Crawl all the information of Cat's Eye, mainly refer to the movie information and actors information in the movie list, such as the interface below.
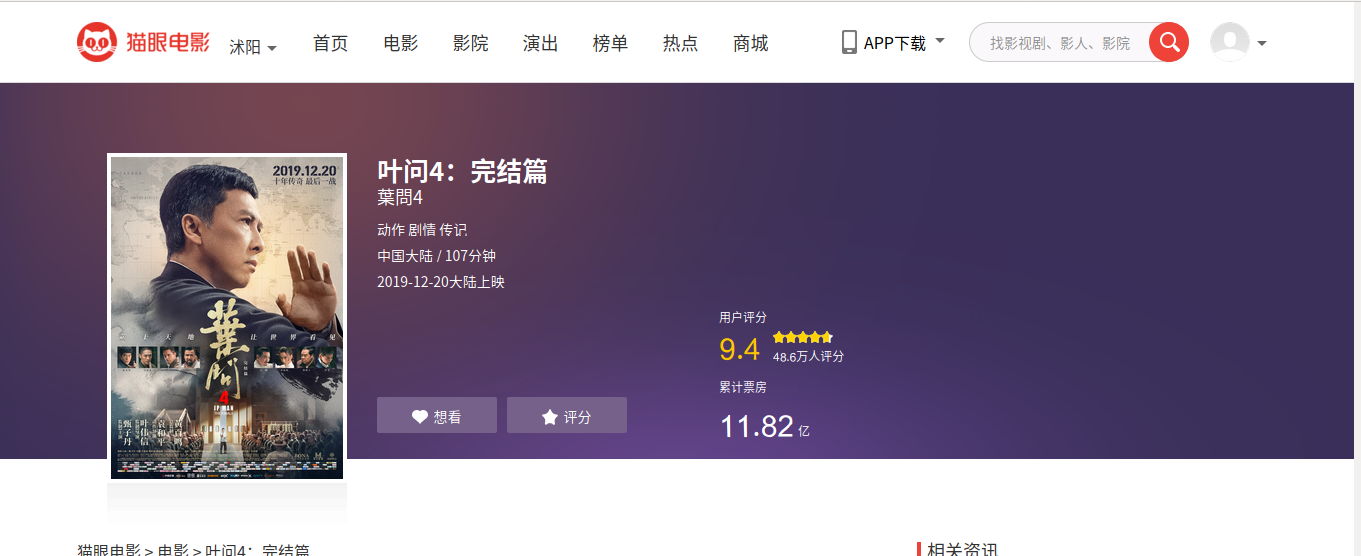
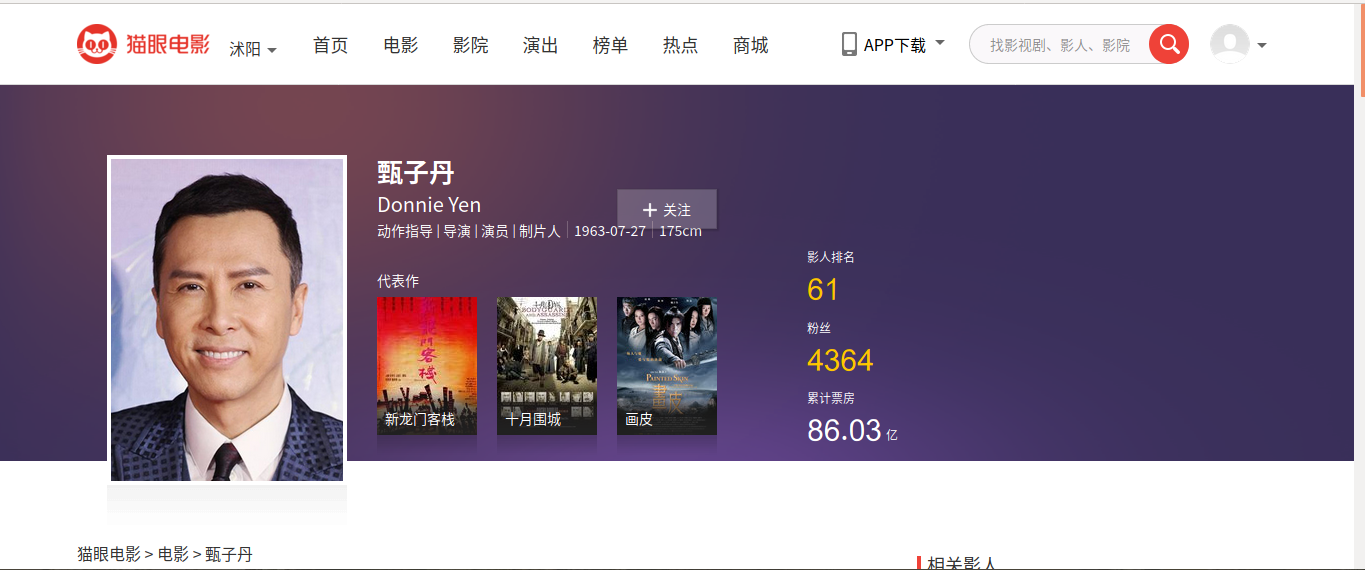 There are two difficulties when crawling.One: Font encryption (now seems to have a newer mechanism, but it is not possible to use the online method); two: Meituan detection.Below I will describe the process of my resolution.
