Multiple callees are virtualized into one callee when calling, which is Dubbo's clustering. This article will talk about how Dubbo clusters from an experience of hitting a wall.
(don't make complaints about virtualization. According to the broad definition we mentioned in our class, abstraction is to hide details [e.g. Devices > files with different interfaces). Virtualization is to hide the details of [e.g. physical devices > virtual devices with the same interface.
scene
I need to maintain their metadata for all invokers, so I added code to maintain it in LoadBalance. However, a strange thing is found that when the number of invokers is 1, LoadBalance doesn't happen.
Although these data are not needed now, what if an Invoker is added dynamically? There will be a problem. I want to make a callee cluster, OK? After all, clusters are essentially different from individual invokers, while clusters with size of 100 and clusters with size of 1 have only quantitative changes.
I hope the cluster with size 1 can still execute load balancing code, so I want to delete the boundary detection.
Service discovery source code analysis
Read the Dubbo framework source code. Dubbo has been optimized in the case of a single invoker.
public abstract class AbstractLoadBalance implements LoadBalance {
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (CollectionUtils.isEmpty(invokers)) {
return null;
} else {
return invokers.size() == 1 ? (Invoker)invokers.get(0) : this.doSelect(invokers, url, invocation);
}
}We overloaded the custom LoadBalance implementation, but the result was still not good
@Override
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (CollectionUtils.isEmpty(invokers)) {
return null;
} else {
return this.doSelect(invokers, url, invocation);
}
}Here we will talk about the principle of Dubbo service discovery. Directory corresponds to the list of services registered in zookeeper, Router filters services according to conditions, and LoadBalance selects services according to algorithms.
The Cluster here disguises a group of services as a service, that is, the Invoker is selected as the Invoker called by the Cluster according to the Directory, Router, LoadBalance and other rules defined above.
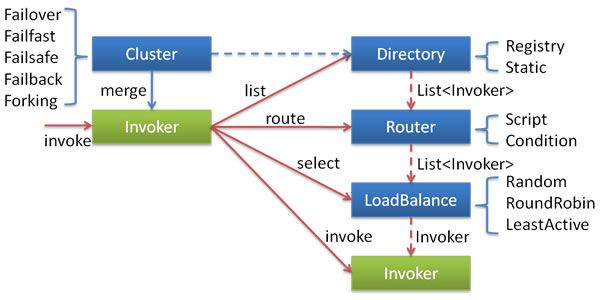
Cluster architecture
Let's take a look at how Cluster disguises itself as an Invoker through these rules. (omit irrelevant code)
Directory: filter invokers from Router Chain by URL
public abstract class AbstractDirectory<T> implements Directory<T> {
protected RouterChain<T> routerChain;
}
public class RegistryDirectory<T> extends AbstractDirectory<T> implements NotifyListener {
private void refreshInvoker(List<URL> invokerUrls) {
List<Invoker<T>> newInvokers = Collections.unmodifiableList(new ArrayList(newUrlInvokerMap.values()));
this.routerChain.setInvokers(newInvokers);
this.invokers = this.multiGroup ? this.toMergeInvokerList(newInvokers) : newInvokers;
this.urlInvokerMap = newUrlInvokerMap;
}
}RouterChain: filter each route in turn and get the intersection
public List<Invoker<T>> route(URL url, Invocation invocation) {
List<Invoker<T>> finalInvokers = this.invokers;
Router router;
for(Iterator var4 = this.routers.iterator(); var4.hasNext(); finalInvokers = router.route(finalInvokers, url, invocation)) {
router = (Router)var4.next();
}
return finalInvokers;
}Router: filter according to configuration items. If match, it will be added to the results
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException {
Iterator var5 = invokers.iterator();
while(var5.hasNext()) {
Invoker<T> invoker = (Invoker)var5.next();
if (this.matchThen(invoker.getUrl(), url)) {
result.add(invoker);
}Cluster: create a cluster Invoker according to the Directory, and obtain the invokers through the directory/router
public class FailoverCluster extends AbstractCluster {
public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException {
return new FailoverClusterInvoker(directory);
}ClusterInvoker: doinvoke - > select of abstractinvoker
public class FailoverClusterInvoker<T> extends AbstractClusterInvoker<T> {
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
Invoker<T> invoker = this.select(loadbalance, invocation, copyInvokers, invoked);
}
}AbstractInvoker: Select - > doselect - > select of loadbalance
public abstract class AbstractClusterInvoker<T> implements Invoker<T> {
protected Invoker<T> select(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
Invoker<T> invoker = this.doSelect(loadbalance, invocation, invokers, selected);
if (sticky) {
this.stickyInvoker = invoker;
}
}
private Invoker<T> doSelect(LoadBalance loadbalance, Invocation invocation, List<Invoker<T>> invokers, List<Invoker<T>> selected) throws RpcException {
if (CollectionUtils.isEmpty(invokers)) {
return null;
} else if (invokers.size() == 1) {
return (Invoker)invokers.get(0);
} else {
Invoker<T> invoker = loadbalance.select(invokers, this.getUrl(), invocation);It can be seen that the key lies in the doSelect step of AbstractInvoker, which directly skips the cluster of single services. We need to rewrite Abstract invoker. Dubbo is open source. If we directly fork the source code, this step is easy. The problem is that these are read-only in maven project.
However, after hard rewriting here, the reality is still cruel, and I can only go back.
Referenceconfig: createproxy - > doJoin of cluster
After the avatar demon, I continue to see where there is boundary detection. The answer is in the reference setting. At the beginning, there was only one URL, so there was no cluster.
public class ReferenceConfig<T> extends ReferenceConfigBase<T> {
@SuppressWarnings({"unchecked", "rawtypes", "deprecation"})
private T createProxy(Map<String, String> map) {
if (urls.size() == 1) {
invoker = REF_PROTOCOL.refer(interfaceClass, urls.get(0));
}
else {
List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();
URL registryURL = null;
for (URL url : urls) {
invokers.add(REF_PROTOCOL.refer(interfaceClass, url));
if (UrlUtils.isRegistry(url)) {
registryURL = url; // use last registry url
}
}
if (registryURL != null) { // registry url is available
// for multi-subscription scenario, use 'zone-aware' policy by default
String cluster = registryURL.getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME);
// The invoker wrap sequence would be: ZoneAwareClusterInvoker(StaticDirectory) -> FailoverClusterInvoker(RegistryDirectory, routing happens here) -> Invoker
invoker = Cluster.getCluster(cluster, false).join(new StaticDirectory(registryURL, invokers));
}WDNMD!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
I choose to die. I won't go this way. I announce that the cluster nodes that need to maintain data should not be less than 2.
I can't change the source code of maven project. I'm so angry. Is this the pain of the framework.
summary
Dubbo's clustering is divided into these steps
Preparation phase (doJoin)
- Listen to the URL of the registry and create invokers. If the number of URLs is greater than 1, all invokers will be clustered
- According to the URL directory, the cluster filters the invokers in turn according to the routing rules until the invokers that meet the rules are selected
- Return the virtualized Invoker, interface with the single Invoker, and encapsulate the cluster fault tolerance details.
Call phase (doInvoke)
- The invoker that meets the routing rules selects the corresponding invoker according to the load balancing
- The selected invoker makes multiple calls according to the cluster fault tolerance policy, collects the results and returns them
The difference from individual invokers is that when the cluster is fault-tolerant, you can select different invokers and actually call them multiple times. You can even broadcast, collect the results of all invokers and return Qurom.