|Foreword
To read this article, you need to have the following knowledge base
- Java memory model, visibility issues
- CAS
- HashMap underlying principle
We know that the HashMap used in daily development is thread unsafe, and the thread safe HashTable class simply locks the method to achieve thread safety, which is inefficient. Therefore, we usually use ConcurrentHashMap in a thread safe environment, but why do we need to learn ConcurrentHashMap? Is it over? I think learning its source code has two advantages:
- More flexible use of ConcurrentHashMap
- Appreciate the works of concurrent programming master Doug Lea. There are many concurrent ideas worth learning in the source code. We should realize that thread safety is not just locking
I ask the following questions:
- How does ConcurrentHashMap achieve thread safety?
- How does the get method get the key and value thread safely?
- How does the put method thread safely set key and value?
- size method if the thread safely obtains the container capacity?
- How to ensure thread safety when the underlying data structure is expanded?
- How to ensure thread safety when initializing data structures?
- How to improve the concurrency efficiency of ConcurrentHashMap?
- Compared with phase locking, why is it more efficient than HashTable?
Next, let's continue with the questions and enjoy the wonderful concurrent art works of the concurrent master (the following discussion is based on JDK1.8)
|Related concepts
Amdahl's law
The description of the laws in this section comes from the book "practice of Java Concurrent Programming"
Assuming that F is the part that must be executed serially, N represents the number of processors and Speedup represents the acceleration ratio, which can be simply understood as CPU utilization
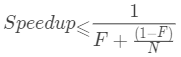
This formula tells us that when N approaches infinity, the maximum acceleration ratio approaches 1/F. assuming that 50% of our program needs serial execution, even if the number of processors is infinite, the maximum acceleration ratio can only be 2 (20% utilization). If only 10% of the program needs serial execution, the maximum acceleration ratio can reach 9.2 (92% utilization), However, our program must have a serial execution part more or less, so f cannot be 0. Therefore, even if there are an infinite number of CPU s, the acceleration ratio cannot reach 10 (100% utilization). The following figure shows the impact of different proportion of serial execution part on utilization:
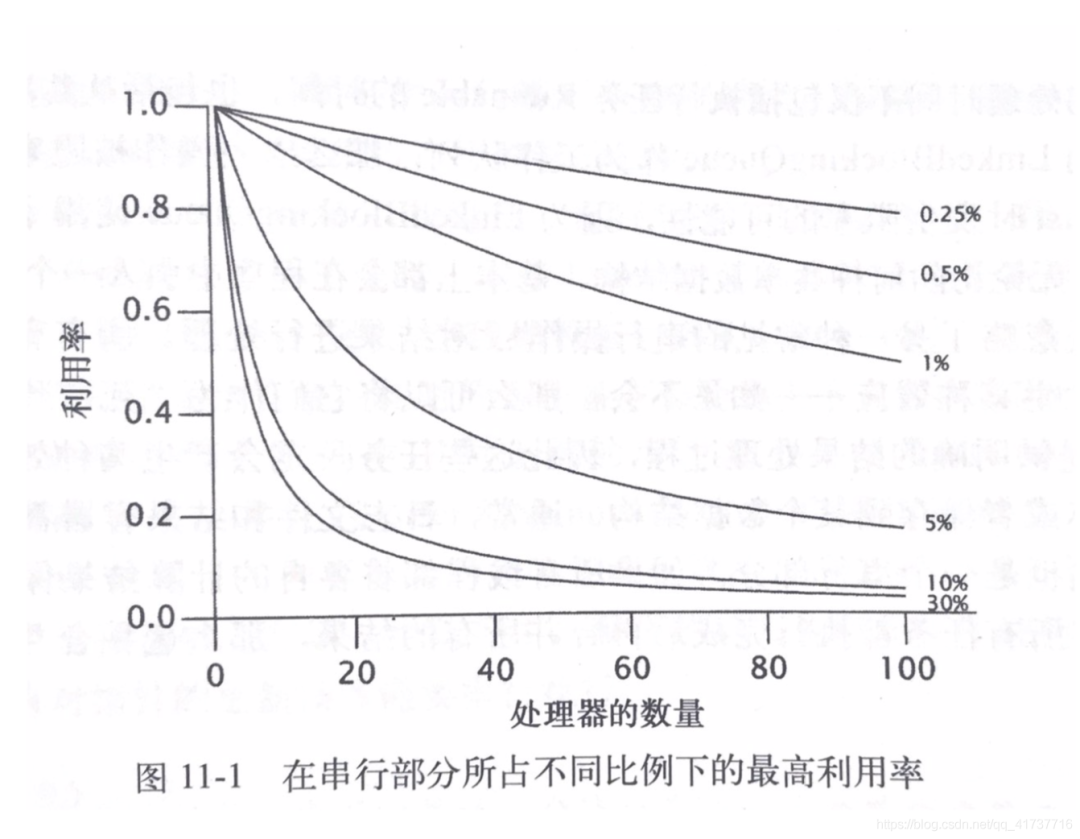
From this, we can see that the scalability in the program (the ratio of increasing the concurrent performance by increasing the external resources) is affected by the serial execution part of the program, and the common serial execution includes lock competition (context switching consumption, waiting, serial) and so on, which gives us an inspiration. We can optimize the concurrent performance by reducing lock competition, Concurrent HashMap uses lock segmentation (reducing lock range), CAS (optimistic lock, reducing context switching overhead, no blocking) and other technologies. Let's take a specific look
|Thread safety when initializing data structures
The underlying data structure of HashMap is briefly described here, and will not be described too much:
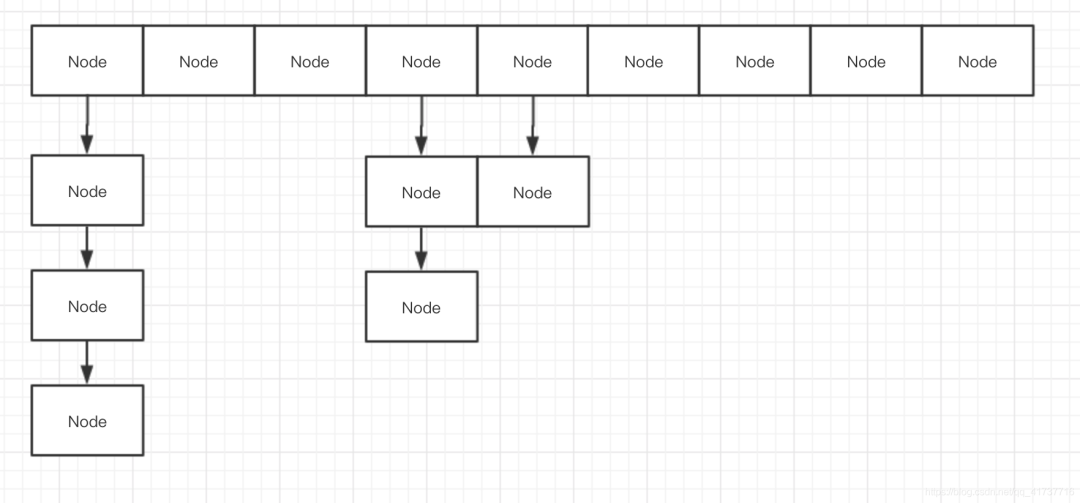
A node object array is roughly used to store data. In case of Hash conflict, a node linked list will be formed. When the length of the linked list exceeds 8 and the node array exceeds 64, the linked list structure will be converted into a red black tree. Node objects:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
}
It is worth noting that the value and next pointers use volatile to ensure their visibility.
In JDK1.8, when initializing ConcurrentHashMap, the Node [] array has not been initialized. It will not be initialized until the first put method call:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//Judge that the Node array is empty
if (tab == null || (n = tab.length) == 0)
