This article is compiled and published by jiumo (Ma Zhi), chief lecturer of HeapDump performance community
Part 9 - definition of bytecode instructions
The previous article introduced the Java stack frame creation and bytecode dispatch logic under explanation and execution, but never talked about how the virtual machine executes the bytecode in the Java method. Before introducing the execution of bytecode, you need to know the definition of bytecode instruction. Some properties of bytecode instructions are defined in the Bytecodes::initialize() function. The call chain of this function is as follows:
init_globals() bytecodes_init() Bytecodes::initialize()
There are definitions like this in the Bytecodes::initialize() function:
// bytecode bytecode name format wide f. result tp stk traps def(_nop , "nop" , "b" , NULL , T_VOID , 0, false); def(_aconst_null , "aconst_null" , "b" , NULL , T_OBJECT , 1, false); def(_iconst_m1 , "iconst_m1" , "b" , NULL , T_INT , 1, false); def(_iconst_0 , "iconst_0" , "b" , NULL , T_INT , 1, false); def(_iconst_1 , "iconst_1" , "b" , NULL , T_INT , 1, false); // ...
Now the 202 bytecode instructions defined in the Java virtual machine specification will be defined by calling the def() function as shown in the figure above. We need to focus on the parameters bytecode name, format, etc. passed when calling the def() function. The following explanations are as follows:
- Bytecode name is the bytecode name;
- Wide indicates whether a wide can be added before the bytecode. If yes, the value is "wbii";
- result tp indicates the result type after the instruction is executed, such as t_ When integer, it means that only the current bytecode is referenced, and the type of execution result cannot be determined, such as_ When invokevirtual method calls an instruction, the result type should be the method return type, but it cannot be determined by referring only to the bytecode instruction of the calling method at this time;
- stk indicates the effect on the depth of the expression stack, such as_ The nop instruction does not perform any operation, so it has no effect on the depth of the expression stack. The value of stk is 0; When used_ iconst_ When 0 pushes 0 into the stack, the depth of the stack increases by 1, so the value of stk is 1. As_ lconst_0, the depth of the stack will increase by 2; As_ lstore_ When 0, the depth of the stack will be reduced by 2;
- traps means can_trap, which is more important, will be described in detail later.
- Format, this attribute can express two meanings. First, it can express the format of bytecode and the length of bytecode.
Next, we need to focus on the parameter format. Format indicates the format of bytecode. When there is a character in the string, it is a bytecode of one byte length. When it is 2 characters, it is a bytecode of 2 bytes length..., such as_ iconst_0 is a bytecode with a byte width_ The format of istore is "bi", so it is 2 bytes wide. Format may also be an empty string. When it is an empty string, it indicates that the current bytecode is not the bytecode defined in the Java virtual machine specification, such as to improve the efficiency of interpretation and execution_ fast_agetfield,_ fast_ Bytecodes such as bgetfield, which are internally defined by the virtual machine. It can also express the format of bytecode. The meaning of each character in the string is as follows:
b: Indicates that bytecode instructions are of non variable length, so for variable length instructions such as tableswitch and lookupswitch, the format string will not contain the B character;
c: The operand is a signed constant. For example, the bipush instruction extends the byte signed to an int value, and then puts the value on the operand stack;
i: The operand is an unsigned local variable table index value. For example, the iload instruction loads an int type value from the local variable table into the operand stack;
j: The operand is the index of the constant pool cache. Note that the constant pool cache index is different from the constant pool index. The constant pool index has been described in detail in the basic volume of in-depth analysis of Java virtual machine: source code analysis and example explanation, and will not be introduced here;
k: The operand is an unsigned constant pool index. For example, the ldc instruction will extract data from the runtime constant pool and push it into the operand stack, so the format is "bk";
o: The operand is the branch offset. For example, ifeq represents the comparison between an integer and zero. If the integer is 0, the comparison result is true. The operand is regarded as the branch offset for jump, so the format is "boo";
_: can be ignored directly
w: Bytecode that can be used to extend the local variable table index. These bytecodes include iload, flow, etc., so the value of wild is "wbii";
The implementation of the called def() function is as follows:
void Bytecodes::def(
Code code,
const char* name,
const char* format,
const char* wide_format,
BasicType result_type,
int depth,
bool can_trap,
Code java_code
) {
int len = (format != NULL ? (int) strlen(format) : 0);
int wlen = (wide_format != NULL ? (int) strlen(wide_format) : 0);
_name [code] = name;
_result_type [code] = result_type;
_depth [code] = depth;
_lengths [code] = (wlen << 4) | (len & 0xF); // The binary value of 0xF is 1111
_java_code [code] = java_code;
int bc_flags = 0;
if (can_trap){
// LDC, ldc_w, ldc2_w, _aload_0, iaload, iastore, idiv, ldiv, ireturn, etc
// Bytecode instructions contain _bc_can_trap
bc_flags |= _bc_can_trap;
}
if (java_code != code){
bc_flags |= _bc_can_rewrite; // All instructions defined in the virtual machine will have _bc_can_rewrite
}
// Assign values to _flags here
_flags[(u1)code+0*(1<<BitsPerByte)] = compute_flags(format, bc_flags);
_flags[(u1)code+1*(1<<BitsPerByte)] = compute_flags(wide_format, bc_flags);
}
Among them, _name, _result_type, etc. are static arrays defined in Bytecodes class. Their subscripts are Opcode values, and the stored values are name, result_type, etc. the definitions of these variables are as follows:
const char* Bytecodes::_name [Bytecodes::number_of_codes]; BasicType Bytecodes::_result_type [Bytecodes::number_of_codes]; s_char Bytecodes::_depth [Bytecodes::number_of_codes]; u_char Bytecodes::_lengths [Bytecodes::number_of_codes]; Bytecodes::Code Bytecodes::_java_code [Bytecodes::number_of_codes]; u_short Bytecodes::_flags [(1<<BitsPerByte)*2];
The value of Bytecodes::number_of_codes is 234, which is enough to store all bytecode instructions (including instructions extended inside the virtual machine)
Looking back at Bytecodes::def() function, by calling the compute_flags() function to calculate some properties of bytecode according to the incoming wide_format and format, and then store it in high 8 bits and low 8 bits. The realization of the compute_flags() function is as follows:
int Bytecodes::compute_flags(const char* format, int more_flags) {
if (format == NULL) {
return 0; // not even more_flags
}
int flags = more_flags;
const char* fp = format;
switch (*fp) {
case '\0':
flags |= _fmt_not_simple; // but variable
break;
case 'b':
flags |= _fmt_not_variable; // but simple
++fp; // skip 'b'
break;
case 'w':
flags |= _fmt_not_variable | _fmt_not_simple;
++fp; // skip 'w'
guarantee(*fp == 'b', "wide format must start with 'wb'");
++fp; // skip 'b'
break;
}
int has_nbo = 0, has_jbo = 0, has_size = 0;
for (;;) {
int this_flag = 0;
char fc = *fp++;
switch (fc) {
case '\0': // end of string
assert(flags == (jchar)flags, "change _format_flags");
return flags;
case '_': continue; // ignore these
case 'j': this_flag = _fmt_has_j; has_jbo = 1; break;
case 'k': this_flag = _fmt_has_k; has_jbo = 1; break;
case 'i': this_flag = _fmt_has_i; has_jbo = 1; break;
case 'c': this_flag = _fmt_has_c; has_jbo = 1; break;
case 'o': this_flag = _fmt_has_o; has_jbo = 1; break;
case 'J': this_flag = _fmt_has_j; has_nbo = 1; break;
...
default: guarantee(false, "bad char in format");
}// End switch
flags |= this_flag;
guarantee(!(has_jbo && has_nbo), "mixed byte orders in format");
if (has_nbo){
flags |= _fmt_has_nbo;
}
int this_size = 1;
if (*fp == fc) {
// advance beyond run of the same characters
this_size = 2;
while (*++fp == fc){
this_size++;
}
switch (this_size) {
case 2: flags |= _fmt_has_u2; break; // Such as sipush, ldc_w, ldc2_w, wide iload, etc
case 4: flags |= _fmt_has_u4; break; // Such as goto_w and invokedynamic instructions
default:
guarantee(false, "bad rep count in format");
}
}
has_size = this_size;
}
}
The function calculates the value of flags according to the wide_format and format. The values in flags can represent the b, c, i, j, k, o, w of bytecode (introduced when format was introduced earlier) and the size of bytecode operand (whether the operand is 2 bytes or 4 bytes). Some variables starting with _fmt have been defined in the enumeration class, as follows:
// Flag bits derived from format strings, can_trap, can_rewrite, etc.:
enum Flags {
// semantic flags:
_bc_can_trap = 1<<0, // Bytecode execution can trap or block
// All bytecode instructions defined inside the virtual machine will contain this ID
_bc_can_rewrite = 1<<1, // Bytecode execution has an alternate form
// format bits (determined only by the format string):
_fmt_has_c = 1<<2, // constant, such as sipush "bcc"
_fmt_has_j = 1<<3, // constant pool cache index, such as getfield "bjj"
_fmt_has_k = 1<<4, // constant pool index, such as ldc "bk"
_fmt_has_i = 1<<5, // local index, such as iload
_fmt_has_o = 1<<6, // offset, such as ifeq
_fmt_has_nbo = 1<<7, // contains native-order field(s)
_fmt_has_u2 = 1<<8, // contains double-byte field(s)
_fmt_has_u4 = 1<<9, // contains quad-byte field
_fmt_not_variable = 1<<10, // not of variable length (simple or wide)
_fmt_not_simple = 1<<11, // either wide or variable length is a bytecode instruction that can add a wild or a variable length instruction
_all_fmt_bits = (_fmt_not_simple*2 - _fmt_has_c),
// ...
