1, Hive's architecture design and SQL statement review summary
1.1. Data warehouse
The definition put forward by Bill Inmon, the father of data warehouse, in his book "Building the Data Warehouse" published in 1991 is widely accepted. (DW for short) (DM)
-
Data Warehouse is a Subject Oriented, Integrated, non volatile and Time Variant data set used to support decision making support.
-
Subject Oriented: organize data by topic (multiple fact tables + multiple dimension tables)
-
Integrated: the data is placed in a non volatile data warehouse according to the theme: it will not change basically and will be fixed at birth. Therefore, there is no need for update and delete in the data warehouse to reflect the historical change: historical data, and each record represents a fact at a certain time in the past
-
Value of data warehouse: used to support decision making support.
-
Manage data of multiple different topics: a topic can be understood as a table or a class of closely related tables
-
Data warehouse: store data, regardless of the format of the data, read mode data storage system.
-
Relatively stable: Generally speaking, the data stored in Hive is log data that will not be modified
-
Support management decision-making: the results of query analysis are of great value
-
Data warehouse: for data, historical data, standardized structural data and text data, query and analysis, and support the select syntax in SQL!
1.2. Hive concept
Explanation on the official website: http://hive.apache.org
1. Hive from Facebook Implement and open source(google, yahoo),hive yes facebook(mapreuce Low development efficiency) 2. Hive Is based on Hadoop A data warehouse tool 3. Hive The stored data is actually stored at the bottom HDFS upper 4. Hive take HDFS The structured data on is mapped to a database table, similar to excel perhaps msyql Table of 5. Hive provide HQL(Hive SQL)Query function 6. Hive The essence of is to SQL Statement to MapReduce Task running makes unfamiliar MapReduce It is convenient for users to use HQL Processing and calculation HDFS Structured data on, suitable for offline batch data calculation (improving development efficiency) 7. Hive Users can greatly simplify the writing of distributed computing programs and focus on business logic
summary
Hive relies on HDFS to store data. Hive converts HQL into MapReduce for execution. Therefore, hive is a data warehouse tool based on Hadoop. In essence, it is a MapReduce computing framework based on HDFS to analyze and manage the data stored in HDFS.
1.3 hive architecture
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-Tfm4FJ70-1633923115698)(assets/image-20210818122452585.png)]
Hive has four internal components: Driver, Compiler, Optimizer, and Executor
The Driver component completes the generation of HQL query statements from lexical analysis, syntax analysis, compilation, optimization, and logical execution plan. The generated logical execution plan is stored in HDFS and then called and executed by MapReduce.
1.3. Metadata
Metadata in HDFS: (storage of large files: decentralized storage + redundant storage)
- Directory tree space
- Which small files do each large file correspond to
- A data block has three copies, so which three nodes are the three copies of the data block stored in?
Hive's metadata: (imagine the structured data stored on HDFS as a two-dimensional table)
- Table name (mapping relationship between table and data file)
- Field definitions (consisting of those fields)
- Row and column separator (since the file is imagined as a two-dimensional table, the boundaries between rows and columns)
- Data in the table (the file stored on HDFS, which table corresponds to the file?)
Hive's metadata management relies on a relational database! (enterprise best practice: MySQL) hive comes with an embedded small RDBM: derby
1.4. Summary of supported SQL syntax
Supported syntax:
1,select * from db.table1 2,select count(distinct uid) from db.table1 3,support select,union all,join(left,right,full join),like,where,having,limit Equivalent standard grammar 4,Support various common functions, aggregate functions and table functions 5,support json analysis 6,Support function customization: UDF(User Defined Function)/ UDAF/UDTF 7,I won't support it update and delete,Both old and new versions are not supported, and there is no need to support! 8,hive Although support in/exists((not supported in older versions), but hive Recommended use semi join Instead of implementation, it is more efficient. 9,support case ... when ...