//Initialize Node array
tab = initTable();
...
}
At this time, there will be concurrency problems. What if multiple threads call initTable to initialize the Node array at the same time? See how the master handled it:
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//Each loop gets the latest Node array reference
while ((tab = table) == null || tab.length == 0) {
//sizeCtl is a flag bit. If it is - 1, that is less than 0, it means that a thread is initializing
if ((sc = sizeCtl) < 0)
//Free CPU time slice
Thread.yield(); // lost initialization race; just spin
//CAS operation, set the sizeCtl variable of this instance to - 1
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
//If the CAS operation is successful, this thread will be responsible for initialization
try {
//Check again if the array is empty
if ((tab = table) == null || tab.length == 0) {
//When initializing the Map, sizeCtl represents the array size, which is 16 by default
//So at this time, n defaults to 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//Node array
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
//Assign it to the table variable
table = tab = nt;
//Through bit operation, n minus N binary shifts 2 bits to the right, which is equivalent to multiplying by 0.75
//For example, 16 is calculated to be 12, which is the same as multiplying 0.75, but the bit operation is faster
sc = n - (n >>> 2);
}
} finally {
//The calculated sc (12) is directly assigned to sizeCtl, which means that the capacity will be expanded when the length reaches 12
//Since there is only one thread executing here, you can directly assign a value. There is no thread safety problem
//You just need to ensure visibility
sizeCtl = sc;
}
break;
}
}
return tab;
}
The table variable uses volatile to ensure that the latest written value is obtained every time:
transient volatile Node<K,V>[] table;
summary
Even if multiple threads perform put operation at the same time, optimistic lock CAS operation is used when initializing the array to determine which thread is qualified for initialization, and other threads can only wait.
Concurrency skills used:
- Volatile variable (sizeCtl): it is a flag bit used to tell other threads whether there is anyone in this pit. The visibility between threads is guaranteed by volatile.
- CAS operation: CAS operation ensures the atomicity of setting sizeCtl flag bit and that only one thread can be set successfully
|Thread safety of put operation
Look directly at the code:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//Hash the hashCode of the key
int hash = spread(key.hashCode());
int binCount = 0;
//An infinite loop until the put operation is completed and the loop exits
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//Initialize when the Node array is empty
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//The Unsafe class extracts the Node object corresponding to the subscript value of the Node array obtained by the operation after hashCode hash in the volatile manner
//If the Node object is empty at this time, it means that there is no thread to insert this Node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//Insert data directly
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
//Insert successfully, exit the loop
break; // no lock when adding to empty bin
}
//Check whether it is expanding. Don't look at it first, and then introduce it
else if ((fh = f.hash) == MOVED)
//Help expand capacity
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//Lock the Node object
synchronized (f) {
//Confirm again that the Node object is still the original one
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
//Infinite loop until put is completed
for (Node<K,V> e = f;; ++binCount) {
K ek;
//Like HashMap, compare hash first and then equals
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
//If it does not conflict with the chain header Node, it is initialized as a new Node as the next Node of the previous Node
//Form a linked list structure
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
...