};
The correspondence with format is as follows:
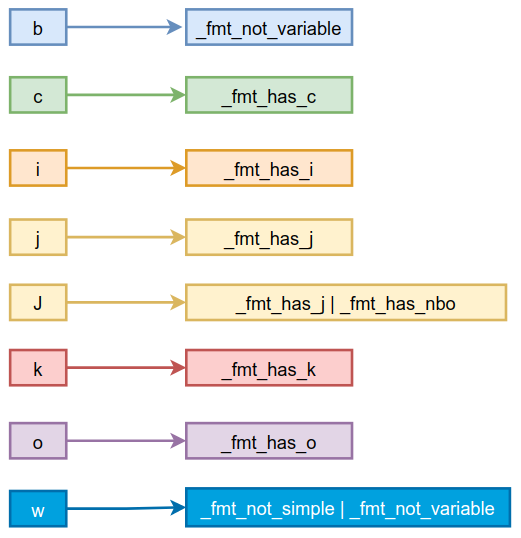
In this way, different values can be represented through combination. The common combinations defined in the enumeration class are as follows:
_fmt_b = _fmt_not_variable, _fmt_bc = _fmt_b | _fmt_has_c, _fmt_bi = _fmt_b | _fmt_has_i, _fmt_bkk = _fmt_b | _fmt_has_k | _fmt_has_u2, _fmt_bJJ = _fmt_b | _fmt_has_j | _fmt_has_u2 | _fmt_has_nbo, _fmt_bo2 = _fmt_b | _fmt_has_o | _fmt_has_u2, _fmt_bo4 = _fmt_b | _fmt_has_o | _fmt_has_u4
For example, when the bytecode is bipush, the format is "bc", then the value of flags is _fmt_b | _fmt_has_c, and the format of ldc bytecode is "bk", then the value of flags is _fmt_b | _fmt_has_k
Part 10 - initialization template table
In Chapter 9 - definition of bytecode instructions, we introduced bytecode instructions and stored the information related to bytecode instructions in the correlation array. We only need Opcode to obtain the corresponding information from the correlation array.
Calling the bytecodes_init() function in the init_globals() function initializes the byte code instruction and then calls the interpreter_init() function to initialize the interpreter. The function will eventually call the TemplateInterpreter::initialize() function. The implementation of the function is as follows:
Source code location: / src/share/vm/interpreter/templateInterpreter.cpp
void TemplateInterpreter::initialize() {
if (_code != NULL)
return;
// Initialization of the abstract interpreter AbstractInterpreter,
// AbstractInterpreter is a common base class of interpreters based on assembly model,
// The abstract interfaces of interpreter and interpreter generator are defined
AbstractInterpreter::initialize();
// Initialization of template table TemplateTable, which saves templates of each bytecode
TemplateTable::initialize();
// generate interpreter
{
ResourceMark rm;
int code_size = InterpreterCodeSize;
// Initialization of Stub queue of CodeCache
_code = new StubQueue(new InterpreterCodeletInterface, code_size, NULL,"Interpreter");
// Instantiate the template interpreter generator object TemplateInterpreterGenerator
InterpreterGenerator g(_code);
}
// Initialization byte distribution
_active_table = _normal_table;
}
The initialization logic involved in this initialization function is more and more complex. We divide initialization into four parts:
(1) Initialization of the abstract interpreter AbstractInterpreter, which is the common base class of the interpreter based on the assembly model and defines the abstract interface between the interpreter and the interpreter generator.
(2) Initialization of template table TemplateTable, which saves templates of each bytecode (object code generation function and parameters);
(3) Initialization of the Stub queue of CodeCache;
(4) Initialization of interpreter generator InterpreterGenerator.
Some counts will be involved in the initialization of the abstract interpreter. These counts are mainly related to compilation and execution, so I won't introduce them here for the time being. I'll introduce them later when I introduce compilation and execution.
Next, we will introduce the initialization process of the above three parts respectively. This article only introduces the initialization process of the template table.
The function TemplateTable::initialize() is implemented as follows:
The template table TemplateTable saves the execution templates (object code generation functions and parameters) of each bytecode. The definition of bytecode has been described in detail in the previous introduction. The execution template defines how each bytecode is executed in interpretation mode. The initialize() function is implemented as follows:
Source code location: / src/share/vm/interpreter/templateInterpreter.cpp
void TemplateTable::initialize() {
if (_is_initialized) return;
_bs = Universe::heap()->barrier_set();
// For better readability
const char _ = ' ';
const int ____ = 0;
const int ubcp = 1 << Template::uses_bcp_bit;
const int disp = 1 << Template::does_dispatch_bit;
const int clvm = 1 << Template::calls_vm_bit;
const int iswd = 1 << Template::wide_bit;
// interpr. templates
// Java spec bytecodes ubcp|disp|clvm|iswd in out generator argument
def(Bytecodes::_nop , ____|____|____|____, vtos, vtos, nop , _ );
def(Bytecodes::_aconst_null , ____|____|____|____, vtos, atos, aconst_null , _ );
def(Bytecodes::_iconst_m1 , ____|____|____|____, vtos, itos, iconst , -1 );
def(Bytecodes::_iconst_0 , ____|____|____|____, vtos, itos, iconst , 0 );
// ...
def(Bytecodes::_tableswitch , ubcp|disp|____|____, itos, vtos, tableswitch , _ );
def(Bytecodes::_lookupswitch , ubcp|disp|____|____, itos, itos, lookupswitch , _ );
def(Bytecodes::_ireturn , ____|disp|clvm|____, itos, itos, _return , itos );
def(Bytecodes::_lreturn , ____|disp|clvm|____, ltos, ltos, _return , ltos );
def(Bytecodes::_freturn , ____|disp|clvm|____, ftos, ftos, _return , ftos );
def(Bytecodes::_dreturn , ____|disp|clvm|____, dtos, dtos, _return , dtos );
def(Bytecodes::_areturn , ____|disp|clvm|____, atos, atos, _return , atos );
def(Bytecodes::_return , ____|disp|clvm|____, vtos, vtos, _return , vtos );
def(Bytecodes::_getstatic , ubcp|____|clvm|____, vtos, vtos, getstatic , f1_byte );
def(Bytecodes::_putstatic , ubcp|____|clvm|____, vtos, vtos, putstatic , f2_byte );
def(Bytecodes::_getfield , ubcp|____|clvm|____, vtos, vtos, getfield , f1_byte );
def(Bytecodes::_putfield , ubcp|____|clvm|____, vtos, vtos, putfield , f2_byte );
def(Bytecodes::_invokevirtual , ubcp|disp|clvm|____, vtos, vtos, invokevirtual , f2_byte );
def(Bytecodes::_invokespecial , ubcp|disp|clvm|____, vtos, vtos, invokespecial , f1_byte );
def(Bytecodes::_invokestatic , ubcp|disp|clvm|____, vtos, vtos, invokestatic , f1_byte );
def(Bytecodes::_invokeinterface , ubcp|disp|clvm|____, vtos, vtos, invokeinterface , f1_byte );
def(Bytecodes::_invokedynamic , ubcp|disp|clvm|____, vtos, vtos, invokedynamic , f1_byte );
def(Bytecodes::_new , ubcp|____|clvm|____, vtos, atos, _new , _ );
def(Bytecodes::_newarray , ubcp|____|clvm|____, itos, atos, newarray , _ );
def(Bytecodes::_anewarray , ubcp|____|clvm|____, itos, atos, anewarray , _ );
def(Bytecodes::_arraylength , ____|____|____|____, atos, itos, arraylength , _ );
def(Bytecodes::_athrow , ____|disp|____|____, atos, vtos, athrow , _ );
def(Bytecodes::_checkcast , ubcp|____|clvm|____, atos, atos, checkcast , _ );
def(Bytecodes::_instanceof , ubcp|____|clvm|____, atos, itos, instanceof , _ );
def(Bytecodes::_monitorenter , ____|disp|clvm|____, atos, vtos, monitorenter , _ );
def(Bytecodes::_monitorexit , ____|____|clvm|____, atos, vtos, monitorexit , _ );
def(Bytecodes::_wide , ubcp|disp|____|____, vtos, vtos, wide , _ );
def(Bytecodes::_multianewarray , ubcp|____|clvm|____, vtos, atos, multianewarray , _ );
def(Bytecodes::_ifnull , ubcp|____|clvm|____, atos, vtos, if_nullcmp , equal );
def(Bytecodes::_ifnonnull , ubcp|____|clvm|____, atos, vtos, if_nullcmp , not_equal );
def(Bytecodes::_goto_w , ubcp|____|clvm|____, vtos, vtos, goto_w , _ );
def(Bytecodes::_jsr_w , ubcp|____|____|____, vtos, vtos, jsr_w , _ );
// wide Java spec bytecodes
def(Bytecodes::_iload , ubcp|____|____|iswd, vtos, itos, wide_iload , _ );
def(Bytecodes::_lload , ubcp|____|____|iswd, vtos, ltos, wide_lload , _ );
// ...
// JVM bytecodes
// ...
def(Bytecodes::_shouldnotreachhere , ____|____|____|____, vtos, vtos, shouldnotreachhere , _ );
}
The initialization call def() of TemplateTable saves the object code generation functions and parameters of all bytecodes in the_ template_table or_ template_table_wide (wide instruction) in the template array. In addition to the bytecode instructions defined in the virtual machine specification, the HotSpot virtual machine also defines some bytecode instructions to assist the virtual machine in better function implementation, such as bytecodes:_ return_ register_ Finalizer has been introduced before, which can better realize the registration function of finalizer type objects.
We only give the template definition of some bytecode instructions, call the def() function to define the template of each bytecode instruction, and the passed parameters are the focus of our attention:
(1) Indicates which bytecode instruction template is defined for
(2) ubcp|disp|clvm|iswd, which is a combined number. The specific number is closely related to the enumeration class defined in the Template. The constants defined in the enumeration class are as follows:
enum Flags {
uses_bcp_bit, // set if template needs the bcp pointing to bytecode
does_dispatch_bit, // set if template dispatches on its own; Rely on yourself
calls_vm_bit, // set if template calls the vm
wide_bit // set if template belongs to a wide instruction
};
These parameters are explained in detail below:
- uses_bcp_bit, the flag needs to use byte code pointer (the value is byte code base address + byte code offset). Indicates whether pointers to bytecode instructions need to be used in the generated template code. In fact, that is, whether operands of bytecode instructions need to be read. Therefore, most instructions containing operands need BCP, but some do not need it, such as monitorenter and monitorexit. These operands are in the expression stack, and the top of the expression stack is their operands, You do not need to read from the Class file, so you do not need BCP;
- does_dispatch_bit flag indicates whether it contains control flow forwarding logic, such as tableswitch, lookupswitch, invokevirtual, ireturn and other bytecode instructions. Control flow forwarding is required by itself;
- calls_vm_bit, which indicates whether the JVM function needs to be called. When calling templatetable:: call_ The VM () function will judge whether there is this flag. Usually, when a method calls a JVM function, it will call TemplateTable::call_VM() function to indirectly complete the call. JVM functions are written in C + +.
- wide_bit, flag whether it is a wide instruction (use additional bytes to expand the global variable index)
(3)_ tos_in and_ tos_out: indicates the TosState before and after the template execution (the data type of the operand stack top element, TopOfStack, is used to check whether the output input type declared by the template is consistent with the function to ensure that the stack top element is used correctly).