Unsupported syntax:
1,support and Multiple conditions join,I won't support it or Multiple conditions join
select a.*, b.* from a join b on a.id = b.id and a.name = b.name; √√√√√
select a.*, b.* from a join b on a.id = b.id or a.name = b.name; xxxxx
2,Cartesian product is not supported by default
select a.*, b.* from a, b;
Your usage principle: most SQL and common SQL syntax are supported!
2, Hive's environment construction and syntax explanation
- hadoop cluster must be installed! Whether it is stand-alone, pseudo distributed, distributed, HA or federated.
- Also install a MySQL (as long as there is a MySQL that can be used and linked. No matter where it is)
- access denied
- Solution: remote connection permission problem
2.1. Environment construction
2.1.1. Dependent environment
Hive cannot run independently! You need to rely on an RDBMS (to help it store metadata) and a file system (to help it store real data)
- An RDBMS must be prepared (it can also be the derby embedded database provided by hive, which is not applicable to the production environment, and MySQL is recommended)
- You must prepare a Hadoop (in fact, you don't have to, you can directly use the linux file system to store it)
2.1.2. Version selection
What aspects should be considered when selecting the version of any technology: function, stability, maintainability, compatibility
Strategy: consider stable versions that are neither new nor old
There are currently two mainstream versions of Hive
- hive-1.x, of which hive-1.2.x is the most widely used version, and the last stable version is hive-1.2.2. If you use this version, your hive will not be able to integrate spark in the future.
- hive-2.x, the current mainstream version of hive. Among the current stable versions of hive-2.x, we choose to use hive-2.3.6
- apache-hive-2.3.6-bin.tar.gz installation package
- apache-hive-2.3.6-src.tar.gz source package
2.1.3. Built in Derby version
Purpose: test, learn and use quickly
1. Upload installation package
put -r apache-hive-2.3.6-bin.tar.gz
2. Unzip the installation package
[bigdata@bigdata05 ~]$ tar -zxvf ~/soft/apache-hive-2.3.6-bin.tar.gz -C ~/apps/
3. Enter the bin directory and run the hive script
[bigdata@bigdata05 ~]$ cd apps/apache-hive-2.3.6-bin/bin [bigdata@bigdata05 bin]$ ./hive
4. Test use
show databases;
create database testdb;
use testdb;
create table student(id int, name string);
insert into table student values ('1','huangbo'), ('2','xuzheng'),('3','wangbaoqiang');
select * from student;
2.1.4. External MySQL version
Purpose: suitable for enterprise production environment
Step 1: prepare MySQL and Hadoop
Please refer to the official website for installation or install by yourself MySQL,Or an available MySQL. Whatever you want MySQL Where, just Hive It can be connected. If Hive and MySQL It is not installed on the same server node, and usually the enterprise environment is not installed on the same node. Remember to Hive open MySQL Remote link permissions for. main points: 1,There is one that works MySQL All right 2,Here MySQL Configure remote connection permissions
Step 2: upload the installation package
Install apache-hive-2.3.6-bin.tar.gz into the server node where Hive is installed.
Upload this installation package to your server in a way you know. Or use the wget command to download it now. Either install the lrzsz command for centos and upload it through the rz command, or use the ftp tool such as filezilla.
Step 3: unzip the installation package into the corresponding Hive installation directory
[bigdata@bigdata05 ~]$ tar -zxvf ~/soft/apache-hive-2.3.6-bin.tar.gz -C ~/apps/
Step 4: modify the configuration file
[bigdata@bigdata05 ~]$ cd ~/apps/apache-hive-2.3.6-bin/conf [bigdata@bigdata05 ~]$ touch hive-site.xml
Note: this file does not exist by default. It is usually created by yourself. Of course, it can also be changed from hive-default.xml, which is not recommended.