}
It is worth noting that the tabAt(tab, i) method uses the operation of Unsafe class volatile to view the value in a volatile manner to ensure that the value obtained each time is the latest:
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
Although volatile is added to the above table variable, it can only ensure the visibility of its reference, not whether the objects in its array are up-to-date. Therefore, Unsafe class needs to get the latest Node in a volatile manner.
summary
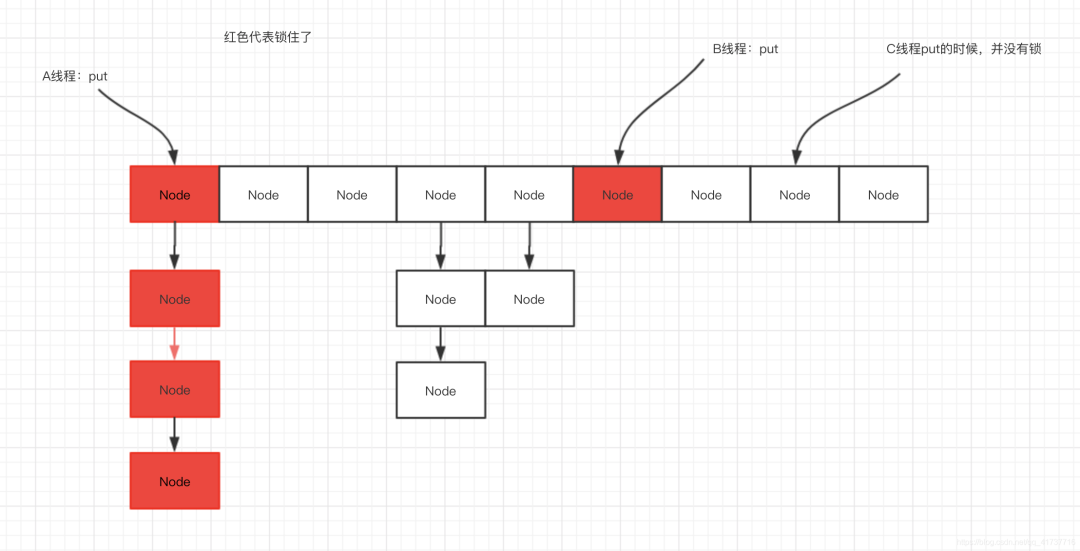
Because it reduces the granularity of the lock, if the hash is perfect and does not conflict, it can support n threads to put at the same time, and n is the size of the Node array. Under the default size of 16, it can support a maximum of 16 threads to operate at the same time without competition and thread safety. When the hash conflict is serious, the Node linked list becomes longer and longer, which will lead to serious lock competition. At this time, the capacity will be expanded and the nodes will be hashed. The thread safety of capacity expansion will be introduced below. Summarize the concurrency techniques used:
- Reduce lock granularity: take the head Node of the Node linked list as the lock. If the default size is 16, there will be 16 locks, which greatly reduces the lock competition (context switching). As mentioned at the beginning, maximize and reduce the serial part. Ideally, the put operations of threads are parallel operations. At the same time, the head Node is directly locked to ensure thread safety
- getObjectVolatile method of Unsafe: this method ensures that the obtained value is the latest.
|Thread safety of capacity expansion operation
During capacity expansion, ConcurrentHashMap supports multithreading Concurrent capacity expansion , in the process of capacity expansion, it also supports get data query. If there is thread put data, it will also help to expand the capacity together. This non blocking algorithm can be called a masterpiece for the design of maximizing parallelism.