_ tos_in and_ tos_ The value of out must be a constant defined in the enumeration class, as follows:
enum TosState { // describes the tos cache contents
btos = 0, // byte, bool tos cached
ctos = 1, // char tos cached
stos = 2, // short tos cached
itos = 3, // int tos cached
ltos = 4, // long tos cached
ftos = 5, // float tos cached
dtos = 6, // double tos cached
atos = 7, // object cached
vtos = 8, // tos not cached
number_of_states,
ilgl // illegal state: should not occur
};
For example, the state of the top of the stack before the execution of the iload instruction is vtos, which means that the data at the top of the stack will not be used. Therefore, if the program caches the result of the last execution into a register in order to improve the execution efficiency, the value of this register should be pressed into the top of the stack before the execution of the iload instruction. The top state of the stack after the iload instruction is executed is itos. Because iload pushes an integer into the operand stack, the top state of the stack at this time is of type int, so this value can be cached in the register. Assuming that the next instruction is ireturn, the States before and after the top of the stack are itos and itos respectively, then the int type cached in the register can be returned directly, There is no need to do any operation related to the operand stack.
(4)_ gen and_ arg: _ gen represents the template generator (function pointer), which will generate the corresponding execution logic for the corresponding bytecode_ Arg represents the parameter passed for the template generator. The calling function pointer will generate different machine instructions for each bytecode instruction on different platforms according to its semantics. Here, we only discuss the implementation of 64 bit machine instructions under x86 architecture. Since the machine instructions are difficult to read, we will only read the assembly instructions decompiled by machine instructions in the future.
Let's take a look at the Template::def() function in the TemplateTable::initialize() function, which is as follows:
void TemplateTable::def(
Bytecodes::Code code, // Bytecode instruction
int flags, // Flag bit
TosState in, // TosState before template execution
TosState out, // TosState after template execution
void (*gen)(int arg), // Template generator is the core component of template
int arg
) {
// Indicates whether a bcp pointer is required
const int ubcp = 1 << Template::uses_bcp_bit;
// Indicates whether to forward within the scope of the template
const int disp = 1 << Template::does_dispatch_bit;
// Indicates whether the JVM function needs to be called
const int clvm = 1 << Template::calls_vm_bit;
// Indicates whether it is a wide instruction
const int iswd = 1 << Template::wide_bit;
// If it is some instructions that allow wide bytecode instructions to be added before bytecode instructions, then
// Can use_ template_table_wild template array for bytecode forwarding, otherwise
// Use_ template_table template array for forwarding
bool is_wide = (flags & iswd) != 0;
Template* t = is_wide ? template_for_wide(code) : template_for(code);
// Call the initialize() method of the template table t to initialize the template table
t->initialize(flags, in, out, gen, arg);
}
A template table consists of a template table array and a set of generators:
Template array has_ template_table and_ template_table_ Field, the subscript of the array is Opcode of bytecode, and the value is template. It is defined as follows:
Template TemplateTable::_template_table[Bytecodes::number_of_codes]; Template TemplateTable::_template_table_wide[Bytecodes::number_of_codes];
The value of the Template array is Template. The Template class defines the method to save flag bits_ flags attribute, which saves the status of stack top cache in and out_ tos_in and_ tos_out, and save the generator gen and parameter arg_ gen and_ Arg, so calling T - > initialize() actually initializes the variables in the Template. The initialize() function is implemented as follows:
void Template::initialize(
int flags,
TosState tos_in,
TosState tos_out,
generator gen,
int arg
) {
_flags = flags;
_tos_in = tos_in;
_tos_out = tos_out;
_gen = gen;
_arg = arg;
}
However, the gen function will not be called here to generate the corresponding assembly code, but all kinds of information passed to the def() function will be saved to the Template instance. In the TemplateTable::def() function, use template_for() or Template_ for_ After the wild() function obtains the corresponding Template instance in the array, it will call the Template::initialize() function to save the information to the corresponding Template instance, so that the corresponding Template instance can be obtained from the array according to the bytecode index, and then the relevant information of the bytecode instruction Template can be obtained.
Although gen will not be called here to generate the machine instruction corresponding to the bytecode instruction, we can take a look at how the pointer function gen generates the corresponding machine instruction for a bytecode instruction in advance.
Take a look at the call to the def() function in the TemplateTable::initialize() function to_ iinc (increase the value of the corresponding slot bit in the local variable table by 1) as an example, call as follows:
def( Bytecodes::_iinc, // Bytecode instruction ubcp|____|clvm|____, // sign vtos, // TosState before template execution vtos, // TosState after template execution iinc , // Template generator is a pointer to iinc() function _ // Template generator parameters are not required );
Set flag bit uses_bcp_bit and calls_vm_bit, indicating that the generator of iinc instruction needs to use BCP pointer function at_bcp(), and the JVM function needs to be called. The definition of the generator is given below:
Source code location: / hotspot/src/cpu/x86/vm/templateTable_x86_64.cpp
void TemplateTable::iinc() {
transition(vtos, vtos);
__ load_signed_byte(rdx, at_bcp(2)); // get constant
locals_index(rbx);
__ addl(iaddress(rbx), rdx);
}
Since the iinc instruction only involves the operation of the local variable table, does not affect the operand stack, and does not need to use the value at the top of the operand stack, the States before and after the top of the stack are vtos and vtos. Calling the transition() function only verifies whether the state of the cache at the top of the stack is correct.
The bytecode format of iinc instruction is as follows:
iinc index // Local variable table index value const // Add const to the slot value corresponding to the index value of the local variable table
The opcode iinc occupies one byte, while index and const occupy one byte respectively. Use at_ The BCP () function obtains the operand of the iinc instruction. 2 indicates an offset of 2 bytes, so const will be taken out and stored in rdx. Call locals_ The index() function takes out index, locales_ Index () is the JVM function. The final compilation is as follows:
// %r13 stores a pointer to the bytecode, offset // After 2 bytes, take const and store it in% edx movsbl 0x2(%r13),%edx // Remove index and store it in% ebx movzbl 0x1(%r13),%ebx neg %rbx // %r14 points to the first address of the local variable table and adds% edx to // %r14+%rbx*8 points to the value stored in the memory // The reason why we want to perform neg symbol inversion on% rbx, // Because on the operating system of the Linux kernel, // The stack grows in the direction of low address add %edx,(%r14,%rbx,8)
The explanation of the notes is very clear, so I won't introduce it too much here.
Chapter 11 - understanding Stub and StubQueue
In Chapter 10 - initializing template tables, we introduced the TemplateInterpreter::initialize() function. In this function, we will call the TemplateTable::initialize() function to initialize the template table, and then use the new keyword to initialize the template defined in the AbstractInterpreter class_ code static attributes, as follows:
static StubQueue* _code;
Because the TemplateInterpreter inherits from AbstractInterpreter, it is initialized in the TemplateInterpreter_ The code attribute is actually defined in the AbstractInterpreter class_ Code attribute.
Initialize in the initialize() function_ The code of the code variable is as follows:
// Interpreter codesize is platform dependent
// Templateinterpreter for_ In x86.hpp
// By definition, 256 * 1024 under 64 bits
int code_size = InterpreterCodeSize;
_code = new StubQueue(
new InterpreterCodeletInterface,
code_size,
NULL,
"Interpreter");
StubQueue is a Stub queue used to save the generated local code. Each element of the queue corresponds to an InterpreterCodelet object. The InterpreterCodelet object inherits from the abstract base class Stub and contains the local code corresponding to bytecode and some debugging and output information. Next, let's introduce the Stub queue class and related classes Stub, InterpreterCodelet class and CodeletMark class.
1. InterpreterCodelet and Stub classes
The Stub class is defined as follows:
class Stub VALUE_OBJ_CLASS_SPEC { ... };
The InterpreterCodelet class inherits from the Stub class. The specific definitions are as follows:
class InterpreterCodelet: public Stub {
private:
int _size; // the size in bytes
const char* _description; // a description of the codelet, for debugging & printing
Bytecodes::Code _bytecode; // associated bytecode if any
public:
// Code info
address code_begin() const {
return (address)this + round_to(sizeof(InterpreterCodelet), CodeEntryAlignment);
}
address code_end() const {
return (address)this + size();
}
int size() const {
return _size;
}
// ...
int code_size() const {
return code_end() - code_begin();
}
// ...
};
The InterpreterCodelet instance is stored in the StubQueue. Each InterpreterCodelet instance represents a piece of machine instruction (including the machine instruction fragment corresponding to the bytecode and some debugging and output information). For example, each bytecode has an InterpreterCodelet instance, so if a bytecode is to be executed during interpretation and execution, The machine instruction fragment represented by the interpreter codelet instance is executed.
Class defines three properties and some functions, and its memory layout is shown in the following figure.
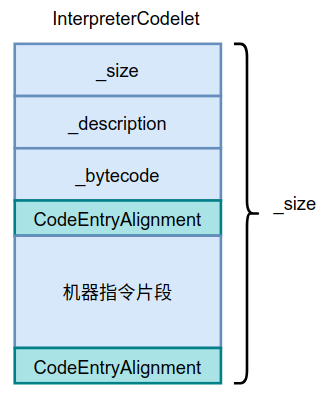
After the alignment to CodeEntryAlignment, the generated object code is immediately followed by the interpreter codelet.
2. StubQueue class
Stub queue is a stub queue used to save the generated local machine instruction fragments. Each element of the queue is an interpreter codelet instance.
The stubbqueue class is defined as follows:
class StubQueue: public CHeapObj<mtCode> {
private:
StubInterface* _stub_interface; // the interface prototype
address _stub_buffer; // where all stubs are stored
int _buffer_size; // the buffer size in bytes
int _buffer_limit; // the (byte) index of the actual buffer limit (_buffer_limit <= _buffer_size)
int _queue_begin; // the (byte) index of the first queue entry (word-aligned)
int _queue_end; // the (byte) index of the first entry after the queue (word-aligned)
int _number_of_stubs; // the number of buffered stubs
bool is_contiguous() const {
return _queue_begin <= _queue_end;
}
int index_of(Stub* s) const {
int i = (address)s - _stub_buffer;
return i;
}
Stub* stub_at(int i) const {
return (Stub*)(_stub_buffer + i);
}
Stub* current_stub() const {
return stub_at(_queue_end);
}
// ...