[bigdata@bigdata05 ~]$ vi hive-site.xml
Add the following screenshot to the newly created configuration file:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata02:3306/myhivemetadb236?createDatabaseIfNotExist=true&verifyServerCertificate=false&useSSL=false
</value>
<description>JDBC connect string for a JDBC metastore</description>
<!-- If mysql and hive In the same server node, please change bigdata02 by localhost -->
<!-- bigdata02 Installed for you MySQL Server node, please change to your own -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<!-- SQL The name of the driver class does not need to be changed -->
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<!-- connect MySQL User account name -->
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>QWer_1234</value>
<!-- connect MySQL Login password of the user -->
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive236/warehouse236</value>
<description>hive default warehouse, if nessecory, change it</description>
<!-- Optional configuration, which is used to specify Hive The data of the data warehouse is stored in HDFS Directory on -->
</property>
</configuration>
Step 5: add MySQL driver
Remember to add the MySQL driver package mysql-connector-java-5.1.40-bin.jar, which is placed in the lib directory under hive's installation root path. After all, hive needs to read and write mysql.
[bigdata@bigdata05 ~]$ cp ~/soft/mysql-connector-java-5.1.40-bin.jar ~/apps/apache-hive-2.3.6-bin/lib
Step 6: copy the configuration file of Hadoop cluster
Remember to place the core-site.xml and hdfs-site.xml configuration files in the Hadoop cluster in the conf directory under the Hive installation directory.
[bigdata@bigdata05 ~]$ cp $HADOOP_HOME/etc/hadoop/core-site.xml ~/apps/apachehive-2.3.6-bin/conf [bigdata@bigdata05 ~]$ cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml ~/apps/apachehive-2.3.6-bin/conf
Step 7: after installation, configure environment variables
vi ~/.bashrc
Add the following two lines:
export HIVE_HOME=/home/bigdata/apps/apache-hive-2.3.6-bin export PATH=$PATH:$HIVE_HOME/bin
Finally, don't forget to make the environment variable configuration effective:
[bigdata@bigdata05 ~]$ source ~/.bashrc
Step 8: verify Hive installation
[bigdata@bigdata05 ~]$ hive --service version
Step 9: initialize metabase
Note: when hive is a version before 1.x, it is OK not to initialize it. When hive is started for the first time, it will be initialized automatically, but whether enough tables in the metabase will be generated. It will be generated slowly during use. But finally initialize. If you are using version 2.x of hive, you must manually initialize the metabase. Use command:
[bigdata@bigdata05 ~]$ schematool -dbType mysql -initSchema

Remember: initialization only needs to be done once. If you use it for a period of time and execute this command again, you will get a new Hive.
Log of successful execution:
[bigdata@bigdata04 hadoop]$ schematool -dbType mysql -initSchema SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/bigdata/apps/apache-hive-2.3.6-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/bigdata/apps/hadoop2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://bigdata02:3306/hivemetadb2003?createDatabaseIfNotExist=true&verifyServerCertificate=false&useSSL=false Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: root Starting metastore schema initialization to 2.3.0 Initialization script hive-schema-2.3.0.mysql.sql Initialization script completed schemaTool completed
Step 10: start Hive client
[bigdata@bigdata05 ~]$ hive [bigdata@bigdata05 ~]$ hive --service cli

Step 11: exit Hive
hive> quit; hive> exit;
Step 12: precautions
When using Hive, be sure to do three things:
- Ensure that the RDBMS metadata is started.
- Make sure HDFS is started. It can operate normally
- Ensure that the YARN cluster is started and can operate normally
2.1.5. HiveServer2 service
The deployment method is as follows:
First: modify the hdfs-site.xml configuration file of hadoop cluster: add a configuration message to enable webhdfs
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
Second: modify the core-site.xml configuration file of hadoop cluster: add two pieces of configuration information: it indicates the proxy user setting hadoop cluster
<property>
<name>hadoop.proxyuser.bigdata.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.bigdata.groups</name>
<value>*</value>
</property>
Modify the core-site.xml and hdfs-site.xml in the Hadoop cluster, and remember that all nodes can be modified. Restart the Hadoop cluster.
