Links to the original text: https://mp.weixin.qq.com/s/oY...
This is a companion article to analyze how Go implements protobuf encoding and decoding:
- How to Realize the Coding and Decoding of protobuf by Go (1): Principle
- How Go implements protobuf encoding and decoding (2): source code
This edition is the second one.
Preface
Last article How to Realize the Coding and Decoding of protobuf by Go (1): Principle
It has been pointed out that the encoding and decoding of Go language data and Protobuf data is accomplished by the package github.com/golang/protobuf/proto. This code will analyze how proto package realizes encoding and decoding.

Coding and Decoding Principle
Coding and decoding packages all have supported coding and decoding types. Let's call these types the underlying types for the time being. The essence of coding and decoding is:
- Equipped with one or more codec functions for each underlying type
- The field of a structure is recursively disassembled into the underlying type, and then the appropriate function is selected for encoding or decoding operations.
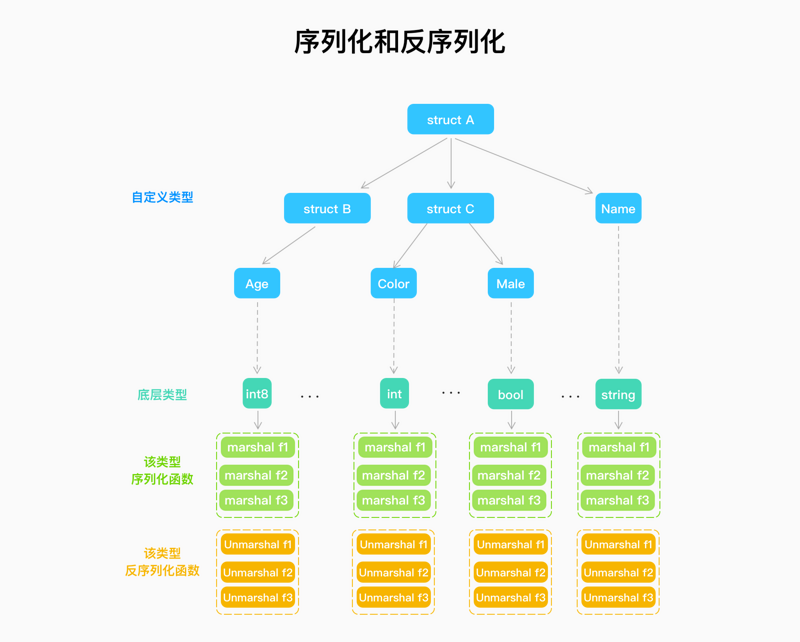
Next, look at the encoding, then at the decoding.
Code
Convention: All of the following code snippets, if they are in request.pb.go or main.go, will mark the file name on the first line, otherwise they are the source code of the proto package.
// main.go package main import ( "fmt" "./types" "github.com/golang/protobuf/proto" ) func main() { req := &types.Request{Data: "Hello Dabin"} // Marshal encoded, err := proto.Marshal(req) if err != nil { fmt.Printf("Encode to protobuf data error: %v", err) } ... }
The encoding calls the proto.Marshal function, which can serialize the Go language data into protobuf data and return serialization results or errors.
The Go structure compiled by proto conforms to the Message interface. Marshal shows that there are three ways to serialize the Go structure:
- When pb Message satisfies the newMarshaler interface, it calls XXX_Marshal() for serialization.
- If pb satisfies the Marshaler interface, it calls Marshal() for serialization, which is suitable for a certain type of custom serialization rules.
- Otherwise, use the default serialization method to create a Warpper, and use wrapper to serialize pb, which will be introduced later. Mode 1 is actually mode 3.