}
The constructor of this class is as follows:
StubQueue::StubQueue(
StubInterface* stub_interface, // InterpreterCodeletInterface object
int buffer_size, // 256*1024
Mutex* lock,
const char* name) : _mutex(lock)
{
intptr_t size = round_to(buffer_size, 2*BytesPerWord); // BytesPerWord has a value of 8
BufferBlob* blob = BufferBlob::create(name, size); // Create a BufferBlob object in the stubbqueue
_stub_interface = stub_interface;
_buffer_size = blob->content_size();
_buffer_limit = blob->content_size();
_stub_buffer = blob->content_begin();
_queue_begin = 0;
_queue_end = 0;
_number_of_stubs = 0;
}
stub_interface is used to save an instance of InterpreterCodeletInterface type. The InterpreterCodeletInterface class defines the function to operate the Stub to avoid defining virtual functions in the Stub. Each Stub queue has an interpreter codeletinterface, which can be used to operate each Stub instance stored in the Stub queue.
Call the BufferBlob::create() function to allocate memory for the stubbqueue. Here, we need to remember that the memory used by the stubbqueue is allocated through the BufferBlob, that is, the essence of the BufferBlob may be a stubbqueue. Let's introduce the create () function in detail.
BufferBlob* BufferBlob::create(const char* name, int buffer_size) {
// ...
BufferBlob* blob = NULL;
unsigned int size = sizeof(BufferBlob);
// align the size to CodeEntryAlignment
size = align_code_offset(size);
size += round_to(buffer_size, oopSize); // oopSize is the width of a pointer, which is 8 on 64 bits
{
MutexLockerEx mu(CodeCache_lock, Mutex::_no_safepoint_check_flag);
blob = new (size) BufferBlob(name, size);
}
return blob;
}
Allocate memory for BufferBlob through the new keyword. The new overload operator is as follows:
void* BufferBlob::operator new(size_t s, unsigned size, bool is_critical) throw() {
void* p = CodeCache::allocate(size, is_critical);
return p;
}
Allocate memory from codecache. Codecache uses local memory and has its own memory management methods, which will be described in detail later.
The layout structure of stubbqueue is shown in the following figure.

The interpreter codelet in the queue represents a small routine, such as iconst_1 corresponding machine code, invokedynamic corresponding machine code, exception handling corresponding code, and method entry point corresponding code. These codes are interpreter codelets. The whole interpreter is composed of these small code routines. Each small routine completes some functions of the interpreter to realize the whole interpreter.
Chapter 12 - know CodeletMark
Interpreter codelet relies on CodeletMark to complete automatic creation and initialization. CodeletMark inherits from ResourceMark and allows automatic deconstruction. The main operation is to allocate memory and submit it according to the actual machine instruction fragments stored in interpreter codelet. This class is defined as follows:
class CodeletMark: ResourceMark {
private:
InterpreterCodelet* _clet; // InterpreterCodelet inherits from Stub
InterpreterMacroAssembler** _masm;
CodeBuffer _cb;
public:
// Constructor
CodeletMark(
InterpreterMacroAssembler*& masm,
const char* description,
Bytecodes::Code bytecode = Bytecodes::_illegal):
// AbstractInterpreter::code() gets the value of stubbqueue * type, which is obtained by calling the request() method
// Is a value of type Stub *, and the called request() method is implemented in the vm/code/stubs.cpp file
_clet( (InterpreterCodelet*)AbstractInterpreter::code()->request(codelet_size()) ),
_cb(_clet->code_begin(), _clet->code_size())
{
// Initializes the in the InterpreterCodelet_ description and_ bytecode property
_clet->initialize(description, bytecode);
// InterpreterMacroAssembler->MacroAssembler->Assembler->AbstractAssembler
// Initialize the of AbstractAssembler with the value of cb.insts attribute passed in_ code_section and_ oop_ The value of the recorder property
// create assembler for code generation
masm = new InterpreterMacroAssembler(&_cb); // In the constructor, initialization r13 points to bcp and r14 points to the local local variable table
_masm = &masm;
}
// ... omit destructor
};
The constructor mainly completes two tasks:
(1) Initializes a variable of type InterpreterCodelet_ clet. Assign values to 3 attributes in the interpreter codelet instance;
(2) Create an instance of InterpreterMacroAssembler and assign it to masm and_ masm, this instance will write machine instructions to the interpreter codelet instance through CodeBuffer.
In the destructor, the destructor is usually called automatically at the end of the code block. In the destructor, the memory used by the interpreter codelet is committed and the values of related variables are cleaned up.
1. CodeletMark constructor
The CodeletMark constructor allocates memory for the interpreter codelet from the StubQueue and initializes the related variables
In initialization_ When the clet variable is, the AbstractInterpreter::code() method is called to return the name of the AbstractInterpreter class_ The value of the code attribute, which has been initialized in the TemplateInterpreter::initialize() method. Continue to call the request() method in the StubQueue class, passing the required size for storing code. Call codelet_size() function, as follows:
int codelet_size() {
// Request the whole code buffer (minus a little for alignment).
// The commit call below trims it back for each codelet.
int codelet_size = AbstractInterpreter::code()->available_space() - 2*K;
return codelet_size;
}
It should be noted that when creating an InterpreterCodelet, almost all the available memory left in the StubQueue will be allocated to the current InterpreterCodelet instance, which is bound to be a great waste. However, we will submit memory according to the instance size of the InterpreterCodelet instance in the destructor, so we don't have to worry about waste. The main reason for this is to let each interpreter codelet instance be stored continuously in memory. This is a very important application, that is, you can know whether the stack frame is an interpretation stack frame simply through pc judgment, which will be described in detail later.
Allocate memory from the stubbqueue by calling the stubbqueue:: request() function. The function is implemented as follows:
Stub* StubQueue::request(int requested_code_size) {
Stub* s = current_stub();
int x = stub_code_size_to_size(requested_code_size);
int requested_size = round_to( x , CodeEntryAlignment); // CodeEntryAlignment=32
// Compare the memory that needs to be allocated for the new interpreter codelet with the size of the available memory
if (requested_size <= available_space()) {
if (is_contiguous()) { // Judge_ queue_begin is less than or equal to_ queue_end, the function returns true
// Queue: |...|XXXXXXX|.............|
// ^0 ^begin ^end ^size = limit
assert(_buffer_limit == _buffer_size, "buffer must be fully usable");
if (_queue_end + requested_size <= _buffer_size) {
// Code fits in at the end = > nothing to do
CodeStrings strings;
stub_initialize(s, requested_size, strings);
return s; // If it's enough, go straight back
} else {
// stub doesn't fit in at the queue end
// => reduce buffer limit & wrap around
assert(!is_empty(), "just checkin'");
_buffer_limit = _queue_end;
_queue_end = 0;
}
}
}
// ...
return NULL;
}
Through the above function, we can clearly see the logic of how to allocate interpreter codelet memory from StubQueue.
First, calculate the memory size to be allocated from the StubQueue. The related functions called are as follows:
Called stub_ code_ size_ to_ The size() function is implemented as follows:
// Functions defined in the stubbqueue class
int stub_code_size_to_size(int code_size) const {
return _stub_interface->code_size_to_size(code_size);
}
// Functions defined in the InterpreterCodeletInterface class
virtual int code_size_to_size(int code_size) const {
return InterpreterCodelet::code_size_to_size(code_size);
}
// Functions defined in the InterpreterCodelet class
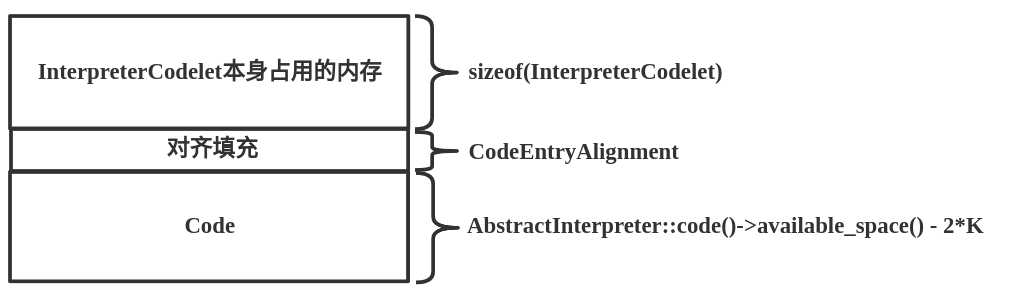
static int code_size_to_size(int code_size) {
// CodeEntryAlignment = 32
// sizeof(InterpreterCodelet) = 32
return round_to(sizeof(InterpreterCodelet), CodeEntryAlignment) + code_size;
}
According to the above method of allocating memory size, the memory structure is as follows:
After calculating the memory size to be allocated from the stubbqueue in the stubbqueue:: request() function, allocate the memory below. The stubbqueue:: request() function only gives the most general case, that is, it is assumed that all InterpreterCodelet instances are from stubbqueue_ stub_ The buffer address is allocated continuously. is_ The continguous() function is used to judge whether the region is continuous. The implementation is as follows:
bool is_contiguous() const {
return _queue_begin <= _queue_end;
}
Available for call_ The space() function obtains the size of the available area of the stubbqueue, which is implemented as follows:
// Methods defined in the stubbqueue class
int available_space() const {
int d = _queue_begin - _queue_end - 1;
return d < 0 ? d + _buffer_size : d;
}
The size obtained by calling the above function is the yellow area in the figure below.

Continue to look at the stub queue:: request() function. When the memory size that can meet the requirements of this interpreter codelet instance is small, stub will be called_ Initialize() function. The implementation of this function is as follows:
// The following operations are performed through the Stub interface
void stub_initialize(Stub* s, int size,CodeStrings& strings) {
// Pass_ stub_interface to operate the Stub, and the initialize() function of s will be called
_stub_interface->initialize(s, size, strings);
}
// Functions defined in the InterpreterCodeletInterface class
virtual void initialize(Stub* self, int size,CodeStrings& strings){
cast(self)->initialize(size, strings);
}
// Functions defined in the InterpreterCodelet class
void initialize(int size,CodeStrings& strings) {
_size = size;
}
We operate stubs through the functions defined in the StubInterface class. As for why we operate stubs through the StubInterface, it is because there are many Stub instances. Therefore, we take the method to avoid wasting memory space by writing virtual functions in stubs (C + + needs to allocate a pointer space to classes containing virtual functions, pointing to the virtual function table).