Let's take a look at the expansion code implementation:
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//According to the number of CPU cores in the machine, a thread is responsible for the migration amount in the Node array
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
//Migration amount allocated to this thread
//Assume 16 (the default is also 16)
stride = MIN_TRANSFER_STRIDE; // subdivide range
//If nextTab is empty, it means that the thread is the first to migrate
//Initialize the new Node array after migration
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
//Here n is the length of the old array. Moving one bit to the left is equivalent to multiplying by 2
//For example, the length of the original array is 16, and the length of the new array is 32
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
//Set the nextTable variable to a new array
nextTable = nextTab;
//Assume 16
transferIndex = n;
}
//Assumed to be 32
int nextn = nextTab.length;
//Indicates the Node object whose hash variable is - 1
//If this Node is encountered during get or put, you can know that the current Node is migrating
//Pass in the nextTab object
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//i is the index of the Node array currently being processed. Each time a Node is processed, it will be reduced by 1
if (--i >= bound || finishing)
advance = false;
//Suppose nextIndex=16
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//Based on the above assumptions, nextBound is 0
//And set nextIndex to 0
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
//bound=0
bound = nextBound;
//i=16-1=15
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
//At this time, i=15, take out the Node with subscript 15 of the Node array. If it is empty, migration is not required
//Directly set the occupation mark, which means that the Node has been processed
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//Check whether the hash of this Node is MOVED. MOVED is a constant - 1, that is, the hash of the placeholder Node mentioned above
//If it is a placeholder Node, it proves that the Node has been processed. Skip the processing of i=15 and continue the cycle
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
//Lock this Node
synchronized (f) {
//Confirm that the Node is the original Node
if (tabAt(tab, i) == f) {
//ln is lowNode, low Node, hn is highNode and high Node
//These two concepts are illustrated in the figure below
Node<K,V> ln, hn;
if (fh >= 0) {
//At this time, fh performs an and operation with the length of the original Node array
//If the high X bit is 0, runBit=0
//If the high X bit is 1, runBit=1
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
//All nodes here are Node objects in the same Node linked list
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//As mentioned above, runBit=0 indicates that this Node is a low order Node
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
//Node is a high-order node
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
//If the hash and n sum operation is 0, it is proved to be a low-order Node. The principle is the same as above
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
//Here, the high Node and the position Node are respectively composed of two linked lists
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//Set the lower Node to the new Node array, and the subscript is the original position
setTabAt(nextTab, i, ln);
//Set the high Node to the new Node array, and the subscript is the original position plus the length of the original Node array
setTabAt(nextTab, i + n, hn);
//Setting this Node as a placeholder Node represents the completion of processing
setTabAt(tab, i, fwd);
//Continue the cycle
advance = true;
}
....
}
}
}
}
}
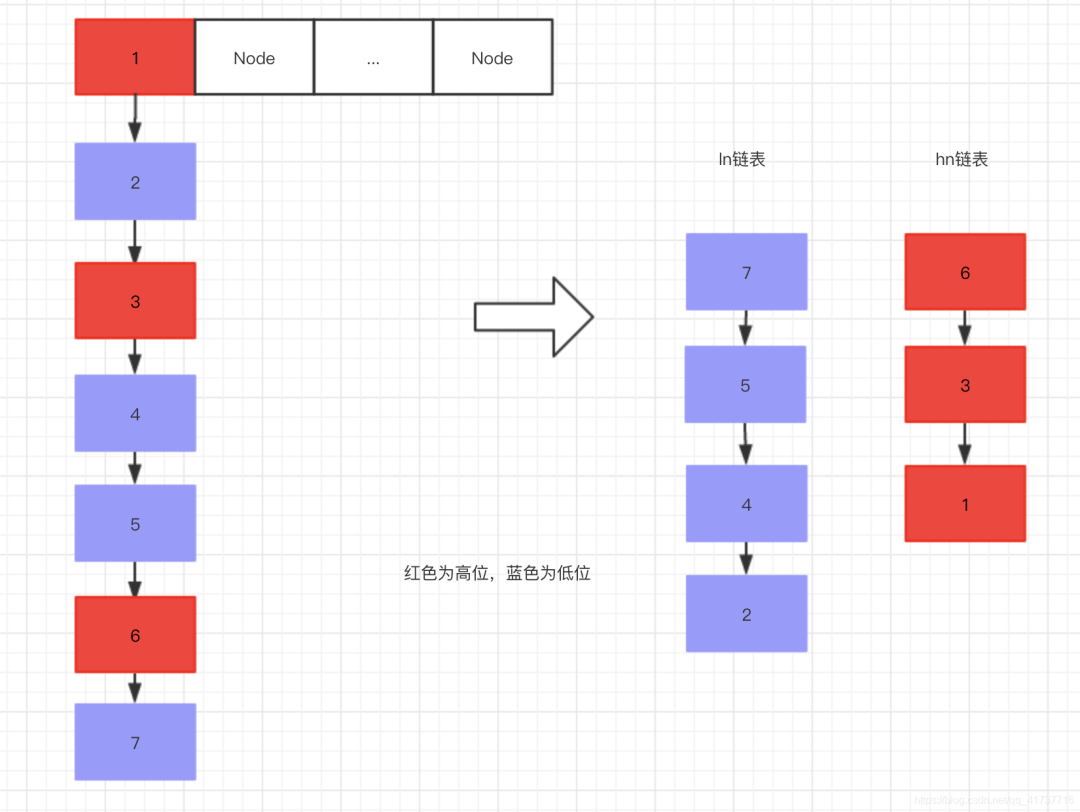
Here's why there are ln (low order Node) and hn (high order Node) during migration. First, let's talk about a phenomenon:
We know that when the put value is, the hash value will be calculated first, and then hashed into the subscript of the specified Node array:
//Hash again according to the hashCode of the key int hash = spread(key.hashCode()); //Use the (n - 1) & hash operation to locate the subscript value in the Node array (f = tabAt(tab, i = (n - 1) & hash);
Where n is the length of the Node array, which is assumed to be 16.
Suppose a key comes in and its hash after hash=9, what is its subscript value?
- (16 - 1) and 9 perform and operation - > 0000 1111 and 0000 1001 result or 0000 1001 = 9
Assuming that the Node array needs to be expanded, we know that the expansion is to double the length of the array, that is, 32, so what is the subscript value?