// Marshal takes a protocol buffer message // and encodes it into the wire format, returning the data. // This is the main entry point. func Marshal(pb Message) ([]byte, error) { if m, ok := pb.(newMarshaler); ok { siz := m.XXX_Size() b := make([]byte, 0, siz) return m.XXX_Marshal(b, false) } if m, ok := pb.(Marshaler); ok { // If the message can marshal itself, let it do it, for compatibility. // NOTE: This is not efficient. return m.Marshal() } // in case somehow we didn't generate the wrapper if pb == nil { return nil, ErrNil } var info InternalMessageInfo siz := info.Size(pb) b := make([]byte, 0, siz) return info.Marshal(b, pb, false) }
New Marshaler and Marshaler are as follows:
// newMarshaler is the interface representing objects that can marshal themselves. // // This exists to support protoc-gen-go generated messages. // The proto package will stop type-asserting to this interface in the future. // // DO NOT DEPEND ON THIS. type newMarshaler interface { XXX_Size() int XXX_Marshal(b []byte, deterministic bool) ([]byte, error) } // Marshaler is the interface representing objects that can marshal themselves. type Marshaler interface { Marshal() ([]byte, error) }
Request implements the new Marshaler interface. XXX_Marshal implements the following. It actually calls xxx_messageInfo_Request.Marshal. xxx_messageInfo_Request is a global variable defined in request.pb.go. The type is International MessageInfo, which is actually the wrapper mentioned earlier.
// request.pb.go func (m *Request) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) { print("Called xxx marshal\n") panic("I want see stack trace") return xxx_messageInfo_Request.Marshal(b, m, deterministic) } var xxx_messageInfo_Request proto.InternalMessageInfo
In essence, XXX_Marshal is also wrapper, followed by a truly serialized body function in the proto package.
Internal MessageInfo is mainly used to cache information needed for serialization and deserialization.
// InternalMessageInfo is a type used internally by generated .pb.go files. // This type is not intended to be used by non-generated code. // This type is not subject to any compatibility guarantee. type InternalMessageInfo struct { marshal *marshalInfo // marshal information unmarshal *unmarshalInfo // unmarshal information merge *mergeInfo discard *discardInfo }
InternalMessageInfo.Marshal first acquires the serialization information u marshalInfo of the type to be serialized, and then uses u.marshal to serialize.
// Marshal is the entry point from generated code, // and should be ONLY called by generated code. // It marshals msg to the end of b. // a is a pointer to a place to store cached marshal info. func (a *InternalMessageInfo) Marshal(b []byte, msg Message, deterministic bool) ([]byte, error) { // Get the MarshalInfo of this message type, and the information is cached. // There is no need to recreate large amounts of concurrency u := getMessageMarshalInfo(msg, a) // Entry Check ptr := toPointer(&msg) if ptr.isNil() { // We get here if msg is a typed nil ((*SomeMessage)(nil)), // so it satisfies the interface, and msg == nil wouldn't // catch it. We don't want crash in this case. return b, ErrNil } // marshal the data according to marshal Info return u.marshal(b, ptr, deterministic) }
Because each type of serialization information is consistent, getMessage MarshalInfo caches the serialization information and caches it in a.marshal. If there is no Marshal information in a, it generates it, but does not initialize it, and then saves it in a.
func getMessageMarshalInfo(msg interface{}, a *InternalMessageInfo) *marshalInfo { // u := a.marshal, but atomically. // We use an atomic here to ensure memory consistency. // Read from Internal MessageInfo u := atomicLoadMarshalInfo(&a.marshal) // Unread represents not saved if u == nil { // Get marshal information from type of message. t := reflect.ValueOf(msg).Type() if t.Kind() != reflect.Ptr { panic(fmt.Sprintf("cannot handle non-pointer message type %v", t)) } u = getMarshalInfo(t.Elem()) // Store it in the cache for later users. // a.marshal = u, but atomically. atomicStoreMarshalInfo(&a.marshal, u) } return u }
getMarshalInfo simply creates a marshalInfo object, filling in the field typ e, and the remaining fields are not filled.