Third: start the Hiveserver2 service
[bigdata@bigdata05 ~]$ nohup hiveserver2 1>/home/bigdata/logs/hiveserver.log 2>/home/bigdata/logs/hiveserver.err &
Step 4: start beeline client
beeline -u jdbc:hive2://bigdata03:10000 -n bigdata
1.6. Hiveserver2 Web UI
Since version 2.0, Hive has provided a simple WEB UI interface for HiveServer2. In the interface, you can intuitively see the current linked session, history log, configuration parameters and measurement information.
Modified: $HIVE_HOME/conf/hive-site.xml configuration file:
<property>
<name>hive.server2.webui.host</name>
<value>bigdata03</value>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
</property>
You can refer to the official website: https://cwiki.apache.org/confluence/display/Hive/Setting+Up+HiveServer2#SettingUpHiveServer2-WebUIforHiveServer2
Restart Hiveserver2 to access the Web UI: http://bigdata05:10002
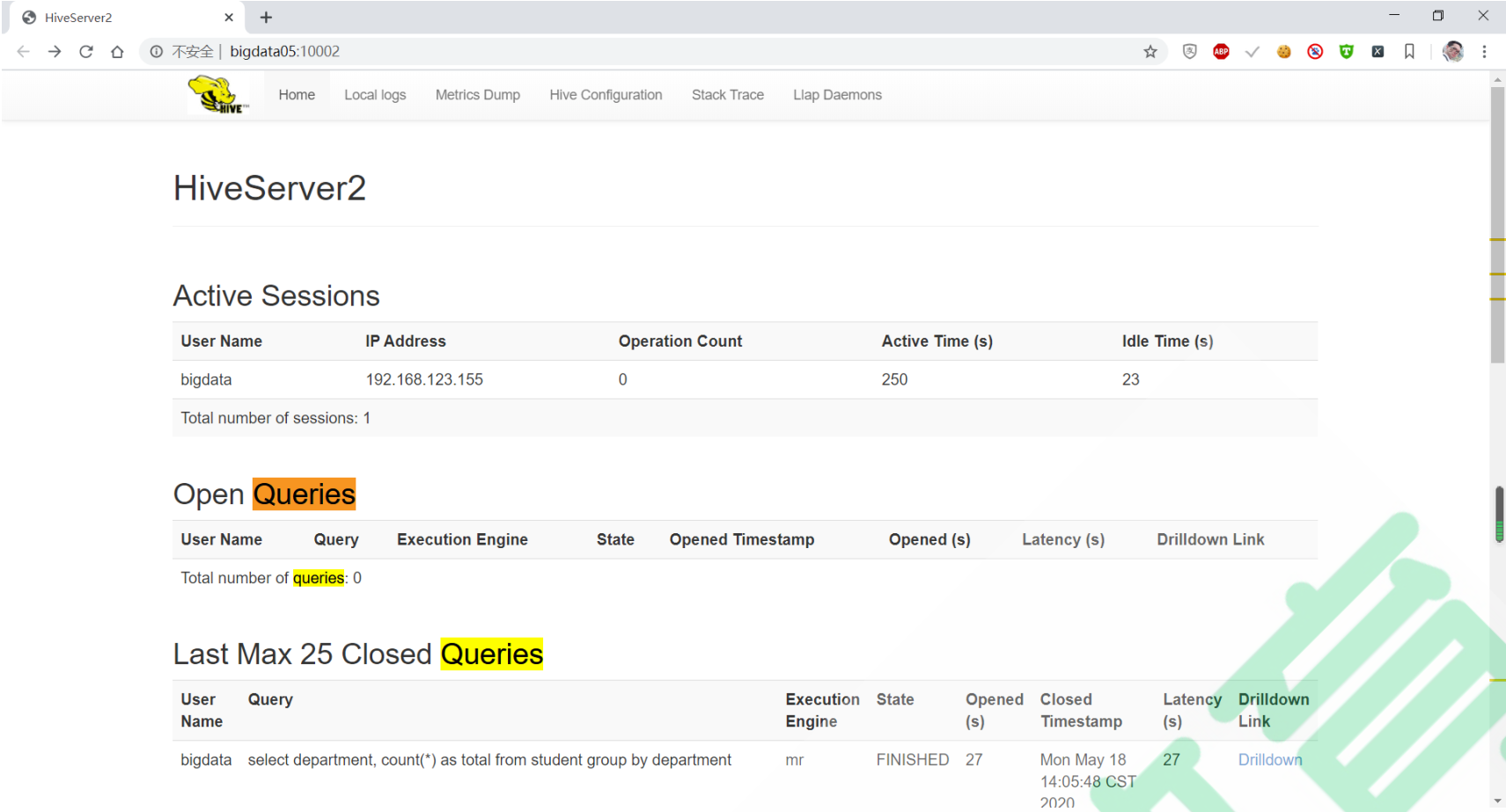
2.2. Hive SQL syntax full operation
2.2.1. Database operation
Create database:
create database mydb;
create databse if not exists mydb comment 'create my db named dbname' with dbproperties ('a'='aaa','b'='bbb')
show create database mydb; -- View create statement desc database extended mydb; -- Query database details show databases; -- List all databases drop database mydb; -- Delete database drop database if exists mydb cascade; -- Delete database use mydb; -- Use database show tables; -- View the data table of the database show tables in mydb; -- View the data table of the database
2.2.2. Add table
Create internal table (managed_table)
create table mingxing(id int, name string, sex string, age int, department string) row format delimited fields terminated by ',';
Create External_Table
create external table mingxing(id int, name string, sex string, age int, department string) row format delimited fields terminated by ',' location '/root/hivedata'; -- Note: specify when creating an external table location The location of must be a directory, not a single file
Create Partition_Table
create table mingxing(id int, name string, sex string, age int, department string) partitioned by (city string) row format delimited fields terminated by ','; -- be careful: partition The field in the table cannot be the field declared in the table
Create Bucket_Table
create table mingxing(id int, name string, sex string, age int, department string) clustered by(id) sorted by(age desc) into 4 buckets row format delimited fields terminated by ',';
2.2.3. Delete table
drop table [if exists] mingxing;
2.2.4. Rename table
alter table mingxing rename to student;
2.2.5. Modification table
alter table mingxing add columns (province string); -- Add field alter table mingxing add columns (province string, xxx bigint); -- Add field drop(Not supported), alternatives can be used replace -- Delete field alter table mingxing change age newage string; -- Modify field alter table mingxing change age newage string first|after id; -- Modify field alter table mingxing replace columns(id int, name string, sex string); -- replace field