There are two difficulties when crawling.One: Font encryption (now seems to have a newer mechanism, but it is not possible to use the online method); two: Meituan detection.Below I will describe the process of my resolution.
1. Font Encryption
About font encryption, there are many descriptions on the network, and the ideas are similar.The cat's eye dynamically loads different font codes each time it loads.The solution is to download one of its font files (.woff ends, methods are introduced on the Internet, I won't go over it) and then compare the font coordinates of the new font file with those downloaded before each time I crawl the new interface.Many methods on the Internet were still a long time ago. At that time, the font encryption mechanism of Cat's Eye was very simple, only if the relative coordinates were equal. Now the mechanism is that every loaded font has subtle changes.Many people on the Internet have a way of saying that their changes are within a range and that the same number exists as long as the difference between them is not more than one range.I also used this method, but found that a lot of numbers were recognized incorrectly, such as 3,5,9; 1,4; 0,8; these three sets of numbers are easily confused.It is not that simple to explain the problem.The first method I used was to take three base font files and then compare each base font file with the dynamically loaded coordinates. I also set a range of differences to count the processes that match this difference, and the last one that counts the largest is certified as the corresponding number.After doing this, there are still errors, and I found that the number of coordinates per number is different. For example, the number of coordinates of 3,5,9 is significantly different. Because the number of coordinates of each number is also different each time it is loaded, there are slight differences, so I will make a difference judgment on the number of coordinates.Another important thing is the choice of this difference value. Many choices on the Internet are 8 and 10. Perhaps the reason for the change of cat's eye encryption mechanism is that these preset difference values have a low recognition rate.When I try 5, the recognition rate is the highest. You can experiment with it yourself.Previously, we selected three sets of benchmarks, because we have done the previous recognition operation, the recognition rate is very high, so we will do another two-game operation to improve the recognition rate again.Because there is so much code, I put in some key code.There's another way that might work. I haven't tried it. You can refer to this blog Reference Blog This blog is recognized by the knn algorithm and should have a high recognition rate.But this requires more font files to improve recognition.
def replace_font(self, response,res):
#Benchmark, compare three times, agree more than two times, default correct
#I'm "I want to be a Taoist". Other non-original
base_font = TTFont('./fonts/base.woff')
base_font.saveXML('./fonts/base_font.xml')
base_dict = {'uniF870': '6', 'uniEE8C': '3', 'uniECDC': '7', 'uniE6A2': '1', 'uniF734': '5',
'uniF040': '9', 'uniEAE5': '0', 'uniF12A': '4', 'uniF2D2': '2', 'uniE543': '8'}
base_list = base_font.getGlyphOrder()[2:]
base_font2 = TTFont('./fonts/base2.woff')
base_font2.saveXML('./fonts/base_font2.xml')
base_dict2 = {'uniF230': '6', 'uniEBA1': '3', 'uniF517': '7', 'uniF1D2': '1', 'uniE550': '5',
'uniEBA4': '9', 'uniEB7A': '0', 'uniEC29': '4', 'uniF7E1': '2', 'uniF6B7': '8'}
base_list2 = base_font2.getGlyphOrder()[2:]
base_font3 = TTFont('./fonts/base3.woff')
base_font3.saveXML('./fonts/base_font3.xml')
base_dict3 = {'uniF8D3': '6', 'uniF0C9': '3', 'uniEF09': '7', 'uniE9FD': '1', 'uniE5B7': '5',
'uniF4DE': '9', 'uniF4F9': '0', 'uniE156': '4', 'uniE9B5': '2', 'uniEC6D': '8'}
base_list3 = base_font3.getGlyphOrder()[2:]
#Fonts dynamically loaded by websites
#I'm "I want to be a Taoist". Other non-original
font_file = re.findall(r'vfile\.meituan\.net\/colorstone\/(\w+\.woff)', response)[0]
font_url = 'http://vfile.meituan.net/colorstone/' + font_file
#print(font_url)
new_file = self.get_html(font_url)
with open('./fonts/new.woff', 'wb') as f:
f.write(new_file.content)
new_font = TTFont('./fonts/new.woff')
new_font.saveXML('./fonts/new_font.xml')
new_list = new_font.getGlyphOrder()[2:]
coordinate_list1 = []
for uniname1 in base_list:
# Get the horizontal and vertical coordinate information of the font object
coordinate = base_font['glyf'][uniname1].coordinates
coordinate_list1.append(list(coordinate))
coordinate_list2 = []
for uniname1 in base_list2:
# Get the horizontal and vertical coordinate information of the font object
coordinate = base_font2['glyf'][uniname1].coordinates
coordinate_list2.append(list(coordinate))
coordinate_list3 = []