// getMarshalInfo returns the information to marshal a given type of message. // The info it returns may not necessarily initialized. // t is the type of the message (NOT the pointer to it). // Get the MarshalInfo structure and, if not, create one using the message type t func getMarshalInfo(t reflect.Type) *marshalInfo { marshalInfoLock.Lock() u, ok := marshalInfoMap[t] if !ok { u = &marshalInfo{typ: t} marshalInfoMap[t] = u } marshalInfoLock.Unlock() return u } // marshalInfo is the information used for marshaling a message. type marshalInfo struct { typ reflect.Type fields []*marshalFieldInfo unrecognized field // offset of XXX_unrecognized extensions field // offset of XXX_InternalExtensions v1extensions field // offset of XXX_extensions sizecache field // offset of XXX_sizecache initialized int32 // 0 -- only typ is set, 1 -- fully initialized messageset bool // uses message set wire format hasmarshaler bool // has custom marshaler sync.RWMutex // protect extElems map, also for initialization extElems map[int32]*marshalElemInfo // info of extension elements }
marshalInfo.marshal is the real body of Marshal. It determines whether u has been initialized. If computeMarshalInfo is not called to calculate the information needed by Marshal, it is actually filling in various fields in marshalInfo.
u.hasmarshaler represents whether the current type implements the Marshaler interface and directly calls the Marshal function for serialization. We can determine the serialization mode 2 of Marshal function, that is, the method of implementing Marshaler interface, and finally we will definitely call marshalInfo.marshal.
The main body of the function is a for loop, which traverses each field of the type in turn, checks the required attribute, and then calls f.marshaler to serialize the field type according to the field type. Where did this f.marshaler come from?
// marshal is the main function to marshal a message. It takes a byte slice and appends // the encoded data to the end of the slice, returns the slice and error (if any). // ptr is the pointer to the message. // If deterministic is true, map is marshaled in deterministic order. // This function is Marshal's main function. After encoding the message as data, it is appended to b and returned to b. // deterministic represents map for true, which is encoded in a determined order. func (u *marshalInfo) marshal(b []byte, ptr pointer, deterministic bool) ([]byte, error) { // Initialize basic information for marshalInfo // Fill in some fields of the structure based on existing information. if atomic.LoadInt32(&u.initialized) == 0 { u.computeMarshalInfo() } // If the message can marshal itself, let it do it, for compatibility. // NOTE: This is not efficient. // If this type implements the Marshaler interface, that is, to be able to own Marshal, then to own Marshal // The result is appended to b if u.hasmarshaler { m := ptr.asPointerTo(u.typ).Interface().(Marshaler) b1, err := m.Marshal() b = append(b, b1...) return b, err } var err, errLater error // The old marshaler encodes extensions at beginning. // Check the extension field and append the extension field of message to b if u.extensions.IsValid() { // Offset function is used to get the specified field of message according to pointer offset e := ptr.offset(u.extensions).toExtensions() if u.messageset { b, err = u.appendMessageSet(b, e, deterministic) } else { b, err = u.appendExtensions(b, e, deterministic) } if err != nil { return b, err } } if u.v1extensions.IsValid() { m := *ptr.offset(u.v1extensions).toOldExtensions() b, err = u.appendV1Extensions(b, m, deterministic) if err != nil { return b, err } } // Traverse each field of message, check and code it, and then append it to b for _, f := range u.fields { if f.required { // If the required field is not set, the error is recorded and all marshal work is processed after completion. if ptr.offset(f.field).getPointer().isNil() { // Required field is not set. // We record the error but keep going, to give a complete marshaling. if errLater == nil { errLater = &RequiredNotSetError{f.name} } continue } } // The field is pointer type and nil, which means it is not set. The field does not need to be coded. if f.isPointer && ptr.offset(f.field).getPointer().isNil() { // nil pointer always marshals to nothing continue } // Encoding with marshaler of this field b, err = f.marshaler(b, ptr.offset(f.field), f.wiretag, deterministic) if err != nil { if err1, ok := err.