2.2.6. hive partition table
alter table mingxing add partition(city='beijing'); -- Add partition alter table mingxing add partition(city='beijing') partition(city='tianjin'); -- Add partition alter table mingxing drop if exists partition(city='beijing'); -- delete a partition alter table mingxing partition(city='beijing') set location '/home/hadoop/data/beijing'; -- Modify partition data path
2.2.7. Various common query and display commands
show databases; -- View Library: show create database mydb; -- View database creation statements show tables; -- View table show tables in mydb; -- View table show create table mingxing; -- View table creation statement show functions; -- View built-in function library show partitions mingxing; -- View table fields desc extended mingxing; -- View table details desc formatted mingxing; -- View the formatted details of the table
2.2.8. Import data in load mode
load data local inpath './student.txt' into table mingxing; -- Import data for local relative path load data local inpath './student.txt' overwrite into table mingxing; -- Import local relative path data overwrite import load data local inpath '/root/hivedata/student.txt' into table mingxing; -- Import local absolute path data load data inpath '/root/hivedata/student.txt' into table mingxing; -- Import HDFS Simple path data on load data inpath 'hdfs://hadoop01:9000/root/hivedata/student.txt' into table mingxing; -- Import data in full path mode on HDFS
2.2.9. Insert data into the table using the insert keyword
insert into table mingxing values(001,'huangbo','male',50,'MA'); -- Single data insertion
Single insertion mode
insert into table student select id,name,sex,age,department from mingxing; -- Note: the queried fields must be student Fields that exist in the table
Multiple insertion mode
from mingxing insert into table student1 select id,name,sex,age insert into table student2 select id,department;
from mingxing2 insert into table student1 partition(department='MA') select id,name,sex ,age where department='MA' insert into table student1 partition(department='CS') select id,name,sex ,age where department='CS';
Static partition insert
load data local inpath '/root/hivedata/student.txt' into table student partition(city='henan');
Dynamic partition insertion
create table student(name string, department string) partitioned by (id int) -- student Table fields: name,department, The partition field is id ..... insert into table student partition(id) select name,department,id from mingxing2; -- The query fields are: name,department,id,Partition field -- Note: the partition field inserted by dynamic partition must be the last field in the query statement
CTAS(create table... as select...) directly stores the query results in a new table
create table student as select id,name,age,department from mingxing; -- Note: as like as two peas, the fields and the fields of the query fields appear in the new automatically table.
2.2.10. Use of like keyword
create table student like mingxing; -- Imitation table
