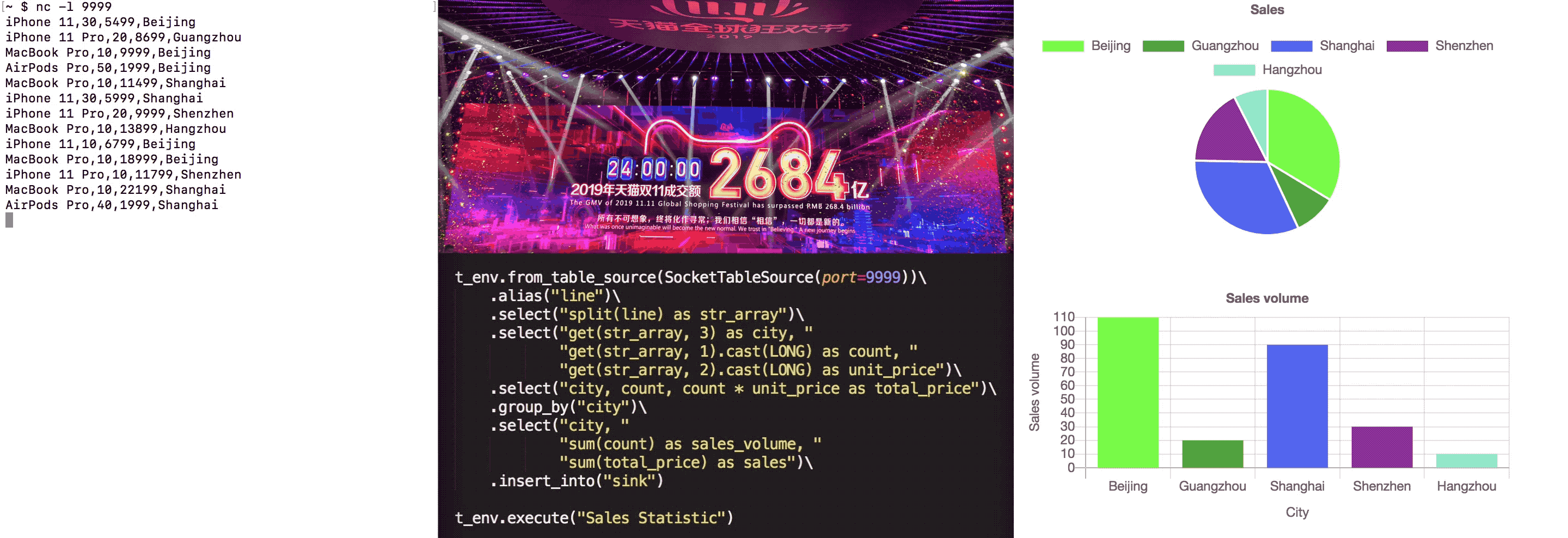
Summary
From architecture to UDF interface definition to specific examples, this article introduces how to use PyFlink for business development after Apache Flink 1.10 is released, in which user-defined Source and Sink are relatively complex, which is also the part of the community that needs to be improved (Java/Scala). In fact, the real core logic part is relatively simple. In order to achieve some success in the actual operation according to this article, I added the customized Source/Sink and graphical part. But if you want to simplify the implementation of the instance, you can also use Kafka as the Source and Sink, so you can save the customized part and make it easier.