(*RequiredNotSetError); ok { // required field but no error set // Required field in submessage is not set. // We record the error but keep going, to give a complete marshaling. if errLater == nil { errLater = &RequiredNotSetError{f.name + "." + err1.field} } continue } // "Dynamic Array" contains nil elements if err == errRepeatedHasNil { err = errors.New("proto: repeated field " + f.name + " has nil element") } if err == errInvalidUTF8 { if errLater == nil { fullName := revProtoTypes[reflect.PtrTo(u.typ)] + "." + f.name errLater = &invalidUTF8Error{fullName} } continue } return b, err } } // To identify the type field, convert directly to bytes and append to b // These fields have been collected in computeMarshalInfo if u.unrecognized.IsValid() { s := *ptr.offset(u.unrecognized).toBytes() b = append(b, s...) } return b, errLater }
computeMarshalInfo is actually a comprehensive check of the type to be serialized, setting up the data to be used for serialization, which includes the serialization function f.marshaler for each field. Let's focus on this part. Each field of struct is assigned a marshalFieldInfo, which represents the information needed for the field serialization and fills the object by calling computeMarshalFieldInfo.
// computeMarshalInfo initializes the marshal info. func (u *marshalInfo) computeMarshalInfo() { // Locking represents the inability to compute marshal information at the same time u.Lock() defer u.Unlock() // Calculate once. if u.initialized != 0 { // non-atomic read is ok as it is protected by the lock return } // Get the message type for marshal t := u.typ u.unrecognized = invalidField u.extensions = invalidField u.v1extensions = invalidField u.sizecache = invalidField // If the message can marshal itself, let it do it, for compatibility. // Determine whether the current type implements the Marshal interface, if the implementation is marked as type-owned marshaler // The useless type assertion is because t is a Type type, not a variable stored in an interface. // NOTE: This is not efficient. if reflect.PtrTo(t).Implements(marshalerType) { u.hasmarshaler = true atomic.StoreInt32(&u.initialized, 1) // You can go back directly and use your own marshaler encoding later return } // get oneof implementers // See * t implements which of the following interfaces, the oneof feature var oneofImplementers []interface{} switch m := reflect.Zero(reflect.PtrTo(t)).Interface().(type) { case oneofFuncsIface: _, _, _, oneofImplementers = m.XXX_OneofFuncs() case oneofWrappersIface: oneofImplementers = m.XXX_OneofWrappers() } n := t.NumField() // deal with XXX fields first // Traversing through every XXX field of t for i := 0; i < t.NumField(); i++ { f := t.Field(i) // Skip fields that are not at the beginning of XXX if !strings.HasPrefix(f.Name, "XXX_") { continue } // Processing the following protobuf fields switch f.Name { case "XXX_sizecache": u.sizecache = toField(&f) case "XXX_unrecognized": u.unrecognized = toField(&f) case "XXX_InternalExtensions": u.extensions = toField(&f) u.messageset = f.Tag.Get("protobuf_messageset") == "1" case "XXX_extensions": u.v1extensions = toField(&f) case "XXX_NoUnkeyedLiteral": // nothing to do default: panic("unknown XXX field: " + f.Name) } n-- } // normal fields // Processing common fields of message fields := make([]marshalFieldInfo, n) // batch allocation u.fields = make([]*marshalFieldInfo, 0, n) for i, j := 0, 0; i < t.NumField(); i++ { f := t.Field(i) // Skip the XXX field if strings.HasPrefix(f.Name, "XXX_") { continue } // Take the next valid field of fields, pointer type // j represents the number of valid fields for fields, and n is the total number of fields that contain XXX fields. field := &fields[j] j++ field.name = f.Name // Fill in u.fields u.fields = append(u.fields, field) // The tag of the field contains "protobuf_oneof" special processing if f.Tag.Get("protobuf_oneof") != "" { field.computeOneofFieldInfo(&f, oneofImplementers) continue } // The field does not contain "protobuf" to represent fields that are not automatically generated by protoc. if f.Tag.Get("protobuf") == "" { // field has no tag (not in generated message), ignore it // Delete the field information just saved u.fields = u.fields[:len(u.fields)-1] j-- continue } // Fill in marshal information for fields field.computeMarshalFieldInfo(&f) } // fields are marshaled in tag order on the wire. // field order sort.Sort(byTag(u.fields)) // Initialization complete atomic.StoreInt32(&u.initialized, 1) }