2.2.11. Using insert to export data to local or hdfs
Single mode export data to local
insert overwrite local directory '/root/outputdata' select id,name,sex,age,department from mingxing;
Multi mode export data to local
from mingxing insert overwrite local directory '/root/outputdata1' select id, name insert overwrite local directory '/root/outputdata2' select id, name,age
Export simple path mode to hdfs
insert overwrite directory '/root/outputdata' select id,name,sex,age,department from mingxing;
Query data to hdfs in full path mode
insert overwrite directory 'hdfs://hadoop01:9000/root/outputdata1' select id,name,sex,age,department from mingxing;
2.2.12. Clear database table
truncate table mingxing;
2.2.13. Query data
Basic query
select * from mingxing join student where ... group by ... order by ... limit...
Query global ordered data
select * from mingxing order by age desc , id asc;
If the amount of data is too large, we use local sorting:
set mapred.reduce.tasks=3; set mapreduce.job.reduces=3; select * from mingxing sort by id asc;
Bucket query:
set hive.enforce.bucketing = true; select * from mingxing distribute by sex;
Query sorted bucket data
select * from mingxing cluster by id sort by id desc, age asc;
2.2.14. Five link queries
inner join:
select student.*, mingxing.* from student join mingxing on student.id = mingxing.id select student.*, mingxing.* from student inner join mingxing on student.id = mingxing.id
left outer join:
select student.*, mingxing.* from student left join mingxing on student.id = mingxing.id select student.*, mingxing.* from student left outer join mingxing on student.id = mingxing.id
right outer join
select student.*, mingxing.* from student right join mingxing on student.id = mingxing.id select student.*, mingxing.* from student right outer join mingxing on student.id = mingxing.id
full outer join
select student.*, mingxing.* from student full join mingxing on student.id = mingxing.id select student.*, mingxing.* from student full outer join mingxing on student.id = mingxing.id
in/exists hive efficiently implements left semi join:
select student.*, mingxing.* from student left semi join mingxing on student.id = mingxing.id;
Equivalent to:
select student.* from student where student.id in(select distinct id from mingxing);
data format
95001,Li Yong,male,20,CS 95002,Liu Chen,female,19,IS 95003,Wang Min,female,22,MA 95004,Zhang Li,male,19,IS 95005,Liu Gang,male,18,MA 95006,Sun Qing,male,23,CS 95007,Yi Siling,female,19,MA 95008,Li Na,female,18,CS 95009,Dream round,female,18,MA 95010,Kong Xiaotao,male,19,CS 95011,Tino ,male,18,MA
SQL statement:
create database if not exists exercise_db; use exercise_db; drop table if exists exercise_student; create table exercise_student(id int, name string, sex string, age int, department string) row format delimited fields terminated by ','; load data local inpath "/home/bigdata/students.txt" into table exercise_student; select * from exercise_student;
2.3. Hive's four tables
hive table has a mapping relationship: a table may store and manage many data files!