The above three functions only accomplish one thing in the end, that is, record the allocated memory size in the interpreter codelet_ In the size attribute. The codelet function was introduced earlier_ As mentioned in size (), this value usually leaves a lot of space after storing machine instruction fragments. However, don't worry. The destructor to be introduced below will update this attribute value according to the size of the machine instructions actually generated in the interpreter codelet instance.
2. CodeletMark destructor
The destructor is implemented as follows:
// Destructor
~CodeletMark() {
// Align InterpreterCodelet
(*_masm)->align(wordSize);
// Ensure that all generated machine instruction fragments are stored in the InterpreterCodelet instance
(*_masm)->flush();
// Update the relevant property values of the InterpreterCodelet instance
AbstractInterpreter::code()->commit((*_masm)->code()->pure_insts_size(), (*_masm)->code()->strings());
// Set_ masm, so you can't continue to generate machine instructions to this InterpreterCodelet instance through this value
*_masm = NULL;
}
Call the AbstractInterpreter::code() function to get the stubbqueue. Call (* _masm) - > code () - > pure_ insts_ Size () gets the actual memory required by the machine instruction fragment of the interpreter codelet instance.
The stubbqueue:: commit() function is implemented as follows:
void StubQueue::commit(int committed_code_size, CodeStrings& strings) {
int x = stub_code_size_to_size(committed_code_size);
int committed_size = round_to(x, CodeEntryAlignment);
Stub* s = current_stub();
assert(committed_size <= stub_size(s), "committed size must not exceed requested size");
stub_initialize(s, committed_size, strings);
_queue_end += committed_size;
_number_of_stubs++;
}
Call stub_ The initialize() function passes through the of the InterpreterCodelet instance_ The size property records the actual memory size of the machine instruction fragment in this instance. Also update the of the stubbqueue_ queue_end and_ number_ of_ The value of the stubs property so that memory can continue to be allocated for the next instance of InterpreterCodelet.
Part 13 - storing machine instruction fragments through interpreter codelet
In templateinterpretergenerator:: generate_ Many bytecode instructions and some machine instruction fragments assisted by virtual machines are generated in the all() function. For example, the implementation of generating null pointer exception throwing entry is as follows:
{
CodeletMark cm(_masm, "throw exception entrypoints");
// ...
Interpreter::_throw_NullPointerException_entry = generate_exception_handler("java/lang/NullPointerException",NULL);
// ...
}
Call generate_ exception_ The handler () function generates a code fragment that throws a null pointer.
address generate_exception_handler(const char* name, const char* message) {
return generate_exception_handler_common(name, message, false);
}
Generate called_ exception_ handler_ The common() function is implemented as follows:
address TemplateInterpreterGenerator::generate_exception_handler_common(
const char* name,
const char* message,
bool pass_oop
) {
assert(!pass_oop || message == NULL, "either oop or message but not both");
address entry = __ pc();
if (pass_oop) {
// object is at TOS
__ pop(c_rarg2);
}
// expression stack must be empty before entering the VM if an
// exception happened
__ empty_expression_stack();
// setup parameters
__ lea(c_rarg1, ExternalAddress((address)name));
if (pass_oop) {
__ call_VM(rax,
CAST_FROM_FN_PTR(address,InterpreterRuntime::create_klass_exception),
c_rarg1,c_rarg2);
} else {
// kind of lame ExternalAddress can't take NULL because
// external_word_Relocation will assert.
if (message != NULL) {
__ lea(c_rarg2, ExternalAddress((address)message));
} else {
__ movptr(c_rarg2, NULL_WORD);
}
__ call_VM(rax,
CAST_FROM_FN_PTR(address, InterpreterRuntime::create_exception),
c_rarg1, c_rarg2);
}
// throw exception
__ jump(ExternalAddress(Interpreter::throw_exception_entry()));
return entry;
}
The generated assembly code is as follows:
0x00007fffe10101cb: mov -0x40(%rbp),%rsp 0x00007fffe10101cf: movq $0x0,-0x10(%rbp) 0x00007fffe10101d7: movabs $0x7ffff6e09878,%rsi 0x00007fffe10101e1: movabs $0x0,%rdx 0x00007fffe10101eb: callq 0x00007fffe10101f5 0x00007fffe10101f0: jmpq 0x00007fffe1010288 0x00007fffe10101f5: lea 0x8(%rsp),%rax 0x00007fffe10101fa: mov %r13,-0x38(%rbp) 0x00007fffe10101fe: mov %r15,%rdi 0x00007fffe1010201: mov %rbp,0x200(%r15) 0x00007fffe1010208: mov %rax,0x1f0(%r15) 0x00007fffe101020f: test $0xf,%esp 0x00007fffe1010215: je 0x00007fffe101022d 0x00007fffe101021b: sub $0x8,%rsp 0x00007fffe101021f: callq 0x00007ffff66b3fbc 0x00007fffe1010224: add $0x8,%rsp 0x00007fffe1010228: jmpq 0x00007fffe1010232 0x00007fffe101022d: callq 0x00007ffff66b3fbc 0x00007fffe1010232: movabs $0x0,%r10 0x00007fffe101023c: mov %r10,0x1f0(%r15) 0x00007fffe1010243: movabs $0x0,%r10 0x00007fffe101024d: mov %r10,0x200(%r15) 0x00007fffe1010254: cmpq $0x0,0x8(%r15) 0x00007fffe101025c: je 0x00007fffe1010267 0x00007fffe1010262: jmpq 0x00007fffe1000420 0x00007fffe1010267: mov 0x250(%r15),%rax 0x00007fffe101026e: movabs $0x0,%r10 0x00007fffe1010278: mov %r10,0x250(%r15) 0x00007fffe101027f: mov -0x38(%rbp),%r13 0x00007fffe1010283: mov -0x30(%rbp),%r14 0x00007fffe1010287: retq 0x00007fffe1010288: jmpq 0x00007fffe100f3d3
The point here is not to understand templateinterpretergenerator:: generate_ exception_ handler_ The logic of the common () function and the assembly code generated, but you should clearly know the application of CodeletMark and generate_ exception_ handler_ How the machine instructions generated by the common () function are written to the InterpreterCodelet instance. The InterpreterCodelet and CodeBuffer classes were introduced earlier, as follows:
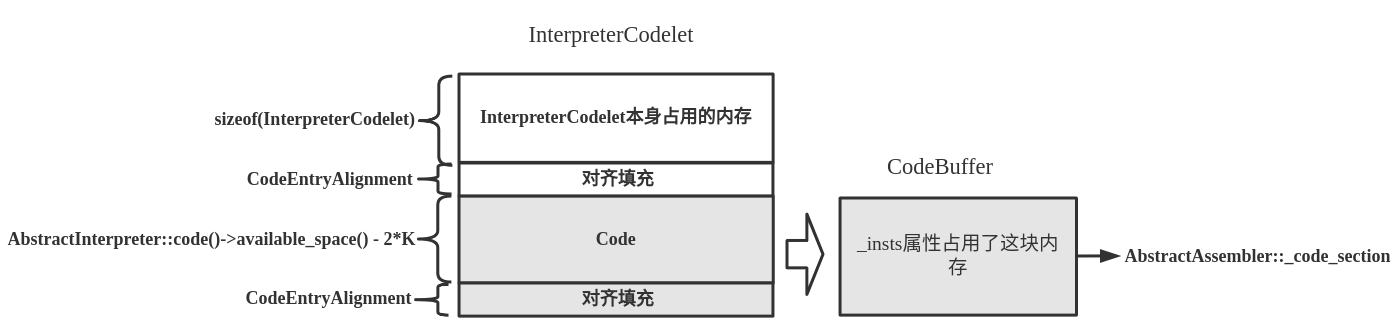
Operate the memory area of the interpreter codelet instance to store machine instruction fragments through CodeBuffer, and the code section in CodeBuffer is assigned to abstractassembler:_ code_section. So we can pass_ code_ The section property writes machine instructions to the interpreter codelet instance.
Passed in to CodeletMark_ The mask parameter is defined in the AbstractInterpreterGenerator class, as follows:
class AbstractInterpreterGenerator: public StackObj {
protected:
InterpreterMacroAssembler* _masm;
// ...
}
generate_ exception_ handler_ In the common() function__ Is a macro defined as follows:
#define __ _masm->
In fact, this is to call the relevant functions in the InterpreterMacroAssembler class to write machine instructions, such as
__ pop(c_rarg2);
The called pop() function is as follows:
// Defined in InterpreterMacroAssembler
void pop(Register r ) {
((MacroAssembler*)this)->pop(r);
}
// Defined in the Assembler class
void Assembler::pop(Register dst) {
int encode = prefix_and_encode(dst->encoding());
emit_int8(0x58 | encode);
}
// Defined in AbstractAssembler class
void emit_int8( int8_t x) {
code_section()->emit_int8( x);
}
code_ The section () function obtains the of AbstractAssembler_ code_ The value of the section property.
Chapter 14 - generating important routines
The TemplateInterpreter::initialize() function was introduced earlier. In this function, the template table and StubQueue instance are initialized. The InterpreterGenerator instance is created in the following way:
InterpreterGenerator g(_code);
Generate is called when the InterpreterGenerator instance is created_ All() function, as follows:
InterpreterGenerator::InterpreterGenerator(StubQueue* code)
: TemplateInterpreterGenerator(code) {
generate_all();
}
In generate_ Various routines (machine instruction fragments) are generated in the all() function and stored in the interpreter codelet instance. In the HotSpot VM, there are not only routines corresponding to bytecode, but also many routines supporting the virtual machine runtime, such as the common method entry described earlier_ Point routine, exception handling routine, etc. These routines are stored in the stubbqueue, as shown in the following figure.
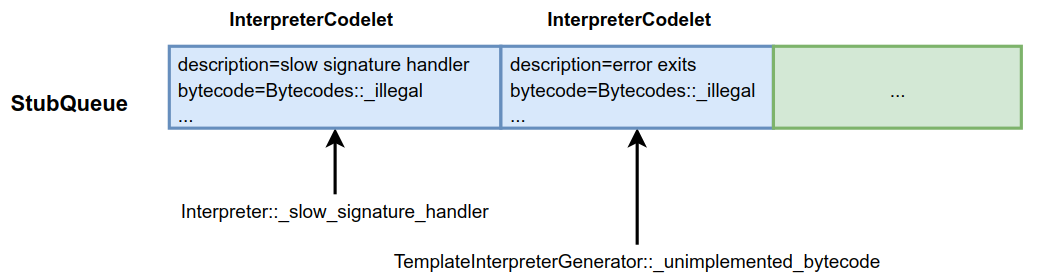
Some important routines generated are shown in the following table.