Looking back at the definition of Request, it contains a field called Data, followed by protobuf:... describing the information that protobuf will use, "bytes,..." which is called tags, after splitting with commas, in which:
- tags[0]: bytes, Data representing Data type to be converted to bytes
- tags[1]: 1, which represents the ID of the field
- tags[2]: opt, which means feasible, not necessary
- tags[3]: name=data, the name in the proto file
- tags[4]: proto3, representing the protobuf version used
// request.pb.go type Request struct{ Data string `protobuf:"bytes,1,opt,name=data,proto3" json:"data,omitempty"` ... }
computeMarshalFieldInfo first gets the field ID and the type to be converted, fills in the marshalFieldInfo, and then calls setMarshaler to obtain the serialization function of the field type using field f and tags.
// computeMarshalFieldInfo fills up the information to marshal a field. func (fi *marshalFieldInfo) computeMarshalFieldInfo(f *reflect.StructField) { // parse protobuf tag of the field. // tag has format of "bytes,49,opt,name=foo,def=hello!" // Get the complete tag of "protobuf" and then use, divide, and get the format above. tags := strings.Split(f.Tag.Get("protobuf"), ",") if tags[0] == "" { return } // The number of tag, string name = x set in message, is the tag id of this field. tag, err := strconv.Atoi(tags[1]) if err != nil { panic("tag is not an integer") } // Types to be converted, bytes, variables, and so on wt := wiretype(tags[0]) // Set whether the field is required or opt if tags[2] == "req" { fi.required = true } // Set field and tag information to Marshal Field Info fi.setTag(f, tag, wt) // Select the marshaler function based on the current tag information (type, etc.). fi.setMarshaler(f, tags) }
The focus of setMarshaler is typeMarshaler, which is a very long function. In fact, it is a serialized function that returns to a pair according to type settings, such as Bool, Int32, Uint32, etc. If it is a composite type of structure, slice, etc., it can form recursion.
// setMarshaler fills up the sizer and marshaler in the info of a field. func (fi *marshalFieldInfo) setMarshaler(f *reflect.StructField, tags []string) { // Special Processing of map Type Fields switch f.Type.Kind() { case reflect.Map: // map field fi.isPointer = true fi.sizer, fi.marshaler = makeMapMarshaler(f) return case reflect.Ptr, reflect.Slice: // Pointer field and slice field mark pointer type fi.isPointer = true } // Select marshaler based on field type and tag fi.sizer, fi.marshaler = typeMarshaler(f.Type, tags, true, false) } // typeMarshaler returns the sizer and marshaler of a given field. // t is the type of the field. // tags is the generated "protobuf" tag of the field. // If nozero is true, zero value is not marshaled to the wire. // If oneof is true, it is a oneof field. // Functions are very long and omitted func typeMarshaler(t reflect.Type, tags []string, nozero, oneof bool) (sizer, marshaler) { ... switch t.Kind() { case reflect.Bool: if pointer { return sizeBoolPtr, appendBoolPtr } if slice { if packed { return sizeBoolPackedSlice, appendBoolPackedSlice } return sizeBoolSlice, appendBoolSlice } if nozero { return sizeBoolValueNoZero, appendBoolValueNoZero } return sizeBoolValue, appendBoolValue case reflect.Uint32: ... case reflect.Int32: .... case reflect.Struct: ... }
Following are two examples of serialization functions of Bool and String types:
func appendBoolValue(b []byte, ptr pointer, wiretag uint64, _ bool) ([]byte, error) { v := *ptr.toBool() b = appendVarint(b, wiretag) if v { b = append(b, 1) } else { b = append(b, 0) } return b, nil }
func appendStringValue(b []byte, ptr pointer, wiretag uint64, _ bool) ([]byte, error) { v := *ptr.toString() b = appendVarint(b, wiretag) b = appendVarint(b, uint64(len(v))) b = append(b, v...) return b, nil }
So the serialized [] byte should conform to this pattern:
| wiretag | data | wiretag | data | ... | data |
OK, the above is the main process of coding, a brief review:
- Proto. Marshall calls the automatically generated Wrapper function in *. pb.go, and the Wrapper function calls InternalMessageInfo for serialization before stepping into the serialization topic.