- (32 - 1) and 9 perform and operation - > 0001 1111 and 0000 1001 result or 9
At this point, we change the hash after hashing to 20, so what will happen?
- (16 - 1) and 20 perform the sum operation - > 0000 1111 and 0001 0100, and the result is 0000 0100 = 4
- (32 - 1) and 20 perform the sum operation - > 0001 1111 and 0001 0100, and the result is 0001 0100 = 20
At this time, careful readers should find that if the high X bit of the hash is 1 (X is the highest bit of binary-1 of the array length), the index value in the Node array needs to be transformed during capacity expansion, otherwise the hash will not be found and the data will be lost. Therefore, during migration, the Node with high X bit of 1 is classified as hn and the Node with high X bit of 0 is classified as ln.
Back in the code:
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash;
K pk = p.key;
V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
This operation consists of two linked list structures, high and low, as shown in the following figure:
Then put its CAS operation into the new Node array:
setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn);
Among them, the low-order linked list is placed at the original subscript, while the high-order linked list needs to add the length of the original Node array. Why not repeat it? It has been illustrated above, so as to ensure that the high-order nodes can still be hashed to the array corresponding to the subscript using the hash algorithm when migrating to the new Node array.
Finally, set the corresponding subscript Node object in the original Node array as fwd marked Node, indicating that the Node migration is completed. Here, the migration of one Node is completed, and the next Node will be migrated, that is, the Node with i-1=14 subscript.
get operation during capacity expansion:
Suppose that a Node with a subscript of 16 is migrating, and suddenly a thread comes in to call the get method, and the key is hashed to the Node with a subscript of 16. What should I do now?
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//If the hash value of the Node is less than 0
//It may be a fwd node
else if (eh < 0)
//Call the find method of the node object to find the value
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
Focus on the two lines with comments. In the source code of the get operation, you will judge whether the hash in the Node is less than 0 and whether you remember our placeholder Node. Its hash is MOVED and the constant value is - 1. Therefore, it is judged that the thread is migrating and entrusted to the fwd placeholder Node to find the value:
//In the internal class ForwardingNode
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
// The search here is to search in the new Node array
// The following search process is the same as HashMap search and will not be repeated
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
It should be clear here that the reason why the placeholder Node needs to save the reference of the new Node array is also because of this. It can support the search for values without blocking during the migration process. It can be described as a wonderful design.
Multi thread assisted capacity expansion
During the put operation, suppose that the migration is in progress, and a thread comes in and wants to put the value to the migrated Node. What should I do?
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//If a placeholder Node is found at this time, it proves that the HashMap is migrating at this time
else if ((fh = f.hash) == MOVED)
//Assist in migration
tab = helpTransfer(tab, f);
...
}
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
//sizeCtl plus one indicates that one more thread comes in to assist in capacity expansion
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
//Capacity expansion
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
This method involves a large number of complex bit operations, which will not be repeated here, but just a few words. At this time, the sizeCtl variable is used to indicate that HashMap is expanding. When it is ready to expand, sizeCtl will be set to a negative number (for example, when the array length is 16), and its binary representation is:
1000 0000 0001 1011 0000 0000 0000 0010
The unsigned bit is 1, indicating a negative number. Among them, the upper 16 bits represent the one bit algorithm mark of the array length (a bit like the function of epoch, indicating that the current migration Dynasty is the array length X). The lower 16 bits indicate that several threads are migrating. At first, it is 2, and then it is increased by 1. After the thread migration, it will be reduced by 1. That is, if the lower 16 bits are 2, it means that a thread is migrating. If it is 3, Represents that 2 threads are migrating, and so on
As long as the array length is long enough, it can accommodate enough threads to expand together, maximize parallel tasks and improve performance.
Under what circumstances will capacity expansion be performed?
- When the put value is, it will assist in capacity expansion when it is found that the Node is a placeholder Node (fwd).
- After adding a node, it is detected that the length of the linked list is greater than 8.
final V putVal(K key, V value, boolean onlyIfAbsent) {
...
if (binCount != 0) {
//TREEIFY_THRESHOLD=8, when the length of the linked list is greater than 8
if (binCount >= TREEIFY_THRESHOLD)
//Call treeifyBin method
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
...
}
treeifyBin method will convert the linked list into a red black tree to increase the search efficiency, but before that, it will check the array length. If it is less than 64, it will give priority to the expansion operation:
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//MIN_TREEIFY_CAPACITY=64
//If the array length is less than 64, expand the capacity first
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
//Capacity expansion
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
//... conversion to red black tree
}
}
}
}
After each new Node is added, the addCount method will be called to detect whether the size of the Node array reaches the threshold:
final V putVal(K key, V value, boolean onlyIfAbsent) {
...