for uniname1 in base_list3:
# Get the horizontal and vertical coordinate information of the font object
coordinate = base_font3['glyf'][uniname1].coordinates
coordinate_list3.append(list(coordinate))
coordinate_list4 = []
for uniname2 in new_list:
coordinate = new_font['glyf'][uniname2].coordinates
coordinate_list4.append(list(coordinate))
index2 = -1
new_dict = {}
for name2 in coordinate_list4:#dynamic
index2 += 1
result1 = ""
result2 = ""
result3 = ""
index1 = -1
max = -1;
for name1 in coordinate_list1: #local
index1 += 1
same = self.compare(name1, name2)
if same > max:
max = same
result1 = base_dict[base_list[index1]]
index1 = -1
max = -1;
for name1 in coordinate_list2: #local
index1 += 1
same = self.compare(name1, name2)
if same > max:
max = same
result2 = base_dict2[base_list2[index1]]
index1 = -1
max = -1;
for name1 in coordinate_list3: #local
index1 += 1
same = self.compare(name1, name2)
if same > max:
max = same
result3 = base_dict3[base_list3[index1]]
if result1 == result2:
new_dict[new_list[index2]] = result2
elif result1 == result3:
new_dict[new_list[index2]] = result3
elif result2 == result3:
new_dict[new_list[index2]] = result3
else:
new_dict[new_list[index2]] = result1
for i in new_list:
pattern = i.replace('uni', '&#x').lower() + ';'
res = res.replace(pattern, new_dict[i])
return res
"""
//Input: A list of coordinates for the fonts of two objects
#I'm "I want to be a Taoist". Other non-original
//Output Similarity
"""
def compare(self, c1, c2):
count = 0
length1 = len(c1)
length2 = len(c2)
if abs(length2-length1) > 7:
return -1
length = 0
if length1 > length2:
length = length2
else:
length = length1
#print(length)
for i in range(length):
if (abs(c1[i][0] - c2[i][0]) < 5 and abs(c1[i][1] - c2[i][1]) < 5):
count += 1
return count2. Meituan Anti-Crawling
There are also many blogs on the Internet about Meituan anti-crawling, but the content you should know is that you copy me, I copy you, and in the end it is almost the same.But there are still a lot of good blog posts to read.I have a limited level and limited reference, so I only give two types of actors that I've used and successfully crawled the data I need for 3000 movies and 900 actors.I use a combination of the two methods to crawl data, and I use normal requests to crawl and selenium automation tools (with mitm-proxy).The fastest is requests, but it is easy to detect; the most stable is selenium, which is not easy to detect.
1, normal requests
requests are still useful for cat-eye crawling, but it takes a long time to cool down after being detected by Mei Tuan. The exact time is unknown. I successfully crawled all the movie details using the cookie that I logged in to using request configuration.The reference code is as follows.Actually, the trouble is that xpath parses the source code of the web page.
class getFilmsData(object):
def __init__(self):
self.headers = {}
self.headers['User-Agent'] = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.06'
self.headers['Cookie'] = 'Fill in your cookie,If you don't know, leave a message and I'll tell you quickly'
self.dataManager = mongoManager()
self.fontDecode = FontDecode()
#Get data based on url,
#LimittItem is a restriction page, i.e. it has been fetched before its page item is completed
#I'm "I want to be a Taoist". Other non-original
def getData(self,url,limitItem):
s = requests.session()
s.headers = self.headers
s.keep_alive = False
content = s.get(url).text
#print("URLTEXT is :",response.text)
if "Verification Center" in content:
print("Directory Interface Meituan Verification")
return False
sel = etree.HTML(content)
count = 0
urls = sel.xpath('//div[@class="movie-item"]')
scores = sel.xpath('//div[@class="channel-detail channel-detail-orange"]')
for box in urls:
#Grab the movie url of the list interface
count += 1
if count < limitItem:
continue
print("begin ",count,"th item")
scoreCheck = scores[count-1].xpath('.//text()')[0]
#Movies without ratings do not crawl
if scoreCheck == "No score yet":
break
urlBack = box.xpath('.//a/@href')[0]
#Get movie details url
url = "https://maoyan.com"+urlBack
#Get movie name, duration, date of release, box office, rating, actor, poster url
resp = s.get(url)
realUrl = resp.url
res = resp.text
if "Verification Center" in res:
print("Information Interface Meituan Verification")
return False
#res2= self.replace_font(res)
selTmp = etree.HTML(res)
#box office
#I'm "I want to be a Taoist". Other non-original
money = selTmp.xpath('//div[@class="movie-index-content box"]/span[1]/text()')
unit = selTmp.xpath('//div[@class="movie-index-content box"]/span[2]/text()')
filmMoney = ""
if len(money) == 0:
#No box-office movies crawl
continue
else:
ascll = str(money[0])
#print("money ascll is:",ascll)
utfs = str(ascll.encode('unicode_escape'))[1:].replace("'","").replace("\\\\u",";&#x").split('.')