- First, get the marshal information u of the type to be serialized. If u is not initialized, initialize it. That is, set up the serialization function of each field of the structure, and other information.
- Traversing through each field of the structure, encoding each field with the information in u, and appending the addition to [] byte, so when the field encoding is completed, the result of serialization [] byte or error is returned.
Decode
The process of decoding is very similar to encoding. It will be the three main steps reviewed above. The main difference is in step 2. It acquires unmarshal information u of serialization type. If u is not initialized, it will be initialized. It sets the deserialization function of each field of the structure and other information.
So the decoded function parsing will go through briefly, no longer as detailed as the coding explanation.
The following are the interface and function definitions for deserialization in the proto package:
// Unmarshaler is the interface representing objects that can // unmarshal themselves. The argument points to data that may be // overwritten, so implementations should not keep references to the // buffer. // Unmarshal implementations should not clear the receiver. // Any unmarshaled data should be merged into the receiver. // Callers of Unmarshal that do not want to retain existing data // should Reset the receiver before calling Unmarshal. type Unmarshaler interface { Unmarshal([]byte) error } // newUnmarshaler is the interface representing objects that can // unmarshal themselves. The semantics are identical to Unmarshaler. // // This exists to support protoc-gen-go generated messages. // The proto package will stop type-asserting to this interface in the future. // // DO NOT DEPEND ON THIS. type newUnmarshaler interface { // Implementation of XXX_Unmarshal XXX_Unmarshal([]byte) error } // Unmarshal parses the protocol buffer representation in buf and places the // decoded result in pb. If the struct underlying pb does not match // the data in buf, the results can be unpredictable. // // Unmarshal resets pb before starting to unmarshal, so any // existing data in pb is always removed. Use UnmarshalMerge // to preserve and append to existing data. func Unmarshal(buf []byte, pb Message) error { pb.Reset() // pb has its own unmarshal function and implements the new Unmarshaler interface if u, ok := pb.(newUnmarshaler); ok { return u.XXX_Unmarshal(buf) } // pb has its own unmarshal function and implements the Unmarshaler interface if u, ok := pb.(Unmarshaler); ok { return u.Unmarshal(buf) } // Use the default Unmarshal return NewBuffer(buf).Unmarshal(pb) }
Request implements the Unmarshaler interface:
// request.pb.go func (m *Request) XXX_Unmarshal(b []byte) error { return xxx_messageInfo_Request.Unmarshal(m, b) }
Deserialization is also done using Internal MessageInfo.