//As described in the following section, this method counts the number of container elements
addCount(1L, binCount);
return null;
}
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
//Operation of counting the number of elements
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//When the number of elements reaches the threshold, expand the capacity
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
//sizeCtl is found to be negative, indicating that a thread is migrating
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//If it is not negative, it is the first migrated thread
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
summary
ConcurrentHashMap uses various CAS operations to maximize the concurrency performance of capacity expansion operations. In the process of capacity expansion, even if a thread calls the get query method, it can safely query data. If a thread performs put operation, it will also assist in capacity expansion. It uses sizeCtl flag bits and various volatile variables to carry out CAS operations to achieve communication and assistance between multiple threads, Only one Node is locked during migration, which not only ensures thread safety, but also improves concurrency performance.
|Thread safety for container size statistics
After each put operation, ConcurrentHashMap will call the addCount method. This method is used to count the container size and detect whether the container size reaches the threshold. If the threshold is reached, capacity expansion is required, which is also mentioned above. This section focuses on how the statistics of container size can achieve thread safety and high concurrency performance.
Most stand-alone data query optimization schemes will reduce the concurrency performance. Just like cache storage, there will be concurrency problems in multi-threaded environment, so there will be parallel or a series of concurrency conflict lock competition problems, which will reduce the concurrency performance. Similarly, hot data also has such problems. In the process of multithreading concurrency, hot data (frequently accessed variables) is data that will be accessed almost more or less in each thread, which will increase the serial part of the program. Recall the description at the beginning, the serial part of the program will affect the scalability of concurrency and degrade the concurrency performance, This usually becomes the bottleneck of concurrent program performance.
In concurrent HashMap, how to quickly count the container size is a very important issue, because the container needs to rely on the container size to consider whether it needs to be expanded. For the client, this method needs to be called to know how many elements the container has. If this hot data is not handled well, the concurrency performance will decline because of the overall performance of the short board.
Imagine, if it were you, how would you design such hot data? Lock or CAS operation? Enter ConcurrentHashMap to see how the master skillfully uses concurrency skills to improve the concurrency performance of hot data.
Let's first look at the general implementation idea in the form of diagram:
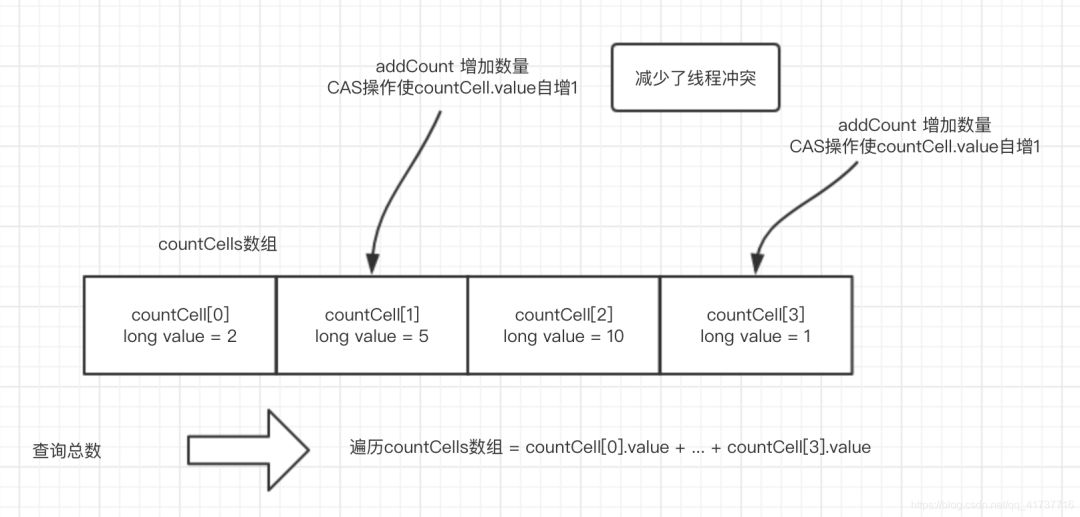
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
This is a rough implementation. In the design, the idea of divide and conquer is used to disperse each count into each countCell object (hereinafter referred to as bucket), so as to minimize the competition. CAS operation is also used. Even if there is competition, other processing can be carried out on the failed thread. The difference between the implementation of optimistic lock and pessimistic lock is that optimistic lock can handle threads that fail to compete with other strategies, while pessimistic lock can only wait for the lock to be released. Therefore, CAS operation is used to deal with threads that fail to compete, and CAS optimistic lock is skillfully used.
Let's take a look at the specific code implementation:
//Count and check whether the length reaches the threshold
private final void addCount(long x, int check) {
//Counting bucket
CounterCell[] as; long b, s;
//If counterCells is not null, it means that it has been initialized and directly enters the if statement block
//If the competition is not serious, counterCells may not be initialized and null. First try CAS operation to increment baseCount value
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
//There are two possibilities to enter this sentence block
//1.counterCells has been initialized and is not null
//2.CAS operation failed to increment baseCount value, indicating competition
CounterCell a; long v; int m;
//Mark whether there is competition
boolean uncontended = true;
//1. First judge whether the counting bucket has not been initialized, then as=null and enter the statement block
//2. Judge whether the counting bucket length is empty or, if yes, enter the statement block
//3. A thread variable random number is made here, which is - 1 with the size of the upper bucket. If this position of the bucket is empty, enter the statement block
//4. This indicates that the bucket has been initialized and the random position is not empty. Try CAS operation to add 1 to the bucket, and fail to enter the statement block
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
//Statistics container size
s = sumCount();
}
...