Among them, the entry of non local methods, the entry of local methods and the entry of bytecode are more important, which is also the focus of our later introduction. This article introduces the entry of non local methods and bytecode. The entry of local methods will be introduced in detail when introducing local methods, but not much here.
1. Non local method entry
When we introduced creating Java stack frames for non-native common methods, we mentioned that the main non-native method entries are as follows:
enum MethodKind {
zerolocals, // Common method
zerolocals_synchronized, // Common synchronization methods
...
}
In generate_ The entry logic for generating common methods and common synchronization methods in the all() function is as follows:
{
CodeletMark cm(_masm, "method entry point (kind = " "zerolocals" ")");
Interpreter::_entry_table[Interpreter::zerolocals] = generate_method_entry(Interpreter::zerolocals);
}
{
CodeletMark cm(_masm, "method entry point (kind = " "zerolocals_synchronized" ")");
Interpreter::_entry_table[Interpreter::zerolocals_synchronized] = generate_method_entry(Interpreter::zerolocals_synchronized);
}
Generate called_ method_ The entry() function has been described in detail in Chapter 6. Finally, it will generate a routine for creating Java stack frames, and store the first address of the routine in the Interpreter::_entry_table array.
The stack frame establishment and special logic processing of synchronization method will be introduced in detail when introducing lock related knowledge, not too much here.
In addition to ordinary methods, some special entry addresses are generated for some methods, such as routines generated for methods such as java.lang.Math.sin(), java.lang.Math.cos(). If you are interested, you can study it yourself. I won't introduce it in detail here.
2. Bytecode entry
In generate_ Set is called in the all() function_ entry_ points_ for_ all_ Bytes() function, which generates routines for all defined bytecodes and saves entries through corresponding properties. These entries point to the first address of the routine. set_ entry_ points_ for_ all_ The bytes() function is implemented as follows:
void TemplateInterpreterGenerator::set_entry_points_for_all_bytes() {
for (int i = 0; i < DispatchTable::length; i++) {
Bytecodes::Code code = (Bytecodes::Code)i;
if (Bytecodes::is_defined(code)) {
set_entry_points(code);
} else {
set_unimplemented(i);
}
}
}
When code is a bytecode instruction defined in the Java virtual machine specification, set is called_ entry_ Points() function, which takes out the template template corresponding to the bytecode instruction and calls set_ short_ enrty_ The points() function performs processing and saves the entry address in the DispatchTable_ normal_table or_ wentry_table (using the wide instruction). Template template has been introduced before. Bytecode instructions correspond to a template, and the template stores the information required in the bytecode instruction generation corresponding code routine.
set_ entry_ The points() function is implemented as follows:
void TemplateInterpreterGenerator::set_entry_points(Bytecodes::Code code) {
CodeletMark cm(_masm, Bytecodes::name(code), code);
address bep = _illegal_bytecode_sequence;
address cep = _illegal_bytecode_sequence;
address sep = _illegal_bytecode_sequence;
address aep = _illegal_bytecode_sequence;
address iep = _illegal_bytecode_sequence;
address lep = _illegal_bytecode_sequence;
address fep = _illegal_bytecode_sequence;
address dep = _illegal_bytecode_sequence;
address vep = _unimplemented_bytecode;
address wep = _unimplemented_bytecode;
// Handle non wide instructions. Note that it refers to bytecode instructions that cannot be preceded by wide instructions
if (Bytecodes::is_defined(code)) {
Template* t = TemplateTable::template_for(code);
set_short_entry_points(t, bep, cep, sep, aep, iep, lep, fep, dep, vep);
}
// Handle wide instructions. Note that it refers to bytecode instructions that can be preceded by wide instructions
if (Bytecodes::wide_is_defined(code)) {
Template* t = TemplateTable::template_for_wide(code);
set_wide_entry_point(t, wep);
}
// When it is a non wide instruction, there are 9 entries in total. When it is a wide instruction, there is only one entry
EntryPoint entry(bep, cep, sep, aep, iep, lep, fep, dep, vep);
Interpreter::_normal_table.set_entry(code, entry);
Interpreter::_wentry_point[code] = wep;
}
Note that a variable cm is created when the function is declared at the beginning. At this time, the CodeletMark constructor will be called to create the InterpreterCodelet instance storing machine fragments in the StubQueue, so the templateinterpretergenerator:: set is called_ short_ entry_ The machine instructions generated by functions such as points () will be written to this instance. When the function is executed, the CodeletMark destructor commits the memory used and resets the related attribute values.
The next step is to assign an initial value to the variable representing the top of stack caching (TOSCA, for short) state, where_ illegal_bytecode_sequence and_ unimplemented_ The bytecode variable also points to the entry address of specific routines, which are generated in generate_ Generated in the all() function. If you are interested, you can study how these routines deal with illegal bytecode.
Call set_ short_ entry_ When using the points() function, you need to pass in the cache state at the top of the stack, that is, the results generated may be stored in the register during the execution of the last bytecode. The use of stack top cache is mainly to improve the efficiency of interpretation execution. HotSpot VM defines nine tosstates, which are represented by enumeration constants, as follows:
enum TosState { // describes the tos cache contents
btos = 0, // byte, bool tos cached
ctos = 1, // char tos cached
stos = 2, // short tos cached
itos = 3, // int tos cached
ltos = 4, // long tos cached
ftos = 5, // float tos cached
dtos = 6, // double tos cached
atos = 7, // object cached
vtos = 8, // tos not cached
number_of_states,
ilgl // illegal state: should not occur
};
Taking the non wide instruction as an example, bep(byte entry point), cep, sep, aep, iep, lep, fep, dep and vep respectively represent the entry address when the state of the top element of the stack before the instruction is executed is byte/boolean, char, short, array / reference, int, long, float, double and void. For example, iconst_0 means that the constant 0 is pushed into the stack, so the bytecode instruction template has the following definitions:
def(Bytecodes::_iconst_0 , ____|____|____|____, vtos, itos, iconst,0);
The third parameter indicates tos_in, the fourth parameter is tos_out,tos_in and tos_out is the TosState before and after the instruction is executed. That is, it is not necessary to obtain the value of the stack top cache before executing this bytecode instruction, so it is void; After execution, the top of the stack will cache an integer of type int, that is, 0. The cache is usually cached in the register, so it is more efficient than pushing it into the stack. If the next bytecode instruction does not need to be executed, the cached 0 value needs to be pushed into the stack. Assuming that the bytecode to be executed next is iconst, it should be executed from the iep (the last cached int type integer 0) entry of iconst instruction. Since the entry of iconst is required to be vtos, it is necessary to stack the int type value 0 in the register. Therefore, each bytecode instruction will have multiple entries, so that after the execution of any bytecode instruction is completed, the corresponding entry of the next bytecode to be executed can be found according to the cache state at the top of the stack after the current execution.
Let's go back to the content related to distributing bytecode introduced in Chapter 8, and set the function DispatchTable:: set for each bytecode entry_ Entry(), where_ The one dimension of table is the stack top cache state and the two dimensions are Opcode. Through these two dimensions, you can find a piece of machine instruction, which is the routine to be executed for the bytecode located according to the current stack top cache state. Let's take a look at templateinterpretergenerator:: set_ entry_ The points() function will finally call DispatchTable:: set_ The entry() function is_ Assignment of table attribute. Such a templateinterpreter of type DispatchTable:_ normal_ Table and templateinterpreter:_ wentry_ Point variable can complete bytecode distribution.
Call templatetable:: template_ The for() function can be from TemplateTable::_template_table array to get the corresponding Template instance, and then call set_ short_ entry_ The points() function generates a routine. Non wild instruction calls set_short_entry_points() function, set_ short_ entry_ The points() function is implemented as follows:
void TemplateInterpreterGenerator::set_short_entry_points(
Template* t,
address& bep, address& cep, address& sep, address& aep, address& iep,
address& lep, address& fep, address& dep, address& vep
) {
switch (t->tos_in()) {
case btos:
case ctos:
case stos:
ShouldNotReachHere();
break;
case atos: vep = __ pc(); __ pop(atos); aep = __ pc(); generate_and_dispatch(t); break;
case itos: vep = __ pc(); __ pop(itos); iep = __ pc(); generate_and_dispatch(t); break;
case ltos: vep = __ pc(); __ pop(ltos); lep = __ pc(); generate_and_dispatch(t); break;
case ftos: vep = __ pc(); __ pop(ftos); fep = __ pc(); generate_and_dispatch(t); break;
case dtos: vep = __ pc(); __ pop(dtos); dep = __ pc(); generate_and_dispatch(t); break;
case vtos: set_vtos_entry_points(t, bep, cep, sep, aep, iep, lep, fep, dep, vep); break;
default : ShouldNotReachHere(); break;
}
}
set_ short_ entry_ The points() function will generate up to 9 stack top entries according to the bytecode Template information saved in the Template instance and assign them to the incoming parameters bep, cep, etc., that is, generate the corresponding entry address for the specific bytecode instruction represented by the Template.
set_ short_ entry_ The points () function judges according to the type of the top element of the operand stack. First, byte, char and short types should be treated as int types, so these types of entry addresses will not be generated for bytecode instructions; If the current bytecode requires a stack top element before execution and the type is atos object type, when there is no stack top cache, enter from the vep entry, and then pop up the object in the expression stack to the stack top cache register. You can directly enter from aep. itos, ltos, ftos and dtos are similar and will become two entry addresses respectively; If the top of stack element is not required, it is vtos, and the non void type will call generate_ and_ The dispatch () function generates various entries.
set_ vtos_ entry_ The points() function is implemented as follows:
void TemplateInterpreterGenerator::set_vtos_entry_points(
Template* t,
address& bep,
address& cep,
address& sep,
address& aep,
address& iep,
address& lep,
address& fep,
address& dep,
address& vep) {
Label L;
aep = __ pc(); __ push_ptr(); __ jmp(L);
fep = __ pc(); __ push_f(); __ jmp(L);
dep = __ pc(); __ push_d(); __ jmp(L);
lep = __ pc(); __ push_l(); __ jmp(L);
bep = cep = sep =
iep = __ pc(); __ push_i();
vep = __ pc();
__ bind(L);
generate_and_dispatch(t);
}
If the bytecode does not require stack top cache (i.e. vtos state), 9 entry addresses will be generated for the current bytecode and saved by bep, cep, etc. For example, when generating the aep entry, because the currently executed bytecode stack does not need the top cache state, it is necessary to push the value into the expression stack, and then jump to L for execution, that is, it is equivalent to entering execution from the vep entry.