// Unmarshal is the entry point from the generated .pb.go files. // This function is not intended to be used by non-generated code. // This function is not subject to any compatibility guarantee. // msg contains a pointer to a protocol buffer struct. // b is the data to be unmarshaled into the protocol buffer. // a is a pointer to a place to store cached unmarshal information. func (a *InternalMessageInfo) Unmarshal(msg Message, b []byte) error { // Load the unmarshal information for this message type. // The atomic load ensures memory consistency. // Get unmarshal information stored in a u := atomicLoadUnmarshalInfo(&a.unmarshal) if u == nil { // Slow path: find unmarshal info for msg, update a with it. u = getUnmarshalInfo(reflect.TypeOf(msg).Elem()) atomicStoreUnmarshalInfo(&a.unmarshal, u) } // Then do the unmarshaling. // Execute unmarshal err := u.unmarshal(toPointer(&msg), b) return err }
The following is the deserialized topic function, which calls computeUnmarshalInfo when u is not initialized to set the information needed for deserialization.
// unmarshal does the main work of unmarshaling a message. // u provides type information used to unmarshal the message. // m is a pointer to a protocol buffer message. // b is a byte stream to unmarshal into m. // This is top routine used when recursively unmarshaling submessages. func (u *unmarshalInfo) unmarshal(m pointer, b []byte) error { if atomic.LoadInt32(&u.initialized) == 0 { // Fill in the unmarshal information for u and set the unmarshaler function for each field type u.computeUnmarshalInfo() } if u.isMessageSet { return unmarshalMessageSet(b, m.offset(u.extensions).toExtensions()) } var reqMask uint64 // bitmask of required fields we've seen. var errLater error for len(b) > 0 { // Read tag and wire type. // Special case 1 and 2 byte varints. var x uint64 if b[0] < 128 { x = uint64(b[0]) b = b[1:] } else if len(b) >= 2 && b[1] < 128 { x = uint64(b[0]&0x7f) + uint64(b[1])<<7 b = b[2:] } else { var n int x, n = decodeVarint(b) if n == 0 { return io.ErrUnexpectedEOF } b = b[n:] } // Get tag and wire Tags tag := x >> 3 wire := int(x) & 7 // Dispatch on the tag to one of the unmarshal* functions below. // Select this type of unmarshal Field Info:f according to tag var f unmarshalFieldInfo if tag < uint64(len(u.dense)) { f = u.dense[tag] } else { f = u.sparse[tag] } // If the type has an unmarshaler function, decoding and error handling are performed if fn := f.unmarshal; fn != nil { var err error // Parse from b and fill in the corresponding fields of f b, err = fn(b, m.offset(f.field), wire) if err == nil { reqMask |= f.reqMask continue } if r, ok := err.(*RequiredNotSetError); ok { // Remember this error, but keep parsing. We need to produce // a full parse even if a required field is missing. if errLater == nil { errLater = r } reqMask |= f.reqMask continue } if err != errInternalBadWireType { if err == errInvalidUTF8 { if errLater == nil { fullName := revProtoTypes[reflect.PtrTo(u.typ)] + "." + f.name errLater = &invalidUTF8Error{fullName} } continue } return err } // Fragments with bad wire type are treated as unknown fields. } // Unknown tag. // Skip unknown tag s, maybe the message definition in proto has been upgraded and some fields have been added. If you use the old version, you will not recognize new fields. if !u.unrecognized.IsValid() { // Don't keep unrecognized data; just skip it. var err error b, err = skipField(b, wire) if err != nil { return err } continue } // Check if the unrecognized field is extension // Keep unrecognized data around. // maybe in extensions, maybe in the unrecognized field. z := m.offset(u.unrecognized).toBytes() var emap map[int32]Extension var e Extension for _, r := range u.extensionRanges { if uint64(r.Start) <= tag && tag <= uint64(r.End) { if u.extensions.IsValid() { mp := m.offset(u.extensions).toExtensions() emap = mp.extensionsWrite() e = emap[int32(tag)] z = &e.enc break } if u.oldExtensions.IsValid() { p := m.offset(u.oldExtensions).toOldExtensions() emap = *p if emap == nil { emap = map[int32]Extension{} *p = emap } e = emap[int32(tag)] z = &e.enc break } panic("no extensions field available") } } // Use wire type to skip data. var err error b0 := b b, err = skipField(b, wire) if err != nil { return err } *z = encodeVarint(*z, tag<<3|uint64(wire)) *z = append(*z, b0[:len(b0)-len(b)]...) if emap != nil { emap[int32(tag)] = e } } // Check the number of required fields parsed and report an error if they do not match the record in u if reqMask != u.reqMask && errLater == nil { // A required field of this message is missing. for _, n := range u.reqFields { if reqMask&1 == 0 { errLater = &RequiredNotSetError{n} } reqMask >>= 1 } } return errLater }
The process of setting the field deserialization function is ignored. Let's see how to choose the function. TypeeUnmarshaler is the field type, and it chooses the deserialized function. These functions are one-to-one correspondence with the serialized function.