}
Assume that the current thread is the first put thread
Assuming that the current Map has not been put data, addCount must not have been called. If the current thread calls the addCount method first, then the countCell must not have been initialized and is null, then make the following judgment:
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x))
The if judgment here must follow the second judgment. First, increase the value of the variable baseCount:
private transient volatile long baseCount;
What's the use of this value? Let's take a look at the method sumCount for counting container size:
final long sumCount() {
//Get count bucket
CounterCell[] as = counterCells; CounterCell a;
//Get baseCount and assign it to sum total
long sum = baseCount;
//If the counting bucket is not empty, count the value in the counting bucket
if (as != null) {
for (int i = 0; i < as.length; ++i) {
//Traverse the counting bucket and add the value value
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
The general idea of this method is similar to the figure at the beginning. The size of the container is actually divided into two parts. At the beginning, only the part of the counting bucket is mentioned. In fact, there is also a baseCount. In other words, when increasing the capacity, CAS increments the baseCount first.
It can be seen that there are two ways to count the container size:
- CAS direct increment: when there is little thread competition, you can directly use CAS operation to increment the baseCount value. The little competition here means that CAS operation will not fail
- Divide and conquer bucket counting: if the CAS operation fails, it proves that there is thread competition, and the counting mode is changed from CAS mode to divide and conquer bucket counting mode
CAS failed due to thread contention
In case of competition, the CAS method will not be used for counting. Instead, the bucket method will be used directly. It can be seen from the addCount method above that the countCell is empty. Finally, the fullAddCount method will be entered to initialize the bucket:
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
...
//If the counting bucket= null, which proves that it has been initialized. This sentence block will not be taken at this time
if ((as = counterCells) != null && (n = as.length) > 0) {
...
}
//Enter this sentence block to initialize the counting bucket
//CAS sets cellsBusy=1, which means that the counting bucket is now in Busy
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
//If a thread initializes the counting bucket at the same time, only one thread enters here due to CAS operation
boolean init = false;
try { // Initialize table
//Reconfirm that the counting bucket is empty
if (counterCells == as) {
//Initializes a counting bucket with a length of 2
CounterCell[] rs = new CounterCell[2];
//h is a random number, and the upper 1 represents the random one of 0 and 1
//That is, select any counting bucket in the subscripts of 0 and 1, x=1, and the value of 1 represents an increase of 1 capacity
rs[h & 1] = new CounterCell(x);
//Assign the initialized counting bucket to ConcurrentHashMap
counterCells = rs;
init = true;
}
} finally {
//Finally, set the busy ID to 0, indicating that you are not busy
cellsBusy = 0;
}
if (init)
break;
}
//If a thread initializes the counting bucket at the same time, the thread that does not grab the busy qualification will first come to CAS to increment baseCount
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
This completes the initialization of the counting bucket. The counting bucket will be used to count the total number in subsequent counting.
Capacity expansion of counting bucket
From the above analysis, we know that the length of the counting bucket after initialization is 2, which is certainly not enough when the competition is large, so there must be capacity expansion of the counting bucket, so there are two problems now:
- Under what conditions will the counting bucket be expanded?
- What is the capacity expansion operation like?
Suppose that the counting bucket is used for counting at this time:
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
//At this point, it is obvious that a random bucket will be selected in the bucket array
//Then use CAS operation to add value+1 in this bucket
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
//If the CAS operation fails, it is proved that there is competition, and enter the fullAddCount method
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
...
}
Enter the fullAddCount method:
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
//After the counting bucket is initialized, you must go through this if statement block
if ((as = counterCells) != null && (n = as.length) > 0) {
//Randomly select a counting bucket from the counting bucket array. If it is null, it means that the bucket has not been incremented by a thread
if ((a = as[(n - 1) & h]) == null) {
//Check whether the busy status of the counting bucket is identified
if (cellsBusy == 0) { // Try to attach new Cell
//If not busy, directly new a counting bucket
CounterCell r = new CounterCell(x); // Optimistic create
//CAS operation, mark in counting bucket busy
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try { // Recheck under lock
CounterCell[] rs; int m, j;
//Check again under the lock. The counting bucket is null
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
//Assign the counting bucket just created to the corresponding position
rs[j] = r;
created = true;
}
} finally {
//The sign is not busy
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
//This means that the counting bucket is not null. Try to increment the counting bucket
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
else if (counterCells != as || n >= NCPU)
collide = false; // At max size or stale
//If the CAS operation fails, it will enter once and then go through the for loop just now
//If the second for loop collade = true, it will not go in
else if (!collide)
collide = true;
//During the capacity expansion of the counting bucket, if a thread goes through the for loop twice, that is, it performs multiple CAS operations, and the incremental counting bucket fails
//Then the capacity of the counting bucket is expanded, and CAS indicates that the counting bucket is busy
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
//Confirm that the counting bucket is still the same
if (counterCells == as) {// Expand table unless stale
//Expand the length to 2x
CounterCell[] rs = new CounterCell[n << 1];
//Traverse the old counting bucket and move the reference directly
for (int i = 0; i < n; ++i)
rs[i] = as[i];
//assignment
counterCells = rs;
}
} finally {
//Cancel busy status
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = ThreadLocalRandom.advanceProbe(h);
}
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
//Initialize counting bucket
}
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
Seeing this, I think we can solve the above two problems:
Under what conditions will the counting bucket be expanded?