Now let's briefly sort out which entry the last bytecode instruction enters into the next bytecode instruction from. It depends on the execution result of the last bytecode instruction. If the result of the last bytecode instruction execution is fep, and the stack top cache state before the current bytecode instruction execution is required to be VTOs, start from templateinterpretergenerator:: set_ vtos_ entry_ The execution starts at the place where the fep is assigned in the points() function. Therefore, the execution result of the last bytecode instruction and the stack top cache state required before the execution of the next bytecode instruction jointly determine which entry to enter from.
push_ The implementation of F () function is as follows:
Source code location: / hotspot/src/cpu/x86/vm/interp_masm_x86_64.cpp
void InterpreterMacroAssembler::push_f(XMMRegister r) { // The default value of r is xmm0
subptr(rsp, wordSize); // wordSize is the machine word length and 8 bytes under 64 bits, so the value is 8
movflt(Address(rsp, 0), r);
}
void MacroAssembler::subptr(Register dst, int32_t imm32) {
LP64_ONLY(subq(dst, imm32)) NOT_LP64(subl(dst, imm32));
}
void Assembler::subq(Register dst, int32_t imm32) {
(void) prefixq_and_encode(dst->encoding());
emit_arith(0x81, 0xE8, dst, imm32);
}
void Assembler::emit_arith(int op1, int op2, Register dst, int32_t imm32) {
assert(isByte(op1) && isByte(op2), "wrong opcode");
assert((op1 & 0x01) == 1, "should be 32bit operation");
assert((op1 & 0x02) == 0, "sign-extension bit should not be set");
if (is8bit(imm32)) {
emit_int8(op1 | 0x02); // set sign bit
emit_int8(op2 | encode(dst));
emit_int8(imm32 & 0xFF);
} else {
emit_int8(op1);
emit_int8(op2 | encode(dst));
emit_int32(imm32);
}
}
Call emit_arith(),emit_int8() and other functions generate machine instruction fragments, and the generated contents will finally be stored in the interpreter codelet instance of StubQueue. Machine instructions and generation stored procedures have been introduced before, and will not be introduced here.
set_ vtos_ entry_ The machine instruction fragment generated by the points() function is decompiled and the corresponding assembly code is as follows:
// Entrance to aep
push %rax
jmpq L
// fep inlet
sub $0x8,%rsp
movss %xmm0,(%rsp)
jmpq L
// dep inlet
sub $0x10,%rsp
movsd %xmm0,(%rsp)
jmpq L
// lep entrance
sub $0x10,%rsp
mov %rax,(%rsp)
jmpq L
// iep entrance
push %rax
// ---- L ----
set_ vtos_ entry_ The points () function finally calls generate_. and_ The dispatch() function writes the machine instruction fragment corresponding to the current bytecode instruction and jumps to the logical processing part of the next bytecode instruction.
generate_ and_ The main implementation of the dispatch() function is as follows:
void TemplateInterpreterGenerator::generate_and_dispatch(Template* t, TosState tos_out) {
// Generates the machine instruction fragment corresponding to the current bytecode instruction
t->generate(_masm);
if (t->does_dispatch()) {
// asserts
} else {
// Generate logic to distribute to the next bytecode instruction
__ dispatch_epilog(tos_out, step);
}
}
Here, take iconst bytecode as an example to analyze the implementation of generate() function:
void Template::generate(InterpreterMacroAssembler* masm) {
// parameter passing
TemplateTable::_desc = this;
TemplateTable::_masm = masm;
// code generation
_gen(_arg);
masm->flush();
}
The generate() function calls the generator function_ gen(_arg). For the iconst instruction, the generator function is iconst(). The generate() function varies according to the platform, such as x86_64 platform, as defined below:
Source code location: / hotspot/src/cpu/x86/vm/templateTable_x86_64.cpp
void TemplateTable::iconst(int value) {
if (value == 0) {
__ xorl(rax, rax);
} else {
__ movl(rax, value);
}
}
We know, iconst_ The i instruction is to push i onto the stack. When i is 0, the generator function iconst() does not directly write 0 to rax, but uses the XOR operation to clear, that is, write the instructions "XOR% rax,% rax" to the code buffer; When i is not 0, write instruction "mov $0xi,% rax"
When forwarding is not required, it will be displayed in templateinterpretergenerator:: generate_ and_ Call dispatch_ in dispatch () function Epilog() function generates the object code to remove an instruction and dispatch:
void InterpreterMacroAssembler::dispatch_epilog(TosState state, int step) {
dispatch_next(state, step);
}
dispatch_ The next() function is implemented as follows:
void InterpreterMacroAssembler::dispatch_next(TosState state, int step) {
// load next bytecode (load before advancing r13 to prevent AGI)
load_unsigned_byte(rbx, Address(r13, step));
// advance r13
increment(r13, step);
dispatch_base(state, Interpreter::dispatch_table(state));
}
This function has been introduced before and will not be introduced here.
Chapter 15 - interpreter and interpreter generator
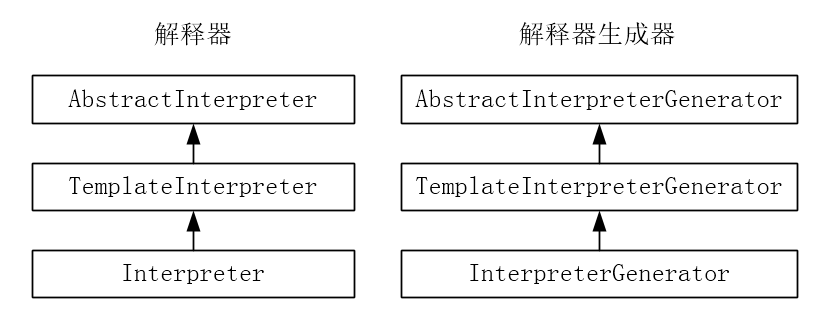
Method interpretation needs the support of interpreter and interpreter generator. The inheritance system of interpreter and interpreter generator is as follows:
The interpreter and interpreter generator are described in detail below.
1. Interpreter
The interpreter is constructed by a pile of local code routines. These routines will be written to the StubQueue when the virtual machine is started. Later, when interpreting and executing, you only need to enter the specified routine.
The inheritance system of the interpreter is as follows:
AbstractInterpreter /interpreter/abstractInterpreter.hpp
CppInterpreter
TemplateInterpreter /interpreter/templateInterpreter.hpp
Interpreter /interpreter/templateInterpreter.hpp
The Interpreter can inherit from CppInterpreter or TemplateInterpreter through macros. The former is called C + + Interpreter. Each bytecode instruction corresponds to a piece of C + + code and processes bytecode through switch. The latter is called template Interpreter. Each instruction corresponds to a piece of machine instruction fragment and processes bytecode through instruction template, HotSpot VM uses the template Interpreter by default.
(1) Abstract interpreter
All interpreters inherit from the abstract interpreter. The definitions of classes and important attributes are as follows:
class AbstractInterpreter{
StubQueue* _code
address _entry_table[n];
// ...
};
_ The code attribute has been described earlier. This is a queue. The interpreter codelet in the queue represents a routine, such as iconst_1 corresponding code, invokedynamic corresponding code, exception handling corresponding code, and method entry point corresponding code. These codes are interpreter codelets. The whole interpreter is composed of these routines. Each routine completes some functions of the interpreter to realize the whole interpreter.
_ entry_ The table array will save the method entry point. For example, the entry point of an ordinary method is_ entry_table [0]. The entry point of the common synchronization method is_ entry_table[1], these_ entry_table[0],_ entry_table[1] refers to the previous_ The routine in the code queue. These logic are generated_ Completed in the all() function, as follows:
void TemplateInterpreterGenerator::generate_all() {
// ...
method_entry(zerolocals)
method_entry(zerolocals_synchronized)
method_entry(empty)
method_entry(accessor)
method_entry(abstract)
method_entry(java_lang_math_sin )
method_entry(java_lang_math_cos )
method_entry(java_lang_math_tan )
method_entry(java_lang_math_abs )
method_entry(java_lang_math_sqrt )
method_entry(java_lang_math_log )
method_entry(java_lang_math_log10)
method_entry(java_lang_math_exp )
method_entry(java_lang_math_pow )
method_entry(java_lang_ref_reference_get)
// ...
}
method_ The entry macro is defined as follows:
#define method_entry(kind) \
{ \
CodeletMark cm(_masm, "method entry point (kind = " #kind ")"); \
Interpreter::_entry_table[Interpreter::kind] = generate_method_entry(Interpreter::kind); \
}
As you can see, call generate_ method_ The entry () function returns the entry address corresponding to the routine and saves it to the entry defined in the AbstractInterpreter class_ entry_table array. Call generate_ method_ The parameter passed in by the entry () function is an enumeration constant, which represents some special methods and some common method types.
(2) Template interpreter
The template interpreter class is defined as follows:
class TemplateInterpreter: public AbstractInterpreter {
protected:
// Array out of bounds exception routine
static address _throw_ArrayIndexOutOfBoundsException_entry;
// Array storage exception routine
static address _throw_ArrayStoreException_entry;
// Arithmetic exception routine
static address _throw_ArithmeticException_entry;
// Type conversion exception routine
static address _throw_ClassCastException_entry;
// Null pointer exception routine
static address _throw_NullPointerException_entry;
// Throw exception common routine
static address _throw_exception_entry;
// ...
}
The abstract interpreter defines the necessary routines, and the specific interpreter also has its own ad hoc routines. The template interpreter is an example. It inherits from the abstract interpreter and has its own ad hoc routines on top of those routines. For example, some properties defined above save the entry routines in case of program exceptions. In fact, there are many fields or arrays defined to save the routine entry, which will not be introduced here.
(3) Interpreter
Class is defined as follows:
class Interpreter: public CC_INTERP_ONLY(CppInterpreter) NOT_CC_INTERP(TemplateInterpreter) {
// ...
}
There are no new properties defined, only a few functions. Interpreter inherits TemplateInterpreter by default through macro extension.
2. Interpreter generator
To get a runnable interpreter, you also need an interpreter generator. The interpreter generator could have completed the filling work alone, perhaps for decoupling or clear structure. HotSpot VM extracts the bytecode routines and puts them into the TemplateTable template table. It assists the template interpreter generator templateInterpreterGenerator to generate various routines.