// typeUnmarshaler returns an unmarshaler for the given field type / field tag pair. func typeUnmarshaler(t reflect.Type, tags string) unmarshaler { ... // Figure out packaging (pointer, slice, or both) slice := false pointer := false if t.Kind() == reflect.Slice && t.Elem().Kind() != reflect.Uint8 { slice = true t = t.Elem() } if t.Kind() == reflect.Ptr { pointer = true t = t.Elem() } ... switch t.Kind() { case reflect.Bool: if pointer { return unmarshalBoolPtr } if slice { return unmarshalBoolSlice } return unmarshalBoolValue } }
Unmarshal BoolValue is the default Bool type deserialization function, which decodes the protobuf data b, converts it to bool type v, and assigns the value to field f.
func unmarshalBoolValue(b []byte, f pointer, w int) ([]byte, error) { if w != WireVarint { return b, errInternalBadWireType } // Note: any length varint is allowed, even though any sane // encoder will use one byte. // See https://github.com/golang/protobuf/issues/76 x, n := decodeVarint(b) if n == 0 { return nil, io.ErrUnexpectedEOF } // TODO: check if x>1? Tests seem to indicate no. // toBool is a pointer that returns bool type // Complete assignment of field f v := x != 0 *f.toBool() = v return b[n:], nil }
summary
This paper analyses the process of serialization and deserialization of protobuf data in Go language, which can be summarized as follows:
- proto.Marshal and proto.Unmarshal call the Wrapper function automatically generated in *. pb.go, and the Wrapper function calls InternalMessageInfo for (de) serialization before stepping into (de) serialization.
- First, get the (um)marshal information u of the target type. If u is not initialized, initialize it. That is, set up the (de) serialization function of each field of the structure, and other information.
- Traversing through each field of the structure, encoding each field with the information in u, generating serialized results, or decoding, assigning values to the members of the structure
Reference Articles
The following reference articles are worth reading:
-
https://tech.meituan.com/2015...
"Serialization and Deserialization" is from the technical team of the United States Mission, which is worth reading. -
https://github.com/golang/pro...
Go supports protocol buffer warehouse, Readme, which is worth reading in detail. -
https://developers.google.com...
The Google language tutorial of Google Protocol Buffers is worth reading and practicing in detail. -
https://developers.google.com...
Overview of Google Protocol Buffers introduces what Protocol Buffers are, its principle, history (origin), and its comparison with XML, which is compulsory. -
https://developers.google.com...
Language Guide (proto3) this article introduces the definition of proto3, can also be understood as. proto file grammar, just like the grammar of Go language, do not know how to write. proto file grammar? Read this article will understand many principles, and you can step on the pit less, must read. -
https://developers.google.com...
This article "Go Generated Code" describes in detail how protoc uses. protoc to generate. pb.go, optional. -
https://developers.google.com...
Protocol Buffers Encoding introduces coding principles, optional. -
https://godoc.org/github.com/...
"package proto Document" can regard proto package as SDK for GoLanguage to operate protobuf data. It realizes the conversion of structure and protobuf data. It is used in conjunction with. pb.go file.