A: after the CAS operation fails to increase the counting bucket for 3 times, the capacity of the counting bucket will be expanded. Note that at this time, the counting bucket is randomly located twice to increase the CAS, so the probability can be guaranteed. The capacity of the counting bucket will be expanded only because the counting bucket is not enough
What is the capacity expansion operation like?
A: when the length of the counting bucket is doubled, the data is directly traversed and migrated. Because the counting bucket is not as complex as the HashMap data structure, it is affected by the hash algorithm. In addition, the counting bucket only stores a count value of long type, so it can be directly assigned and referenced.
summary
Personally, thread safety and capacity expansion of container size can be regarded as the two smartest concurrent designs in concurrent HashMap. I can't help clapping my hands when reading this source code. I think this may also be a fun to see the source code. Stand on the shoulders of giants and watch the thoughts of giants.
Summarize the concurrency techniques used in counting:
- CAS increments the baseCount value to sense whether there is thread competition. If the competition is not large, CAS can directly increment the baseCount value, and the performance is not different from that of direct baseCount + +.
- If there is thread competition, initialize the counting bucket. If there is also competition in the process of initializing the counting bucket, and multiple threads initialize the counting bucket at the same time, the threads that do not grab the initialization qualification directly try to complete the counting by increasing the baseCount value of CAS, maximizing the parallelism of threads. At this time, the counting bucket is used to count, divide and conquer. At this time, the two counting buckets can provide a maximum of two threads to count at the same time, and the CAS operation is used to sense thread competition. If the CAS operation still fails frequently (fails 3 times) in the case of two buckets, the counting bucket is directly expanded to four counting buckets, supporting a maximum of four threads to count concurrently at the same time, And so on... Using bit operation and random number to "load balance" the thread counting requests nearly evenly in each counting bucket.
|Thread safety of get operation
For get operation, there is no thread safety problem, only visibility problem. Just ensure that the data of get is visible between threads:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
//This process is the same as the get operation of HashMap and will not be repeated
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//When hash < 0, it may be migration. Use fwd placeholder Node to find the data in the new table
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
In addition to adding the judgment of migration, the get operation is basically the same as the get operation of HashMap, which will not be repeated here. It is worth mentioning that the tabAt method Unsafe class volatile is used to obtain the nodes in the Node array to ensure that the obtained nodes are up-to-date.
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
|Different implementations of JDK1.7 and 1.8
Underlying data structure of ConcurrentHashMap in JDK1.7:
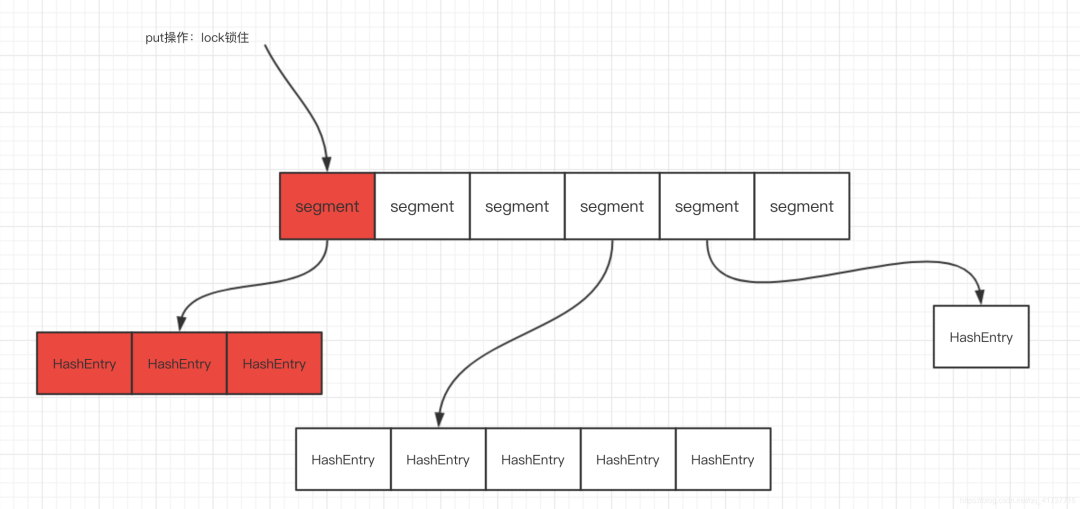
The implementation of 1.7 also adopts the segmented lock technology, but multiple segments correspond to a small HashMap. The segment inherits ReentrantLock and acts as a lock. One lock locks a small HashMap (equivalent to multiple nodes). From the implementation of 1.8, the granularity of the lock is reduced from multiple Node levels to one Node level, Reduce lock contention again and reduce the part of program synchronization.
|Summary
I have to say that the master uses CAS operations incisively and vividly. I believe readers who understand the above source code can also learn the concurrency skills used by the master, not only in ConcurrentHashMap, but also in most of the source code of JUC. Many concurrency ideas are worth reading and learning.