The inheritance system of interpreter generator is as follows:
AbstractInterpreterGenerator /interpreter/abstractInterpreter.hpp
TemplateInterpreterGenerator /interpreter/templateInterpreter.hpp
InterpreterGenerator /interpreter/interpreter.hpp
The template interpreter generator extends the abstract interpreter generator. The interpreter generator and the interpreter actually have a corresponding relationship in a sense. For example, some functions are defined in the abstract interpreter generator, and calling these functions will initialize the properties in the abstract interpreter, such as saving the routine_ entry_table array, etc. the functions defined in the template interpreter generator will initialize some properties defined in the template interpreter, such as_ throw_ArrayIndexOutOfBoundsException_entry et al. The null pointer routine described earlier is generated in the TemplateInterpreterGenerator class_ Generated in the all() function. As follows:
{
CodeletMark cm(_masm, "throw exception entrypoints");
// ...
Interpreter::_throw_NullPointerException_entry = generate_exception_handler("java/lang/NullPointerException",NULL);
// ...
}
There will be no more introduction to the interpreter generator.
Here, we need to remind that some functions defined in the Interpreter and Interpreter generator are platform independent in the implementation process, so they will be implemented in the file under the / Interpreter folder. For example, the Interpreter and InterpreterGenerator classes are defined in the / Interpreter folder, and the defined functions will be implemented in the interpreter.cpp file in the / Interpreter folder. However, some functions are specific to a specific platform. We only discuss the 64 bit implementation of linux in x86 architecture, so there is also an Interpreter in the cpu/x86/vm folder_ X86.hpp and interpreter_x86_64.cpp and other files, you only need to include the Interpreter when defining the Interpreter class_ X86.hpp file is enough.
Chapter 16 - assemblers in virtual machines
The inheritance system of the assembler is as follows:
For the relevant assembly interface provided for the parser, each bytecode instruction will be associated with a generator function, and the generator function will call the assembler to generate machine instruction fragments. For example, when generating routines for iload bytecode instructions, the called generation function is TemplateTable::iload(int n). The implementation of this function is as follows:
Source code location: hotspot/src/cpu/x86/vm/templateTable_x86_64.cpp
void TemplateTable::iload() {
transition(vtos, itos);
...
// Get the local value into tos
locals_index(rbx);
__ movl(rax, iaddress(rbx)); // iaddress(rb) is the source operand and rax is the destination operand
}
Function call__ The movl (rax, iadress (RBX)) function generates the corresponding machine instruction. The generated machine instruction is mov reg,operand, where__ Is a macro, defined as follows:
Source code location: hotspot/src/cpu/x86/vm/templateTable_x86_64.cpp
#define __ _masm->
_ The masm variable is defined as follows:
Source code location: hotspot/src/share/vm/interpreter/abstractInterpreter.hpp
class AbstractInterpreterGenerator: public StackObj {
protected:
InterpreterMacroAssembler* _masm;
...
}
Finally_ The mask is instantiated as the interptermacroassembler type.
The implementation of calling movl() function on x86 64 bit platform is as follows:
Source code location: hotspot/src/cpu/x86/vm/assembler_86.cpp
void Assembler::movl(Register dst, Address src) {
InstructionMark im(this);
prefix(src, dst);
emit_int8((unsigned char)0x8B);
emit_operand(dst, src);
}
Call prefix(), emit_ When int8() and other functions are defined in the assembler, these functions will pass abstractassembler::_ code_ The section attribute writes machine instructions to the interpreter codelet instance. This content has been introduced before and will not be introduced here.
1. AbstractAssembler class
The AbstractAssembler class defines the abstract public basic functions for generating assembly code, such as the pc() function for obtaining the current memory location of the associated CodeBuffer, flushing all machine instructions to the flush() function in the InterpreterCodelet instance, and the bind() function for binding jump labels. AbstractAssembler class is defined as follows:
Source code location: hotspot/src/share/vm/asm/assembler.hpp
// The Abstract Assembler: Pure assembler doing NO optimizations on the
// instruction level; i.e., what you write is what you get.
// The Assembler is generating code into a CodeBuffer.
class AbstractAssembler : public ResourceObj {
friend class Label;
protected:
CodeSection* _code_section; // section within the code buffer
OopRecorder* _oop_recorder; // support for relocInfo::oop_type
...
void emit_int8(int8_t x) {
code_section()->emit_int8(x);
}
void emit_int16(int16_t x) {
code_section()->emit_int16(x);
}
void emit_int32(int32_t x) {
code_section()->emit_int32(x);
}
void emit_int64(int64_t x) {
code_section()->emit_int64(x);
}
void emit_float( jfloat x) {
code_section()->emit_float(x);
}
void emit_double( jdouble x) {
code_section()->emit_double(x);
}
void emit_address(address x) {
code_section()->emit_address(x);
}
...
}
The assembler generates the machine instruction sequence and stores the generated instruction sequence in the cache_ code_begin points to the first address of the cache_ code_pos points to the current writable location of the cache.
The assembler provides the basic functions for writing machine instructions. These functions can easily write 8-bit, 16 bit, 32-bit and 64 bit data or instructions. The business processed in this assembler does not depend on a specific platform.
2. Assembler class
In addition to the AbstractAssembler class, the assembly.hpp file also defines the label label class used by the jmp jump instruction. After calling the bind() function, the current label instance will be bound to a specific location in the instruction flow. For example, when the jmp instruction receives the label parameter, it will jump to the corresponding location and start execution, which can be used to realize control flow operations such as loop or condition judgment.
The definition of Assembler is related to the CPU architecture. The macro in the assembler.hpp file contains the Assembler implementation under a specific CPU, as follows:
Source code location: hotspot/src/share/vm/asm/assembler.hpp
#ifdef TARGET_ARCH_x86 # include "assembler_x86.hpp" #endif
The Assembler class adds CPU architecture specific instruction implementation and instruction operation related enumerations. It is defined as follows:
Source code location: hotspot/src/cpu/x86/vm/assembler_x86.hpp
// The Intel x86/Amd64 Assembler: Pure assembler doing NO optimizations on the instruction
// level (e.g. mov rax, 0 is not translated into xor rax, rax!); i.e., what you write
// is what you get. The Assembler is generating code into a CodeBuffer.
class Assembler : public AbstractAssembler {
...
}
Many functions provided are basically the implementation of a single machine instruction. For example, the implementation of a movl() function is as follows:
void Assembler::movl(Register dst, Address src) {
InstructionMark im(this);
prefix(src, dst);
emit_int8((unsigned char)0x8B);
emit_operand(dst, src);
}
The subq() function is implemented as follows:
void Assembler::subq(Register dst, int32_t imm32) {
(void) prefixq_and_encode(dst->encoding());
emit_arith(0x81, 0xE8, dst, imm32);
}
The above function will call emit_arith() function, as follows:
void Assembler::emit_arith(int op1, int op2, Register dst, int32_t imm32) {
assert(isByte(op1) && isByte(op2), "wrong opcode");
assert((op1 & 0x01) == 1, "should be 32bit operation");
assert((op1 & 0x02) == 0, "sign-extension bit should not be set");
if (is8bit(imm32)) {
emit_int8(op1 | 0x02); // set sign bit
emit_int8(op2 | encode(dst));
emit_int8(imm32 & 0xFF);
} else {
emit_int8(op1);
emit_int8(op2 | encode(dst));
emit_int32(imm32);
}
}
Call emit_int8() or emit_ Functions such as int32 () write machine instructions. The last instruction written is as follows:
83 EC 08
Since 8 can be represented by an 8-bit signed number, the first byte is 0x81 | 0x02, i.e. 0x83, the register number of rsp is 4, the second byte is 0xE8 | 0x04, i.e. 0xEC, and the third byte is 0x08 & 0xff, i.e. 0x08. This instruction is at & T style sub sub $0x8,% rsp.x8,%rsp.
I won't interpret emit in the assembler in detail here_ The implementation logic of arith () and other functions. If these functions do not understand the machine instruction coding, it is difficult to understand their implementation process. After introducing the machine instruction coding format according to the Intel manual, we will select several typical implementations for interpretation.
3. MacroAssembler class
The MacroAssembler class inherits from the Assembler class and mainly adds some common assembly instruction support. Class is defined as follows:
Source code location: hotspot/src/cpu/x86/vm/macroAssembler_x86.hpp
// MacroAssembler extends Assembler by frequently used macros.
//
// Instructions for which a 'better' code sequence exists depending
// on arguments should also go in here.
class MacroAssembler: public Assembler {
...
}
The functions in this class are completed by calling some functions defined in the MacroAssembler class or Assembler class. It can be regarded as completing some functions convenient for business code operation through the combination of machine instructions.
According to the parameters passed by some methods, it can support data type level operations within the JVM.
For example, when a machine instruction performs an addition operation, it is not allowed that both operands are memory operands at the same time, or one is from memory and the other is from an immediate number, but such a function is provided in the MacroAssembler assembler.
4. InterpreterMacroAssembler class
In the templateTable.hpp file, the files to be imported have been determined according to the platform, as follows:
#ifdef TARGET_ARCH_x86 # include "interp_masm_x86.hpp" #endif
In interp_ masm_ The InterpreterMacroAssembler class is defined in the x86.hpp file, as follows:
Source code location: hotspot/src/cpu/x86/vm/interp_masm_x86.hpp
// This file specializes the assember with interpreter-specific macros
class InterpreterMacroAssembler: public MacroAssembler {
...
#ifdef TARGET_ARCH_MODEL_x86_64
# include "interp_masm_x86_64.hpp"
#endif
...
}
For 64 bit platforms, interp is introduced_ masm_ x86_ 64.hpp file.
In interp_masm_x86_64.cpp file defines the following functions:
(1)InterpreterMacroAssembler::lock_object()
(2)InterpreterMacroAssembler::unlock_object()
(3)InterpreterMacroAssembler::remove_activation()
(4)InterpreterMacroAssembler::dispatch_next()
Dispatch among them_ You should be familiar with the next () function. This function, introduced earlier, generates routines for distributing bytecode instructions; lock_object() and unlock_object() generates corresponding routines for loading and releasing locks under the condition of explanation and execution. It will be described in detail later when introducing lock related knowledge; remove_ The activation () function means to remove the corresponding stack frame. For example, when an exception is encountered, if the current method cannot handle the exception, the stack needs to be destructively expanded, and the corresponding stack frame needs to be removed during the expansion process.
The official account [in-depth analysis of Java virtual machine HotSpot] has updated the VM source code to analyze 60+ articles. Welcome to be concerned. If there are any problems, add WeChat mazhimazh to pull you into virtual cluster communication.