unicode = ""
if len(utfs)>1:
unicode = utfs[0][1:]+";."+utfs[1][1:]+";"
else:
unicode = utfs[0][1:]+";"
filmMoney = self.fontDecode.replace_font(res,unicode)
if len(unit) > 0:
filmMoney += unit[0]
#Movie Name
filmName = selTmp.xpath('//div[@class="movie-brief-container"]/h1[1]/text()')[0]
#Movie Poster
filmImage = selTmp.xpath('//div[@class="avatar-shadow"]/img[1]/@src')[0]
#Movie duration
filmTime = selTmp.xpath('//div[@class="movie-brief-container"]/ul[1]/li[2]/text()')[0].replace('\n', '').replace(' ', '')
#Movie show time
filmBegin = selTmp.xpath('//div[@class="movie-brief-container"]/ul[1]/li[3]/text()')[0].replace('\n', '')
#Movie Scoring
score = selTmp.xpath('//div[@class="movie-index-content score normal-score"]/span[1]/span[1]/text()')
#Because box office and score font encoding are encrypted, unicode is required before decrypting
#I'm "I want to be a Taoist". Other non-original
filmScore = ""
if len(score) == 0:
filmScore = "Score not available yet"
else:
ascll = str(score[0])
#print("score ascll is:",ascll)
utfs = str(ascll.encode('unicode_escape'))[1:].replace("'","").replace("\\\\u",";&#x").split('.')
unicode = ""
if len(utfs)>1:
unicode = utfs[0][1:]+";."+utfs[1][1:]+";"
else:
unicode = utfs[0][1:]+";"
filmScore = self.fontDecode.replace_font(res,unicode)+"branch"
print(filmMoney,filmScore)
#Get a movie cast, only the top 10 leading actors
actorSol = selTmp.xpath('//div[@class="tab-celebrity tab-content"]/div[@class="celebrity-container"]/div[@class="celebrity-group"][2]/ul/li')
#print(actors)
actors = []
actorUrls = []
num = len(actorSol)
for i in range(10):
num -= 1
if num < 0:
break
actorUrl = "https://maoyan.com"+actorSol[i].xpath('.//div[@class="info"]/a/@href')[0]
actorItem = actorSol[i].xpath('.//div[@class="info"]/a/text()')[0].replace('\n', '').replace(' ', '')
if len(actorSol[i].xpath('.//div[@class="info"]/span[1]/text()')) > 1:
actorItem += (" "+actorSol[i].xpath('.//div[@class="info"]/span[1]/text()')[0].replace('\n', '').replace(' ', ''))
actorUrls.append(actorUrl)
actors.append(actorItem)
#Get an introduction to the movie
introductionT = ""
introductionF = selTmp.xpath('//span[@class = "dra"]/text()')
if len(introductionF) > 0:
introductionT = introductionF[0]
print(count,filmName,filmImage,filmBegin,filmTime,filmScore,filmMoney,actors,introductionT)
time.sleep(1)
s.close()2, selenium with mitmproxy
The second method is selenium with mitmproxy, which is an automated tool. Unlike request to crawl web content, selenium can imitate a user opening a browser to browse a web page, and everything he sees can be crawled.This is also used when crawling large amounts of data to avoid detection.But if you just use selenium, it's still easy to detect, and I don't really understand it here, it's just use it.This is roughly the number of reply parameters set by the browser, which will be assigned if selenium is used, which are undefined if normal users browse, and there are other anti-selenium parameters that I don't understand further.
The specific configuration can refer to the blog I wrote before: mitmproxy with selenium
I find that when I crawl, this method is more stable than the first one. The probability of Meituan authentication is very low, and after that, copy the website web address to open manually in the corresponding browser, the verification will occur. You can try several times manually and then go on crawling.Of course, this is certainly not as fast as request.For example, I'm crawling At https://maoyan.com/films/celebrity/28936, Metro Detection appeared. I'm using Google's driver. Copy this web address into Google Browser. Usually, Metro Detection appears at this time. After your manual verification has passed (close the browser a few more times without passing), just continue crawling.In fact, selenium automatically uses the browser or is considered to be browsing by the web address. Only when detection occurs, selenium will be recognized by the web address, so we just need to think that it is over-detection.
That's how I want the source to trust me