How are hive tables and data files mapped? select count(*) fro table;
table and HDFS directories
Default path of data warehouse:/user/hive/warehouse/ Library path: nxde1.db Table path: nx_student Data file: stduent.txt Full path to the data store directory of the current table: /user/hive/warehouse/nxde1.db/nx_student/stduent.txt Mapping relationship: Table: nx_student HDFS catalog:/user/hive/warehouse/nxde1.db/nx_student/
2.3.1. Internal table
create table nx_student()
When you create a table, the default organization method is used to store the data of the table in the default warehouse path
2.3.2. External table
When you create a table, in fact, the data is already in HDFS, but not in your default directory. You need to specify the directory when you create the table:
create external table nx_student() row .... location "/aa/bb/ccc"
When deleting a table:
- Internal table: delete metadata and delete data files
- External table: delete metadata without deleting data files
2.3.3. Zoning table
Default path of data warehouse:/user/hive/warehouse/ Library path: nxde1.db Table path: nx_student Partition: city=beijing city=shanghai Data file: stduent.txt Full path to the data store directory of the current table: /user/hive/warehouse/nxde1.db/nx_student/city=shanghai/stduent.txt
create table student_ptn(id int, name string) partitioned by(age int)
Important: the partition field must not be the same as the table, but when used, the partition field is not different from the table field!
Previously, the data was directly placed in the table directory. Now, create folders in the table directory. Each folder guarantees part of the data of the table. This means that the data of a table can be managed by category
select * from student_ptn where city = beijing; select * from student_ptn where date > 2020-08-21; Effect: scan 3 partitions
In the production environment, most of the fact tables are partitioned tables (most of the partitioned fields are also of date type: the probability of partitioning by day is the greatest)
2.3.4. Barrel separation table
Partitions are organized in the form of folders
Pail is as like as two peas in the form of a file. The rule of dividing a barrel is exactly the same as the HashPartitioner of the default mapreduce.
create table student_bck(id int, name string, age int) clustered by (name) sorted by (age desc) into 3 buckets; According to the data in this table name Fields are divided into three files for management, and the data in each file will be managed according to age The descending sort rule is MR Default in hash The logic of the hash component is the same
effect:
1,Partition table: used to submit query efficiency.
Enterprise best practices:
1,If you meet a lot of people SQL In, it will be filtered by a field. So when you build a table. You should use this field as a partition field to create a table
2,If your data basically only analyzes incremental data, not full data, you should partition it according to time
1,Bucket table: also used to improve query efficiency + Used for sampling
Enterprise best practices:
1,If a field in a table is often regarded as a join The query criteria should be optimized by creating a bucket table
select a.*, b.* from a join b on a.id = b.id;
a Table and b All watches should be divided into barrels, and the rules of barrel division should be the same. (the bucket distribution fields are consistent, and the number of buckets is a multiple)
Data warehouse: fact table and dimension table
Query: fact table join dimension table
Whether it is partition or bucket, data skew will occur!
- Data skew in hive 3-5
- There are 11 kinds of data skew in spark
Selection mechanism:
- If you still choose to use hive, you accept MR as the engine by default
- Hive On Spark is not as stable as expected
- SparkSQL is fully hive compatible.
hive + sparkSQL
DAG execution engine: spark tez
Introduction: OLAP engine
- clickhouse kylin druid kudu doris ...>